
'프로그래밍언어/Java&Servlet'에 해당되는 글 25건
- 2020.07.30 :: Java - 자바 날짜&시간 java.time 패키지(LocalDateTime, ZoneDateTime)
- 2020.07.29 :: Java - Reactor switchIfEmpty 사용시 주의점(Lambda, 람다 Lazy Evaluation) 2
- 2020.07.22 :: Java - 자바 클로져(Closure) & 커링(currying)
- 2020.05.14 :: Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스)
- 2020.04.29 :: Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)!
- 2020.04.21 :: Java - 중첩이 많은 Stream 처리 Tip !
- 2019.12.19 :: Java - CopyOnWriteArraySet 클래스
- 2019.08.05 :: Java - HashMap 동작 방법(jdk1.7,1.8 차이점)

오늘 다루어볼 내용은 jdk1.8의 날짜&시간을 다루는 java.time 패키지를 다루어볼 것이다. 바로 java.time 패키지 내용을 다루기 전에 우선 프로그래밍에서의 날짜와 시간에 대해 표준인 ISO-8601에 대해 먼저 알아본다.
ISO-8601
<wiki>
ISO 8601 Data elements and interchange formats - Information interchange - Representation of dates and times은 날짜와 시간과 관련된 데이터 교환을 다루는 국제 표준이다. 이 표준은 국제 표준화 기구(ISO)에 의해 공포되었으며 1988년에 처음으로 공개되었다. 이 표준의 목적은 날짜와 시간을 표현함에 있어 명백하고 잘 정의된 방법을 제공함으로써, 날짜와 시간의 숫자 표현에 대한 오해를 줄이고자함에 있는데, 숫자로 된 날짜와 시간 작성에 있어 다른 관례를 가진 나라들간의 데이터가 오갈때 특히 그렇다.
일반적으로, ISO 8601는 그레고리력 (proleptic Gregorian도 가능)에서의 날짜와 (부가적으로 시간대 정보를 포함하는) 24시간제에 기반하는 시간, 시간 간격(time interval) 그리고 그들의 조합에 대한 표현과 형식에 적용된다. 이 표준은 표현할 날짜/시간 요소에 어떠한 특정 의미도 할당하지 않는다; 그 의미는 사용 맥락에 따라 달라질 것이다. 추가로, 표현될 날짜와 시간은 표준 내에서의 지정된 의미의 숫자(예를 들자면, 중국 달력의 년도 이름)가 아니고서는 단어를 포함할 수 없으며 단어들은 문자(예: 이미지, 소리)를 사용하지 않는다.
교환을 위한 표현에서, 날짜와 시간은 재배치되어서, 가장 큰 시간 용어(년도)가 왼쪽에 놓이며 각각의 더 작은 용어들은 이전 용어의 우측에 놓이게 된다. 표현은 아라비아 숫자와 표준 내에서 특정 의미를 제공하는 ("-", ":", "T", "W" 그리고 "Z"와 같은) 어떤 문자들로 작성되어야 한다. 그것이 의미하는 바는, "January" 혹은 "Thursday"처럼 날짜의 일부를 작성하는 어떤 평범한 방법이 교환 표현에서는 허용되지 않는다는 것이다.
참조 : https://ko.wikipedia.org/wiki/ISO_8601
위 내용은 위키 내용을 인용하였는데, 한마디로 세계에서 각기 다른 시간대에서 사용하기 위한 날짜&시간에 대한 표준을 정해놓은 것이다. 포맷으로는 보통 아래와 같은 포맷을 다룬다.(물론 기본형식이 있지만 아래 확장 형식을 대부분 사용하는 듯하다.)
- 날짜(년월일) : YYYY-MM-DD
- 날짜(년월) : YYYY-MM
- 날짜&시간 : YYYY-MM-DDThh:mm:ss(YYYY-MM-DDThh:mm:ss.sss)
- 시간 : hh:mm:ss(hh:mm:ss.sss)
날짜와 시간을 다루는데 아주 중요한 것중 하나는 "표준 시간대 지정자"이다. ISO-8601의 표준 시간대는 (불특정 위치의) "지역 시간"(local time), "UTC" 혹은 "UTC의 오프셋"으로 표현된다.
