
'2020/04'에 해당되는 글 11건
- 2020.04.29 :: Spring - application.yaml(.properties) 파일 로드 규칙 및 순서
- 2020.04.29 :: Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)!
- 2020.04.22 :: 네트워크(DNS) - A record와 CNAME의 차이점!(DNS Record Type)
- 2020.04.21 :: Docker - DOOD로 띄웠을 경우 proxy(프록시) 설정
- 2020.04.21 :: Java - 중첩이 많은 Stream 처리 Tip !
- 2020.04.20 :: Docker - Docker 다른 레포지토리에 push하기
- 2020.04.16 :: Elasticsearch - Elasticsearch custom docker image 빌드(엘라스틱서치 커스텀 도커 이미지 생성)
- 2020.04.12 :: Network - Proxy(프록시)와 Gateway(게이트웨이)란? 이 둘의 차이점은?

오늘 다루어볼 내용은 spring application.yaml(properties)파일들의 로드 규칙 및 순서이다. 기본적인 내용일수는 있겠지만 필자는 이번에 해당 순서의 중요성을 다시 한번 알게되서 한번더 정리해보려고 한다.
Spring Boot Features
If you need to call remote REST services from your application, you can use the Spring Framework’s RestTemplate class. Since RestTemplate instances often need to be customized before being used, Spring Boot does not provide any single auto-configured RestT
docs.spring.io
위 링크를 보면 PropertySource의 적용 순서가 나와있다. 우리가 신경 쓸 것은 application.properties와 application-{profiles}.properties의 순서이다. 위 링크에서는 application-{profiles}.properties가 더 우선 순위를 갖는다고 이야기하고 있다. 그 말은 무엇일까? 아래 간단히 application.properties 파일을 확인해보자.
#application.yaml
spring:
application:
name: name-1
#application-dev.yaml
spring:
application:
name: name-2
과연 위 yaml파일들을 모두 적용하고 나서 아래 코드를 실행한다면 어떤 값이 출력될까? 실행할때 VM option에
"-Dspring.profiles.active=dev"
을 넣어서 run 해야한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Slf4j
@RestController
@SpringBootApplication
public class JenkinsSampleApplication implements CommandLineRunner {
@Value("${spring.application.name}")
private String appName;
public static void main(String[] args) {
SpringApplication.run(JenkinsSampleApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
log.info(appName);
}
}
|
cs |
결과는 "name-2"가 출력된다. 그 말은 application-{profiles}.yaml이 우선 적용이 된다는 뜻이다. 그렇다면 아래와 같은 config가 있다면 어떨까?
#application.yaml
spring:
application:
name: name-1
#application-dev.yaml
spring:
profiles:
include: dev-common
application:
name: name-2
#application-dev-common.yaml
spring:
application:
name: name-3
출력결과는 "name-3"이다. 그 말은 application-dev.yaml에서 include한 application-dev-common.yaml이 가장 큰 우선순위를 갖는 것이다.
#application.yaml
spring:
profiles:
include: dev-common
application:
name: name-1
#application-dev.yaml
spring:
application:
name: name-2
#application-dev-common.yaml
spring:
application:
name: name-3
위 파일은 application-dev-common.yaml파일을 application.yaml에 include하였다. 이때 결과는 어떻게 될것인가? "name-2"를 출력할 것이다. 그 이유는 application.yaml에서 include했지만 application-dev.yaml이 더 우선순위를 갖기 때문이다. 즉, include된 설정값이 가장 우선순위를 갖기 위해서는 application-{profiles}.yaml에 include해야한다.
(만약 application-{profiles}.yaml이 없었다면 application-dev-common.yaml의 설정인 "name-3" 설정이 적용이 될것이다.)
해당 규칙들을 잘 활용해서 관리하기 쉽게 설정값들을 유지하면 좋을 것 같다. 여기까지 간단하게 spring application 설정의 적용 규칙 및 순서에 대해 다루어보았다.
