
'2019/06'에 해당되는 글 9건
- 2019.06.27 :: Elasticsearch - Rest High Level Client를 이용한 Index Template 생성
- 2019.06.26 :: ELK Stack - Logstash(로그스태시)를 이용한 로그 수집 1
- 2019.06.18 :: Eclipse - Archive for required library 해결방법
- 2019.06.17 :: ELK Stack - Filebeat(파일비트)란? 간단한 사용법 1
- 2019.06.15 :: Springboot - Logback 설정 방법 !(logback-spring.xml) 1
- 2019.06.13 :: Spring - RestTemplate Connection Pooling
- 2019.06.13 :: Java - Inner Class Json parse(can only instantiate non-static inner class by using default no-argument constructor)
- 2019.06.08 :: Elasticsearch - 엘라스틱서치 노드의 종류 그리고 클러스터링 4

오늘 간단히 다루어볼 내용은 엘라스틱서치의 REST 자바 클라이언트인 Rest High Level Client를 이용하여 Index Template을 생성해보는 예제이다. 바로 예제로 들어간다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
public void indexTemplate() throws IOException {
String typeName = "_doc";
if(!existTemplate()) {
try(RestHighLevelClient client = createConnection();){
PutIndexTemplateRequest templateRequest = new PutIndexTemplateRequest("log-template");
templateRequest.patterns(Arrays.asList("logstash-*"));
XContentBuilder mapping = XContentFactory.jsonBuilder()
.startObject()
.startObject(typeName)
.startObject("properties")
.startObject("date")
.field("type","date")
.endObject()
.startObject("fieldName")
.field("type","keyword")
.endObject()
.endObject()
.endObject()
.endObject();
templateRequest.mapping("_doc", mapping);
AcknowledgedResponse templateResponse = client.indices().putTemplate(templateRequest, RequestOptions.DEFAULT);
if(!templateResponse.isAcknowledged()) throw new ElasticsearchException("Create Index Template Failed !");
}
}
}
|
cs |
해당 인덱스 템플릿으로 생성될 수 있는 인덱스 패턴은 배열로 여러개 지정가능하다. 현재 설정은 단순 mapping만 설정하였지만, settings 정보까지 인덱스 템플릿 설정으로 넣어줄 수 있다. 만약 로그스태시나 비트 프레임워크를 엘라스틱과 연동하여 일자별 로그를 수집하는 기능을 구현한다면 미리 인덱스 템플릿으로 생성될 인덱스의 정의를 잡아주는 것이 좋을 것이다.
이제 해당 인덱스 템플릿을 구성한 이후에 logstash-*로 시작하는 인덱스가 생성될때 위와 같은 mapping 설정대로 필드가 생성될 것이다.
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2 (1) | 2019.09.20 |
|---|---|
| Elasticsearch - Aggregation API(엘라스틱서치 집계,메트릭(Metric Aggregations) 집계) -1 (0) | 2019.09.19 |
| ELK Stack - Logstash(로그스태시)를 이용한 로그 수집 (1) | 2019.06.26 |
| ELK Stack - Filebeat(파일비트)란? 간단한 사용법 (1) | 2019.06.17 |
| Elasticsearch - 엘라스틱서치 노드의 종류 그리고 클러스터링 (4) | 2019.06.08 |
오늘 포스팅할 내용은 ELK Stack의 요소중 하나인 Logstash(로그스태시)입니다. 로그스태시 설명에 앞서 로그란 시스템이나 애플리케이션 상태 및 행위와 관련된 풍부한 정보를 포함하고 있습니다. 이러한 정보를 각각 시스템마다 파일로 기록하고 있는 경우가 대다수 일겁니다. 그렇다면 과연 이러한 정보를 파일로 관리하는 것이 효율적인 것인가를 생각해볼 필요가 있습니다. 한곳에 모든 로그데이터를 시스템별로 구분하여 저장하고 하나의 뷰에서 모든 시스템의 로그데이터를 볼 수 있다면 굉장히 관리가 편해질 것입니다. 이러한 모든 로그정보를 수집하여 하나의 저장소(DB, Elasticsearch 등)에 출력해주는 시스템이 로그스태시라는 시스템입니다. 앞선 포스팅에서 다루어보았던 Filebeat와 연동을 한다면 파일에 축적되고 있는 로그데이터를 하나의 저장소로 보낼 수도 있고, 카프카의 토픽에 누적되어 있는 메시지들을 가져와 하나의 저장소에 보낼 수도 있습니다.
2019/06/17 - [Elasticsearch&Solr] - ELK Stack - Filebeat(파일비트)란? 간단한 사용법
ELK Stack - Filebeat(파일비트)란? 간단한 사용법
오늘 포스팅할 내용은 ELK Stack에서 중요한 보조 수단 중 하나인 Filebeat(파일비트)에 대해 다루어볼 것이다. 우선 Filebeat를 이용하는 사례를 간단하게 하나 들어보자면, 운영중인 애플리케이션에서 File을..
coding-start.tistory.com
다시 한번 로그스태시는 아래 그림과 같이 오픈소스 데이터 수집 엔진으로, 실시간 파이프라인 기능을 갖춘 데다 널리 사용되고 있는 시스템입니다. 로그스태시를 활용하면 다양한 입력차원에서 데이터를 수집 및 분석, 가공 및 통합해 다양한 목적지에 저장하는 파이프라인을 쉽게 구축할 수 있습니다.

게다가 로그스태시는 사용하기 쉽고, 연동하기 간단한 입력 필터와 출력 플러그인과 같이 다양한 플러그인을 제공합니다. 이처럼 로그스태시를 사용하면 대용량 데이터와 각종 데이터 형식을 통합하고 정규화하는 프로세스 구축이 가능합니다.
로그스태시 아키텍쳐

로그스태시는 위의 그림과 같이 여러 원천데이터를 가져와 필터를 통해 가공하여 하나 이상의 시스템으로 내보낼 수 있습니다. 입력은 여러 원천데이터가 될 수 있고, 필터 또한 하나 이상을 정의하여 가공할 수 있습니다. 즉 입력,필터,출력 세 가지 단계로 구성이 됩니다. 이중 입력과 출력은 필수요소, 필터는 선택요소입니다. 또한 로그스태시는 기본적으로 파이프라인 단계마다 이벤트를 버퍼에 담기 위해 인메모리 바운드 큐를 사용하는데, 로그스태시가 비정상 종료된다면 인메모리에 저장된 이벤트는 손실됩니다. 하지만 손실 방지를 위하여 영구큐를 사용해 실행하면 이벤트를 디스크에 작성하기 때문에 비정상 종료후 재시작되어도 데이터의 손실이 없습니다.
영구 큐는 LOGSTASH_HOME/config 디렉토리의 logstash.yml 설정 파일에서 queue.type: persisted 속성을 설정하면 활성화 가능하다. 또한 로그스태시 힙메모리를 늘리려면 LOGSTASH_HOME/config 디렉토리 밑에 jvm.options 파일에서 조정가능합니다.
입력 플러그인
일반적으로 많이 사용되는 입력 플러그인에 대해 설명한다.
1)File
File 플러그인은 파일에서 이벤트를 한 줄씩 가져오는데 사용한다. 리눅스와 유닉스 명령어 tail -f와 유사한 방식으로 동작한다. 각 파일의 모든 변경 사항을 추적하고 마지막으로 읽은 위치를 기반으로 해당 시점 이후의 데이터만 전송한다. 각 파일에서 현재 위치는 sincedb라는 별도로 분리한 파일에 기록하여 로그스태시를 재기동하여도 읽지 못한 데이터를 빠지지 않고 읽어 올 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
|
#sample.conf
#input plugin file
input
{
file {
path => ["/Users/yun-yeoseong/*","...","..."]
start_position => "beginning"
#sincedb_path => "NULL" ~> 로그스태시를 재시작할때마다 파일의 처음부터 읽는다.
exclude => ["*.csv"]
discover_interval => "10s"
type => "applogs" ~>새로운 필드를 선언한다. 추후 필터에서 유용하게 쓰이는 필드이다.