만약 UTC 관계 정보에 시간 표현이 함께 주어지지 않는다면, 시간은 지역 시간으로 간주된다. 동일한 시간대에서 통신 시 지역 시간을 가정하는 것이 가장 안전할지 몰라도, 시간대가 다른(국가와 국가간 시차) 지역간의 통신에서 지역시간을 사용하는 경우는 아주 모호하게 된다.
(UTC 오프셋이 표현되지 않는다면 해당 시간이 어느나라 기준의 시간인지 알수 없기에 각자 나라의 시간대로 표현이 불가능하다.)
UTC
시간이 UTC인 경우, 시간 뒤에 빈칸없이 "Z" 를 직접 추가해야 한다. Z는 오프셋이 0인 UTC를 위한 지역 지정자이다. 그러므로 "09:30:12"의 UTC는 "09:30:12Z"로 표현된다.
UTC에서의 시간 오프셋
UTC에서의 오프셋은 위에서 Z를 붙였던 것과 동일한 방법으로 시간뒤에 덧붙인다. 우리나라는 기준시보다 9시간이 빠른 나라이기 때문에 시간을 UTC 오프셋으로 표현하게 되면 "09:30:12+09:00"으로 표현하게 된다. 이렇게 UTC 오프셋으로 시간을 표현하게 되면 기준시에 오프셋이 붙어있는 것이기 때문에 해당 시간으로 다른 시간대의 나라의 시간으로도 표현이 명확히 가능하게 된다.(느린 시간대라면 -로 오프셋을 표현한다.)
java.time 패키지의 핵심 클래스
날짜와 시간을 하나로 표현하는 Calendar클래스와 달리, java.time 패키지에서는 날짜와 시간을 별도의 클래스로 분리해 놓았다. 시간을 표현할 때는 LocalTime 클래스를 사용하고, 날짜를 표현할 때는 LocalDate클래스를 사용한다. 그리고 날짜와 시간이 모두 필요할 때는 LocalDateTime클래스를 사용하면 된다. 만약 여기에 Time-Zone까지 다뤄야 한다면, ZonedDateTime클래스를 사용한다.
LocalDateTime은 기본적으로 Time-zone이 없는 형태이다. 그 말은 ZoneOffset을 표기 하지 않는 날짜 형식을 출력해준다. 물론 ZoneOffset을 고려해서 LocalDateTime 오브젝트를 만들수 있다. 하지만 Time-zone이 없는 개념이기 때문에, 아래와 같이 출력이 된다.
LocalDateTime.now() - 2020-07-30T00:38:55.215245
ZonedDateTime.now() - 2020-07-30T00:38:55.215245+09:00[Asia/Seoul]
Jdk1.8 이전의 날짜&시간을 다루는 Calendar는 ZonedDateTime처럼, 날짜와 시간 그리고 시간대까지 모두 가지고 있다. Date와 유사한 클래스로는 Instant가 있는데, 이 클래스는 날짜와 시간을 초 단위(엄밀히는 나노초까지)로 표현한다. 날짜와 시간을 초단위로 표현한 값을 time stamp라고 부르는데, 이 값은 날짜와 시간을 하나의 정수로 표현할 수 있으므로 날짜와 시간의 차이를 계산하거나 순서를 비교하는데 유리해서 데이터 베이스에서 많이 사용한다.(타임스탬프는 타임존에 대한 정보없이 절대적인 시간을 다루기 때문에 아주 명확한 값을 가지게 된다.) 이외에도 날짜를 더 세부적으로 다룰 수 있는 Year, YearMonth, MonthDay와 같은 클래스도 있다.
예제 코드는 millisecond는 조금 다르지만 같은 시간이라 가정하자.