'Web > Spring' 카테고리의 다른 글
| Spring Data - 여러 spring data module을 사용할때 레퍼런스 (0) | 2020.06.25 |
|---|---|
| Springboot - reactive mongo driver 사용시 ClusterSettings 시 유의사항 (0) | 2020.05.15 |
| Springboot - Spring webflux handler test(웹플럭스 핸들러 테스트), WebTestClient (0) | 2020.03.20 |
| Springboot - @CacheEvict 사용시 주의점, Spring cache(@Cacheable,@CacheEvict) (1) | 2020.03.03 |
| Springboot - junit을 이용한 DB관련 테스트 작성하는 방법, embedded mongo를 이용한 테스트 (1) | 2020.03.01 |

오늘 다루어볼 내용은 Model mapping을 아주 쉽게 해주는 Mapstruct라는 라이브러리를 다루어볼 것이다. 그 전에 Model mapping에 많이 사용되는 ModelMapper와의 간단한 차이를 이야기해보면, Model Mapper는 Runtime 시점에 reflection으로 모델 매핑을 하게 되는데, 이렇게 런타임시에 리플렉션이 자주 이루어진다면 앱성능에 아주 좋지 않다. 하지만 Mapstruct는 컴파일 타임에 매핑 클래스를 생성해줘 그 구현체를 런타임에 사용하는 것이기 때문에 앱 사이즈는 조금 커질수 있지만 성능상 크게 이슈가 없어서 ModelMapper보다 더 부담없이 사용하기 좋다. 그리고 아주 다양한 기능을 제공하기 때문에 조금더 세밀한 매핑이 가능해진다.
바로 간단하게 Mapstruct를 맛보자.
build.gradle
build.gradle를 채워넣어보자 !
buildscript {
ext {
mapstructVersion = '1.3.1.Final'
}
}
...
// Mapstruct
implementation "org.mapstruct:mapstruct:${mapstructVersion}"
annotationProcessor "org.mapstruct:mapstruct-processor:${mapstructVersion}"
testAnnotationProcessor "org.mapstruct:mapstruct-processor:${mapstructVersion}"
...
compileJava {
options.compilerArgs = [
'-Amapstruct.suppressGeneratorTimestamp=true',
'-Amapstruct.suppressGeneratorVersionInfoComment=true'
]
}
Java
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class CarDto {
private String name;
private String color;
}
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class Car {
private String modelName;
private String modelColor;
}
@Mapper
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
Car to(CarDto carDto);
}
|
cs |
사실 간단한 것이라, 어노테이션만 보아도 어떠한 기능을 제공하는지 확실하다. 하지만 각 클래스에 getter/setter 및 기본생성자는 꼭 생성해주자.(필드명이 동일할 일은 많이 없겠지만, 각 객체의 필드명이 동일하면 @Mapping 어노테이션은 생략가능하다.) 해당 코드로 테스트코드를 간단하게 작성하자.
|
1
2
3
4
5
6
7
8
9
10
11
|
public class MapstructTest {
@Test
public void test() {
CarDto carDto = CarDto.of("bmw x4", "black");
Car car = CarMapper.INSTANCE.to(carDto);
assertEquals(carDto.getName(), car.getModelName());
assertEquals(carDto.getColor(), car.getModelColor());
}
}
|
cs |
테스트가 성공하는 것을 볼 수 있다. 아주 간단하면서도 파워풀한 라이브러리인 것 같다. 그러면 실제로 생성된 코드를 한번 볼까?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
public class CarMapperImpl implements CarMapper {
@Override
public Car to(CarDto carDto) {
if ( carDto == null ) {
return null;
}
Car car = new Car();
car.setModelName( carDto.getName() );
car.setModelColor( carDto.getColor() );
return car;
}
}
|
cs |
우리가 작성하지 않았지만, 코드가 생성되었다. 리플렉션과 같이 비용이 큰 기술이 사용되지 않았다. 간단한 validation 코드와 생성자, getter, setter 코드 뿐이다. 이제 더 많은 Mapstruct 기능들을 살펴보자.
하나의 객체로 합치기
여러 객체의 필드값을 하나의 객체로 합치기가 가능하다. 특별히 다른 옵션을 넣는 것은 아니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class UserDto {
private String name;
}
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class AddressDto {
private String si;
private String dong;
}
@Mapper
public interface UserInfoMapper {
UserInfoMapper INSTANCE = Mappers.getMapper(UserInfoMapper.class);
@Mapping(source = "user.name", target = "userName")
@Mapping(source = "address.si", target = "si")
@Mapping(source = "address.dong", target = "dong")
UserInfo to(UserDto user, AddressDto address);
}
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
public class UserInfoMapperImpl implements UserInfoMapper {
@Override
public UserInfo to(UserDto user, AddressDto address) {
if ( user == null && address == null ) {
return null;
}
UserInfo userInfo = new UserInfo();
if ( user != null ) {
userInfo.setUserName( user.getName() );
}
if ( address != null ) {
userInfo.setDong( address.getDong() );
userInfo.setSi( address.getSi() );
}
return userInfo;
}
}
|
cs |
이미 생성된 객체에 매핑
새로운 인스턴스를 생성하는 것이 아니라, 기존에 이미 생성되어 있는 객체에 매핑이 필요한 경우이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
@Mapper
public interface UserInfoMapper {
UserInfoMapper INSTANCE = Mappers.getMapper(UserInfoMapper.class);
@Mapping(source = "user.name", target = "userName")
@Mapping(source = "address.si", target = "si")
@Mapping(source = "address.dong", target = "dong")
void write(UserDto user, AddressDto address, @MappingTarget UserInfo userInfo);
}
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
public class UserInfoMapperImpl implements UserInfoMapper {
@Override
public void write(UserDto user, AddressDto address, UserInfo userInfo) {
if ( user == null && address == null ) {
return;
}
if ( user != null ) {
userInfo.setUserName( user.getName() );
}
if ( address != null ) {
userInfo.setDong( address.getDong() );
userInfo.setSi( address.getSi() );
}
}
}
|
cs |
타입 변환
대부분의 암시적인 자동 형변환이 가능하다. (Integer -> String ...) 다음은 조금 유용한 기능이다.