}
}
|
cs |
위의 input 설정을 설명하면 path에 설정된 경로에서 파일을 읽어오며 파일에서 로그 추출 시작점을 파일의 처음으로 잡았고 경로의 파일중 csv 확장자는 제외하고 10초마다 파일을 읽어들이며 type이라는 필드에 applogs라는 데이터를 추가한다. type 필드를 이용하여 시스템 이름등을 넣어 로그스태시가 수집한 로그데이터 구분이 가능하다. 나머지 기타 설정들을 공식 홈페이지를 확인하자.
2)Beat
Beat 입력 플러그인을 사용하면 로그스태시에서 엘라스틱비트 프레임워크의 이벤트를 수신할 수 있다. 엘라스틱비트란 로그스태시를 보조하는 역할이며, 다양한 시스템에서 데이터를 수집하여 전달해주는 역할이다. 로그스태시와 공통점이라면 다양한 시스템의 데이터를 수집할 수 있다는 점이며, 차이점은 수집한 데이터를 가공하지 못한다는 점이다. 즉, 보통 엘라스틱비트에서 데이터를 수집하여 로그스태시에 보내면 로그스태시는 데이터를 가공하여 출력 포인트로 가공된 데이터를 내보낸다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#input plugin beat
input
{
beats {
host => "192.168.10.229"
port => 2134 =>"실행중인 비트 포트만 작성해주면 된다.
}
beats { =>beats를 여러개 입력하여 다중 비트 입력을 받을 수 있다.
host => "ip"
port => "port"
}
}
|
cs |
위의 input 설정을 설명하자면 192.168.10.229:2134로 떠있는 비트에서 이벤트를 수신한다는 설정이다. 여러개의 beat 설정을 넣어서 여러 비트프레임워크에서 이벤트를 수신할 수 있다. 만약 로그스태시와 비트가 같은 서버에 있다면 host는 생략하고 port만 명시해도 된다.
설명한 input 플러그인 이외에도 JDBC,Kafka 등 많은 입력 플러그인이 있다. 그 중 카프카에서 데이터를 가져오는 예제는 이 포스팅 마지막에 할 예정이라 설명을 생략하였다.
TIP 로그스태시 실행 시 -r 옵션을 지정하면 설정을 변경하고 저장할 때마다 자동으로 바뀐 환경설정을 다시 로드한다. 즉, 매번 설정이 변경될 때마다 로그스태시를 재시작하지 않아도 된다.
출력 플러그인
가장 일반적으로 많이 사용되는 출력 플러그인 설명이다.
1)Elasticsearch
로그스태시에서 일래스틱서치로 이벤트 혹은 로그 데이터를 전송하는 데 사용하며, 권장하는 방법이라고 한다. 엘라스틱서치에 데이터가 있으면 키바나로 손쉽게 시각화가 가능하기에 사용하면 여러모로 유용하다.
|
1
2
3
4
5
6
7
8
9
10
|
#output to elasticsearch
output {
elasticsearch {
index => "elasticserach-%{+YYYY.MM.dd}" => default logstash-%{+YYYY.MM.dd}
document_type => "_doc"
hosts => "192.162.43.30" / ["ip1:9200","ip2:9200"] => default localhost:9200
user => "username"
password => "password"
}
}
|
cs |
직관적인 설정방법이라 크게 설명할 것은 없다. 몇개 짚고 넘어가자면 여러 엘라스틱서치 노드가 존재한다면 위와 같이 배열형태로 설정할 수 있고, 엘라스틱서치 사용자 자격 증명이 필요하다면 user,password를 지정할 수 있다. 데이터를 보낼 인덱스명은 기본값을 가지고 있지만 사용자 정의가 가능하다. 호스트 포트를 생략하면 기본적으로 엘라스틱서치의 기본포트를 이용한다.
2)CSV
CSV 플러그인을 사용하면 출력을 CSV 형식으로 저장할 수 있다. 플러그인 사용 시 필요한 설정은 출력 파일 위치를 지정하는 path 매개변수와 CSV 파일에 기록할 이벤트 필드명을 지정하는 fields 매개변수다. 이벤트에 필드가 없는 경우, 빈 문자열이 기록된다.
|
1
2
3
4
5
6
7
|
#output to elasticsearch
output {
csv {
fields => ["message","@timestamp","host"]
path => "/home/..."
}
}
|
cs |
설명한 출력 플러그인 이외에도 많은 출력 플러그인이 존재한다. 나머지는 공식 홈페이지를 참고하자.
코덱 플러그인
가장 일반적으로 많이 사용되는 코덱 플러그인이다.
1)JSON
해당 코덱은 데이터가 json으로 구성된 경우, 입력 플러그인에서 데이터를 디코딩하고 출력 플러그인에서 데이터를 인코딩하도록 사용하는데 유용하다. 만약 \n 문자가 들어간 JSON 데이터가 있는 경우 json_lines 코덱을 사용한다.
|
1
2
3
4
5
6
|
input codec exam
input {
stdin {
codec => "json" => \n 구분자가 있는 pretty json 일경우 json_lines codec을 이용한다.
}
}
#input exam
{"question":"안녕","answer":"네, 안녕하세요"}
#output result
{
"answer" => "네, 안녕하세요", "question" => "안녕", "host" => "yun-yeoseong-ui-MacBook-Pro.local", "@version" => "1", "@timestamp" => 2019-06-26T13:26:08.704Z }
#input exam2 {"question":"안녕","answer":"네, \n 안녕하세요"} #output result { "message" => "{\"question\":\"안녕\",\"answer\"n 안세요\"}", "host" => "yun-yeoseong-ui-MacBook-Pro.local", "@version" => "1", "tags" => [ [0] "_jsonparsefailure" ], "@timestamp" => 2019-06-26T13:28:58.986Z }
============================================================================= input codec exam input { stdin { codec => "json_lines" => \n 구분자가 있는 pretty json 일경우 json_lines codec을 이용한다. } }
#input exam {"question":"안녕","answer":"네, \n 안녕하세요"} #output result { "host" => "yun-yeoseong-ui-MacBook-Pro.local", "question" => "안녕", "answer" => "네, \n 안녕하세요", "@version" => "1", "@timestamp" => 2019-06-26T13:30:12.650Z } |
cs |
코덱플러그인은 위와 같이 입력,출력 플러그인에 설정이 들어간다.
2)Multiline
여러 행에 걸친 데이터를 단일 이벤트로 병합하는 데 유용한 플러그인이다.
|
1
2
3
4
5
6
7
8
9
10
11
|
#input codex exam2
input {
file {
path => "/var/log/access.log"
codex => multiline {
pattern => "^\s" 공백으로 시작하는 데이터를 이전 행과 결합
negate => false
what => "previous"
}
}
}
|
cs |
공백으로 시작하는 모든 행을 이전 행과 결합하는 코덱설정이다.
이외에도 더 많은 코덱 플러그인이 존재한다. 자세한 사항을 공식 홈페이지를 참고바란다.
Kafka(카프카) + ELK Stack을 이용한 로그 분석 구현
사실 데이터의 흐름은 정의하기 나름이지만 필자 나름대로의 플로우로 로그분석을 위한 로그데이터 파이프라인을 구축해보았고, 실제 솔루션 내에도 적용한 플로우이다.
전체적인 플로는 아래와 같다.
App -> Kafka -> Logstash -> Elasticsearch
위와 같이 애플리케이션에서 발생하는 로그들을 DB에 저장하는 것이 아니라, 카프카를 이용해 특정 토픽에 메시지를 보낸 후에 해당 토픽을 폴링하고 있는 로그스태시가 데이터를 수집하여 엘라스틱서치에 색인한다.
1)App(Spring boot + Spring Cloud Stream)
애플리케이션은 스프링부트 기반의 웹프로젝트이며, 스프링 클라우드 스트림 라이브러리를 이용하여 카프카와 연동하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
############################<Binder Config>###############################
#broker list(cluster)
spring.cloud.stream.kafka.binder.brokers=localhost:9092,localhost:9093,localhost:9094,localhost:9095
#acks mode
spring.cloud.stream.kafka.binder.producer-properties.acks=all
#required acks num
spring.cloud.stream.kafka.binder.required-acks=3
#min partition num
#spring.cloud.stream.kafka.binder.min-partition-count=4
#auto create topic enable
spring.cloud.stream.kafka.binder.auto-create-topics=true
#auto add partitions
#spring.cloud.stream.kafka.binder.auto-add-partitions=true
#replication factor
spring.cloud.stream.kafka.binder.replication-factor=2
############################</Binder Config>###############################
############################<Producer Config>##############################
#Log Producer
spring.cloud.stream.bindings.logstash_producer.destination=KIVESCRIPT_CHAT_LOG
spring.cloud.stream.bindings.logstash_producer.content-type=application/json
spring.cloud.stream.bindings.logstash_producer.producer.partition-count=4
############################</Producer Config>#############################
|
cs |
애플리케이션에서 카프카와 연동하기 위한 application.properties 설정들이다. 만약 위의 설정들을 모른다면 이전에 포스팅했던 글을 참고하길 바란다.