LocalDateTime.now()
-> 2020-07-30T01:04:38.488822
LocalDateTime.ofInstant(Instant.ofEpochMilli(System.currentTimeMillis()), ZoneId.systemDefault())
-> 2020-07-30T01:04:38.490
LocalDateTime.ofInstant(Instant.ofEpochMilli(System.currentTimeMillis()), ZoneId.of("Asia/Seoul"))
-> 2020-07-30T01:04:38.490
LocalDateTime.ofInstant(Instant.ofEpochSecond(System.currentTimeMillis() / 1000), ZoneId.systemDefault())
-> 2020-07-30T01:04:38
LocalDateTime.ofInstant(Instant.ofEpochSecond(System.currentTimeMillis() / 1000), ZoneId.of("Asia/Seoul"))
-> 2020-07-30T01:04:38
LocalDateTime.ofInstant(Instant.ofEpochSecond(System.currentTimeMillis() / 1000), ZoneId.systemDefault()).plusDays(7)
-> 2020-08-06T01:04:38
LocalDateTime.ofEpochSecond(System.currentTimeMillis() / 1000, 0, ZoneOffset.UTC)
-> 2020-07-29T16:04:38
LocalDateTime.ofEpochSecond(System.currentTimeMillis() / 1000, 0, ZoneOffset.ofHours(9))
-> 2020-07-30T01:04:38
ZonedDateTime.now()
-> 2020-07-30T01:04:38.491441+09:00[Asia/Seoul]
LocalDateTime.now().atZone(ZoneId.of("Asia/Seoul"))
-> 2020-07-30T01:04:38.491568+09:00[Asia/Seoul]
작성중...
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - Reactor switchIfEmpty 사용시 주의점(Lambda, 람다 Lazy Evaluation) (2) | 2020.07.29 |
|---|---|
| Java - 자바 클로져(Closure) & 커링(currying) (0) | 2020.07.22 |
| Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스) (0) | 2020.05.14 |
| Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)! (0) | 2020.04.29 |
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |

리액터의 switchIfEmpty라는 메서드를 다루기 전에 자바의 Lazy evaluation(지연 평가)에 대해 다루어보자. 자바는 논리 operation을 평가할때 lazy evaluation을 사용한다. 예제 코드를 예로 들면 아래와 같다.
@Test
void lazyEvaluationTest() {
boolean isLazy = lazyEvaluation();
if (true || isLazy) {
System.out.println("method execute!!!");
}
}
private boolean lazyEvaluation() {
System.out.println("lazy evaluation");
return true;
}
위 테스트에서 결과는 어떻게 될 것인가?
lazy evaluation
method execute!!!
위와 같이 사용하지 않는 boolean 변수이지만, 미리 isLazy를 만들기 위해 메서드를 호출한다. 여기서 사용하지 않는 변수라는 뜻은 자바에서는 논리 operation에서 이미 참 혹은 거짓이라고 판단이 난 논리식이면 나머지 값 자체를 참조하지 않는다. 이 예는 위와 같이 true || isLazy일때, 이미 앞의 true에서 참이 되었기에 뒤의 isLazy 자체를 참조하지 않는다. 이것을 테스트 하기 위해 아래와 같이 코드를 만들어보았다.
@Test
void lazyEvaluationTest() {
if (true || lazyEvaluation()) {
System.out.println("method execute!!!");
}
}
private boolean lazyEvaluation() {
System.out.println("lazy evaluation");
return true;
}
위 예제코드에서는 lazyEvaluation()를 호출자체를 하지 않는다. 그렇다면 아래와 같은 코드는 결과가 어떻게 될까?
@Test
void lazyEvaluationTest() {
System.out.println("before boolean operation");
if (true && lazyEvaluation()) {
System.out.println("method execute!!!");
}
}
private boolean lazyEvaluation() {
System.out.println("lazy evaluation");
return true;
}
결과는 아래와 같다.
before boolean operation
lazy evaluation
method execute!!!
실제 lazyEvaluation()가 필요한 시점에 호출하게 되는 것이다. 여기까지 자바에서 논리 operation은 lazy evaluation 한다는 것은 알았고, 다른 상황에서는 어떻게 될까?
자바는 어떠한 지역변수에 값을 할당할때, 그리고 어떠한 메서드의 매개변수를 만들때는 eager evaluation 전략을 따른다. 그 말은 무엇이냐면 어떠한 메서드를 처리하기 전에 그 메서드의 매개변수의 값이 미리 준비가 되어 있어야한다는 것이다. 아래 예제코드를 한번 살펴보자.
