
'2019/09'에 해당되는 글 33건
- 2019.09.24 :: Git - Mac OS, Git pull 명령 후 non-fast-forward 문제 해결방법
- 2019.09.24 :: Git - Mac OS, Github remote:Permission to 에러
- 2019.09.21 :: DB - MongoDB 맵리듀스(Map Reduce)
- 2019.09.20 :: Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3
- 2019.09.20 :: Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2 1
- 2019.09.19 :: Elasticsearch - Aggregation API(엘라스틱서치 집계,메트릭(Metric Aggregations) 집계) -1
- 2019.09.19 :: DB - MongoDB FindAndModify 란?
- 2019.09.19 :: DB - MongoDB OperationFailed Sort operation used more than the maximum 33554432 bytes of Ram.
현상
github에서 저장소 생성 후 저장소 주소를 remote에 입력(git remote add origin https://github…..)했고, 로컬에서도 정상적으로 초기화(git init)했는데도 git pull 또는 git merge 명령이 동작하지 않고 git push origin master시 [rejected] master -> master (non-fast-forward)이런 에러가 발생하는 경우
원인
깃허브에 생성된 원격 저장소와 로컬에 생성된 저장소 간 공통분모가 없는 상태에서 병합하려는 시도로 인해 발생. 기본적으로 관련 없는 두 저장소를 병합하는 것은 안되도록 설정되어 있음.
해결방법
아래와 같이 git pull 시에 –allow-unrelated-histories 옵션 추가하여 관련 없었던 두 저장소를 병합하도록 허용
'Tools > Git&GitHub' 카테고리의 다른 글
| Git - .gitignore가 작동하지 않을때(.gitignore가 안먹을때) (0) | 2020.03.26 |
|---|---|
| Git - 특정 브랜치(branch)만 clone하는 명령어 (0) | 2019.10.15 |
| Git - Mac OS, Github remote:Permission to 에러 (0) | 2019.09.24 |
| GitHub - github를 maven repository로 사용하기(깃허브를 메이븐 레포지토리로 사용하기) (0) | 2019.02.22 |
| Github - eclipse(이클립스)와 local repository(로컬레포지토리) 연동. (0) | 2019.02.16 |
remote: Permission to 403
remote: Permission to ~ denied to id(xxx).
fatal: unable to access 'https://github.com/~': The requested URL returned error: 403
a라는 github 아이디로 '최초' 글로벌 유저를 등록 후 b라는 github 아이디로 글로벌유저를 등록 후 git push를 하게 되면 기존에 최초 등록한 a아이디를 바라보고 있기에 에러를 발생시키는 것이었습니다.
- spolight 검색을 통해 keychain Access.app 또는 키체인 접근을 실행합니다.
- 오른쪽 상단에 검색창에 github.com 을 검색합니다.
- 리스트에 보이는 github.com 더블클릭 후 계정과 암호를 현재 사용할 깃허브의 계정과 암호로 입력합니다.
- 변경사항 저장을 누르고 창닫기
에러메세지에서 익숙했던 xxx(id)는 최초 등록했던 id였고 현재 작업하고 있는 mac에서 키체인 자격을 업데이트를 하여 해결할 수 있었습니다.
'Tools > Git&GitHub' 카테고리의 다른 글
| Git - 특정 브랜치(branch)만 clone하는 명령어 (0) | 2019.10.15 |
|---|---|
| Git - Mac OS, Git pull 명령 후 non-fast-forward 문제 해결방법 (0) | 2019.09.24 |
| GitHub - github를 maven repository로 사용하기(깃허브를 메이븐 레포지토리로 사용하기) (0) | 2019.02.22 |
| Github - eclipse(이클립스)와 local repository(로컬레포지토리) 연동. (0) | 2019.02.16 |
| GitHub - Git 사용법 2 (명령어,branch, checkout, reset 등) (0) | 2019.02.12 |

몽고디비 서버에서도 다른 대용량 분산 NoSQL DBMS처럼 맵리듀스 기능을 제공한다. 맵리듀스와 유사한 집계(Aggregations)기능도 제공하지만 더욱 복잡한 패턴의 분석은 맵리듀스 기능이 필요 할 수도 있다. 몽고디비의 맵리듀스는 자바스크립트 언어의 문법을 사용하여 구현한다. 즉, 내부적으로는 자바스크립트 엔진을 이용한다는 뜻이다. 몽고디비가 현재까지 SpiderMonkey, V8 등의 자바스크립트 엔진을 사용했지만 현재는 SpiderMonkey 엔진을 기본으로 사용한다. 두 엔진의 차이가 여기서 이야기할 내용은 아니지만 간단히 아래와 같은 차이를 갖는다.
V8 엔진은 멀티 프로세스 방식이며, SpiderMonkey는 단일 프로세스 내에서 멀티 스레드로 작동한다.
어찌됬든 몽고디비에서 성능이 더 나은 엔진을 선택했을 것이다. 내부적으로 도큐먼트를 자바스크립트 변수로 매핑하고 자바스크립트로 여러가지 맵리듀스 과정을 거쳐 최종적으로 다시 몽고디비 문서로 생성되는 것이다.
아래 이미지는 공식 레퍼런스에 있는 맵리듀스 과정을 도식화한 것이다.
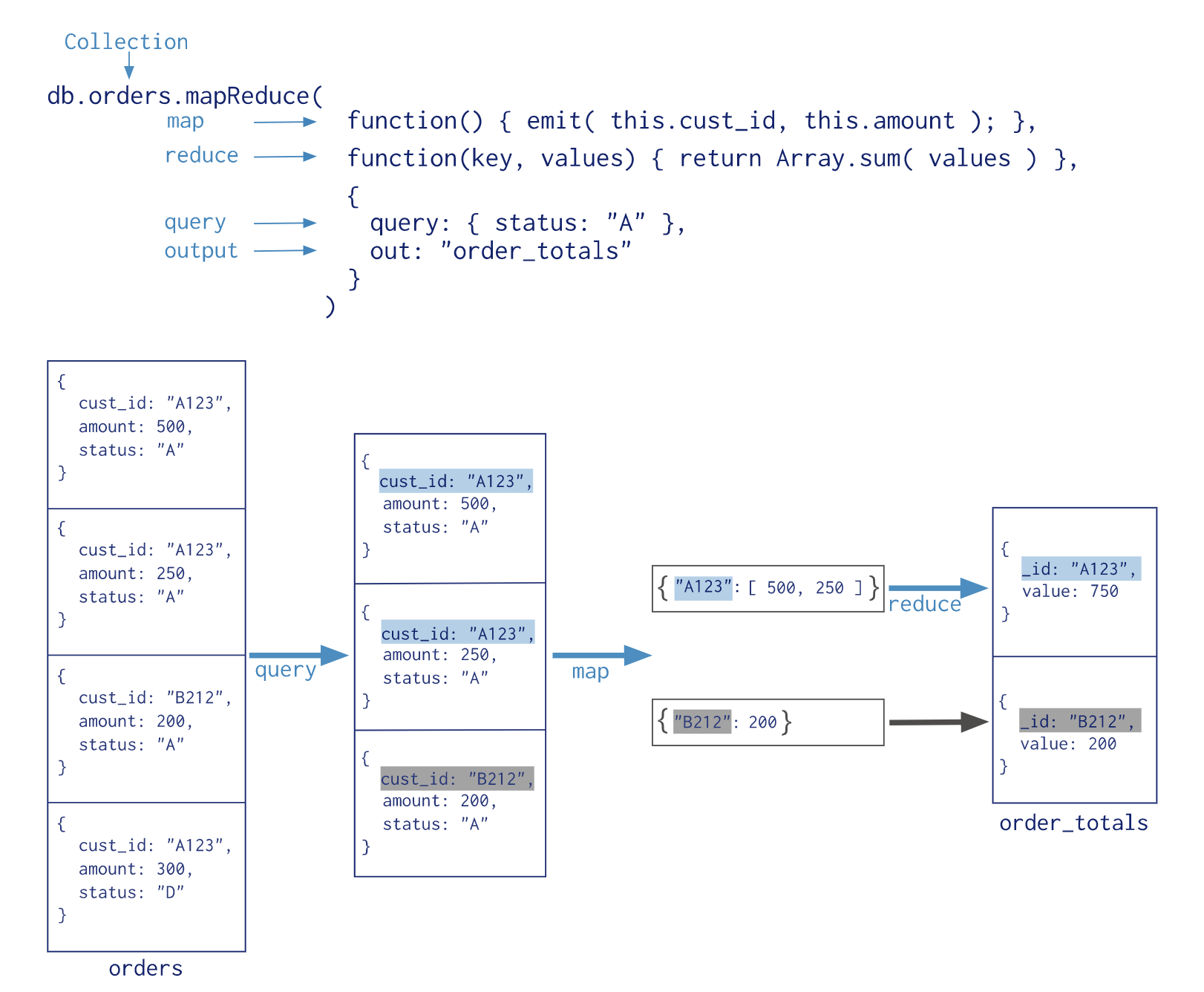
결론적으로는 map 과정에서 emit이라는 함수를 호출하는데, 키로 사용될 필드, 값으로 사용될 필드를 인자로 넣어준다. 그러면 내부적으로 같은 키값에 대한 여러개의 값을 배열로 가지고 있게 되고 이후 reduce 과정에서 해당 키와 값배열을 받아 reduce 연산(이밎에서는 Array.sum(values)라는 합산 연산)을 실행한 후 결과 문서를 출력 혹은 별도 컬렉션의 저장등의 작업을 수행한다. 여기서 키와 값은 스칼라 값일 수도 있고, 문서 혹은 서브도큐먼트 일수도 있다.
그러면 mapReduce에서 사용하는 각종 옵션에 대해 알아보자.
> db.collection.mapReduce(
<map>
,<reduce>
{
out: <collection>
,query:<document>
,sort:<document>
,limit:<number>
,finalize:<function>
,scope:<document>
,jsMode:<boolean>
,verbose:<boolean>
}
)
| 옵션 | 설명 |
| out | 맵리듀스 명령의 결과를 저장하거나 출력할 위치를 명시하는데, out 인자에는 문자열 또는 도큐먼트를 설정할 수 있다. |
| query | 맵리듀스 명령을 실행할 대상 문서를 검색하는 조건을 명시한다. query 옵션에는 일반적인 find 명령의 검색 조건과 동일한 오퍼레이터를 활용할 수 있으며, 쿼리의 검색 성능이나 인덱스 활용도 find 명령과 동일한 방식으로 작동한다. 풀스캔보다는 인덱스를 활용하여 검색 성능을 향상시키는 것이 좋다. |
| sort | 맵리듀스 명령을 실행할 대상 문서를 먼저 정렬해서 맵리듀스 엔진으로 전달하고자 할 때에는 sort 옵션을 사용한다. 맵리듀스 엔진은 key 필드의 값으로 정렬을 수행하는데, sort 옵션을 사용하여 인덱스를 활용한 정렬을 수행할 수 있다면 맵리듀스 엔진의 정렬에 드는 부하를 줄일 수 있다. |
| limit | 맵리듀스 엔진으로 전달할 문서의 개수를 설정한다. |
| finalize | 대게 맵리듀스는 map과 reduce 함수로 이루어지는데, reduce함수의 결과를 다시 한번 가공해 최종결과를 만들고 싶다면 finalize 함수를 이용한다. |
| scope | map과 reduce 함수 그리고 finalize 함수에서 접근할 수 있는 글로벌 변수를 정의한다. 보통은 map&reduce에는 인자로 전달된 값만 이용할 수 있으므로 모든 문서가 공유할 변수값등이 필요하면 scope를 이용하면 된다. |
| jsMode | 몽고디비 맵리듀스 엔진은 map이나 reduce 함수로 전달되는 문서를 계속해서 몽고디비서버와 자바스크립트 엔진 사이에서 변환 작업을 한다. 이는 맵리듀스 처리과정에 상당한 성능 저하를 일으키는데, jsMode를 true로 설정하면 중간 과정의 데이터를 메모리에 모두 보관한다. 더 빠른 처리가 가능하지만 그만큼 메모리를 많이 먹는 작업이다. 처리하는 문서가 50만건을 초과하면 jsMode를 true로 설정할 수 없다. jsMode는 기본값이 false이다. |
| verbose | 맵리듀스의 처리 결과에 단계별 처리 과정 및 소요 시간에 대한 정보를 포함할 것인지 결정한다. 기본값은 true이다. |
밑은 간단하게 out에 적용할 수 있는 옵션에 대한 설명이다.
| out 옵션 | 설명 |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: {inline:1}} ); |
맵리듀스 결과를 화면 혹은 클라이언트 명령의 결과로 전달한다. |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: "collection"} ); |
맵리듀스의 결과를 collection이라는 이름의 컬렉션으로 저장한다. |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: {replace:"collection"}} ); |
collection이라는 컬렉션이 이미 존재한다면 기존 내용을 모두 삭제하고, 맵리듀스 명령의 결과를 해당 컬렉션에 저장한다. |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: {merge:"collection"}} ); |
collection이라는 컬렉션이 이미 존재하고, 프라이머리 키가 동일한 문서가 존재한다면 맵리듀스의 결과로 그 문서를 덮어쓰기 한다. |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: {reduce:"collection"}} ); |
collection이라는 컬렉션이 이미 존재하고, 프라이머리 키가 동일한 문서가 존재한다면 맵리듀스의 결과와 기존 문서를 이용해서 다시 맵리듀스를 실행해서 결과를 저장한다. 즉, reduce 타입의 out은 incremental 맵리듀스를 실행할 때 사용한다. |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: {replace:"collection", db: database}} ); |
맵리듀스의 결과를 새로운 database라는 데이터베이스의 collection 컬렉션에 저장한다. |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: {replace:"collection", sharded:true}} ); |
맵리듀스의 결과를 collection 컬렉션에 저장하고, 이때 collection 컬렉션을 _id 필드를 기준으로 샤딩한 다음 결과를 저장한다. 4.2 버전 기준으로 해당 옵션은 deprecated 됬다. 현재는 샤딩된 컬렉션으로 출력하기 위해서는 미리 먼저 샤딩된 컬렉션을 생성해야한다. |
|
> db.collection.mapReduce(mapFunction, reduceFunction, {out: {merge:"collection", nonAtomic:true}} ); |
맵리듀스의 결과를 collection 컬렉션에 저장할 때 원자 단위로 처리한다. |
참고로 nonAtomic 옵션은 merge나 reduce 방식의 out에만 적용할 수 있는 옵션이며, 기본값은 false이다. 만약 nonAtomic 옵션을 false로 지정하면 맵리듀스 처리결과를 컬렉션에 저장할 때, 데이터베이스 레벨의 잠금을 걸게된다. nonAtomic이 true라면 물론 데이터베이스 잠금이 걸리지만, 적절히 잠금을 해제(Yield)했다가 다시 잠금을 걸면서 처리한다. 해당 옵션은 상황에 따라 적용하면 될듯하다. 만약 잠금이 걸려있다면 다른 커넥션에서 조회 변경 등을 할 수 없다.