Kafka - Spring cloud stream kafka(스프링 클라우드 스트림 카프카)
Kafka - Spring cloud stream kafka(스프링 클라우드 스트림 카프카) 이전 포스팅까지는 카프카의 아키텍쳐, 클러스터 구성방법, 자바로 이용하는 프로듀서,컨슈머 등의 글을 작성하였다. 이번 포스팅은 이전까지..
coding-start.tistory.com
밑의 링크는 카프카 클러스터링에 관련된 포스팅이다.
Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법
Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법 ▶︎▶︎▶︎카프카란? 이전 포스팅에서는 메시징 시스템은 무엇이고, 카프카는 무엇이며 그리고 카프카의 특징과 다른 메시지 서버와의 차이..
coding-start.tistory.com
다음은 카프카 바인더와 연결시켜줄 채널을 명시해주는 자바 컨피그 클래스이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
/**
* Custom Message Processor
* @author yun-yeoseong
*
*/
public interface MessageProcessor {
public static final String CHAT_LOG = "logstash_producer";
@Output(KiveMessageProcessor.CHAT_LOG)
MessageChannel chatLog();
}
|
cs |
애플리케이션에서 카프카 토픽으로 메시지를 내보내는 코드이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
/**
*
* @author yun-yeoseong
*
*/
@Slf4j
@Component
public class MessageSender {
@Autowired
private MessageProcessor messageProcessor;
public void sendMessage(String log) {
MessageChannel outputChannel = messageProcessor.chatLog();
outputChannel.send(MessageBuilder
.withPayload(request)
.setHeader(MessageHeaders.CONTENT_TYPE, MimeTypeUtils.APPLICATION_JSON)
.build());
}
}
|
cs |
다음은 로그스태시 설명이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
input {
kafka {
bootstrap_servers => "127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9095"
topics => "LOGSTASH_PRODUCER"
group_id => "APP_LOG_GROUP"
enable_auto_commit => "true"
auto_offset_reset => "latest"
consumer_threads => 4
codec => "json"
}
}
output {
elasticsearch {
index => "chatlog-%{+YYYY.MM.dd}"
document_type => "_doc"
hosts => ["127.0.0.1:9200","127.0.0.1:9400"]
template_name => "log-template"
}
}
|
cs |
위 설정은 Logstash 입력과 출력을 정의한 conf 파일이다. 별다른 설정은 없고 입력으로 카프카 클러스터의 특정 토픽을 폴링하고 있으며, 출력으로 엘라스틱서치를 바라보고 있다. 설정에 대한 자세한 사항은 공식홈페이지를 확인하길 바란다. 하나 짚고 넘어갈 것이 있다면 필자는 로그를 색인하기 위한 인덱스를 동적으로 생성하지 않고, 미리 Index Template를 선언해 놓았다. 만약 동적으로 인덱스를 생성한다면 비효율적인 필드 데이터 타입으로 생성될 것이다.(keyword성 데이터도 text타입으로 생성)
아래 링크는 엘라스틱서치 Rest 자바 클라이언트를 이용하여 인덱스 템플릿을 생성하는 예제이다.
Elasticsearch - Rest High Level Client를 이용한 Index Template 생성
오늘 간단히 다루어볼 내용은 엘라스틱서치의 REST 자바 클라이언트인 Rest High Level Client를 이용하여 Index Template을 생성해보는 예제이다. 바로 예제로 들어간다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1..
coding-start.tistory.com
생략된 나머지 설정(카프카,엘라스틱서치 등)들은 이전 포스팅 글들을 참조하자. 혹시나 모든 설정파일 및 소스가 필요하다면 댓글을 달아주시면 될 듯하다.
기타 명령어
LOGSTASH_HOME/bin logstash-plugin list -> 현재 설치된 플러그인 목록
LOGSTASH_HOME/bin logstash-plugin list --group filter -> 필터 플러그인 목록 출력(input,output,codec 등을 그룹명으로 줄 수 있음)
LOGSTASH_HOME/bin logstash-plugin list 'kafka' -> kafka라는 단어가 포함된 플러그인이 있다면 출력
LOGSTASH_HOME/bin logstash-plugin install logstash-output-email -> logstash-output-email 플러그인 설치
LOGSTASH_HOME/bin logstash-plugin update logstash-output-email -> logstash-output-email 플러그인 최신버전으로 업데이트
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - Aggregation API(엘라스틱서치 집계,메트릭(Metric Aggregations) 집계) -1 (0) | 2019.09.19 |
|---|---|
| Elasticsearch - Rest High Level Client를 이용한 Index Template 생성 (0) | 2019.06.27 |
| ELK Stack - Filebeat(파일비트)란? 간단한 사용법 (1) | 2019.06.17 |
| Elasticsearch - 엘라스틱서치 노드의 종류 그리고 클러스터링 (4) | 2019.06.08 |
| Elasticsearch - 엘라스틱서치 자바 힙 메모리 변경(JVM Heap) (0) | 2019.06.08 |

Archive for required library 와 같은 메시지와 함께 이클립스 빌드패스 문제가 있을 때가 있다. Update Project를 해보고, Maven clean & install을 해보아도 문제가 해결되지 않았다.(여기까지로 해결되는 경우도 종종있음)
해당 에러 메시지를 보면 특정 메이븐 경로에 있는 특정 라이브러리가 눈에 띌 것이다. 해당 경로를 들어가서 폴더를 싹 지운 후에 해당 프로젝트 우클릭->Maven->Update Project 하면 문제가 말끔히 해결된다.
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - Garbage Collection(GC,가비지 컬렉션) 란? (1) | 2019.07.29 |
|---|---|
| Java - JVM이란? JVM 메모리 구조 (1) | 2019.07.29 |
| Java - Inner Class Json parse(can only instantiate non-static inner class by using default no-argument constructor) (0) | 2019.06.13 |
| Java - lambda(람다) 간단한 사용법 ! (0) | 2019.03.10 |
| Java - Collections.rotate() 란? (0) | 2019.02.25 |

오늘 포스팅할 내용은 ELK Stack에서 중요한 보조 수단 중 하나인 Filebeat(파일비트)에 대해 다루어볼 것이다. 우선 Filebeat를 이용하는 사례를 간단하게 하나 들어보자면, 운영중인 애플리케이션에서 File을 통한 로그데이터를 계속 해서 쌓고 있다면 이러한 로그데이터를 단순 파일로 가지고 있는 것이 유용할까? 물론 모니터링하는 시스템이 존재 할 수 있다. 하지만 이러한 모니터링 시스템이 아닌 로그데이터를 계속해서 축적하여 통계를 내고 싶고, 데이터의 증가,하강 추이를 시각화하여 보고 싶을 수도 있다. 이렇게 특정 로그파일을 주기적으로 스캔하여 쌓이고 있는 데이터를 긁어오는 역할을 하는 것이 파일비트이다. 물론 록그스태시만 이용하여 파일에 쌓이는 행데이터를 가져올 수 있다. 하지만 이러한 로그스태시를 엔드서버에 설치하지 못하는 상황이 있을 수 있기에 가벼운 파일비트를 이용하곤 한다.