|
1
2
3
4
5
6
7
8
9
|
@Mapper
public interface CarMapper {
@Mapping(source = "price", numberFormat = "$#.00")
CarDto carToCarDto(Car car);
@IterableMapping(numberFormat = "$#.00")
List<String> prices(List<Integer> prices);
}
|
cs |
만약 클래스에 있는 List<Integer> 필드값을 List<String>의 다른 포맷으로 변경하고 싶다면 @IterableMapping 어노테이션을 이용하자. 위와 비슷하게 날짜 데이터를 문자열로 변환하는 dateFormat이라는 옵션도 존재한다.
Source, Target mapping policy
매핑될 필드가 존재하지 않을 때, 엄격한 정책을 가져가기 위한 기능을 제공한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
ja@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class Car {
private String modelName;
private String modelColor;
private String modelPrice;
private String description;
}
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class CarDto {
private String name;
private String color;
private Integer price;
}
@Mapper(unmappedTargetPolicy = ReportingPolicy.ERROR)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
Car to(CarDto carDto);
}
|
cs |
위 코드는 타겟이 되는 오브젝트 필드에 대한 정책을 가져간다. Car 클래스에는 description 필드가 있는데, CarDto 클래스에는 해당 필드가 존재하지 않기때문에 컴파일시 컴파일에러가 발생한다.(ERROR, IGNORE, WARN 정책존재) 만약 특정 필드는 해당 정책을 피하고 싶다면 아래와 같이 어노테이션하나를 달아준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
@Mapper(unmappedTargetPolicy = ReportingPolicy.ERROR)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(target = "description", ignore = true)
Car to(CarDto carDto);
}
|
cs |
null 정책
Source가 null이거나 혹은 Source의 특정 필드가 null일때 적용가능한 정책이 존재한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_DEFAULT
)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(target = "description", ignore = true)
Car to(CarDto carDto);
}
|
cs |
위 코드는 Source 오브젝트가 null일때, 기본생성자로 필드가 비어있는 Target 오브젝트를 반환해준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_NULL
)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(
source = "description",
target = "description",
ignore = true,
nullValuePropertyMappingStrategy = NullValuePropertyMappingStrategy.SET_TO_DEFAULT
)
Car to(CarDto carDto);
}
|
cs |
위 코드는 각 필드에 대해 null 정책을 부여한다. 만약 SET_TO_DEFAULT로 설정하면, List 일때는 빈 ArrayList를 생성해주고, String은 빈문자열, 특정 오브젝트라면 해당 오브젝트의 기본 생성자 등으로 기본값을 생성해준다.
특정 필드 매핑 무시
특정 필드는 매핑되지 않길 원한다면 @Mapping 어노테이션에 ignore = true 속성을 넣어준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_NULL
)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(target = "description", ignore = true)
Car to(CarDto carDto);
}
public class MapstructTest {
@Test
public void test() {
CarDto carDto = CarDto.of(
"bmw x4",
"black",
10000,
"description");
Car car = CarMapper.INSTANCE.to(carDto);
System.out.println(car.toString());
}
}
result =>
Car(modelName=bmw x4, modelColor=black, modelPrice=$10000.00, description=null)
|
cs |
매핑 전처리, 후처리
매핑하기 이전과 매핑 이후 특정 로직을 주입시킬 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_NULL,
componentModel = "spring"
)
public abstract class CarMapper {
@BeforeMapping
protected void setColor(CarDto carDto, @MappingTarget Car car) {
if (carDto.getName().equals("bmw x4")) {
car.setModelColor("red");
} else {
car.setModelColor("black");
}
}
@Mapping(source = "name", target = "modelName")
@Mapping(target = "modelColor", ignore = true)
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
public abstract Car to(CarDto carDto);
@AfterMapping
protected void setDescription(@MappingTarget Car car) {
car.setDescription(car.getModelName() + " " + car.getModelColor());
}
}
<Generate Code>
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
@Component
public class CarMapperImpl extends CarMapper {
@Override
public Car to(CarDto carDto) {
if ( carDto == null ) {
return null;
}
Car car = new Car();
setColor( carDto, car );
car.setModelName( carDto.getName() );
if ( carDto.getPrice() != null ) {
car.setModelPrice( new DecimalFormat( "$#.00" ).format( carDto.getPrice() ) );
}
car.setDescription( carDto.getDescription() );
setDescription( car );
return car;
}
}
|
cs |
전처리와 후처리를 위한 메서드는 private을 사용해서는 안된다. 그 이유는 generate된 코드에 전,후 처리 메서드가 들어가는 것이 아니라 추상 클래스에 있는 메서드를 그대로 사용하기 때문이다.