Map-Reduce And Sharded Collection
-Sharded Collection as Input
맵리듀스 작업의 입력으로 샤딩된 컬렉션을 이용할 때, 몽고디비서버는 각 샤드에 맵리듀스 작업을 자동으로 병렬 전송한다. 입력으로 샤딩된 컬렉션을 이용하기 위해 별도의 옵션은 필요하지 않고 몽고디비서버는 모든 작업이 끝날 때까지 기다린다.
-Sharded Collection as output
sharded 옵션이 true라면, 몽고디비서버는 _id 필드 값 샤딩키로 사용하여 맵리듀스 결과 출력 컬렉션을 샤딩한다.
샤딩된 컬렉션으로 출력을 하려면 아래와 같은 조건을 지켜줘야한다.
- 맵리듀스 결과로 출력할 컬렉션이 존재하지 않는다면, 먼저 샤딩된 컬렉션을 생성해야한다. 4.2버전 기준의 몽고디비는 맵리듀스 옵션으로 새로운 샤딩된 컬렉션을 생성하는 것이 deprecated됬고, sharded 옵션 사용도 deprecated됬다. 즉, 샤딩된 컬렉션을 출력 컬렉션으로 사용하고 싶다면 맵리듀스 작업 이전에 먼저 샤딩된 컬렉션을 생성해야한다. 물론 현재 샤딩된 컬레션이 존재하지 않으면, _id 필드값을 기준으로 샤딩된 컬렉션을 생성하긴 하지만 공식적으로 추천하지 않는 방법이다.
- 4.2버전 몽고디비서버부터 이미 존재하는 샤딩된 컬렉션을 replacement하는 방식은 deprecated됬다.
- 버전 4.0부터 출력 컬렉션이 이미 있지만 샤딩되지 않은 경우 map-reduce가 실패한다.
- 새롭게 생성된 샤딩된 컬렉션 또는 비어있는 샤딩된 컬렉션의 경우 MongoDB는 맵리듀스 작업의 첫 단계 결과를 사용하여 샤드에 분산 된 초기 청크를 만듭니다.
- 몽고디비서버는 출력 후처리를 모든 샤드에 병렬로 수행한다.
Map-Recuce Concurrency
맵리듀스 작업에는 많은 작업들이 있는데, 각 작업마다 동시성을 위한 락이 걸린다. 각 단계에 대한 락은 아래와 같다.
- The read phase takes a read lock. It yields every 100 documents.
- The insert into the temporary collection takes a write lock for a single write.
- If the output collection does not exist, the creation of the output collection takes a write lock.
- If the output collection exists, then the output actions (i.e. merge, replace, reduce) take a write lock. This write lock is global, and blocks all operations on the mongod instance.
- 읽기 단계는 읽기 잠금을 수행한다. 100개 문서마다 잠금을 해제한다.
- 임시 콜렉션에 삽입하면 단일 쓰기에 대한 쓰기 잠금이 사용된다.
- 출력 콜렉션이 존재하지 않으면 출력 콜렉션 작성에 쓰기 잠금이 사용됩니다. 출
- 력 콜렉션이 존재하면 출력 조치 (즉, 병합, 대체, 리듀스)가 쓰기 잠금을 수행합니다. 이 쓰기 잠금은 전역 적이며 mongod 인스턴스의 모든 작업을 차단합니다.
위 설명은 간단히 전체 문서를 한번에 읽고 작업하는 것이 아니라 일정 크기의 데이터를 잘라서 맵리듀스 작업을 한다라고 생각하면 된다. 작업을 잘라서 수행하기 때문에 일부 문서들을 map하여 reduce한 다음에 결과를 임시 저장소에 보관했다가 나중에 다시 reduce가 수행될때 동일한 key를 가진 중간 결과가 있으면 같이 모아 reduce를 수행한다.
최종 출력에서 merge나 reduce 작업은 문서의 양의 따라 상당히 많은 시간이 걸릴 수 있다. 즉, 오랜 시간동안 락이 걸리면 안되기 때문에 nonAtomic 옵션을 true로 주어서 잠금을 해제하고 잠금을 다시 걸고 하는 방식으로 작업을 해줘야한다. 즉, merge&reduce 출력 옵션은 nonAtomic 옵션을 true로 하길 권장한다.
Map-Reduce 예제
|
1
2
3
4
5
6
7
8
9
|
db.orders.insert({
... _id: ObjectId("50a8240b927d5d8b5891743c"),
... cust_id: "abc123",
... ord_date: new Date("Oct 04, 2012"),
... status: 'A',
... price: 25,
... items: [ { sku: "mmm", qty: 5, price: 2.5 },
... { sku: "nnn", qty: 5, price: 2.5 } ]
... });
|
cs |
위 문서를 삽입한다. 위 문서를 삽입한 후에 소비자별 총액을 구하는 맵리듀스 연산을 해보도록 할 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
> var mapFunction1 = function() {
... emit(this.cust_id, this.price);
... };
> var reduceFunction1 = function(keyCustId, valuesPrices) {
... return Array.sum(valuesPrices);
... };
> db.orders.mapReduce(
... mapFunction1,
... reduceFunction1,
... { out: "map_reduce_example" }
... )
{
"result" : "map_reduce_example",
"timeMillis" : 76,
"counts" : {
"input" : 1,
"emit" : 1,
"reduce" : 0,
"output" : 1
},
"ok" : 1
}
->result
> db.map_reduce_example.find()
{ "_id" : "abc123", "value" : 25 }
|
cs |
위는 소비자별 금액 총액을 구하는 맵리듀스 연산이고 결과를 map_reduce_example이라는 새로운 컬렉션에 저장하는 예제이다. 우선 각 단계별로 사용법을 살펴보자.
-Map
mapFunction1이라는 변수에 함수를 정의한다. emit이라는 함수는 특정 키값별로 값을 그룹핑하는 함수이다. 여기서 this 연산자는 map 작업에 사용될 문서를 참조하는 키워드이다. 즉, cust_id 별로 price를 배열로 그룹핑하고 있다.
-Reduce
reduceFunction1이라는 변수에 함수를 정의한다. 이 함수는 그룹핑된 문서들의 값을 조작하는 함수이다. 즉, 결과값을 가공하는 단계라고 보면 된다. 인자의 keyCustId와 valuesPrices는 Map 단계에서 그룹핑된 키와 값의 배열을 인자로 받고 있다.
-output
db.orders.mapReduce 명령으로 우리가 정의한 Map함수와 Reduce함수를 전달하여 작업을 수행한 후 map_reduce_example이라는 컬렉션을 새로 생성하여 결과값을 저장한다.
문서하나로는 부족하니 3개의 문서를 더 삽입하여 다시 실행해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
> db.orders.insertMany([{
... cust_id: "abc123",
... ord_date: new Date("Oct 04, 2012"),
... status: 'A',
... price: 40,
... items: [ { sku: "mmm", qty: 5, price: 2.5 },
... { sku: "nnn", qty: 5, price: 2.5 } ]
... },
... {
... cust_id: "abc123",
... ord_date: new Date("Oct 04, 2012"),
... status: 'A',
... price: 25,
... items: [ { sku: "mmm", qty: 5, price: 2.5 },
... { sku: "nnn", qty: 5, price: 2.5 } ]
... },
... {
... cust_id: "abc123",
... ord_date: new Date("Oct 04, 2012"),
... status: 'A',
... price: 10,
... items: [ { sku: "mmm", qty: 5, price: 2.5 },
... { sku: "nnn", qty: 5, price: 2.5 } ]
... }]);
> var mapFunction1 = function() {emit(this.cust_id, this.price)};
> var reduceFunction1 = function(keyCustId, valuesPrices) {return Array.sum(valuesPrices);};
> db.orders.mapReduce(mapFunction1,reduceFunction1,{ out: "map_reduce_example"});
{
"result" : "map_reduce_example",
"timeMillis" : 47,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 1,
"output" : 1
},
"ok" : 1
}
> db.map_reduce_example.find()
{ "_id" : "abc123", "value" : 100 }
|
cs |
4개의 문서의 price를 모두 더하고 있다. 다음은 replace 출력이다. 기존 맵리듀스 결과를 저장하는 컬렉션에 더미 데이터를 하나 삽입하고 맵리듀스를 다시 실행시켰다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
> db.map_reduce_example.insert({description:"dummy data"});
WriteResult({ "nInserted" : 1 })
> db.map_reduce_example.find()
{ "_id" : "abc123", "value" : 100 }
{ "_id" : ObjectId("5d859b0b9ca9d5ca23a3447e"), "description" : "dummy data" }
> var mapFunction1 = function() { emit(this.cust_id, this.price); };
> var reduceFunction1 = function(keyCustId, valuesPrices) { return Array.sum(valuesPrices); };
> db.orders.mapReduce(mapFunction1,reduceFunction1,{out:{replace:"map_reduce_example"}});
{
"result" : "map_reduce_example",
"timeMillis" : 44,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 1,
"output" : 1
},
"ok" : 1
}
> db.map_reduce_example.find()
{ "_id" : "abc123", "value" : 100 }
|
cs |
기존 컬렉션의 데이터를 모두 지우고 새로운 맵리듀스 결과를 삽입하였다. 다음은 merge 출력이다. orders 컬렉션에 하나의 문서를 추가했고 map_reduce_example에 역시 더미 데이터를 하나 삽입하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
> db.map_reduce_example.insert({description:"dummy data"});
WriteResult({ "nInserted" : 1 })
> db.orders.insertOne({cust_id:"abc123",price:20});
{
"acknowledged" : true,
"insertedId" : ObjectId("5d859bdd9ca9d5ca23a34480")
}
> var mapFunction1 = function() { emit(this.cust_id, this.price); };
> var reduceFunction1 = function(keyCustId, valuesPrices) { return Array.sum(valuesPrices); };
> db.orders.mapReduce(mapFunction1,reduceFunction1,{out:{merge:"map_reduce_example"}});
{
"result" : "map_reduce_example",
"timeMillis" : 47,
"counts" : {
"input" : 5,
"emit" : 5,
"reduce" : 1,
"output" : 2
},
"ok" : 1
}
> db.map_reduce_example.find()
{ "_id" : "abc123", "value" : 120 }
{ "_id" : ObjectId("5d859bbf9ca9d5ca23a3447f"), "description" : "dummy data" }
|
cs |
기존의 더미 데이터는 그대로 남아있고 새로운 결과를 기존 문서에 병합하였다. 마지막은 reduce 출력이다. orders 컬렉션에 새로운 문서하나를 삽입하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
> db.orders.insertOne({cust_id:"abc123",price:30});
{
"acknowledged" : true,
"insertedId" : ObjectId("5d859c8c9ca9d5ca23a34481")
}
> var mapFunction1 = function() { emit(this.cust_id, this.price); };
> var reduceFunction1 = function(keyCustId, valuesPrices) { return Array.sum(valuesPrices); };
> db.orders.mapReduce(mapFunction1,reduceFunction1,{out:{reduce:"map_reduce_example"}});
{
"result" : "map_reduce_example",
"timeMillis" : 39,
"counts" : {
"input" : 6,
"emit" : 6,
"reduce" : 1,
"output" : 2
},
"ok" : 1
}
> db.map_reduce_example.find()
{ "_id" : "abc123", "value" : 270 }
{ "_id" : ObjectId("5d859bbf9ca9d5ca23a3447f"), "description" : "dummy data" }
|
cs |
내가 생각했던 결과와는 조금 다르다. 내가 생각했던 결과를 실제 결과를 보고 다시 생각하니 당연히 내가 생각한 결과가 나올 수가없다. 내가 생각한 결과는 기존에 120이 합산되어있고 price가 30인 문서를 새로 삽입했으니 150이 되겠지 했는데, 결과는 당연히 아니다 맵리듀스결과는 150으로 나오고 기존 120에 150이 합해져 270이라는 결과가 나오는 것이다. 당연하다..맵리듀스 결과 컬렉션에 문서단위로 들어간게 아니니..당연히 120에 150이 더해진다. 보통 incremental 맵리듀스는 날짜등을 기준으로 증분시키면서 사용하면 될듯하다. 역시 바보였다 나는..