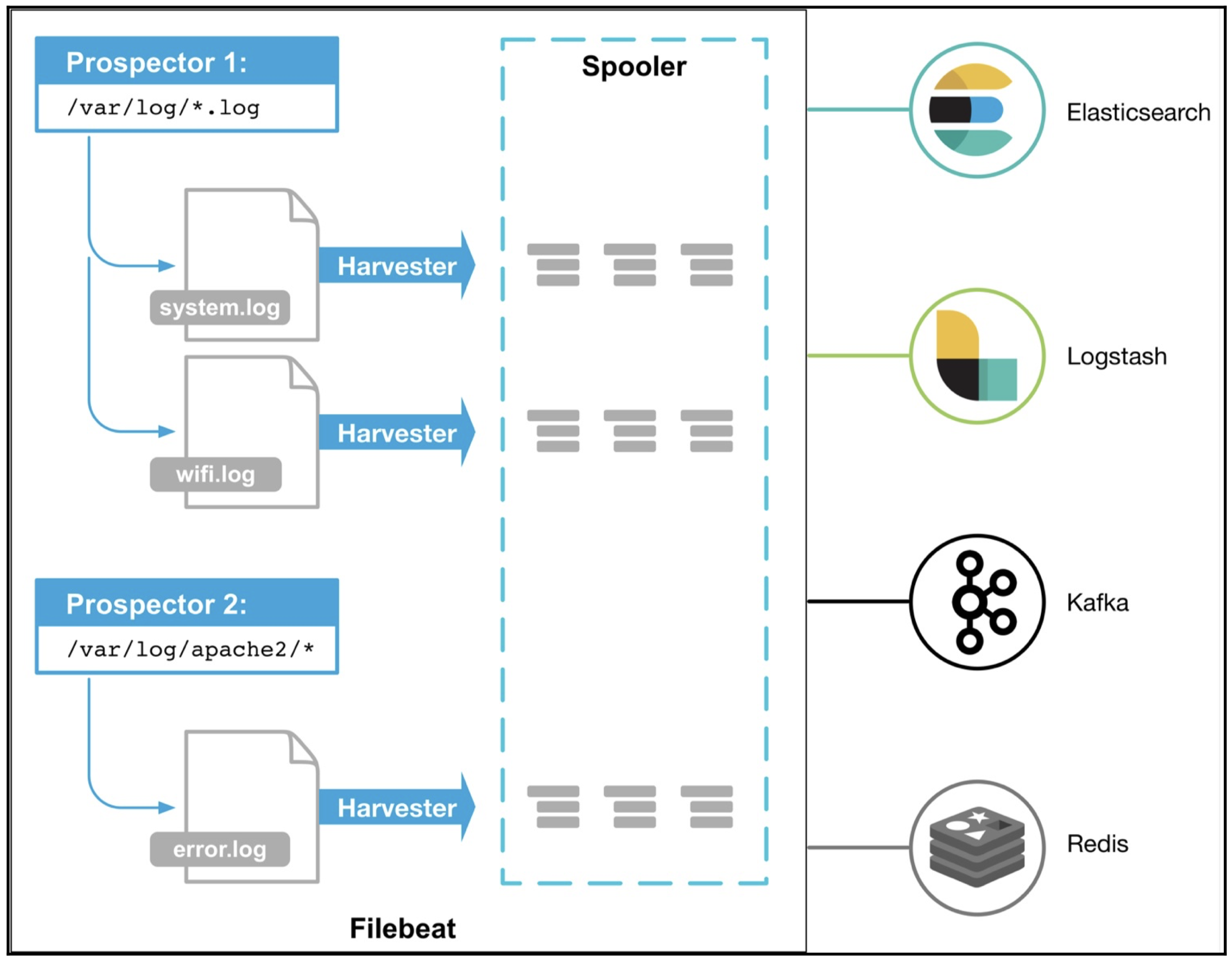
파일비트 아키텍쳐
파일비트는 Prospectors, Harvesters, Spooler라는 주요 구성 요소를 가지고 있다. Prospector는 로그를 읽을 파일 목록을 구분하는 역할을 담당한다. 여러 파일 경로를 설정하면 로그를 읽을 파일을 식별하고 각 파일에서 로그를 읽기 시작한다. 이때 파일 컨텐츠, 즉 이벤트 데이터(로그)를 읽는 역할은 Harvester가 담당한다. 파일을 행 단위로 읽고 출력으로 보낸다. 하나의 Harvester가 개별로 파일을 담당하며 파일을 열고 닫는다. 읽어올 파일 수가 여러개가 되면 그에 따라 Harvester도 여러개가 되는 것이다. 이벤트가 발생하여 읽어온 로그데이터는 Spooler에게 보낸다. 그리고 Spooler는 이벤트를 집계하고 설정할 출력으로 전달한다.
위의 그림처럼 파일비트는 다수의 Prospector, Harvester로 이루어진다. 파일비트가 지원하는 Input 타입은 log와 stdin이 있다. log는 Prospectors에 정의된 파일을 읽어 데이터를 수집하며, stdin은 표준 입력에서 데이터를 읽는다. 그럼 여기서 의문이 드는 것이 있다. 물리적인 파일을 읽는데 어디까지 읽었고, 출력은 어디까지 보냈고 이런 정보를 어디서 유지하고 있는 것일까? 이러한 정보는 Harvester가 offset으로 디스크에 주기적으로 기록하며 이는 레지스트리 파일에서 관리한다. 엘라스틱서치,카프카,레디스 같은 출력 부분 미들웨어 시스템에 문제가 발생하면 파일비트는 마지막으로 보낸 행을 기록하고, 문제가 해결될때까지 계속 데이터를 수집하고 있는다. 이러한 관리 덕분에 파일비트를 내렸다 다시 올려도 데이터의 위치를 기억한 상태에서 기동되게 된다. 또한 Harvester 같은 경우 출력에게 데이터를 보낸 후에 출력 부분에서 데이터를 잘 받았다는 응답을 기다리는데 해당 응답을 받지 않은 경우 다시 데이터를 보내게됨으로 반드시 한번은 데이터 손실없이 보내게 된다.
파일비트 사용법(filebeat-6.6.2 버전기준으로 작성됨)
여기서 파일비트 설치법은 다루지 않는다. 예제에서 다루어볼 것은 Input(file-log type) output(es,logstash) 이다. 간단한 예제이므로 주석에 설명을 달아놓았고 별도의 설명은 하지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
filebeat.yml
#Filebeat prospectors
filebeat.prospectors:
- input_type: log
paths:
- /Users/yun-yeoseong/rnb-chatbot-rivescript/logs/*.log
#파일비트로 읽어오지 않을 패턴을 지정
#exclude_lines: ["^INFO"]
#파일비트로 읽어올 패턴을 지정
#include_liens: ["^ERR","^WARN"]
#파일비트가 파일을 output으로 내보낼때 밑의 tags도 추가해서 보낸다.(field -> tags)
#보통 수집기 별로 혹은 애플리케이션 별로 tags 필드의 값을 다르게 주어
#키바나와 로그스태시에서 이벤트를 필터링하는데 사용한다.
tags: ["app_logs"]
#output으로 보낼때 해당 필드를 추가해서 보낸다.(field -> fields.env)
fields:
env: dev
#여러라인의 로그를 어떻게 처리할지 패턴을 정의한다
#RE2 구문을 기반으로 정규식을 짠다(https://godoc.org/regexp/syntax)
#공백으로 시작하는 연속행을 발견한다.
multiline.pattern: '^[[:space:]]'
#정규식패턴 무효화 여부
multiline.negate: false
#공백으로 시작하는 구문을 공백으로 시작하지 않는 구문 어디로 합칠것인가(after,before)
multiline.match: after
#파일을 몇 초마다 스캔할 것인가(default 10s)
scan_frequency: 5s
#엘라스틱서치가 아웃풋이라면 document type을 무엇으로 할지
#document_type: doc
#Outputs
#Elasticsearch output
output.elasticsearch:
#enabled로 출력을 활성/비활성 할 수 있다.
enabled: true
#ES클러스터 노드 리스트를 지정할 수 있다. 각 노드의 데이터 분배는
#라운드로빈 방식을 이용한다.
hosts: ["localhost:9200","localhost:9300"]
#인증이 필요할 경우 username/password 지정이 가능
username: "elasticsearch"
password: "password"
#인제스트노드 파이프라인에 전달해 색인 이전에 데이터 전처리가 가능
#pipeline: "pipeline-name"
#logstash output, 로그스태시를 지정하려면 로그스태시에서
#비트 이벤트를 수신할 수 있는 비트 입력 플러그인을 설정해야한다.
#output.logstash:
# enabled: true
#출력 노드를 여러개 지정할 수 있다. 기본적으로 임의의 노드를 선택해 데이터를 보내고,
#데이터를 보낸 호스트에서 응답을 하지 않으면 다른 노드들중 하나로 다시 데이터를 보낸다.