이외에도 지원하는 기능이 너무 많다.. 다 못쓰겠다. 아래 공식 레퍼런스를 살펴보자..
MapStruct 1.3.1.Final Reference Guide
The mapping of collection types (List, Set etc.) is done in the same way as mapping bean types, i.e. by defining mapping methods with the required source and target types in a mapper interface. MapStruct supports a wide range of iterable types from the Jav
mapstruct.org
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - 자바 클로져(Closure) & 커링(currying) (0) | 2020.07.22 |
|---|---|
| Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스) (0) | 2020.05.14 |
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |
| Java - CopyOnWriteArraySet 클래스 (0) | 2019.12.19 |
| Java - HashMap 동작 방법(jdk1.7,1.8 차이점) (0) | 2019.08.05 |

오늘 다루어볼 내용은 DNS Record type중에 A record와 CNAME의 차이점을 간단하게 다루어본다.
A record
DNS의 레코드 타입중에 A record type이란 간단하게 도메인(domain) name에 IP Address를 매핑하는 방법이다.
> nslookup coding-start.tistory.com
Server: 10.20.30.60
Address: 10.20.30.60#53
Non-authoritative answer:
Name: coding-start.tistory.com
Address: 211.231.99.250
위 nslookup <domain> 명령을 치면 211.231.99.250이라는 IP가 매핑되어 있는 것을 볼 수 있다. IP 매핑은 VIP로 매핑하여 여러 IP를 하나의 도메인에 매핑할 수도 있고, A 타입 레코드에 각 서버의 IP를 여러개 넣을 수도 있다.
#VIP?
VIP는 하나의 호스트에 여러 개의 IP주소를 할당하는 기술이다. 이 기술을 이용하면,
하나의 네트워크 인터페이스에 여러 개의 IP 주소를 줄 수 있다.
바깥에서는 마치 하나 이상의 네트워크 인터페이스가 있는 것으로 보일 것이다.
VIP는 흔히 HA나 로드밸런싱을 위해서 널리 사용된다.
vip : 211.231.99.250
ip list : a.b.c.d, d.a.e.s, d.e.a.h, d.e.a.a ...
CNAME(Canonical Name)
Canonical Name의 줄임말로 하나의 도메인에 도메인 별칭을 부여하는 방식이다. 즉, 도메인의 또 다른 도메인 이름으로 생각하면 좋을 것 같다.
coding-start.com -> coding-start.tistory.com (CNAME)
coding-start.tistory.com -> 211.231.99.250 (A record)
A record는 직접적으로 IP가 할당되어 있기 때문에 IP가 변경되면 직접적으로 도메인에 영향을 미치지만, CNAME은 도메인에 도메인이 매핑되어 있기 때문에 IP의 변경에 직접적인 영향을 받지 않는다.
여기까지 간단하게 A record와 CNAME의 차이점을 알아보았고, 혹시나 DNS record의 여러가지 type을 보고 싶다면 아래 위키 페이지를 참조하자.
List of DNS record types - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search This list of DNS record types is an overview of resource records (RRs) permissible in zone files of the Domain Name System (DNS). It also contains pseudo-RRs. Resource records[edit] Ty
en.wikipedia.org
'인프라 > 네트워크(기초)' 카테고리의 다른 글
| [HTTP, HTTPS] x-forwarded-for(XFF) header (0) | 2023.04.07 |
|---|---|
| Network - Proxy(프록시)와 Gateway(게이트웨이)란? 이 둘의 차이점은? (0) | 2020.04.12 |
| 네트워크 - GSLB(Global Server Load Balancing)란? (2) | 2020.04.07 |
| OS - ssh 비밀번호 없이 접속하기 (0) | 2019.08.04 |
| 네트워크 - HTTP/HTTPS 차이점, HTTPS란? (0) | 2019.08.01 |

이번 포스팅에서 다루어볼 내용은 DOOD로 도커를 띄웠을 때, proxy 설정하는 방법이다. 그전에 간단하게 Docker in Docker(dind)와 Docker Out Of Dcoker(DooD)에 대해 알아보자.