다음은 finalize를 통해 맵리듀스 결과를 다시 한번 가공하는 예제이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
> var mapFunction2 = function() {
... for (var idx = 0; idx < this.items.length; idx++) {
... var key = this.items[idx].sku;
... var value = {
... count: 1,
... qty: this.items[idx].qty
... };
... emit(key, value);
... }
... };
> var reduceFunction2 = function(keySKU, countObjVals) {
... reducedVal = { count: 0, qty: 0 };
...
... for (var idx = 0; idx < countObjVals.length; idx++) {
... reducedVal.count += countObjVals[idx].count;
... reducedVal.qty += countObjVals[idx].qty;
... }
...
... return reducedVal;
... };
> var finalizeFunction2 = function (key, reducedVal) {
...
... reducedVal.avg = reducedVal.qty/reducedVal.count;
...
... return reducedVal;
...
... };
> db.orders.mapReduce( mapFunction2,
... reduceFunction2,
... {
... out: { merge: "map_reduce_example" },
... query: { ord_date:
... { $gt: new Date('01/01/2012') }
... },
... finalize: finalizeFunction2
... }
... )
{
"result" : "map_reduce_example",
"timeMillis" : 47,
"counts" : {
"input" : 4,
"emit" : 8,
"reduce" : 2,
"output" : 4
},
"ok" : 1
}
> db.map_reduce_example.find()
{ "_id" : "abc123", "value" : 270 }
{ "_id" : ObjectId("5d859bbf9ca9d5ca23a3447f"), "description" : "dummy data" }
{ "_id" : "mmm", "value" : { "count" : 4, "qty" : 20, "avg" : 5 } }
{ "_id" : "nnn", "value" : { "count" : 4, "qty" : 20, "avg" : 5 } }
|
cs |
-input
입력값을 전체 문서 대상이 아닌 ord_date 값이 2012년1월1일 이후인 문서를 입력값으로 받고 있다.
-Map
item 배열을 하나씩 순회하면서 값을 채워주고 있다. 여기서 value는 하나의 문서로 들어가고 있다. 처음에 설명했듯이 key나 value에는 스칼라 값뿐만 아니라 문서도 들어갈 수 있다.
-Reduce
하나의 key 값에 대해 값을 누적시키고 있다. 각 배열의 요소에는 count가 1과 각자의 qty를 가지고 있고, 해당 값들을 누적시키기 위해서 reducedVal 변수를 초기화했다.
-finalize
맵리듀스의 결과를 키/값으로 받고 해당 값들을 가공하고 있다. 여기서는 평균 수량을 구하기 위한 연산을 수행하고 있고 인자로 들어온 reducedVal에 새로운 필드를 생성하고 평균값을 넣었다.
-output
map_reduce_example 컬렉션으로 결과를 merge한다.
Incremental MapReduce
증분 맵리듀스에 대한 간단한 예제이다. 각 map/reduce/finalize에 대한 설명은 하지 않는다.
|
1
2
3
4
5
6
7
8
9
|
db.sessions.save( { userid: "a", ts: ISODate('2011-11-03 14:17:00'), length: 95 } );
db.sessions.save( { userid: "b", ts: ISODate('2011-11-03 14:23:00'), length: 110 } );
db.sessions.save( { userid: "c", ts: ISODate('2011-11-03 15:02:00'), length: 120 } );
db.sessions.save( { userid: "d", ts: ISODate('2011-11-03 16:45:00'), length: 45 } );
db.sessions.save( { userid: "a", ts: ISODate('2011-11-04 11:05:00'), length: 105 } );
db.sessions.save( { userid: "b", ts: ISODate('2011-11-04 13:14:00'), length: 120 } );
db.sessions.save( { userid: "c", ts: ISODate('2011-11-04 17:00:00'), length: 130 } );
db.sessions.save( { userid: "d", ts: ISODate('2011-11-04 15:37:00'), length: 65 } );
|
cs |
위 문서들을 삽입해준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
> db.sessions.insertMany([db.sessions.save( { userid: "a", ts: ISODate('2011-11-03 14:17:00'), length: 95 } ),
... db.sessions.save( { userid: "b", ts: ISODate('2011-11-03 14:23:00'), length: 110 } ),
... db.sessions.save( { userid: "c", ts: ISODate('2011-11-03 15:02:00'), length: 120 } ),
... db.sessions.save( { userid: "d", ts: ISODate('2011-11-03 16:45:00'), length: 45 } ),
... db.sessions.save( { userid: "a", ts: ISODate('2011-11-04 11:05:00'), length: 105 } ),
... db.sessions.save( { userid: "b", ts: ISODate('2011-11-04 13:14:00'), length: 120 } ),
... db.sessions.save( { userid: "c", ts: ISODate('2011-11-04 17:00:00'), length: 130 } ),
... db.sessions.save( { userid: "d", ts: ISODate('2011-11-04 15:37:00'), length: 65 } )]);
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5d85a1f29ca9d5ca23a3448a"),
ObjectId("5d85a1f29ca9d5ca23a3448b"),
ObjectId("5d85a1f29ca9d5ca23a3448c"),
ObjectId("5d85a1f29ca9d5ca23a3448d"),
ObjectId("5d85a1f29ca9d5ca23a3448e"),
ObjectId("5d85a1f29ca9d5ca23a3448f"),
ObjectId("5d85a1f29ca9d5ca23a34490"),
ObjectId("5d85a1f29ca9d5ca23a34491")
]
}
> var mapFunction = function() {
... var key = this.userid;
... var value = {
... userid: this.userid,
... total_time: this.length,
... count: 1,
... avg_time: 0
... };
...
... emit( key, value );
... };
> var reduceFunction = function(key, values) {
...
... var reducedObject = {
... userid: key,
... total_time: 0,
... count:0,
... avg_time:0
... };
...
... values.forEach( function(value) {
... reducedObject.total_time += value.total_time;
... reducedObject.count += value.count;
... }
... );
... return reducedObject;
... };
> var finalizeFunction = function (key, reducedValue) {
...
... if (reducedValue.count > 0)
... reducedValue.avg_time = reducedValue.total_time / reducedValue.count;
...
... return reducedValue;
... };
> db.sessions.mapReduce( mapFunction,
... reduceFunction,
... {
... out: "session_stat",
... finalize: finalizeFunction
... }
... )
{
"result" : "session_stat",
"timeMillis" : 44,
"counts" : {
"input" : 16,
"emit" : 16,
"reduce" : 5,
"output" : 5
},
"ok" : 1
}
> db.session_stat.find()
{ "_id" : null, "value" : { "userid" : null, "total_time" : NaN, "count" : 8, "avg_time" : NaN } }
{ "_id" : "a", "value" : { "userid" : "a", "total_time" : 200, "count" : 2, "avg_time" : 100 } }
{ "_id" : "b", "value" : { "userid" : "b", "total_time" : 230, "count" : 2, "avg_time" : 115 } }
{ "_id" : "c", "value" : { "userid" : "c", "total_time" : 250, "count" : 2, "avg_time" : 125 } }
{ "_id" : "d", "value" : { "userid" : "d", "total_time" : 110, "count" : 2, "avg_time" : 55 } }
|
cs |
첫 맵리듀스의 수행 결과이다. 유저 아이디당 총 세션시간과 접속 횟수, 평균 세션 시간을 넣고 있다. 추가적으로 문서를 추가한다.
|
1
2
3
4
|
db.sessions.save( { userid: "a", ts: ISODate('2011-11-05 14:17:00'), length: 100 } ),
db.sessions.save( { userid: "b", ts: ISODate('2011-11-05 14:23:00'), length: 115 } ),
db.sessions.save( { userid: "c", ts: ISODate('2011-11-05 15:02:00'), length: 125 } ),
db.sessions.save( { userid: "d", ts: ISODate('2011-11-05 16:45:00'), length: 55 } )
|
cs |
맵리듀스를 2011년11월5일 이후에 새로 들어온 문서를 기준으로 결과를 내고, 이전의 맵리듀스 결과에 증분(누적)시킨다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
> db.sessions.insertMany([db.sessions.save( { userid: "a", ts: ISODate('2011-11-05 14:17:00'), length: 100 } ),
... db.sessions.save( { userid: "b", ts: ISODate('2011-11-05 14:23:00'), length: 115 } ),
... db.sessions.save( { userid: "c", ts: ISODate('2011-11-05 15:02:00'), length: 125 } ),
... db.sessions.save( { userid: "d", ts: ISODate('2011-11-05 16:45:00'), length: 55 } )]);
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5d85a29d9ca9d5ca23a34496"),
ObjectId("5d85a29d9ca9d5ca23a34497"),
ObjectId("5d85a29d9ca9d5ca23a34498"),
ObjectId("5d85a29d9ca9d5ca23a34499")
]
}
> var mapFunction = function() {
... var key = this.userid;
... var value = {
... userid: this.userid,
... total_time: this.length,
... count: 1,
... avg_time: 0
... };
...
... emit( key, value );
... };
> var reduceFunction = function(key, values) {
...
... var reducedObject = {
... userid: key,
... total_time: 0,
... count:0,
... avg_time:0
... };
...
... values.forEach( function(value) {
... reducedObject.total_time += value.total_time;
... reducedObject.count += value.count;
... }
... );
... return reducedObject;
... };
> var finalizeFunction = function (key, reducedValue) {
...
... if (reducedValue.count > 0)
... reducedValue.avg_time = reducedValue.total_time / reducedValue.count;
...
... return reducedValue;
... };
> db.sessions.mapReduce( mapFunction,
... reduceFunction,
... {
... query: { ts: { $gt: ISODate('2011-11-05 00:00:00') } },
... out: { reduce: "session_stat" },
... finalize: finalizeFunction
... }
... );
{
"result" : "session_stat",
"timeMillis" : 43,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 0,
"output" : 5
},
"ok" : 1
}
> db.session_stat.find()
{ "_id" : null, "value" : { "userid" : null, "total_time" : NaN, "count" : 8, "avg_time" : NaN } }
{ "_id" : "a", "value" : { "userid" : "a", "total_time" : 300, "count" : 3, "avg_time" : 100 } }
{ "_id" : "b", "value" : { "userid" : "b", "total_time" : 345, "count" : 3, "avg_time" : 115 } }
{ "_id" : "c", "value" : { "userid" : "c", "total_time" : 375, "count" : 3, "avg_time" : 125 } }
{ "_id" : "d", "value" : { "userid" : "d", "total_time" : 165, "count" : 3, "avg_time" : 55 } }
|
cs |
결과가 누적된 것을 볼수 있다. 이런식으로 날짜를 기준으로 증분 맵리듀스를 사용하면 가장 활용도가 좋을 듯 싶다. 즉, 시점을 기준으로 하자는 것이다.
마지막으로 맵리듀스를 사용하면서 꼭 알아야할 내용이다.
- Map 함수에서 호출하는 emit() 함수의 두번째 인자와 Reduce 함수의 리턴 값은 같은 포맷이어야 한다.
- Reduce 함수의 연산 작업은 멱등(Idempotent)이어야 한다. 즉, Reduce 함수 작업이 멱등하지 않다면 정확한 결과가 나오지 않을 수 있다.
여기까지 간단하게 몽고디비의 맵리듀스를 다루어보았다. 사실 영어로된 레퍼런스가 해석이 애매모호한 부분도 많고 아직 다루어보지 않은 맵리듀스 관련 내용도 있다. 해당 내용들을 보완해 추후에 다루어볼 것이다. 이번 포스팅은 맵리듀스가 뭐고 간단히 어떻게 사용해볼 수 있냐를 다루어봤다.
'Database > MongoDB' 카테고리의 다른 글
| MongoDB - 백업하고 복구하기(mongodump&mongorestore) (1) | 2020.08.16 |
|---|---|
| DB - MongoDB FindAndModify 란? (0) | 2019.09.19 |
| DB - MongoDB OperationFailed Sort operation used more than the maximum 33554432 bytes of Ram. (0) | 2019.09.19 |
| DB - MongoDB Insert Ordered 옵션은? (0) | 2019.09.19 |
| DB - MongoDB Text Search(본문 검색) (0) | 2019.09.16 |

파이프라인 집계(Pipeline Aggregations)는 다른 집계와 달리 쿼리 조건에 부합하는 문서에 대해 집계를 수행하는 것이 아니라, 다른 집계로 생성된 버킷을 참조해서 집계를 수행한다. 집계 또는 중첩된 집계를 통해 생성된 버킷을 사용해 추가적으로 계산을 수행한다고 보면 된다. 파이프라인 집계에는 부모(Parent), 형제(Sibling)라는 두 가지 유형이 있다.