@Test
void eagerEvaluationTest() {
System.out.println(convertBooleanToString(eagerEvaluation(true)));
}
private String convertBooleanToString(final boolean bool) {
System.out.println("convertBooleanToString");
return bool ? "true" : "false";
}
private boolean eagerEvaluation(final boolean bool) {
System.out.println("eager evaluation!!!!");
return bool;
}
위 메서드의 결과는 어떻게 될까?
eager evaluation!!!!
convertBooleanToString
true
convertBooleanToString을 실행시키기전에 매개변수의 값을 미리 만들기 위해서 eagerEvaluation 메서드를 호출해 값을 만든다. 그렇다면 lazy evaluation하게 하려면 어떻게 하면 될까?
@Test
void lazyEvaluationTest2() {
System.out.println(convertBooleanToString(() -> lazyEval(true)));
}
private String convertBooleanToString(final Supplier<Boolean> f) {
System.out.println("convertBooleanToString");
return f.get() ? "true" : "false";
}
private boolean lazyEval(final boolean bool) {
System.out.println("lazy evaluation");
return bool;
}
위와 같이 매개변수로 람다를 전달하면 된다. 람다를 전달하게 되면 해당 람다가 사용되는 시점에 메서드를 호출하기 때문에 lazy하게 프로그래밍하게 할 수 있다. 이것은 꼭 실행하지 않아도될 로직을 처리하지 않게 할 수 있고, 혹은 실행 시점을 뒤로 미룰 수도 있기 때문에 알고 있으면 아주 좋은 개념이 될것이다. 위 예제를 결과는 아래와 같다.
convertBooleanToString
lazy evaluation
true
실행 순서가 바뀐 것을 볼 수 있다. 그리고 매서드의 매개변수로 담기는 메서드의 lazy 로딩하는 것 외에 지역변수의 초기화를 지연 시킬 수 도 있다.
@Test
void lazyEvaluationTest3() {
Supplier<Boolean> supplier = () -> lazyEval(true);
System.out.println("before method");
if (supplier.get()) {
System.out.println("method !!");
}
}
여기까지 자바의 eager, lazy evaluation을 다루어보았고, 이제 본론으로 switchIfEmpty를 사용할때 주의해야할 점을 알아보자 !
@Test
void switchIfEmptyTest() {
Mono.just("str")
.map(s -> {
System.out.println(s);
return s;
})
.switchIfEmpty(defaultStr())
.subscribe();
}
private Mono<String> defaultStr() {
System.out.println("defalutStr");
return Mono.just("default");
}
<console>
defalutStr
str
위 코드를 보면 우리는 보통 Mono.just가 Mono.empty를 리턴하면 switchIfEmpty를 실행하겠지? 라는 생각을 하기 쉽다. 하지만, 실제 동작은 그렇지 않다. 자바에서는 보통 메서드의 매개변수의 값을 미리 결정시켜놓으려한다.(eager evaluation) 그래서 실제 map을 실행하기 전에 switchIfEmpty를 먼저 실행시켜 값을 만들어 놓는다. 만약 switchIfEmpty안에 실행되는 메서드가 비용이 크고, 실제로 Mono.just는 empty를 반환하지 않는다면, 굳이 실행되지 않아도 되는 비싼 비용의 메서드를 호출해야한다. 이럴때는 우리는 lazy evaluation 전략을 사용하여 switchIfEmpty안의 실행을 실제 필요시점으로 미룰 수 있게 하는 것이다.
@Test
void switchIfEmptyTest2() {
Mono.just("str")
.map(s -> {
System.out.println(s);
return s;
})
.switchIfEmpty(Mono.defer(this::lazyDefaultStr))
.subscribe();
}
@Test
void switchIfEmptyTest3() {
Mono.just("str")
.map(s -> {
System.out.println(s);
return s;
})
.switchIfEmpty(Mono.fromSupplier(() -> "defaultStr"))
.subscribe();
}
private Mono<String> lazyDefaultStr() {
System.out.println("defalutStr");
return Mono.just("default");
}
<console>
str
위와 같이 Mono.defer 혹은 Mono.fromSupplier를 사용하면 해당 메서드의 매개변수로 Supplier를 넘기기 때문에 미리 값을 만들어 놓지 않고, 실제 호출되는 시점으로 실행을 지연시킬 수 있다. 위 코드에서는 아예 메서드 호출자체를 하지도 않는다. 필자도 지금까지는 이러한 것을 크게 인지하지 못하고 코딩을 했었는데, 이렇게 lazy programming을 조금 생각하고 코딩하게 된다면 조금이라도 성능향상을 할 수 있지 않을까 생각이 든다.