Docker in Docker(dind)
도커 내부에 격리된 Docker 데몬을 실행하는 방법이다. CI(Jenkins docker agent) 측면에서 접근하면 Agent가 Docker client와 Docker Daemon 역할 두가지를 동시에 하게 된다. 하지만 이 방법은 단점이 존재한다. 내부의 도커 컨테이너가 privileged mode로 실행되어야 한다.
> docker run --privileged --name dind -d docker:1.8-dind
privileged 옵션을 사용하면 모든 장치에 접근할 수 있을뿐만 아니라 호스트 컴퓨터 커널의 대부분의 기능을 사용할 수 있기 때문에 보안에 좋지않은 방법이다. 하지만 실제로 실무에서 많이 쓰는 방법이긴하다.
Docker out of Docker(dood)
Docker out of Docker는 호스트 머신에서 동작하고 있는 Docker의 Docker socket과 내부에서 실행되는 Docker socket을 공유하는 방법이다. 간단하게 볼륨을 마운트하여 두 Docker socket을 공유한다.
> docker run -v /var/run/docker.sock:/var/run/docker.sock ...
이 방식을 그나마 Dind보다는 권장하고 있는 방법이긴하다. 하지만 이 방식도 단점은 존재한다. 내부 도커에서 외부 호스트 도커에서 실행되고 있는 도커 컨테이너를 조회할 수 있고 조작할 수 있기 때문에 보안상 아주 좋다고 이야기할 수는 없다.
DooD proxy 설정
dood로 도커를 띄운 경우, 호스트 머신에 동작하고 있는 도커에 proxy 설정이 되어있어야 내부 도커에도 동일한 proxy 설정을 가져간다.
방법1. /etc/sysconfig/docker에 프록시 설정
> sudo vi /etc/sysconfig/docker
HTTP_PROXY="http://proxy-domain:port"
HTTPS_PROXY="http://proxy-domain:port"
#docker restart
> service docker restart
방법2. 환경변수 설정
> mkdir /etc/systemd/system/docker.service.d
> cd /etc/systemd/system/docker.service.d
> vi http-proxy.conf
[Service]
Environment="HTTP_PROXY=http://proxy-domain:port"
Environment="HTTPS_PROXY=http://proxy-domain:port"
Environment="NO_PROXY=hostname.example.com, 172.10.10.10"
> systemctl daemon-reload
> systemctl restart docker
> systemctl show docker --property Environment
Environment=GOTRACEBACK=crash HTTP_PROXY=http://proxy-domain:port HTTPS_PROXY=http://proxy-domain:port NO_PROXY= hostname.example.com,172.10.10.10
여기까지 dood로 도커 엔진을 띄웠을 때, proxy 설정하는 방법이다.
참고
How to configure docker to use proxy – The Geek Diary
www.thegeekdiary.com
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Docker - 도커 이미지 만들기 ! (Dockerfile) (0) | 2020.07.18 |
|---|---|
| Docker - 도커를 이용해 Single node Kafka 띄우기 (0) | 2020.06.04 |
| Docker - Docker 다른 레포지토리에 push하기 (0) | 2020.04.20 |
| Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때 (0) | 2020.04.09 |
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |

오늘 다루어볼 내용은 자바에서 Stream(java 8 stream, reactor ...)을 사용할때 유용한 팁이다. 많은 사람들이 아는 해결법일 수도 있고, 혹은 필자와 같은 스타일을 선호하지 않는 사람들도 있을 것이다. 하지만 필자가 개발할때 이러한 상황에서 조금 유용했던 Stream pipeline Tip을 간단히 소개한다.
중첩이 많고, 이전 스트림보다 더 이전의 스트림의 결과 값을 사용해야 할때
상황은 아래와 같은데, 간단히 바로 이전 스트림의 결과가 아닌, 더 전의 스트림 원자를 로직에서 사용하려면 대게 아래와 같이 스트림 파이프 라인을 이어나간다.
Mono.just("id")
.flatMap(id ->
return Mono.just(service.getById(id))
.map(entity -> {
...
})
)
파이프라인의 시작인 id 값을 파이프라인의 중간에서 사용하려면 Stream의 pipeline을 점점 안으로 중첩해 나가면서 사용해야한다. 이렇게 된다면 복잡한 로직일 수록 점점 안쪽으로 파고드는 파이프라인이 될 것이다. 그렇다면 훨씬 가독성 좋은 코드는 어떻게 작성해 볼 수 있을까?