#hosts: ["localhost:5044","localhost:5045"]
#로그스태시 호스트들에서 이벤트데이터를 균등히 보내고 싶다면 로드벨런싱 설정을 넣어준다.
#loadbalance: true
#전역옵션
#파일 정보를 유지하는 데 사용하는 레지스트리 파일 위치를 지정한다.
#마지막으로 읽은 오프셋과 읽은 행이 설정 시 지정한 출력 지점의 응답 여부 등
#filebeat.registry_file: /Users/yun-yeoseong/elasticsearch-file/filebeat/registry
#파일비트 종료 시 데이터 송신이 끝마칠 때까지 대기하는 시간
#파일비트는 기본적으로 종료시 이벤트 송신 처리를 기다리지 않고 종료하기 때문에
#이벤트 송신이 잘되었는지 수신을 종료전에 기다리도록 시간설정을 할 수 있다.
filebeat.shutdown_timeout: 10s
#일반옵션
#네트워크 데이터를 발송하는 수집기의 이름 기본적으로 필드에는 호스트 이름을 지정한다.
name: "app_log_harvester"
#동시에 실행할 수 있는 최대 CPU 개수를 설정. 기본값은 시스템에서 사용 가능한 논리적인 CPU 개수
#max_procs: 2
|
cs |
./filebeat --c ./filebeat_exam.yml -> 해당 명령어로 실행시켜준다.
데이터는 spring boot 프로젝트를 실행시켰을 때, 올라가는 로그를 수집한 결과이다. kibana Discovery tab을 이용하여 데이터가 어떻게 들어왔는지 결과를 확인할 것이다.
Result
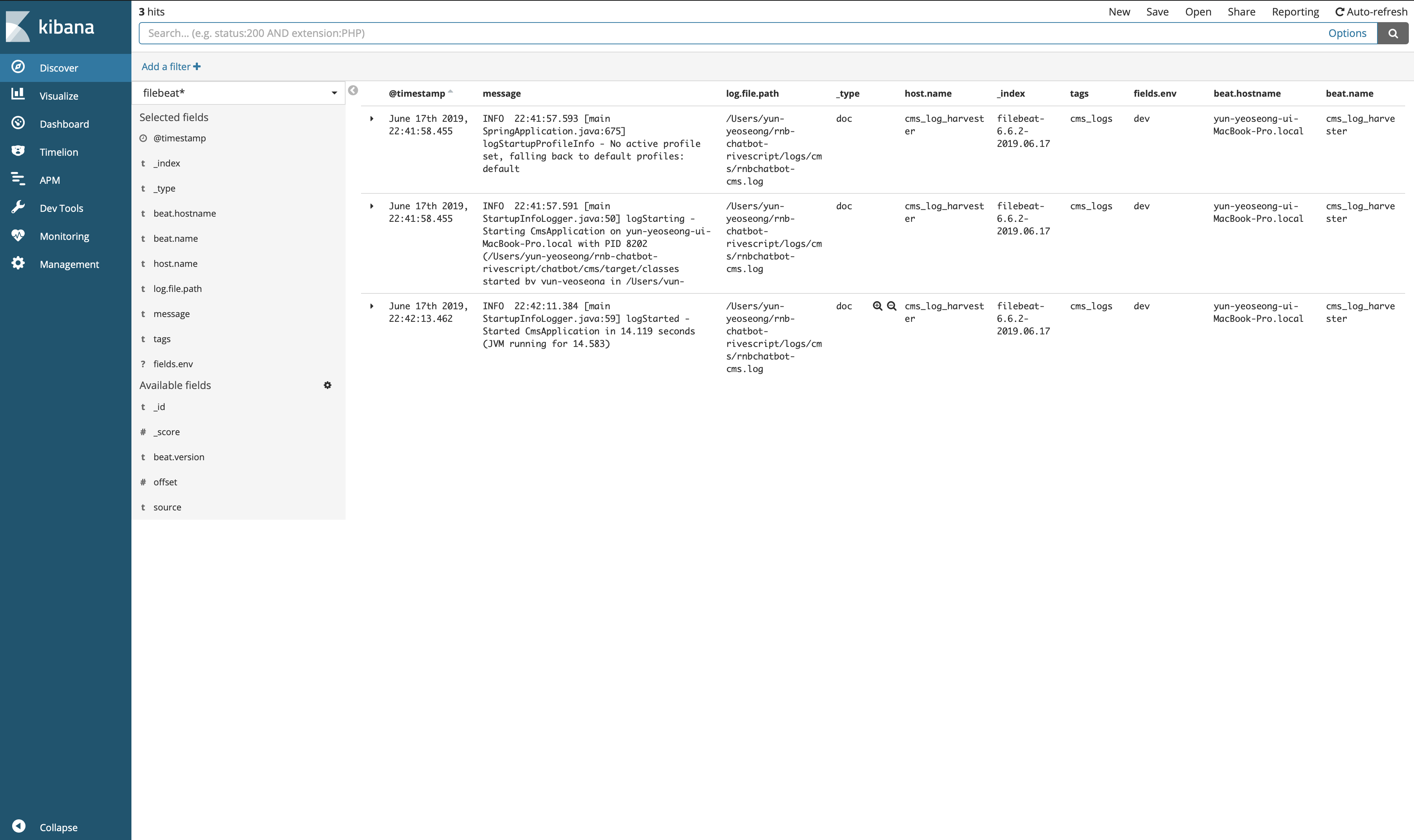
일부 예제에 들어간 설정과 다른 데이터가 들어간 것도 있다. 데이터는 고려하지 말고 어떤 필드들이 생겼고 어떤 데이터가 설정과 비교하여 들어왔는지 확인하자. 일반적으로 파일비트는 인덱스를 버전정보+날짜정보를 이용하여 일자별로 인덱스 생성을 진행한다.(매일 생긴다는 것은? 그만큼 인덱스가 많아진다는 것이기 때문에 백업 스케쥴을 잘 잡아줘야한다.)그리고 @timestamp를 찍어 데이터 색인 시간을 볼 수 있고, 모든 데이터는 message 필드에 저장된다. 또한 설정 부분에 tags, fields.env 설정이 들어간 것이 있을 것이다. 만약 성격이 다른 애플리케이션이 있고 각각 따로 통계를 내고 싶다면 해당 필드들을 이용하여 필터를 걸수도 있고 또한 Logstash를 이용하여 데이터 처리를 할때 해당 필드들을 이용하여 필터를 걸어 사용할 수도 있을 것이다.(Input의 파일 경로(- input_type)를 여러개 지정할 수 있으므로 각 패스마다 해당 필드의 값을 다르게 준다)
여기까지 간단히 파일비트가 뭔지 알아봤고 사용법도 알아보았다. 사실 운영환경에서는 이렇게 간단히 사용할 수 없는 환경이 대부분일 것이다. 레퍼런스를 활용하여 더 깊게 공부할 필요성이 있다.
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - Rest High Level Client를 이용한 Index Template 생성 (0) | 2019.06.27 |
|---|---|
| ELK Stack - Logstash(로그스태시)를 이용한 로그 수집 (1) | 2019.06.26 |
| Elasticsearch - 엘라스틱서치 노드의 종류 그리고 클러스터링 (4) | 2019.06.08 |
| Elasticsearch - 엘라스틱서치 자바 힙 메모리 변경(JVM Heap) (0) | 2019.06.08 |
| Elasticsearch - 엘라스틱서치와 루씬의 관계 - 2(세그먼트 불변성,Translog) (1) | 2019.05.25 |

오늘 포스팅할 내용은 개발 단계에서 없어서는 안되는 로그에 관한 포스팅입니다. 매번 sysout으로 로그를 찍는 것은 바보 같이 리소스를 낭비하는 짓이라는 것은 누구나 다 알고 계실겁니다. 저는 별소 lombok을 즐겨 사용하기에 @Slfj4 어노테이션을 자주 사용하게 됩니다. 하지만 이번에는 단순 콘솔에서만 출력하는 것이 아니라, 일자별 로그파일을 떨구어주는 설정파일에 대해 알아볼 것입니다. 바로 예제로 들어가겠습니다.(로그사용법에 대해서는 다루지 않습니다.)