파이프라인 집계를 수행할 때는 buckets_path 파라미터를 사용해 참조할 집계의 경로를 지정함으로써 체인 형식으로 집계 간의 연산이 이뤄진다. 파이프라인 집계는 모든 집계가 완료된 후에 생성된 버킷을 사용하기 때문에 하위 집계를 가질 수는 없지만 다른 파이프라인 집계와는 buckets_path를 통해 참조하도록 지정할 수 있다.
-형제 집계(Sibling)
형제 집계는 동일 선상의 위치에서 수행되는 새 집계를 의미한다. 즉, 형제 집계를 통해 수행되는 집계는 기존 버킷에 추가되는 형태가 아니라 동일 선상의 위치에서 새 집계가 생성되는 파이프라인 집계다. 형제 집계는 다음과 같은 집계들이 있다.
| 평균 버킷 집계(Avg Bucket Aggregation) |
| 최대 버킷 집계(Max Bucket Aggregation) |
| 최소 버킷 집계(Min Bucket Aggregation) |
| 합계 버킷 집계(Sum Bucket Aggregation) |
| 통계 버킷 집계(Stats Bucket Aggregation) |
| 확장 통계 버킷 집계(Extended Stats Bucket Aggregation) |
| 백분위수 버킷 집계(Percentiles Bucket Aggregation) |
| 이동 평균 집계(Moving Average Aggregation) |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
{
"aggs":{
"histo":{
"date_histogram":{
"field":"timestamp",
"interval":"day"
},
"aggs":{ //중첩 집계
"bytes_sum":{
"sum":{
"field":"bytes"
}
}
}
},
"max_bytes":{ //파이프라인 집계
"max_bucket":{
"buckets_path":"histo>bytes_sum" //버킷 참조
}
}
}
}
->result
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"histo": {
"buckets": [
{
"key_as_string": "2015-05-17T00:00:00.000Z",
"key": 1431820800000,
"doc_count": 1632,
"bytes_sum": {
"value": 4.14259902E8
}
},
{
"key_as_string": "2015-05-18T00:00:00.000Z",
"key": 1431907200000,
"doc_count": 2893,
"bytes_sum": {
"value": 7.88636158E8
}
},
{
"key_as_string": "2015-05-19T00:00:00.000Z",
"key": 1431993600000,
"doc_count": 2896,
"bytes_sum": {
"value": 6.65827339E8
}
},
{
"key_as_string": "2015-05-20T00:00:00.000Z",
"key": 1432080000000,
"doc_count": 2578,
"bytes_sum": {
"value": 8.78559106E8
}
}
]
},
"max_bytes": {
"value": 8.78559106E8,
"keys": [
"2015-05-20T00:00:00.000Z"
]
}
}
}
|
cs |
위는 간단하게 2개의 집계를 중첩하였고, 형제 레벨로 histo 집계 밑의 bytes_sum의 버킷을 참조하여 최대값을 구하는 파이프라인 집계를 작성한 것이다. 결과값으로는 중첩된 집계결과와 마지막에 파이프라인의 집계가 나온다. 현재는 bytes_sum이 단일 메트릭 집계이기 때문에 집계 이름으로만 참조하고 있지만 stats 같은 다중 메트릭 집계일 경우 메트릭명까지 참조해줘야 한다. histo>bytes_sum.avg
Additional Sibling Aggregations
| 파이프라인 집계명 | 집계 쿼리 |
| 최대 버킷 집계 - 최대 값으로 버킷을 식별하고 버킷의 값과 키를 출력하는 형제 파이프 라인 집계입니다. 지정된 메트릭은 숫자 여야하고 형제 집계는 다중 버킷 집계 여야합니다. |
{ "max_bucket":{ "bucket_path":"histo>bytes_sum" } } |
| 최소 버킷 집계 - 최소값으로 버킷을 식별하고 버킷의 값과 키를 모두 출력하는 형제 파이프 라인 집계이다. 지정된 메트릭은 숫자 여야하고 형제 집계는 다중 버킷 집계 여야한다. |
{ "min_bucket":{ "bucket_path":"histo>bytes_sum" } } |
| 평균 버킷 집계 - 지정된 메트릭의 평균 값을 계산하는 파이프 라인 집계이다. 지정된 메트릭은 숫자 여야하고 형제 집계는 다중 버킷 집계여야한다. |
{ "avg_bucket":{ "bucket_path":"histo>bytes_sum" } } |
| 통계 버킷 집계 - 모든 버킷에 대한 다양한 통계를 계산하는 형제 파이프 라인 집계이다. 지정된 메트릭은 숫자 여야하고 형제 집계는 다중 버킷 집계 여야한다. |
{ "stats_bucket":{ "bucket_path":"histo>bytes_sum" } } |
| 확장 통계 버킷 집계 -
모든 버킷에 대한 다양한 통계를 계산하는 형제 파이프 라인 집계이다. 지정된 메트릭은 숫자 여야하고 형제 집계는 다중 버킷 집계 여야한다. 이 집계는 집계와 비교하여 몇 가지 통계 (제곱합, 표준 편차 등)를 제공한다. |
{ "extended_stats_bucket":{ "bucket_path":"histo>bytes_sum" } } |
| 백분위수 버킷 집계 - 모든 버킷에서 백분위 수를 계산하는 형제 파이프 라인 집계이다.. 지정된 메트릭은 숫자 여야하고 형제 집계는 다중 버킷 집계 여야한다. |
{ "percentiles_bucket":{ "bucket_path":"histo>bytes_sum" } } |
|
이동 평균 버킷 집계 - 이동 평균은 순차 데이터를 부드럽게하는 간단한 방법이다. 이동 평균은 일반적으로 주가 또는 서버 메트릭과 같은 시간 기반 데이터에 적용이다. 평활화는 고주파수 변동 또는 랜덤 노이즈를 제거하는 데 사용될 수 있으므로 계절 성과 같이 저주파수 추세를보다 쉽게 시각화 할 수 있다. 다양한 옵션이 있으므로 자세한 사용법은 레퍼런스를 참고하자. |
{ "moving_avg_bucket":{ "bucket_path":"histo>bytes_sum" } } |
이동 평균 버킷 집계는 부모에 histogram 혹은 date_histogram 집계가 있어야 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
{
"aggs":{
"histo":{
"date_histogram":{
"field":"timestamp",
"interval":"day"
},
"aggs":{
"bytes_sum":{
"sum":{
"field":"bytes"
}
},
"moving_avg_agg":{
"moving_avg":{
"buckets_path":"bytes_sum"
}
}
}
}
}
}
->result
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"histo": {
"buckets": [
{
"key_as_string": "2015-05-17T00:00:00.000Z",
"key": 1431820800000,
"doc_count": 1632,
"bytes_sum": {
"value": 4.14259902E8
}
},
{
"key_as_string": "2015-05-18T00:00:00.000Z",
"key": 1431907200000,
"doc_count": 2893,
"bytes_sum": {
"value": 7.88636158E8
},
"moving_avg_agg": {
"value": 4.14259902E8
}
},
{
"key_as_string": "2015-05-19T00:00:00.000Z",
"key": 1431993600000,
"doc_count": 2896,
"bytes_sum": {
"value": 6.65827339E8
},
"moving_avg_agg": {
"value": 6.0144803E8
}
},
{
"key_as_string": "2015-05-20T00:00:00.000Z",
"key": 1432080000000,
"doc_count": 2578,
"bytes_sum": {
"value": 8.78559106E8
},
"moving_avg_agg": {
"value": 6.229077996666666E8
}
}
]
}
}
}
|
cs |
-부모 집계(Parent)
부모 집계는 집계를 통해 생성된 버킷을 사용해 계산을 수행하고, 그 결과를 기존 집계 결과에 반영한다. 집계의 종류는 아래와 같다.
| 파생 집계(Derivative Aggregation) |
| 누적 집계(Cumulative Sum Aggregation) |
| 버킷 스크립트 집계(Bucket Script Aggregation) |
| 버킷 셀렉터 집계(Bucket Selector Aggregation) |
| 시계열 차분 집계(Serial Differencing Aggregation) |
아파치 웹 로그 등을 통해 수집된 데이터가 시간이 지남에 따라 변화하는 값의 변경폭 추이를 확인하고 싶은 경우 파생 집계를 활용할 수 있다. 파생 집계는 부모 히스토그램 또는 날짜 히스토그램 집계에서 지정된 메트릭의 파생값을 계산하는 상위 파이프라인 집계다. 이는 부모 히스토그램 집계 측정 항목에 대해 작동하고, 히스토그램 집계에 의한 각 버킷의 집계 값을 비교해서 차이를 계산한다. 반드시 지정된 메트릭은 숫자여야 하고, 상위에 해당하는 집계의 min_doc_count가 0보다 큰 값으로 설정되는 경우 일부 간격이 결과에서 생략될 수 있기에 min_doc_count 값을 0으로 설정해야 한다.
파생 집계의 경우에는 이처럼 선행되는 데이터가 존재하지 않으면 집계를 수행할 수 없는데, 실제 데이터를 다루다 보면 종종 노이즈가 포함되기도 하고, 필요한 필드에 값이 존재하지 않을 수 있다. 이러한 부분을 갭(Gap)이라고 할 수 있는데, 쉽게 말해 데이터가 존재하지 않는 부분을 의미한다.
갭(gap)이 발생되는 이유는 아래와 같다.
- 어느 하나의 버킷 안으로 포함되는 문서들에 요청된 필드가 포함되지 않은 경우
- 하나 이상의 버킷에 대한 쿼리와 일치하는 문서가 존재하지 않는 경우
- 다른 종속된 버킷에 값이 누락되어 계산된 메트릭이 값을 생성할 수 없는 경우
이러한 경우에는 파이프라인 집계에 원하는 동작을 알리는 메커니즘이 필요하다. 이 역할을하는 것이 갭 정책(gap_policy)이다. 모든 파이프라인 집계에서는 gap_policy 파라미터를 허용한다.
<갭정책>
| skip | 누락된 데이터를 버킷이 존재하지 않는 것으로 간주한다. 버킷을 건너뛰고 다음으로 사용 가능한 값을 사용해 계산을 계속해서 수행한다. |
| insert_zeros | 누락된 값을 0으로 대체하며 파이프라인 집계 계산은 정상적으로 진행된다. |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
{
"aggs":{
"histo":{
"date_histogram":{
"field":"timestamp",
"interval":"day"
},
"aggs":{
"bytes_sum":{
"sum":{
"field":"bytes"
}
},
"sum_deriv":{
"derivative":{
"buckets_path":"bytes_sum"
}
}
}
}
}
}
->result
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"histo": {
"buckets": [
{
"key_as_string": "2015-05-17T00:00:00.000Z",
"key": 1431820800000,
"doc_count": 1632,
"bytes_sum": {
"value": 4.14259902E8
}
},
{
"key_as_string": "2015-05-18T00:00:00.000Z",
"key": 1431907200000,
"doc_count": 2893,
"bytes_sum": {
"value": 7.88636158E8
},
"sum_deriv": {
"value": 3.74376256E8
}
},
{
"key_as_string": "2015-05-19T00:00:00.000Z",
"key": 1431993600000,
"doc_count": 2896,
"bytes_sum": {
"value": 6.65827339E8
},
"sum_deriv": {
"value": -1.22808819E8
}
},
{
"key_as_string": "2015-05-20T00:00:00.000Z",
"key": 1432080000000,
"doc_count": 2578,
"bytes_sum": {
"value": 8.78559106E8
},
"sum_deriv": {
"value": 2.12731767E8
}
}
]
}
}
}
|
cs |
결과를 보면 파생 집계는 각 버킷 간의 차이를 값으로 보여준다. 첫번째 버킷은 이전 데이터가 존재하지 않으므로 파생 집계 결과가 포함되지 않는다.