Tuple을 사용해서 넘겨주자.
reactor에 있는 Tuple을 사용해서 이전 파이프라인의 값을 뒤로 넘겨줘보자.
void stream() {
Mono.just("id")
.flatMap(str -> {
...
return Mono.just(Tuples.of(str, "str2"));
})
.flatMap(tuple -> {
final String str = tuple.getT1();
...
return Mono.just("result");
})
}
위처럼 튜플을 이용하여 해당 스트림의 결과와 이전 스트림의 결과가 나중에 쓰일 수 있도록 튜플에 값을 넣어서 넘겨준다. 이렇게 파이프라이닝하면 같은 depth로 파이프라인을 이어나갈 수 있기 때문에 가독성이 훨씬 좋다. 만약 튜플을 사용하지 않았다면 점점 depth가 깊어지는 중첩 파이프라인을 이어나가야하기 때문에 가독성도 훨씬 떨어지게 될 것이다.
여기까지 중첩이 많고, 이전 스트림의 결과를 미래 파이프라인에서 사용할 때 이용할 수 있는 팁이었다.
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스) (0) | 2020.05.14 |
|---|---|
| Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)! (0) | 2020.04.29 |
| Java - CopyOnWriteArraySet 클래스 (0) | 2019.12.19 |
| Java - HashMap 동작 방법(jdk1.7,1.8 차이점) (0) | 2019.08.05 |
| Java - Garbage Collection(GC,가비지 컬렉션) 란? (1) | 2019.07.29 |

공식 dockerhub가 아닌, 개인 혹은 사내 dockerhub로 push하는 방법이다. (dockerHubHost가 개인 혹은 사내 도커허브 도메인)
> docker build -t dockerHubHost/levi.yoon/jenkins_example
> docker push dockerHubHost/levi.yoon/jenkins_example
뭔가 다른 방법이 있을 것 같긴한대.. 간단하게 위 방법으로도 가능하다 !
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Docker - 도커를 이용해 Single node Kafka 띄우기 (0) | 2020.06.04 |
|---|---|
| Docker - DOOD로 띄웠을 경우 proxy(프록시) 설정 (0) | 2020.04.21 |
| Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때 (0) | 2020.04.09 |
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |
| Kubernetes - Kubernetes 아키텍쳐 (0) | 2019.11.26 |

이번에 다루어볼 포스팅은 도커로 ES를 띄우기전에 뭔가 커스텀한 이미지를 만들어서 올릴수없을까 하는 생각에 간단히 ES 기본 이미지에 한글 형태소 분석기(Nori) 플러그인이 설치가된 ES docker image를 커스텀하게 만들어보았다.
#Dockerfile
FROM docker.elastic.co/elasticsearch/elasticsearch:7.6.2
ENV ES_VOLUME=/usr/share/elasticsearch/data
ENV ES_BIN=/usr/share/elasticsearch/bin
RUN mkdir $ES_VOLUME/dictionary
RUN $ES_BIN/elasticsearch-plugin install --batch analysis-nori
간단히 설명하면, 베이스 이미지로 공식 elasticsearch image를 사용하였고, 나중에 사용자 사전이 위치할 도커 볼륨 디렉토리를 잡아주었고, 거기에 사전이 담기는 디렉토리를 생성했다. 그리고 마지막으로 한글 형태소분석기 플러그인을 설치하는 쉘을 실행시켰다. 이렇게 빌드된 elasticsearch image는 한글 형태소분석기가 이미 설치가된 elasticsearch image가 된다. 그래서 굳이 plugin directory를 마운트해서 직접 플러그인을 설치할 필요가 없다. 물론 추후에 필요에 의해서 설치해야한다면 어쩔수 없지만 말이다.
여기에 추후 더 커스텀할 내용을 넣으면 될듯하다.