참고로 Logback은 slf4j의 구현체이자 스프링 부트의 기본 로그 객체입니다. 기본으로 classpath에서 스프링부트가 읽어가는 파일 이름은 logback-spring.xml입니다. 물론 설정 파일명을 변경하실 수도 있습니다.
|
1
2
|
#logging config
logging.config=classpath:logging-config.xml
|
cs |
저는 기본 설정파일명을 사용하지 않을 것이기 때문에 application.properties에 로깅 설정 파일명을 명시해줍니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
<configuration>
<!-- Created By yeoseong_yoon -->
<!-- 로그 경로 변수 선언 -->
<property name="LOG_DIR" value="${user.home}/logs/app" />
<property name="LOG_PATH" value="${LOG_DIR}/app.log"/>
<!-- Console Appender -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>
%-5level %d{HH:mm:ss.SSS} [%thread %F:%L] %method - %msg%n
</pattern>
</encoder>
</appender>
<!-- Rolling File Appender -->
<appender name="ROLLING_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 파일 경로 -->
<file>${LOG_PATH}</file>
<!-- 출력패턴 -->
<encoder>
<pattern>%-5level %d{HH:mm:ss.SSS} [%thread %F:%L] %method - %msg%n</pattern>
</encoder>
<!-- Rolling 정책 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- .gz,.zip 등을 넣으면 자동으로 일자별 로그파일 압축 -->
<fileNamePattern>${LOG_DIR}/app_%d{yyyy-MM-dd}_%i.log.gz</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<!-- 파일당 최고 용량 10MB -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 일자별 로그파일 최대 보관주기(일단위)
만약 해당 설정일 이상된 파일은 자동으로 제거-->
<maxHistory>60</maxHistory>
</rollingPolicy>
</appender>
<logger name="애플리케이션패키지명(ex com.web.spring)" level="INFO"/>
<root level="INFO"> <!-- DEBUG -->
<appender-ref ref="ROLLING_FILE"/>
</root>
</configuration>
|
cs |
우선은 <property>를 이용하여 전역으로 사용할 변수명을 지정해줍니다. 이 설정파일에서는 로그파일의 경로, 로그파일 Full Path를 변수에 할당하였습니다. 그다음 중요한 설정인 <appender> 설정입니다. 로그 파일의 출력 형식을 지정해주는 설정이라고 보시면 됩니다. 사실 설정의 핵심중 하나입니다. 현재 설정에서는 console,rollingfile appender를 지정해주었습니다.
Appender 종류
| 이름 | 설명 |
| ConsoleAppender | 콘솔에 로그를 찍음 |
| FileAppender | 파일에 로그를 찍음(하나의 파일에 로그를 계속 누적해서 찍음) |
| RollingFileAppender | 여러개의 파일을 순회하면서 로그를 찍음 |
| SMTPAppender | 로그를 메일에 찍어 보냄 |
| DBAppender | DB에 로그를 찍음 |
| 기타 SocketAppender, SSLSocketAppender... |
패턴에 사용되는 요소
- 1. %Logger{length}
- - Logger name을 축약할 수 있다. {length}는 최대 자리 수
- 2. %thread
- - 현재 Thread 이름
- 3. %-5level
- - 로그 레벨, -5는 출력의 고정폭 값
- 4. %msg
- - 로그 메시지 (=%message)
- 5. %n
- - new line
- 6. ${PID:-}
- - 프로세스 아이디
- 기타
- %d : 로그 기록시간
- %p : 로깅 레벨
- %F : 로깅이 발생한 프로그램 파일명
- %M : 로깅일 발생한 메소드의 이름
- %l : 로깅이 발생한 호출지의 정보
- %L : 로깅이 발생한 호출지의 라인 수
- %t : 쓰레드 명
- %c : 로깅이 발생한 카테고리
- %C : 로깅이 발생한 클래스 명
- %m : 로그 메시지
- %r : 애플리케이션 시작 이후부터 로깅이 발생한 시점까지의 시간
위에 설정에서 하나 짚고 넘어갈 것이 있다면 RollingAppender의 <file>과 <fileNamePattern>이다. 일자별 로그파일을 찍기 위해 버퍼가 되는 파일이고 후자는 일자별 로그파일의 이름 패턴을 넣어주는 것이다.
이상 정말 간단한 Logback 설정방법을 다루어보았다. 이것보다 많은 설정들이 있을 것이다. 하지만 필자로 깊게 알지못하기에 간단한 사용법만 다루었다. 하지만 하나 중요한 사실은 로그를 남기는 것도 좋지만, 적정 레벨의 선택 그리고 포맷이다. 필자가 프로젝트를 하며 ELK를 이용하여 로그를 중앙 집중식으로 관리를 하게되었는데, 정규식패턴식과 같은 것으로 로그파일을 필터링 할 상황이 생겼다. 만약 구조화된 로그 출력이라면 정규식으로 필터링 걸기가 편할 것이지만 구조화되지 않고 애플리케이션마다 출력하는 패턴이 다르다면 필터링 하는 작업도 쉽지 않을 것이다.
'Web > Spring' 카테고리의 다른 글
| Spring - Field vs Constructor vs Setter Injection 그리고 순환참조(Circular Reference) (3) | 2019.08.17 |
|---|---|
| Springboot - DB Datasource 암호화/복호화(application.properties) (0) | 2019.08.05 |
| Spring - RestTemplate Connection Pooling (0) | 2019.06.13 |
| Spring - JSON to Object(Object to JSON) Converting Gson ! (0) | 2019.05.30 |
| Spring - ModelMapper란? (2) | 2019.04.10 |

오늘 포스팅할 내용은 Spring의 RestTemplate입니다. 우선 RestTemplate란 Spring 3.0부터 지원하는 Back End 단에서 Http 통신에 유용하게 쓰이는 템플릿 객체이며, 복잡한 HttpClient 사용을 한번 추상화하여 Http 통신사용을 단순화한 객체입니다. 즉, HttpClient의 사용에 있어 기계적이고 반복적인 코드들을 한번 랩핑해서 손쉽게 사용할 수 있게 해줍니다. 또한 json,xml 포멧의 데이터를 RestTemplate이 직접 객체에 컨버팅해주기도 합니다.
이렇게 사용하기 편한 RestTemplate에서도 하나 짚고 넘어가야할 점이 있습니다. RestTemplate 같은 경우에는 Connection Pooling을 직접적으로 지원하지 않기 때문에 매번 RestTemplate를 호출할때마다, 로컬에서 임시 TCP 소켓을 개방하여 사용합니다. 또한 이렇게 사용된 TCP 소켓은 TIME_WAIT 상태가 되는데, 요청량이 엄청 나게 많아진다면 이러한 상태의 소켓들은 재사용 될 수 없기 때문에 응답이 지연이 될것입니다. 하지만 이러한 RestTemplate도 Connection Pooling을 이용할 수 있는데 이것은 바로 RestTemplate 내부 구성에 의해 가능합니다. 바로 내부적으로 사용되는 HttpClient를 이용하는 것입니다. 바로 예제 코드로 들어가겠습니다.
우선 Connection pool을 적용하기 위한 HttpClientBuilder를 사용하기 위해서는 dependency 라이브러리가 필요하다.
compile group: 'org.apache.httpcomponents', name: 'httpclient', version: '4.5.6'
각자 필요한 버전을 명시해서 의존성을 추가해준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
/*
* Connection Pooling을 적용한 RestTemplate
*/
@Bean(name="restTemplateClient")
public RestTemplate restClient() {
HttpComponentsClientHttpRequestFactory httpRequestFactory = new HttpComponentsClientHttpRequestFactory();
/*
* 타임아웃 설정
*/
//httpRequestFactory.setConnectTimeout(timeout);
//httpRequestFactory.setReadTimeout(timeout);
//httpRequestFactory.setConnectionRequestTimeout(connectionRequestTimeout);
HttpClient httpClient = HttpClientBuilder.create()
.setMaxConnTotal(150)
.setMaxConnPerRoute(50)
.build();
httpRequestFactory.setHttpClient(httpClient);
return new RestTemplate(httpRequestFactory);
}
|
cs |
위에 코드를 보면 최대 커넥션 수(MaxConnTotal)를 제한하고 IP,포트 1쌍 당 동시 수행할 연결 수(MaxConnPerRoute)를 제한하는 설정이 포함되어있습니다. 이런식으로 최대 커넥션 수를 150개로 제한하여 150개의 자원내에서 모든 일을 수행하게 되는 것입니다. 마치 DB의 Connection Pool 과 비슷한 역할이라고 보시면 됩니다.(물론 같지는 않음.) 그리고 RestTemplate은 Multi Thread 환경에서 safety 하기 때문에 빈으로 등록하여 가져다 쓰도록 하였습니다.