Addtional Parent Aggregations
| 파이프라인 집계명 | 쿼리 |
| 파생 집계 - 상위 히스토그램 (또는 date_histogram) 집계에서 지정된 메트릭의 미분을 계산하는 상위 파이프 라인 집계이다. 지정된 메트릭은 숫자 여야하며 둘러싸는 막대 그래프는 ( 집계의 기본값 ) 으로 min_doc_count이 0으로 설정되어 있어야한다. |
{ "derivative":{ "buckets_path":"bytes_sum" } } |
| 누적 집계 - 위 히스토그램 (또는 date_histogram) 집계에서 지정된 지표의 누적 합계를 계산하는 상위 파이프 라인 집계입니다. 지정된 메트릭은 숫자 여야하며 둘러싸는 막대 그래프는 ( 집계의 기본값 ) 으로 min_doc_count이 0으로 설정되어 있어야합니다 . |
{ "cumulative_sum":{ "buckets_path":"bytes_sum" } } |
| 버킷 스크립트 집계 - 부모 다중 버킷 집계에서 지정된 메트릭에 대해 버킷 당 계산을 수행 할 수있는 스크립트를 실행하는 부모 파이프 라인 집계입니다. 지정된 메트릭은 숫자 여야하며 스크립트는 숫자 값을 반환해야합니다. |
{ "bucket_script":{ "buckets_path":{ "my_var1":"bytes_sum", "my_var2":"total_count" }, "script":"params.my_var1/params.my_var2 } } |
| 버킷 셀렉터 집계 - 현재 버킷을 상위 멀티 버킷 집계에 유지할지 여부를 결정하는 스크립트를 실행하는 상위 파이프 라인 집계입니다. 지정된 메트릭은 숫자 여야하며 스크립트는 부울 값을 반환해야합니다. 스크립트 언어 인 경우 expression숫자 반환 값이 허용됩니다. 이 경우 0.0은 그대로 평가되고 false 다른 모든 값은 true로 평가됩니다. |
{ "bucket_selector":{ "buckets_path":{ "my_var1":"bytes_sum", "my_var2":"total_count" }, "script":"params.my_var1 > params.my_var2 } } |
| 시계열 차분 집계 - 시계열의 값을 다른 시차 또는 기간에 차감하는 기술입니다. 예를 들어, 데이터 포인트 f (x) = f (x t )-f (x t-n ), 여기서 n은 사용되는 기간입니다. |
{ "serial_diff":{ "buckets_path":"bytes_sum", "lag":"7" } } |
자세한 설명은 공식 레퍼런스를 참고하시길 바랍니다.
누적 집계
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
{
"aggs":{
"histo":{
"date_histogram":{
"field":"timestamp",
"interval":"day"
},
"aggs":{
"bytes_sum":{
"sum":{
"field":"bytes"
}
},
"sum_deriv":{
"cumulative_sum":{
"buckets_path":"bytes_sum"
}
}
}
}
}
}
->result
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"histo": {
"buckets": [
{
"key_as_string": "2015-05-17T00:00:00.000Z",
"key": 1431820800000,
"doc_count": 1632,
"bytes_sum": {
"value": 4.14259902E8
},
"sum_deriv": {
"value": 4.14259902E8
}
},
{
"key_as_string": "2015-05-18T00:00:00.000Z",
"key": 1431907200000,
"doc_count": 2893,
"bytes_sum": {
"value": 7.88636158E8
},
"sum_deriv": {
"value": 1.20289606E9
}
},
{
"key_as_string": "2015-05-19T00:00:00.000Z",
"key": 1431993600000,
"doc_count": 2896,
"bytes_sum": {
"value": 6.65827339E8
},
"sum_deriv": {
"value": 1.868723399E9
}
},
{
"key_as_string": "2015-05-20T00:00:00.000Z",
"key": 1432080000000,
"doc_count": 2578,
"bytes_sum": {
"value": 8.78559106E8
},
"sum_deriv": {
"value": 2.747282505E9
}
}
]
}
}
}
|
cs |
집계의 값을 계속 해서 누적하는 집계이다.
버킷 스크립트 집계
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
{
"aggs":{
"histo":{
"date_histogram":{
"field":"timestamp",
"interval":"day"
},
"aggs":{
"bytes_sum":{
"sum":{
"field":"bytes"
}
},
"sum_deriv":{
"bucket_script":{
"buckets_path":{
"my_var1":"bytes_sum",
"my_var2":"bytes_sum"
},
"script":"params.my_var1/params.my_var2"
}
}
}
}
}
}
->result
{
"took": 106,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"histo": {
"buckets": [
{
"key_as_string": "2015-05-17T00:00:00.000Z",
"key": 1431820800000,
"doc_count": 1632,
"bytes_sum": {
"value": 4.14259902E8
},
"sum_deriv": {
"value": 1.0
}
},
{
"key_as_string": "2015-05-18T00:00:00.000Z",
"key": 1431907200000,
"doc_count": 2893,
"bytes_sum": {
"value": 7.88636158E8
},
"sum_deriv": {
"value": 1.0
}
},
{
"key_as_string": "2015-05-19T00:00:00.000Z",
"key": 1431993600000,
"doc_count": 2896,
"bytes_sum": {
"value": 6.65827339E8
},
"sum_deriv": {
"value": 1.0
}
},
{
"key_as_string": "2015-05-20T00:00:00.000Z",
"key": 1432080000000,
"doc_count": 2578,
"bytes_sum": {
"value": 8.78559106E8
},
"sum_deriv": {
"value": 1.0
}
}
]
}
}
}
|
cs |
스크립트를 활용해 버킷의 결과 값을 스크립트로 조작가능하다.
버킷 셀렉터
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
{
"aggs":{
"histo":{
"date_histogram":{
"field":"timestamp",
"interval":"day"
},
"aggs":{
"bytes_sum":{
"sum":{
"field":"bytes"
}
},
"sum_deriv":{
"bucket_selector":{
"buckets_path":{
"my_var1":"bytes_sum",
"my_var2":"bytes_sum"
},
"script":"params.my_var1 < params.my_var2"
}
}
}
}
}
}
->result
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"histo": {
"buckets": []
}
}
}
|
cs |
불린을 결과값으로 하는 script를 작성해 결과에 노출시킬 버킷을 선택한다.
시계열 차분 집계
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
{
"aggs":{
"histo":{
"date_histogram":{
"field":"timestamp",
"interval":"day"
},
"aggs":{
"bytes_sum":{
"sum":{
"field":"bytes"
}
},
"thirtieth_difference":{
"serial_diff":{
"buckets_path":"bytes_sum",
"lag":2
}
}
}
}
}
}
->result
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"histo": {
"buckets": [
{
"key_as_string": "2015-05-17T00:00:00.000Z",
"key": 1431820800000,
"doc_count": 1632,
"bytes_sum": {
"value": 4.14259902E8
}
},
{
"key_as_string": "2015-05-18T00:00:00.000Z",
"key": 1431907200000,
"doc_count": 2893,
"bytes_sum": {
"value": 7.88636158E8
}
},
{
"key_as_string": "2015-05-19T00:00:00.000Z",
"key": 1431993600000,
"doc_count": 2896,
"bytes_sum": {
"value": 6.65827339E8
},
"thirtieth_difference": {
"value": 2.51567437E8
}
},
{
"key_as_string": "2015-05-20T00:00:00.000Z",
"key": 1432080000000,
"doc_count": 2578,
"bytes_sum": {
"value": 8.78559106E8
},
"thirtieth_difference": {
"value": 8.9922948E7
}
}
]
}
}
}
|
cs |
lag 값을 2로 주어 2번째 전 버킷과 현재 버킷의 차분을 계산하여 결과값에 포함시킨다.
여기까지 간단히 파이프라인 집계에 대해 다루어보았다. 사실 집계의 모든 것을 다 다루지는 못했다. 부족한 것은 공식레퍼런스와 서적을 더 참고해야겠다.
이번 포스팅말고 메트릭, 버킷 집계는 아래 링크를 참조하자.
Elasticsearch - Aggregation API(엘라스틱서치 집계,메트릭(Metric Aggregations) 집계) -1
이번에 다루어볼 내용은 엘라스틱서치 Aggregation API이다. 해당 기능은 SQL과 비교하면 Group by의 기능과 아주 유사하다. 즉, 문서 데이터를 그룹화해서 각종 통계 지표 만들어 낼 수 있다. 엘라스틱서치의 집..
coding-start.tistory.com
Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2
이번 포스팅은 엘라스틱서치 Aggregation(집계) API 두번째 글이다. 이번 글에서는 집계중 버킷집계(Bucket)에 대해 알아볼 것이다. 우선 버킷 집계는 메트릭 집계와는 다르게 메트릭을 계산하지 않고 버킷을 생..
coding-start.tistory.com
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글

이번 포스팅은 엘라스틱서치 Aggregation(집계) API 두번째 글이다. 이번 글에서는 집계중 버킷집계(Bucket)에 대해 알아볼 것이다. 우선 버킷 집계는 메트릭 집계와는 다르게 메트릭을 계산하지 않고 버킷을 생성한다. 생성되는 버킷은 쿼리와 함께 수행되어 쿼리 결과에 따른 컨텍스트 내에서 집계가 이뤄진다. 이렇게 집계된 버킷은 또 다시 하위에서 집계를 한번 더 수행해서 집계된 결과에 대해 중첩된 집계 수행이 가능하다.
버킷이 생성되는 것은 집계 결과 집합을 메모리에 저장한다는 것이기 때문에 너무 많은 중첩 집계는 메모리 사용량을 점점 높히기에 성능에 악영향을 줄 수 있다. 이러한 문제때문에 엘라스틱서치는 설정으로 최대 버킷수를 조정할 수 있다.
> search.max_buckets
버킷의 크기를 -1 혹은 10000 이상의 값을 지정할 경우 엘라스틱서치에서 경고메시지를 보낸다. 이 말은 여러가지 이유로 안정적인 집계 분석을 위해 버킷의 크기, 집계의 중첩양 등을 충분히 고려한 후에 집계 수행을 해야한다.
-범위 집계(Range Aggregations)
범위 집계는 사용자가 지정한 범위 내에서 집계를 수행하는 다중 버킷 집계이다. 집계가 수행되면 쿼리의 결과가 범위에 해당하는 지 체크하고, 범위에 해당되는 문서들에 대해서만 집계를 수행한다. from과 to 속성을 지정하고, to에 지정한 값을 결과에서 제외된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
{
"aggs":{
"bytes_range":{
"range":{
"field":"bytes",
"ranges":[{"from":1000,"to":2000}]
}
}
}
}
->result
{
"took": 51,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"bytes_range": {
"buckets": [
{
"key": "1000.0-2000.0",
"from": 1000.0,
"to": 2000.0,
"doc_count": 754
}
]
}
}
}
|
cs |
결과값에 대해 간단히 설명하면 "key"는 집계할 범위를 뜻하고, from은 시작,to는 끝,doc_count는 범위 내의 문서수를 의미한다. 또한 집계 쿼리에서 "ranges" 필드가 배열인 것으로 보아 여러개의 범위 지정이 가능한 것을 알 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
{
"aggs":{
"bytes_range":{
"range":{
"field":"bytes",
"ranges":[
{"from":1000,"to":2000},
{"from":2000,"to":4000}
]
}
}
}
}
->result
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"bytes_range": {
"buckets": [
{
"key": "1000.0-2000.0",
"from": 1000.0,
"to": 2000.0,
"doc_count": 754
},
{
"key": "2000.0-4000.0",
"from": 2000.0,
"to": 4000.0,
"doc_count": 1004
}
]
}
}
}
|
cs |
그리고 키값을 더 의미있는 값으로 지정해 줄 수도 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
{
"aggs":{
"bytes_range":{
"range":{
"field":"bytes",
"ranges":[
{"key":"small","from":1000,"to":2000},
{"key":"medium","from":2000,"to":4000}
]
}
}
}
}
->result
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"bytes_range": {
"buckets": [
{
"key": "small",
"from": 1000.0,
"to": 2000.0,
"doc_count": 754
},
{
"key": "medium",
"from": 2000.0,
"to": 4000.0,
"doc_count": 1004
}
]
}
}
}
|
cs |
-날짜 범위 집계
날짜 값을 범위로 집계를 수행한다. 날짜 포맷은 엘라스틱서치가 내부적으로 이해할 수 있는 날짜 타입이 와야한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
{
"aggs":{
"request_count_date":{
"date_range":{
"field":"timestamp",
"ranges":[
{"from":"2015-05-04T05:16:00.000Z","to":"2015-05-18T05:16:00.000Z"}
]
}
}
}
}
->result
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"request_count_date": {
"buckets": [
{
"key": "2015-05-04T05:16:00.000Z-2015-05-18T05:16:00.000Z",
"from": 1.43071656E12, //시작날짜의 밀리초값
"from_as_string": "2015-05-04T05:16:00.000Z",
"to": 1.43192616E12, //끝날짜의 밀리초값
"to_as_string": "2015-05-18T05:16:00.000Z",
"doc_count": 2345 //날짜 범위에 해당되는 문서수
}
]
}
}
}
|
cs |
-히스토그램 집계(Histogram)
지정한 범위 간격으로 집계를 낸다. 만약 10000으로 지정하였다면, 0~10000(미포함), 10000~20000 의 간격으로 집계를 낸다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
{
"aggs":{
"bytes_histogram":{
"histogram":{
"field":"bytes", //집계필드
"interval":10000, //집계 간격
"min_doc_count":1 //최소 1개 이상되어야 결과에 포함
}
}
}
}
->result
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"bytes_histogram": {
"buckets": [
{
"key": 0.0,
"doc_count": 4196
},
{
"key": 10000.0,
"doc_count": 1930
},
{
"key": 20000.0,
"doc_count": 539
},
...
{
"key": 5.43E7,
"doc_count": 24
},
{
"key": 6.525E7,
"doc_count": 2
},
{
"key": 6.919E7,
"doc_count": 2
}
]
}
}
}
|
cs |
대시보드에서 시각화할때도 아주 좋은 역할을 할듯하다.