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - 클러스터, 샤드, 인덱스 상태 확인하기 (0) | 2020.08.25 |
|---|---|
| Elasticsearch - 퍼포먼스 튜닝하는 방법 by ebay (1) | 2020.08.19 |
| Elasticsearch - 한글 자동완성(Nori Analyzer, Ngram, Edge Ngram) (0) | 2020.04.09 |
| Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3 (0) | 2019.09.20 |
| Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2 (1) | 2019.09.20 |
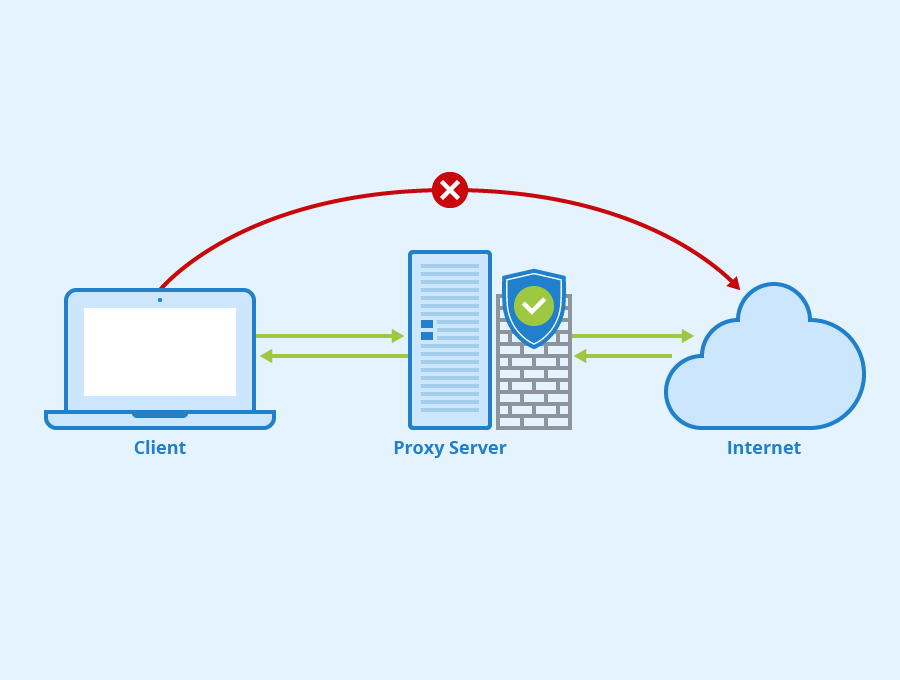
필자는 그동안 프록시서버와 게이트웨이를 혼동해서 용어를 많이 사용했었던 것 같다. 사실 글을 쓰는 지금까지도 이 두개의 차이점을 100% 명확히 구분짓기 힘들지만, 범용적으로 사용되는 프록시서버와 게이트웨이를 뜻을 알아본다.
Proxy Server(프록시 서버)
위키에는 프록시 서버에 대한 설명이 아래와 같이 나와있다.
프록시 서버는 클라이언트가 자신을 통해서 다른 네트워크 서비스에 간접적으로 접속할 수 있게 해 주는 컴퓨터 시스템이나 응용 프로그램을 가리킨다. 서버와 클라이언트 사이에 중계기로서 대리로 통신을 수행하는 것을 가리켜 '프록시', 그 중계 기능을 하는 것을 프록시 서버라고 부른다.
프록시 서버 중 일부는 프록시 서버에 요청된 내용들을 캐시를 이용하여 저장해 둔다. 이렇게 캐시를 해 두고 난 후에, 캐시 안에 있는 정보를 요구하는 요청에 대해서는 원격 서버에 접속하여 데이터를 가져올 필요가 없게 됨으로써 전송 시간을 절약할 수 있게 됨과 동시에 불필요하게 외부와의 연결을 하지 않아도 된다는 장점을 갖게 된다. 또한 외부와의 트래픽을 줄이게 됨으로써 네트워크 병목 현상을 방지하는 효과도 얻을 수 있게 된다.
HTTP Protocol 관점에서 조금 더 설명을 더하자면, 프록시 서버는 클라이언트와 서버 사이에 위치하여, 클라이언트의 모든 HTTP 요청을 받아 서버에 전달한다.(대개 요청을 수정한 후에) 이 애플리케이션(프록시서버)은 사용자를 위한 프록시로 동작하며 사용자를 대신해서 서버에 접근한다. 프록시는 주로 보안을 위해 사용된다. 즉, 모든 웹 트래픽 흐름 속에서 신뢰할 만한 중개자 역할을 한다. 또한 프록시는 요청과 응답을 필터링한다. 예를 들어 회사 내부망에서 외부로 요청(메이븐, 그래들 라이브러리 다운로드 등)을 신뢰할만한 요청인지 확인해서 회사 내부정책에서 인정한 인가한 서버만 접속가능하도록 하는 등의 기능이다.
밑은 용도에 따른 Proxy server 종류이다.
- Caching Proxy Server : 이전 클라이언트의 요청 내용과 응답 컨텐츠를 저장해 두었다가 동일한 요청이 들어오면 저장된 컨텐츠를 전송한다. 이 방법을 이용하면 높은 트래픽에 대한 대응이 가능하다. 비용 절감 효과도 있을 수 있기 때문에 Caching Proxy를 자주 사용한다.