마지막으로 구글링을 하던 도중에 Keep-alive 활성화가 되야지만 HttpClient의 Connection Pooling 지원이 가능하다고 나와있습니다. 기본적으로 HTTP1.1은 Keep-alive가 활성화되어 있지만 이부분은 더 깊게 알아봐야할 점인것 같습니다. 만약 해당 부분에 대해 아시는 분은 꼭 댓글에 코멘트 부탁드리겠습니다.
'Web > Spring' 카테고리의 다른 글
| Springboot - DB Datasource 암호화/복호화(application.properties) (0) | 2019.08.05 |
|---|---|
| Springboot - Logback 설정 방법 !(logback-spring.xml) (1) | 2019.06.15 |
| Spring - JSON to Object(Object to JSON) Converting Gson ! (0) | 2019.05.30 |
| Spring - ModelMapper란? (2) | 2019.04.10 |
| Spring boot - Redis를 이용한 HttpSession (1) | 2019.04.02 |

RestTemplate으로 다른 API를 호출하고 특정 객체 타입으로 JSON을 parsing 하는 상황이었다. 그런데 해당 특정 객체는 내부적으로 Inner Class를 가지고 있는 상황이었는데, 아래와 같은 예외가 발생하였다.
예외:can only instantiate non-static inner class by using default no-argument constructor
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
@Getter
@Setter
@ToString
public class Outer {
@Getter
@Setter
@ToString
@NoArgsConstructor
public class Inner1{
private String[] a;
private double[] b;
}
@Getter
@Setter
@ToString
@NoArgsConstructor
public class Inner2{
private String[] a;
}
private long id;
private Inner1[] a;
private Inner2[] b;
private int status;
}
|
cs |
무슨 일 일까? 분명 매개변수 없는 생성자로 생성하였는데, 위와 같은 예외가 발생했다니... 원인은 바로 Inner Class가 static(정적)으로 선언되지 않는 한 단독(Outer 클래스를 참조하지 않고)으로 Inner Class의 디폴트 생성자를 호출해 인스턴스를 생성할 수 없는 것이다. 즉, 위와 같은 예외를 피하려면 Inner Class를 별도의 클래스로 생성하던가, 아니면 static Inner Class로 선언해주어야 한다.
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - JVM이란? JVM 메모리 구조 (1) | 2019.07.29 |
|---|---|
| Eclipse - Archive for required library 해결방법 (0) | 2019.06.18 |
| Java - lambda(람다) 간단한 사용법 ! (0) | 2019.03.10 |
| Java - Collections.rotate() 란? (0) | 2019.02.25 |
| Java - ThreadLocal 이란? 쓰레드로컬 사용법! (0) | 2019.02.21 |

개발환경 또는 테스트를 진행하기 위해서는 엘라스틱서치의 단일 노드로도 충분하다. 그래서 엘라스틱서치 노드는 기본적으로 싱글 노드에서 모든 역할을 수행할 수 있게 설정하는 것이 가능하다. 하지만 실제 운영환경에서는 대부분 다수의 노드를 클러스터링하여 구성하기 때문에 각각 목적에 맞는 노드를 적절히 설정해 운영하는 것이 유리하다.
엘라스틱서치 노드의 종류
elasticsearch.yml 파일에는 노드 관련 속성이 제공된다. 이 속성들을 적절히 조합해서 특정 모드로 설정하는 것이 가능하다.
- node.master : 마스터 기능 활성화 여부
- node.data : 데이터 기능 활성화 여부
- node.ingest : Ingest 기능 활성화 여부
- search.remote.connect : 외부 클러스터 접속 가능 여부
위의 설정들을 조합하여 아래와 같은 노드 모드로 운영가능하다.
- Single Node mode
- Master Node mode
- Data Node mode
- Ingest Node mode
- Coordination Node mode
Single Node mode
모든 기능을 수행하는 모드다. 기본 설정으로 지정돼 있기 때문에 elasticsearch.yml 파일에 아무런 설정을 하지 않는다면 기본적으로 싱글모드로 동작한다.
node.master: true / node.data: true / node.ingest: true / search.remote.connect: true
검색 클러스터의 규모가 작을 때는 노드별로 별도의 Role을 분담하여 운영하기 보다는 모든 노드가 싱글 모드로 수행하게 하는 것이 좋다. 일반적으로 3대 이하의 소규모 클러스터를 구축한다면 모든 엘라스틱서치 노드를 싱글모드로 동작시키는 것이 좋다.
Master Node mode
클러스터의 제어를 담당하는 모드이다.
node.master: true / node.data: false / node.ingest: false / search.remote.connect: false
마스터 모드는 기본적으로 인덱스 생성/변경/삭제 등의 역할을 담당한다. 그리고 분산코디네이터 역할을 담당하여 클러스터를 구성하는 노드의 상태를 주기적으로 점검하여 장애를 대비한다. 즉, 마스터 모드는 클러스터 전체를 관장하는 마스터 역할을 수행하게 된다. 이처럼 중요한 역할을 하는 마스터 노드는 클러스터에 다수 존재하는 것이 좋다. 그래야 장애가 발생할 경우에도 후보 마스터 노드가 역할을 위임받아 안정적으로 클러스터 운영 유지가 되기 때문이다.
Data Node mode
클러스터의 데이터를 보관하고 데이터의 CRUD, 검색, 집계 등 데이터 관련 작업을 담당하는 모드이다.
node.master: false / node.data: true / node.ingest: false / search.remote.connect: false
노드가 데이터 모드로 동작하면 내부에 색인된 데이터가 저장된다. 이말은 즉, 마스터 노드와는 달리 대용량의 저장소를 필수적으로 갖춰야한다.(물론 대용량 서비스 운영환경이라면) 또한 CRUD 작업과 검색, 집계와 같은 리소스를 제법 잡아먹는 역할도 수행하기 때문에 디스크만이 아닌 전체적인 스펙을 갖춘 서버로 운영하는 것이 좋다.
Ingest Node mode
다양한 형태의 데이터를 색인할 때 데이터의 전처리를 담당하는 모드다.
node.master: false / node.data: false / node.ingest: true / search.remote.connect: false
엘라스틱서치에서 데이터를 색인하려면 인덱스라는(RDB Schema) 틀을 생성해야한다. 비정형 데이터를 다루는 저장소로 볼 수 있지만 일정한 형태의 인덱스를 생성해주어야한다. 그리고 해당 인덱스에는 여러 포맷의 데이터 타입 필드가 존재한다. 만약 데이터를 색인할때 간단한 포맷 변경이나 유효성 검증 같은 전처리가 필요할 때 해당 모드를 이용할 수 있다.
Coordination Node mode
사용자 요청을 받아 처리하는 코디네이터 모드이다.
node.master: false / node.data: false / node.ingest: false / search.remote.connect: false
엘라스틱서치의 모든 노드는 기본적으로 코디네이션 모드 노드이다. 이 말은 즉, 모든 노드가 사용자의 요청을 받아 처리할 수 있다는 뜻이다. 하지만 이렇게 별도의 코디네이션 노드가 필요한 이유가 있을까? 싱글 모드로 구성된 클러스터에 사용자가 검색 요청을 보낸다면 검색요청을 받은 노드는 클러스터에 존재하는 모든 데이터 노드에게(싱글 모드는 모든 노드가 대상) 검색을 요청한다. 왜냐하면 클러스터에 존재하는 모든 데이터 노드에 샤드로 데이터가 분산되어 있기 때문이다. 그리고 각 샤드는 자신이 가지고 있는 데이터 내에서 검색을 수행하고 자신에게 요청을 보낸 노드에서 결과값을 전송한다. 그리고 모든 데이터를 취합하여 사용자에게 전달한다. 모든 데이터가 취합될때까지 요청을 다른 노드에게 보낸 코디네이션 노드역할(싱글모드에서는 코디네이션 이외의 모든일을 하는 노드가 된다.)을 하는 노드는 아무 일도 못하고 기다리고 있어야한다. 또한 데이터를 취합하는 일도 많은 양의 메모리가 필요한 작업이다. 이 상황에서 코디네이션 노드를 따로 구축하지 않았다면 이렇게 결과를 취합하는 과정에 마스터 노드로서의 역할이나 데이터 노드로서의 역할을 할 수 없게 되고 최악의 경우에는 노드에 장애가 발생할 수 있다. 이렇게 다른 노드들에게 요청을 분산하고 결과값을 취합하는 코디네이션 노드를 별도로 구축한다면 안정적인 클러스터 운영이 가능해진다.