-날짜 히스토그램 집계
날짜 히스토그램 집계는 분, 시간, 월, 연도를 구간으로 집계를 수행할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
{
"aggs":{
"daily_request_count":{
"date_histogram":{
"field":"timestamp", //집계 필드
"interval":"day", //집계 간격
"format":"yyyy-MM-dd" //출력되는 날짜 포맷 변경
}
}
}
}
->result
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"daily_request_count": {
"buckets": [
{
"key_as_string": "2015-05-17",
"key": 1431820800000,
"doc_count": 1632
},
{
"key_as_string": "2015-05-18",
"key": 1431907200000,
"doc_count": 2893
},
{
"key_as_string": "2015-05-19",
"key": 1431993600000,
"doc_count": 2896
},
{
"key_as_string": "2015-05-20",
"key": 1432080000000,
"doc_count": 2578
}
]
}
}
}
|
cs |
key_as_string은 집계한 기준 날짜인데, UTC가 기본이며 "yyyy-MM-dd'T'HH:mm: ss.SSS 형식을 사용한다. 하지만 "format" 필드로 형식 포맷 변경이 가능하다. key는 집계 기준 날짜에 대한 밀리초이다.
구간 지정을 위해서 interval 속성을 사용하는데, 여기에 year, quarter, month, week, day, hour, minute, second 표현식을 사용할 수 있고, 더 세밀한 설정을 위해 30m(30분 간격), 1.5h(1시간 30분 간격) 같은 값도 사용가능하다.
지금까지 사용한 예제에서 날짜는 모두 UTC 기준으로 기록됬다. 우리나라 사용자가 사용하기 위해서는 9시간을 더해서 계산해야 현재 시간이 되기 때문에 번거로울 수 있다. 하지만 엘라스틱서치는 타임존을 지원하기 때문에 한국 시간으로 변환된 결과를 받을 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
{
"aggs":{
"daily_request_count":{
"date_histogram":{
"field":"timestamp",
"interval":"day",
"format":"yyyy-MM-dd-HH:mm:ss",
"time_zone":"+09:00"
}
}
}
}
->result
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"daily_request_count": {
"buckets": [
{
"key_as_string": "2015-05-17-00:00:00",
"key": 1431788400000,
"doc_count": 538
},
{
"key_as_string": "2015-05-18-00:00:00",
"key": 1431874800000,
"doc_count": 2898
},
{
"key_as_string": "2015-05-19-00:00:00",
"key": 1431961200000,
"doc_count": 2902
},
{
"key_as_string": "2015-05-20-00:00:00",
"key": 1432047600000,
"doc_count": 2862
},
{
"key_as_string": "2015-05-21-00:00:00",
"key": 1432134000000,
"doc_count": 799
}
]
}
}
}
|
cs |
타임존과는 다르게 offset을 사용해 집계 기준이 되는 날짜 값의 조정이 가능하다. 위에서 데일리로 집계했을 때, 00시 기준이었는데, 3시를 기준으로 하고 싶다면 아래와 같이 사용하면 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
{
"aggs":{
"daily_request_count":{
"date_histogram":{
"field":"timestamp",
"interval":"day",
"format":"yyyy-MM-dd-HH:mm:ss",
"offset":"+3h"
}
}
}
}
->result
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"daily_request_count": {
"buckets": [
{
"key_as_string": "2015-05-17-03:00:00",
"key": 1431831600000,
"doc_count": 1991
},
{
"key_as_string": "2015-05-18-03:00:00",
"key": 1431918000000,
"doc_count": 2898
},
{
"key_as_string": "2015-05-19-03:00:00",
"key": 1432004400000,
"doc_count": 2895
},
{
"key_as_string": "2015-05-20-03:00:00",
"key": 1432090800000,
"doc_count": 2215
}
]
}
}
}
|
cs |
-텀즈 집계(terms)
텀즈 집계는 버킷이 동적으로 생성되는 다중 버킷 집계이다. 집계 시 지정한 필드에 대해 빈도수가 높은 텀의 순위로 결과가 반환된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
{
"aggs":{
"request_count_country":{
"terms":{
"field":"geoip.country_name.keyword"
}
}
}
}
->result
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"request_count_country": {
"doc_count_error_upper_bound": 48,
"sum_other_doc_count": 2334,
"buckets": [
{
"key": "United States",
"doc_count": 3974
},
{
"key": "France",
"doc_count": 855
},
{
"key": "Germany",
"doc_count": 510
},
{
"key": "Sweden",
"doc_count": 440
},
{
"key": "India",
"doc_count": 428
},
{
"key": "China",
"doc_count": 416
},
{
"key": "United Kingdom",
"doc_count": 276
},
{
"key": "Spain",
"doc_count": 227
},
{
"key": "Canada",
"doc_count": 224
},
{
"key": "Russia",
"doc_count": 214
}
]
}
}
}
|
cs |
집계 필드는 "geoip.country_name" 필드인데, 해당 필드는 text와 keyword 타입 두개를 가지는 필드이며, 집계 필드로 "*.keyword"로 지정하였다. 이유는 text 데이터 타입의 경우 형태소 분석이 들어가기에 집계할때는 형태소 분석이 없는 keyword 데이터 타입을 사용해야만 한다. 물론 text 타입이 안되는 건 아니지만, 성능은.. 최악이 될것이다.
결과 값에 대해 설명하자면 "doc_count_error_upper_bound"는 문서 수에 대한 오류 상한선이다. 오류 상한선이 있는 이유는 각 샤드별로 계산되는 집계의 성능을 고려해 근사치를 계산하기에 문서 수가 정확하지 않아 최대 오류 상한선을 보여준다. "sum_other_doc_count"는 결과에 포함되지 않은 모든 문서수를 뜻한다.(size를 늘려 결과에 더 많은 집계 데이터를 포함시키면 된다. terms 안의 field와 같은 레벨로 size 옵션을 주면 된다.) key는 집계 필드 값이고, doc_count는 같은 필드 값의 문서수이다.
여기서 "doc_count_error_upper_bound" 값에 대해 조금 더 자세히 다루어보면, 내부 집계 처리 플로우는 각 샤드에서 집계를 한후에 모든 결과를 병합해서 집계 결과를 최종으로 반환한다. 하지만 아래와 같은 상황이 있다고 해보자.
| 샤드 A | 샤드 B | 샤드 C | |
| 1 | Product A(25) | Product A(30) | Product A(45) |
| 2 | Product B(18) | Product B(25) | Product C(44) |
| 3 | Product C(25) |
청크의 분포가 위와 같다라고 가정하고 집계 시 사이즈를 2로 지정하면 아래와 같은 결과를 반환할 것이다.
| 1 | Product A(100) |
| 2 | Product B(43) |
| 3 | Product C(44) |
결과는 나왔지만, Product C의 값에 오차가 생겼다. 즉, 쿼리 작성시 적절히 size값을 정해서 오차를 줄이거나 혹은 전부 포함시켜야한다. 하지만 역시나 사이즈를 키우면 키울 수록 집계 비용은 올라갈 것이다. 즉 위에서는 doc_count_error_upper_bound 값이 25가 될것이다.
집계와 샤드 크기
텀즈 집계가 수행될 때 각 샤드에게 최상위 버킷을 제공하도록 요청한 후에 모든 샤드로부터 결과를 받을 때까지 기다린다. 결과를 기다리다가 모든 샤드로부터 결과를 받으면 설정된 size에 맞춰 하나로 병합한 후 결과를 반환한다.
각 샤드는 size에 해당되는 갯수로 집계 결과를 반환하지 않는다. 각 샤드에서는 정확성을 위해 size의 크기가 아닌 샤드 크기를 이용한 경험적인 방법(샤드 크기*1.5+10)을 사용해 내부적으로 집계를 수행하는데, 텀즈 집계 결과로 받을 텀의 개수를 정확하게 파악할 수 있는 경우에는 shard_size 속성을 사용해 각 샤드에서 집계할 크기를 직접 지정해 불필요한 연산을 줄이면서 정확도를 높힐 수 있다.
앞서 설명한 바와 같이 shard_size가 기본값 -1로 되어있다면 엘라스틱서치가 샤드 크기를 기준으로 자동으로 추정한다. 만약 shard_size를 직접 설정할 경우에는 size보다 작은 값은 설정할 수 없다.
여기까지 간단히 버킷집계를 다루어보았고, 다음 포스팅에 이어 파이프라인 집계부터 다루어볼 것이다.
Elasticsearch - Aggregation API(엘라스틱서치 집계,메트릭(Metric Aggregations) 집계) -1
이번에 다루어볼 내용은 엘라스틱서치 Aggregation API이다. 해당 기능은 SQL과 비교하면 Group by의 기능과 아주 유사하다. 즉, 문서 데이터를 그룹화해서 각종 통계 지표 만들어 낼 수 있다. 엘라스틱서치의 집..
coding-start.tistory.com
Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3
파이프라인 집계(Pipeline Aggregations)는 다른 집계와 달리 쿼리 조건에 부합하는 문서에 대해 집계를 수행하는 것이 아니라, 다른 집계로 생성된 버킷을 참조해서 집계를 수행한다. 집계 또는 중첩된 집계를..
coding-start.tistory.com
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - 한글 자동완성(Nori Analyzer, Ngram, Edge Ngram) (0) | 2020.04.09 |
|---|---|
| Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3 (0) | 2019.09.20 |
| Elasticsearch - Aggregation API(엘라스틱서치 집계,메트릭(Metric Aggregations) 집계) -1 (0) | 2019.09.19 |
| Elasticsearch - Rest High Level Client를 이용한 Index Template 생성 (0) | 2019.06.27 |
| ELK Stack - Logstash(로그스태시)를 이용한 로그 수집 (1) | 2019.06.26 |

이번에 다루어볼 내용은 엘라스틱서치 Aggregation API이다. 해당 기능은 SQL과 비교하면 Group by의 기능과 아주 유사하다. 즉, 문서 데이터를 그룹화해서 각종 통계 지표 만들어 낼 수 있다.
엘라스틱서치의 집계(Aggregation)
통계 분석을 위한 프로그램은 아주 많다. 하지만 실시간에 가깝게 어떠한 대용량의 데이터를 처리하여 분석 결과를 내놓은 프로그램은 많지 않다. 즉, RDBMS이나 하둡등의 대용량 데이터를 적재하고 배치등을 돌려 분석을 내는 것이 대부분이다. 하지만 엘라스틱서치는 많은 양의 데이터를 조각내어(샤딩)내어 관리하며 그 덕분에 다른 분석 프로그램보다 거의 실시간에 가까운 통계 결과를 만들어낼 수 있다.
하지만 집계기능은 일반 검색 기능보다 훨씬 더 많은 리소스를 소모한다. 성능 문제를 어느정도 효율적으로 해결하기 위해서는 캐시를 적절히 이용해야 하는 것이다. 물론 우리가 직접적으로 캐시를 조작하는 API를 사용하거나 하지는 않지만 어느정도 설정으로 조정가능하다. 그렇다면 엘라스틱서치에서 사용하는 캐시의 종류가 뭐가 있는지 간단히 알아보자.
캐시 종류 설명에 앞서 우선 엘라스틱서치의 캐시를 이용하면 질의의 결과를 캐시에 두고 다음에 동일한 요청이 오면 다시 한번 요청을 처리하는 것이 아닌 캐시에 있는 결과값을 그대로 돌려준다. 보통 캐시의 크기는 일반적으로 힙 메모리의 1%로 정도를 할당하며, 캐시에 없는 질의의 경우 성능 향상에 별다른 도움이 되지 못한다. 만약 엘라스틱서치가 사용하는 캐시 크기를 키우고 싶다면 아래와 같은 설정이 가능하다.
~/elasticsearch.yml
indices.requests.cache.size: n%
여기서 퍼센트(%)는 엘라스틱서치가 사용하는 힙메모리 중 몇 퍼센트를 나타내는 것이다. 다음은 엘라스틱서치가 사용하는 캐시 종류이다.
| 캐시명 | 설명 |
| Node query Cache |
노드의 모든 샤드가 공유하는 LRU(Least-Recently-Used)캐시다. 캐시 용량이 가득차면 사용량이 가장 적은 데이터를 삭제하고 새로운 결과값을 캐싱한다. 쿼리 캐싱 사용여부는 elasticsearch.yml 파일에 아래 옵션을 추가한다. 기본값은 true이다. index.queries.cache.enabled: true |
| Shard request Cache | 샤드는 데이터를 분산 저장하기 위한 단위로서, 사실 그 자체가 온전한 기능을 가지는 인덱스라고 볼 수 있다. 그래서 우리는 조회 기능을 특정 샤드에 요청해서 그 샤드에 있는 결과값만 얻어올 수 있는 이유가 그렇다. Shard request Cache는 바로 이 샤드에서 수행된 쿼리의 결과를 캐싱한다. 샤드의 내용이 변경되면 캐시도 삭제하기 때문에 문서 수정이 빈번한 인덱스에서는 오히려 성능 저하가 있을 수 있다. |
| Field data Cache | 엘라스틱서치가 필드에서 집계 연산을 수행할 때는 모든 필드 값을 메모리에 로드한다. 이러한 이유로 엘라스틱서치에서 계산되는 집계 쿼리는 성능적인 측면에서 비용이 상당하다. Field data Cache는 집계 계산동안 필드의 값을 메모리에 보관한다. |
Aggregation API
집계 쿼리 구조
GET>http://localhost:9200/indexName/_search?size=0
|
1
2
3
4
5
6
7
8
9
10
|
"aggregations":{
"<aggregation_name>":{
"<aggregation_type>":{
"<aggregation_body>"
}
[,"meta":{[<meta_data_body>]}]?