- Web Proxy : 웹 트래픽에 초점이 맞춰진 Proxy 서버이다. 가장 일반적인 형태를 Web Cache이다. 어떤 프록시 서버는 이기종간의 컨텐츠를 변환하는 일을 하기도 한다.
- Forward Proxy : 일반적으로 사용하는 프록시 방식이다. 프록시 서버는 클라이언트와 애플리케이션 서버사이에 위치하여 클라이언트가 타겟인 서버에 애플리케이션 서비스를 요청할 때, 프록시 서버로 요청을 보내게 된다. 프록시서버는 그 사이에서 중계자 역할을 하게된다.(애플리케이션 서버에게 클라이언트가 누구인지 감춰진다.)
- Reverse Proxy : 기본적인 구성은 Forward Proxy와 동일하지만, 클라이언트는 Proxy Server 뒤에 있는 타겟서버의 URL이 아닌 Proxy Server의 URL로 요쳥한다. 이를 통해 애플리케이션 서버는 외부로부터 감춰지는 효과를 보게된다.(클라이언트에게 애플리케이션 서버가 무엇인지 감춰진다.)
우리가 많이 사용하는 Nginx 같은 녀석도 프록시서버라고 볼수도 있겠다. Nginx는 위에서 설명한 대부분의 기능을 모두다 제공한다.(캐시, 포워드 프록시, 리버스 프록시)
Gateway(게이트웨이)

위키에는 게이트웨이 서버를 아래와 같이 설명한다.
게이트웨이는 컴퓨터 네트워크에서 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 컴퓨터나 소프트웨어를 두루 일컫는 용어, 즉 다른 네트워크로 들어가는 입구 역할을 하는 네트워크 포인트이다. 넓은 의미로는 종류가 다른 네트워크 간의 통로의 역할을 하는 장치이다. 또한 게이트웨이를 지날 때마다 트래픽(traffic)도 증가하기 때문에 속도가 느려질 수 있다. 쉽게 예를 들자면 해외여행을 들 수 있는데 해외로 나가기 위해서 꼭 통과해야하는 공항이 게이트웨이와 같은 개념이다.
즉, 게이트웨이는 서로 다른 네트워크 상의 통신 프로토콜(protocol,통신규약)을 적절히 변환해주는 역할을 한다.
게이트웨이는 프록시 서버와 비슷하게 클라이언트(혹은 서버)와 서버끼리 통신 사이에 중개자로 동작하는 서비스이다. 하지만 용도가 조금 다르다. 게이트웨이는 주로 HTTP 트래픽을 다른 프로토콜로 변환하기 위해 사용한다. 마치 게이트웨이는 언제나 스스로가 리소스를 갖고 있는 진짜 서버인 것처럼 요청을 다룬다. 클라이언트는 자신이 게이트웨이와 통신하고 있음을 알아채지 못할 것이다.
두 컴퓨터가 네트워크 상에서 서로 연결되려면 동일한 통신 프로토콜을 사용해야 하는데, 만약 요청은 HTTP 요청이고 백엔드에서 데이터를 가져오려면 FTP 통신이 필요하다면 중간에 게이트웨이가 두 프로토콜을 호환가능하도록 HTTP->FTP, FTP->HTTP를 대신 해주는 대행자가 되는 것이다.
Gateway(게이트웨이)
각각의 의미가 무엇이며 용도에 대해 알아보니 둘의 차이점을 조금이나마 알수 있었다. 둘다 중개자 역할임은 동일하지만 각각의 용도가 다르다는 것을 차이점으로 볼 수 있을 것 같다.
프록시 서버는 컨텐트 캐시, 보안, 필터링 등의 역할을 하는 중개자라면 게이트웨이는 서로 다른 네트워크 통신에서 서로 다른 프로토콜을 호환가능하게 하는 특별한 서버라고 볼 수 있을 것 같다.
여기까지 간단하게 프록시서버와 게이트웨이 서버가 무엇인지 둘의 차이점을 다루어보았다.
'인프라 > 네트워크(기초)' 카테고리의 다른 글
| [HTTP, HTTPS] x-forwarded-for(XFF) header (0) | 2023.04.07 |
|---|---|
| 네트워크(DNS) - A record와 CNAME의 차이점!(DNS Record Type) (0) | 2020.04.22 |
| 네트워크 - GSLB(Global Server Load Balancing)란? (2) | 2020.04.07 |
| OS - ssh 비밀번호 없이 접속하기 (0) | 2019.08.04 |
| 네트워크 - HTTP/HTTPS 차이점, HTTPS란? (0) | 2019.08.01 |