대용량 클러스터 환경에서 전용 마스터 노드 구축이 필요한 이유
예를 들어보자. 만약 모든 노드를 싱글모드로 클러스터링을 구축한 환경에서 무거운 쿼리가 주 마스터 역할을 하는 싱글 노드에 요청되어 데이터 노드의 부하로 인해 시스템에 순간적으로 행(hang, freezing 시스템이 아무런 일도 하지 못하는 상황)이 걸리거나 노드가 다운되는 경우가 발생할 수 있다. 그렇다면 주 마스터 역할로써도 정상적으로 동작하지 못할 것이다. 이 순간 시스템 장애가 발생하면 쉽게 복구할 수 있는 상황도 복구할 수 없게되는 상황이 발생한다.
이러한 경우 다른 싱글 노드 중 하나가 마스터 역할로 전환되어 처리되지 않을 까라는 생각을 당연히 하게 되지만 모든 상황에서 그렇지는 않다. 주 마스터 노드가 hang 상태에 빠져있지만 시스템적으로 정상적으로 프로세스로 떠 있다 판단 될 수 있어 다른 후보 마스터에게 역할이 위임되지 않을 가능성이 있기 때문이다.
이렇게 마스터 노드와 데이터 노드의 분리는 대용량 클러스터 환경에서 필수이게 되는 것이다.
대용량 클러스터 환경에서의 검색엔진에서 코디네이션 노드 구축이 필요한 이유
엄청난 데이터량을 가지고 있는 클러스터를 가지고 있다고 생각해보자. 만약 이러한 클러스터에서 복잡한 집계 쿼리를 날린다고 가정하면 안그래도 리소스를 많이 잡아먹는 집계쿼리인데 데이터마저 크다면 엄청난 부하를 주게 될 것이다. 이런 상황에서 데이터 노드 모드와 코디네이션 노드 모드를 분리하여 클러스터 환경을 구성한다면 장애가 발생할 가능성이 조금은 낮아질 것이다. 왜냐 검색은 데이터노드가 담당하고 이러한 요청을 보내는 역할과 결과의 병합을 코디네이션 노드가 담당하기에 리소스 사용의 부담을 서로 나누어 갖기 때문이다.
클러스터 Split Brain 문제 방지
클러스터에는 마스터 노드 모드로 설정된 노드가 최소한 하나 이상 존재해야 장애가 발생하였을 때, 즉시 복구가 가능해진다. 다수의 마스터 노드가 존재할 경우 모든 마스터 노드들은 투표를 통해 하나의 마스터 노드만 마스터 노드로서 동작하고 나머지는 후보 마스터 노드로서 대기한다. 클러스터를 운영하는 중에 마스터 노드에 장애가 발생할 경우 대기 중인 후보 마스터 노드 중에서 투표를 통해 최종적으로 하나의 후보 마스터 노드가 주 마스터 노드로 승격하게 된다. 이후 장애가 발생한 주 마스터노드는 다시 후보 마스터 노드로 하락하게 된다. 이런식으로 마스터 노드의 부재없이 안정적인 클러스터 운영이 가능한 것이다.
그렇다면 전용으로 구축되는 마스터 노드는 몇개가 적당할까?
이런 상황을 생각해보자. 만약 주 마스터 노드에 장애가 발생하였고 후보 마스터 노드 3개 중 투표를 통해 하나의 마스터 노드를 선출하는 도중에 네트워크 환경에 단절이 발생했다 생각하자. 그렇다면 후보노드들은 모두 나 자신밖에 마스터노드 후보가 없다고 생각하고 자기 자신을 마스터 노드로 승격시킬 것이고, 각 노드가 동일하게 행동하여 하나 이상의 마스터 노드가 생겨버릴 수 있다.(Split Brain 문제) 이렇다면 클러스터는 엉망진창으로 꼬일 것이고 서비스 불능 상태가 될 수 있다. Split Brain 문제는 비단 엘라스틱서치만의 문제는 아니고 클러스터 환경에서 운영되는 애플리케이션 전반적인 문제이다. 엘라스틱서치는 이 상황을 하나의 설정만으로 해결방법을 제시한다.
elasticsearch.yml -> discovery.zen.minimum_master_nodes
이 속성은 기본 값으로 1을 가진다. 이 뜻은 마스터 노드 선출 투표를 진행할 때, 후보 마스터 노드의 최소한의 갯수를 뜻하는 것이다. 클러스터에 존재하는 마스터 노드의 개수가 1개이거나 2개일 경우는 해당 설정은 1로 설정하고 마스터 노드의 수가 3개 이상일 경우에는 다음 공식에 대입해서 적절한 값을 찾아 설정한다.
(마스터 후보 노드 수 / 2) + 1
- 마스터 노드가 3개일 경우 : 3/2+1 = 2
- 마스터 노드가 4개일 경우 : 4/2+1 = 3
- 마스터 노드가 5개일 경우 : 5/2+1 = 3
- 마스터 노드가 6개일 경우 : 6/2+1 = 4
싱글모드노드로 구성하는 간단한 클러스터링
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
<node1>
cluster.name: clusterName
node.name: node1
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9500"]
discovery.zen.minimum_master_nodes: 1
transport.tcp.port: 9300
#########싱글 노드로 동작 여부#########
node.master: true
node.data: true
node.ingest: true
search.remote.connect: true
<node2>
cluster.name: clusterName
node.name: node1
network.host: 0.0.0.0
http.port: 9400
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"]
discovery.zen.minimum_master_nodes: 1
transport.tcp.port: 5300
#########싱글 노드로 동작 여부#########
node.master: true
node.data: true
node.ingest: true
search.remote.connect: true
|
cs |
두개의 엘라스틱서치 디렉토리를 준비한 후에 각각의 설정 파일을 위와 같이 바꾸어준다. 우선 중요한 것은 cluster.name을 동일하게 마추어줘야한다. 그리고 포트는 적절히 할당해준다. 필자는 동일한 서버환경에서 두개의 노드를 설치한 것이라 포트가 다르지만 서로 다른 환경이라면 동일하게 포트를 맞춰놔도 무방하다. 그리고 중요한 것은 discovery 설정이다. 디스커버리 설정으로 서로다른 노드를 discovery할 수 있게 해주는 설정인 것이다. 그리고 모든 노드가 싱글모드로 동작시키게 하기 위해 싱글 노드 설정으로 세팅해주었다.
설정파일을 모두 변경하였으면 각각 엘라스틱서치를 실행 시킨 후에 아래의 요청을 보내 클러스터링이 잘 걸렸나 확인해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
GET http://localhost:9200/_cluster/health
result ->
{
"cluster_name": "clusterName",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
|
cs |
필자는 클러스터 설정이 모두 정상적으로 적용되어 Active한 노드가 2개인것을 볼 수 있다. 물론 완벽한 클러스터링을 위해서는 설정해야 할것이 많을 수도 있다. 그리고 지금은 개발모드로 작성되어 부트스트랩과정을 거치지 않아서 쉽게 구성되었을 것이다. 하지만 추후에 운영환경모드로 실행을 하면 14가지정도의 부트스트랩 과정을 검사하기 때문에 맞춰주어야 하는 설정들이 많이 있다. 더 자세한 클러스터링 환경설정은 추후에 다루어볼 것이다.
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| ELK Stack - Logstash(로그스태시)를 이용한 로그 수집 (1) | 2019.06.26 |
|---|---|
| ELK Stack - Filebeat(파일비트)란? 간단한 사용법 (1) | 2019.06.17 |
| Elasticsearch - 엘라스틱서치 자바 힙 메모리 변경(JVM Heap) (0) | 2019.06.08 |
| Elasticsearch - 엘라스틱서치와 루씬의 관계 - 2(세그먼트 불변성,Translog) (1) | 2019.05.25 |
| Elasticsearch - 엘라스틱서치와 루씬의 관계 - 1 (1) | 2019.05.25 |