[,"aggregations":{[<sub_aggregation>]+}]?
}
,[,"<aggregation_name_2>:{...}"]*
}
|
cs |
집계쿼리는 위와 같은 구조를 갖는다. 각각의 키값에 대한 설명은 직접 예제 쿼리를 통해 다루어볼 것이다. 엘라스틱서치의 집계 기능이 강력한 이유중 하나는 위의 쿼리에서 보듯 여러 집계를 중첩하여 더 고도화된 데이터를 반환할 수 있다는 점이다. 물론 중첩이 될수록 성능은 떨어지지만 더 다양한 데이터를 집계할 수 있다. 또한 URL 요청을 보면 맨뒤에 size=0이 보일 것이다. 해당 쿼리스트링을 보내지 않으면 집계 스코프 대상(query)의 결과도 노출되니 집계 결과만 보고 싶다면 size=0으로 지정해주어야 한다.
집계 Scope
집계 API의 전체 요청 JSON구조를 보면 아래와 같다.
GET> http://localhost:9200/apache-web-log/_search?size=0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"query":{
"match_all":{}
},
"aggs":{
"region_count":{
"terms":{
"field":"geoip.region_name.keyword",
"size":20
}
}
}
}
|
cs |
위에 query라는 필드가 하나더 존재하는데, 해당 쿼리를 통해 나온 결과값을 이용하여 집계를 내겠다라는 집계 대상이 되는 Scope를 query를 이용하여 지정한다. 참고로 aggregations는 aggs로 줄여서 필드명을 작성할 수 있다. 그렇다면 아래와 같은 쿼리는 어떠한 결과를 낼까?
GET> http://localhost:9200/apache-web-log/_search?size=0
|
1
2
3
4
5
6
7
8
9
10
11
|
{
"size":0,
"aggs":{
"region_count":{
"terms":{
"field":"geoip.region_name.keyword",
"size":3
}
}
}
}
|
cs |
쿼리가 생략되면 내부적으로 match_all 쿼리를 수행한다. 또한 이러한 경우도 있다. 한번의 집계 쿼리를 통해 사용자가 지정한 질의에 해당하는 문서들 집계를 수행하고 전체 문서에 대해서도 집계를 수행해야 하는 경우는 아래와 같이 글로벌 버킷을 사용하면 된다.
GET> http://localhost:9200/apache-web-log/_search?size=0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
{
"query":{
"match":{
"geoip.region_name":"California"
}
},
"aggs":{
"region_count":{
"terms":{
"field":"geoip.region_name.keyword",
"size":3
}
},
"global_aggs":{
"global":{},
"aggs":{
"all_doc_aggs":{
"terms":{
"field":"geoip.region_name.keyword",
"size":3
}
}
}
}
}
}
|
cs |
우선 region_name이 California인 질의의 결과를 이용하여 region_count라는 집계를 수행하고 이것 이외로 global_aggs 글로벌 버킷의 all_doc_aggs 집계를 전체 문서를 대상으로 한번더 수행한다. 결과는 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 756,
"max_score": 0,
"hits": []
},
"aggregations": {
"global_aggs": {
"doc_count": 10001,
"all_doc_aggs": {
"doc_count_error_upper_bound": 77,
"sum_other_doc_count": 5729,
"buckets": [
{
"key": "California",
"doc_count": 756
},
{
"key": "Texas",
"doc_count": 588
},
{
"key": "Virginia",
"doc_count": 424
}
]
}
},
"region_count": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "California",
"doc_count": 756
}
]
}
}
}
|
cs |
그렇다면 집계의 종류에는 무엇이 있을까?
| 집계 종류 | 설명 |
| 버킷 집계 | 쿼리 결과로 도출된 문서 집합에 대해 특정 기준으로 나눈 다음 나눠진 문서들에 대한 산술 연산을 수행한다. 이때 나눠진 문서들의 모음들이 각 버컷에 해당된다. |
| 메트릭 집계 | 쿼리 결과로 도출된 문서 집합에서 필드의 값을 더하거나 평균을 내는 등의 산술 연산을 수행한다. |
| 파이프라인 집계 | 다른 집계 또는 관련 메트릭 연산의 결과를 집계한다. |
| 행렬 집계 | 버킷 대상이 되는 문서의 여러 필드에서 추출한 값으로 행렬 연산을 수행한다. 이를 토대로 다양한 통계정보를 제공한다. |
이제 위의 집계 종류에 대하여 하나하나 간단히 다루어보자.
메트릭 집계
메트릭 집계(Metrics Aggregations)를 사용하면 특정 필드에 대해 합이나 평균을 계산하거나 다른 집계와 중첩해서 결과에 대해 특정 필드의 _score 값에 따라 정렬을 수행하거나 지리 정보를 통해 범위 계산을 하는 등의 다양한 집계를 수행할 수 있다. 이름에서도 알 수 있듯이 정수 또는 실수와 같이 숫자 연산을 할 수 있는 값들에 대한 집계를 수행한다.
메트릭 집계는 또한 단일 숫자 메트릭 집계와 다중 숫자 메트릭 집계로 나뉘는데, 단일 숫자 메트릭 집계는 집계를 수행한 결과값이 하나라는 의미로 sum과 avg 등이 속한다. 다중 숫자 메트릭 집계는 집계를 수행한 결과값이 여러개가 될 수 있고, stats나 geo_bounds가 이에 속한다.
-합산집계(sum)
합산집계는 단일 숫자 메트릭 집계에 해당한다.
apache 로그에 유입되는 데이터의 바이트 총합을 구하는 집계 쿼리이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
{
"aggs":{
"total_bytes":{
"sum":{
"field":"bytes"
}
}
}
}
->result
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0,
"hits": []
},
"aggregations": {
"total_bytes": {
"value": 2747282505
}
}
}
|
cs |
만약 전체 데이터가 아닌 쿼리를 날려 매치되는 문서를 집계하기 위해서 특정 지역에서 유입된 apache 로그를 검색해 그 결과로 bytes 수를 총합하는 쿼리는 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"total_bytes":{
"sum":{
"field":"bytes"
}
}
}
}
->result
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"total_bytes": {
"value": 428964
}
}
}
|
cs |
논외의 이야기이지만, 스코어 점수가 필요없는 어떠한 검색에 constant_score 쿼리를 사용하면 성능상 이슈가 있다. 자주 사용되는 필터 쿼리는 엘라스틱 서치에서 캐시하므로 성능에 이점이 있을 수 있다. 만약 위의 쿼리에서 바이트를 KB나 MB,GB 단위로 보고 싶다면 어떻게 하면 좋을까? 사실 집계 쿼리에 데이터 크기 단위를 조정하는 기능은 없다. 하지만 script를 이용하면 집계되는 데이터를 원하는 단위로 변환이 가능하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"total_bytes":{
"sum":{
"script":{
"lang":"painless",
"source":"doc.bytes.value"
}
}
}
}
}
|
cs |
해당 쿼리는 위의 쿼리와 동일한 결과를 내놓는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"total_bytes":{
"sum":{
"script":{
"lang":"painless",
"source":"doc.bytes.value / params.divice_value",
"params":{
"divice_value":1000
}
}
}
}
}
}
->result
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"total_bytes": {
"value": 422
}
}
}
|
cs |
이렇게 스크립트를 이용하면 결과값을 일부 후처리할 수 있다. 하지만 결과가 조금이상하다. 428964/1000 인데 422가 됬다. 분명 428이 되야하는데 말이다. 그 이유는 모든 합산 값에 대한 나누기가 아니라 각 문서의 개별적인 값을 1000으로 나눈 후에 더했기 때문이다. 즉, 1000보다 작은수는 모두 0이 되어 합산이 되었다. 이 문제를 해결하기 위해서는 정수가 아닌 실수로 값을 계산해야한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"total_bytes":{
"sum":{
"script":{
"lang":"painless",
"source":"doc.bytes.value / (double)params.divice_value",
"params":{
"divice_value":1000
}
}
}
}
}
}
->result
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"total_bytes": {
"value": 428.96399999999994
}
}
}
|
cs |
-평균 집계(avg)
평균 집계는 단일 숫자 메트릭 집계에 해당한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"avg_bytes":{
"avg":{
"field":"bytes"
}
}
}
}
->result
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"total_bytes": {
"value": 20426.85714285714
}
}
}
|
cs |
-최소값 집계(min)
최소값 집계는 단일 숫자 메트릭 집계에 해당한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"min_bytes":{
"min":{
"field":"bytes"
}
}
}
}
->result
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"min_bytes": {
"value": 1015
}
}
}
|
cs |
최대값 집계는 aggregation_type을 max로 바꾸어주면 된다.
-개수집계(count)
개수집계는 단일 숫자 메트릭 집계에 해당한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"count_bytes":{
"value_count":{
"field":"bytes"
}
}
}
}
->result
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"count_bytes": {
"value": 21
}
}
}
|
cs |
-통계집계(Stats)
통계집계는 결과값이 여러 개인 다중 숫자 메트릭 집계에 해당한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"stats_bytes":{
"stats":{
"field":"bytes"
}
}
}
}
->result
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"stats_bytes": {
"count": 21,
"min": 1015,
"max": 53270,
"avg": 20426.85714285714,
"sum": 428964
}
}
}
|
cs |
count,min,max,avg,sum 등 한번에 모든 집계 결과를 받을 수 있다.
-확장 통계 집계(extended Stats)
확장 통계 집계는 결과값이 여러 개인 다중 숫자 메트릭 집계에 해당한다. 앞의 통계 집계를 확장해서 표준편차 같은 통계값이 추가된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"count_bytes":{
"extended_stats":{
"field":"bytes"
}
}
}
}
->result
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"count_bytes": {
"count": 21,
"min": 1015,
"max": 53270,
"avg": 20426.85714285714,
"sum": 428964,
"sum_of_squares": 18371748404,
"variance": 457588669.3605442,
"std_deviation": 21391.32229107271,
"std_deviation_bounds": {
"upper": 63209.501725002556,
"lower": -22355.787439288277
}
}
}
}
|
cs |
-카디널리티 집계(Cardinality)
카디널리티 집계는 단일 숫자 메트릭 집계에 해당한다. 개수 집합과 유사하게 횟수를 계산하는데, 중복된 값은 제외한 고유한 값에 대한 집계를 수행한다. 하지만 모든 문서에 대해 중복된 값을 집계하는 것은 성능에 큰 영향을 줄 수 있기에 근사치를 통해 집계한다. 근사치를 구하기 위해 HyperLogLog++ 알고리즘 기반으로 동작한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
{
"query":{
"bool":{
"must":[
{
"match":{
"geoip.country_name":"United"
}
},
{
"match":{
"geoip.country_name":"States"
}
}
]
}
},
"aggs":{
"us_city_names":{
"cardinality":{
"field":"geoip.city_name.keyword"
}
}
}
}
->result
{
"took": 25,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3974,
"max_score": 0,
"hits": []
},
"aggregations": {
"us_city_names": {
"value": 206
}
}
}
|
cs |
-백분위 수 집계(Percentiles)
역시나 근사치이고 TDigest 알고리즘을 이용한다. 카디날리티 집계와 마찬가지로 문서들의 집합 크기각 작을 수록 정확도는 높아지고, 문서의 집합이 클수록 오차범위가 늘어난다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"bytes_percentiles":{
"percentiles":{
"field":"bytes"
}
}
}
}
->result
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"bytes_percentiles": {
"values": {
"1.0": 1015,
"5.0": 1015,
"25.0": 3638,
"50.0": 6146,
"75.0": 50662.75,
"95.0": 53270,
"99.0": 53270
}
}
}
}
|
cs |
아래와 같이 백분율을 명시할 수도 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"bytes_percentiles":{
"percentiles":{
"field":"bytes",
"percents":[0,10,20,30,40,50,60,70,80,90,100]
}
}
}
}
->result
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"bytes_percentiles": {
"values": {
"0.0": 1015,
"10.0": 1015,
"20.0": 3638,
"30.0": 4629.2,
"40.0": 4877,
"50.0": 6146,
"60.0": 17147,
"70.0": 37258.399999999994,
"80.0": 52315,
"90.0": 52697,
"100.0": 53270
}
}
}
}
|
cs |
-백분위 수 랭크 집계
위의 랭크 집계와는 달리 특정 값을 주고 어느 백분위 범위에 속하는지를 결과값으로 돌려준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
{
"query":{
"constant_score":{
"filter":{
"match":{
"geoip.city_name":"Paris"
}
}
}
},
"aggs":{
"bytes_percentiles_rank":{
"percentile_ranks":{
"field":"bytes",
"values":[4000,6900]
}
}
}
}
->result
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 21,
"max_score": 0,
"hits": []
},
"aggregations": {
"bytes_percentiles_rank": {
"values": {
"4000.0": 26.592105768861217,
"6900.0": 53.03370689244701
}
}
}
}
|
cs |
-지형 경계 집계
지형 좌표를 포함하고 있는 필드에 대해 해당 지역 경계 상자를 계산하는 메트릭 집계다. 해당 집계를 사용하기 위해서는 계산하려는 필드의 타입이 geo_point여야 한다.

필드 매핑타입이다.

해당 필드에 들어간 값의 예제이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
{
"aggs":{
"viewport":{
"geo_bounds":{
"field":"geoip.location",
"wrap_longitude":true
}
}
}
}
->result
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0,
"hits": []
},
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"lat": 69.34059997089207,
"lon": -159.76670005358756
},
"bottom_right": {
"lat": -45.88390002027154,
"lon": 176.91669998690486
}
}
}
}
}
|
cs |
추후 키바나에서 이러한 지형집계로 시각화를 할 수 있다.

-지형 중심 집계
지형 경계 집계 범위에서 정가운데의 위치를 반환한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
{
"aggs":{
"centroid":{
"geo_centroid":{
"field":"geoip.location"
}
}
}
}
->result
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10001,
"max_score": 0,
"hits": []
},
"aggregations": {
"centroid": {
"location": {
"lat": 38.715619301146354,
"lon": -22.189867686554656
},
"count": 9993
}
}
}
|
cs |
여기까지 메트릭 집계에 대해 간단히 다루어봤다. 글이 길어져 다음 포스팅에 이어서 집계 API를 다루어보도록 한다.
Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2
이번 포스팅은 엘라스틱서치 Aggregation(집계) API 두번째 글이다. 이번 글에서는 집계중 버킷집계(Bucket)에 대해 알아볼 것이다. 우선 버킷 집계는 메트릭 집계와는 다르게 메트릭을 계산하지 않고 버킷을 생..
coding-start.tistory.com
Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3
파이프라인 집계(Pipeline Aggregations)는 다른 집계와 달리 쿼리 조건에 부합하는 문서에 대해 집계를 수행하는 것이 아니라, 다른 집계로 생성된 버킷을 참조해서 집계를 수행한다. 집계 또는 중첩된 집계를..
coding-start.tistory.com
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3 (0) | 2019.09.20 |
|---|---|
| Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2 (1) | 2019.09.20 |
| Elasticsearch - Rest High Level Client를 이용한 Index Template 생성 (0) | 2019.06.27 |
| ELK Stack - Logstash(로그스태시)를 이용한 로그 수집 (1) | 2019.06.26 |
| ELK Stack - Filebeat(파일비트)란? 간단한 사용법 (1) | 2019.06.17 |

MongoDB에서는 여러 명령을 하나의 트랜잭션으로 묶어서 사용할 수 없다. 그 이유는 몽고디비는 단일 문서 단위의 트랜잭션만 지원되기 때문이다. 이때문에 변경 직전이나 직후의 문서 데이터를 확인하기란 쉽지 않다. 사실 일반적으로 응용 프로그램에서 변경 직후의 데이터는 자신이 직접 변경한 데이터이므로 크게 필요없을 수 있지만, 변경 직전의 데이터를 확인하는 기능은 필요할 수 있다. 이러한 기능을 제공하기 위해서 몽고디비는 FindAndModify라는 명령을 제공한다. 해당 명령은 검색 조건에 일치하는 문서를 검색하고, 그 문서를 변경하거나 삭제하는 후속 오퍼레이션을 설정할 수 있다.
> db.collection.findAndModify({
query:<document>,
sort:<document>,
remove:<boolean>,
update:<document>,
new:<boolean>,
fields:<document>,
upsert:<boolean>,
bypassDocumentValidation:<boolean>,
writeConcern:<document>,
collation:<document>
});
위는 findAndModify 사용법이다. 주의해야할 점은 FindAndModify 명령의 조건에 일치하는 문서는 여러개 일 수 있다. 하지만 해당 명령은 반드시 하나의 문서만 변경 혹은 삭제하고, 변경된 도큐먼트를 반환한다. 만약 해당 명령의 조건에 일치하는 도큐먼트 중에서 특정 도큐먼트를 변경하거나 삭제하고 싶다면 sort옵션을 사용하면 된다.
| 옵션 | 설명 |
| query | 변경하고자 하는 도큐먼트를 검색할 조건을 명시한다. 주어진 조건에 일치하는 도큐먼트가 여러 개라 하더라도 그 중에서 첫 번째로 검색된 문서에 대해서만 변경 또는 삭제 작업을 수행한다. |
| sort | 검색된 문서가 여러 개일 때, 실제 몽고디비서버가 어떤 문서를 변경했는지 명확히 판단이 힘들다. 그래서 검색 조건에 일치하는 문서가 여러 개일 것이라고 예상될 때, sort 옵션을 이용해서 변경 또는 삭제할 문서를 조정할 수 있다. |
| remove | 검색된 문서 결과를 삭제한다. 기본 값은 false이며, 이 값을 true로 설정하면 몽고디비 서버는 검색 결과를 삭제한다. 만약 upsert 옵션을 설정하면 해당 옵션은 설정이 되지 않거나 false로 설정해야 한다. 하나의 findAndModify 명령으로 update,delete를 동시에 할 수 없다. |
| update | 검색된 문서를 어떻게 변경할 지 설정한다. update 쿼리의 두번째 인자처럼 사용하면 된다. |
| new | findAndModify 명령은 검색된 문서를 변경하거나 삭제하고, 변경하거나 삭제된 문서를 반환한다. 이때 삭제 또는 변경되기 직전의 문서를 반환할지 아니면 변경 또는 삭제된 이후의 문서를 반환할 것인지 new 옵션으로 결정한다. 기본값은 false이며, true로 설정하면 변경 직후의 문서가 반환된다. |
| fields | 결과로 반환되는 문서의 Projection을 설정한다. 즉, 결과로 반환될 문서의 노출 필드를 지정하는 것이다. |
| upsert | 검색결과가 있으면 update, 없다면 insert를 수행한다. |
| bypassDocumentValidation | 몽고디비는 삽입,수정 시점에 필드에 대한 유효성 체크 지정이 가능한데, 해당 옵션을 통해 문서 유효성 검사를 건너 뛰게 설정한다. |
| writeConcern | 변경 또는 삭제 작업의 writeConcern을 조정한다. |
| maxTimeMS | findAndModify 명령이 실행될 최대 시간을 밀리초 단위로 설정한다. |
| collation | 문서 검색시 사용할 콜레이션을 지정한다. |
upsert와 new 옵션 값에 대한 결과값이다.
| new = false | new = true | |
| upsert = false | 변경되기 전 문서 반환, 검색 결과가 없으면 Null | 검색된 결과가 있으면 변경된 직후의 문서 반환, 검색 결과가 없으면 Null |
| upsert = true | 변경되기 전 문서 반환, 검색 결과가 없으면 Null | 검색된 결과가 있으면 변경된 직후의 문서 반환, 검색된 결과가 없으면 Insert된 문서 반환 |
upsert 옵션이 true인 findAndModify 명령과 update 명령과 아주 유사해보인다. 이 둘의 차이점은 아래와 같다.
- 디폴트 옵션에서는 두 명령보두 하나의 문서만 변경할 수 있다. 하지만 update 명령은 multi 옵션을 true로 설정해서 여러 문서를 한번에 변경할 수 있다.
- update 명령은 실제 어떤 문서를 변경할지 알 수없다.(매칭된 문서가 여러개일때) 하지만 findAndModify는 sort 옵션을 통해 특정 문서를 정렬해 첫 번째 문서만 변경할 수 있다.
- update명령은 처리 결과를 반환하지만, findAndModify는 변경전 혹은 직후의 문서를 결과로 반환한다.
> db.users.insertMany([{name:"abc",age:22},{name:"yeoseong",age:28},{name:"sora",age:30},{name:"mija",age:50}])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5d83050d04a68b589a9c1aa5"),
ObjectId("5d83050d04a68b589a9c1aa6"),
ObjectId("5d83050d04a68b589a9c1aa7"),
ObjectId("5d83050d04a68b589a9c1aa8")
]
}
> db.collection.findAndModify({
... query:{name:"abc"},
... sort:{name:1},
... remove:false,
... update:{$set:{name:"cba"}},
... new:true,
... fields:{_id:0,name:1,age:1},
... upsert:false,
... bypassDocumentValidation:false})
위와 같이 문서를 삽입하고 findAndModify 명령을 수행했다. 결과 값으로는 아래와 같다.

new를 true로 적용했고, 프로젝션은 이름과 나이로 적용했으므로 변경된 직후의 문서가 결과로 반환된다. 반대로 적용해보자.
> db.collection.findAndModify({
... query:{name:"cba"},
... sort:{name:1},
... remove:false,
... update:{$set:{name:"abc"}},
... new:false,
... fields:{_id:0,name:1,age:1},
... upsert:false,
... bypassDocumentValidation:false})

결과로 변경되기 전의 문서가 반환되었다. 간단한 예제이지만, 다양하게 옵션을 적용해보며 사용해보면 추후에 유용하게 사용될 명령일 듯하다. 그리고 잘만 사용한다면 insert,update,delete를 해당 명령으로만 사용가능하지 않을까? 물론 문서하나씩만 수행되는 명령이지만..또한 성능이 어쩔지는 모르지만..
'Database > MongoDB' 카테고리의 다른 글
| MongoDB - 백업하고 복구하기(mongodump&mongorestore) (1) | 2020.08.16 |
|---|---|
| DB - MongoDB 맵리듀스(Map Reduce) (0) | 2019.09.21 |
| DB - MongoDB OperationFailed Sort operation used more than the maximum 33554432 bytes of Ram. (0) | 2019.09.19 |
| DB - MongoDB Insert Ordered 옵션은? (0) | 2019.09.19 |
| DB - MongoDB Text Search(본문 검색) (0) | 2019.09.16 |

해당 예외는 정렬시 사용되는 메모리 크기에 관한 예외이다. find로 데이터를 조회한 후에 sort()를 통해서 정렬을 할때, 만약 인덱스를 이용해서 정렬을 수행할 수 있을 때는 메모리 크기와 크게 관계가 없지만, sort() 옵션이 인덱스를 사용할 수 없을 때는 MongoDB 서버가 쿼리를 실행하는 도중에 퀵소트를 실행해서 find 명령의 결과 도큐먼트를 정렬한 다음 클라이언트에게 응답한다. 이때 정렬을 위한 추가적인 큰 메모리 공간이 필요하다. 몽고디비 서버는 기본값으로 정렬을 수행할때 사용할 수 있는 메모리값이 대략 32MB이다. 즉, 아주 큰 결과 도큐먼트들을 정렬할 때는 해당 값(32MB)을 초과하여 위와 같은 예외를 발생시킬 수 있다.
이렇게 메모리 공간이 부족해서 정렬을 수행하지 못하는 경우에는 3가지 정도의 해결방법이 있다. 정확히는 해결방법이라기 보다는 우회방법이라고도 볼 수 있을 것 같다.
-
정렬 작업이 인덱스 필드를 활용할 수 있게 쿼리를 변경
-
정렬을 위한 메모리 공간을 더 크게 설정
-
find() 대신 aggregate()를 사용하고 allowDiskUse 옵션을 true로 설정
> use admin
> db.runCommand({setParameter:1,internalQueryExecMaxBlockingSortBytes:1024*1024*1024})
> db.collection.aggregate([$sort:{field:1}],{allowDiskUse:true})
추가적으로 정렬을 위해 할당된 메모리는 쿼리가 완전히 완료되기 전까지는 운영체제에 자원을 반납하지 않는다. 즉, 클라이언트의 쿼리의 결과를 모두 가져가지 전까지는 정렬을 위해서 할당된 메모리 공간이 반납되지 못한다는 것이다. 만약 클라이언트가 나머지 결과가 더 필요하지 않아 커서에 도큐먼트가 남아 있는 상태로 방치한다면 커서 타임아웃(기본값 10분)이 나기전까지는 메모리에 그대로 남아있게 된다.
그래서 쿼리의 실행 결과로 전달받은 커서는 반드시 모든 도큐먼트를 클라이언트로 가져오거나, 그렇지 않고 더 이상 필요하지 않아서 도큐먼트 패치를 중간에 멈추는 경우에는 커서를 반드시 닫아주는 게 좋다.
'Database > MongoDB' 카테고리의 다른 글
| DB - MongoDB 맵리듀스(Map Reduce) (0) | 2019.09.21 |
|---|---|
| DB - MongoDB FindAndModify 란? (0) | 2019.09.19 |
| DB - MongoDB Insert Ordered 옵션은? (0) | 2019.09.19 |
| DB - MongoDB Text Search(본문 검색) (0) | 2019.09.16 |
| DB - MongoDB와 자주 사용되는 SQL 비교 (0) | 2019.09.16 |