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - 자바 날짜&시간 java.time 패키지(LocalDateTime, ZoneDateTime) (0) | 2020.07.30 |
|---|---|
| Java - 자바 클로져(Closure) & 커링(currying) (0) | 2020.07.22 |
| Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스) (0) | 2020.05.14 |
| Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)! (0) | 2020.04.29 |
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |

오늘은 클로저(Closure)와 커링(Currying)에 대해 다루어본다. 사실 이전에 자바스크립트를 간단히 공부하면서 봤던 기억이 있는 개념이었는데, 사실 정확한 개념을 알지 못하고 사용했던 것 같은데 이번에 정리해본다.
클로저(Closure)
클로저는 내부함수가 외부함수의 맥락(context)에 접근할 수 있는 것을 뜻한다. 그 뜻은 외부 함수안에 있는 내부 함수가 외부함수의 지역변수를 사용할 수 있다라는 뜻이다. 특이한 것은 외부 함수가 종료되더라도 내부함수에서 참조하는 외부함수의 context는 유지 된다는 것이다. 그것을 간단하게 자바 코드로 짜면 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public class closure {
@Test
void closure() {
final var supplier = outerMethod();
System.out.println(supplier.get());
}
private Supplier<String> outerMethod() {
final String str = "outer method local variable";
return () -> str;
}
}
|
cs |
위 코드를 보면 outerMethod는 Supplier를 반환하는데, 그 내부의 Supplier는 외부 메서드의 지역변수를 참조해 그대로 리턴하고 있다. 그리고 해당 메서드를 사용하는 @Test 메서드를 보자. outerMethod()를 호출했고 그것을 변수로 받고 있는데, 이 시점에는 outerMethod()는 종료되어 소멸되었지만, Supplier를 get하면 이미 종료된 함수의 지역변수를 그대로 출력하고 있다. 어떻게 이미 종료된 외부함수의 지역변수를 참조할 수 있는 것일까? 그 이유는 클로저가 생성되는 시점에 함수 자체가 복사되어 따로 컨텍스트를 유지하기 때문이다. 조금더 자세히 설명하면 익명 클래스에 컨텍스트를 넘겨주는 것이 클로저다. 컴파일러는 이 필요한 정보를 복사해서 넘겨주는데 이를 Variable capture 라고 한다.
자바에서 클로저가 어떻게 동작하는지 조금 더 자세히 살펴보면, 내부함수가 사용하는 외부함수의 지역변수를 클로저가 생성되는 시점에 final로 간주된다. final로 간주된다는 뜻은 새로운 인스턴스를 할당하지 못하게 되는 것이다. 1.7이전 자바는 명시적으로 final을 붙여줘야했지만 1.8 이후부터는 외부함수의 지역변수는 유사파이널로 간주되어 final를 명시적으로 붙이지 않아도 컴파일 타임에 final로 간주하게 된다.
그리고 위 코드를 아래와 같이 변경하게 되면 컴파일 에러가 난다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@Test
void closure() {
final var supplier = outerMethod();
System.out.println(supplier.get());
}
private Supplier<String> outerMethod() {
String str = "outer method local variable";
return () -> {
str = "aa";
return str;
};
}
|
cs |
final로 간주되는 str 변수에 새로운 주소값을 할당하려하니 컴파일 에러가 나는 것이다. 하지만 이를 우회하는 방법으로 객체를 사용할 수 있다. 객체는 final로 생성되더라도, 안에 프로퍼티를 변경 할수 있기 때문이다.
그렇다면 자바에서 람다와 클로저의 차이점은 무엇일까?
람다와 클로저의 차이점
람다와 클로저는 모두 익명의 특정 기능 블록이고, 차이점은 클로저는 외부 변수를 참조하고, 람다는 자신이 받는 매개변수만 참조한다는 것이다.
// Lambda.
(server) -> server.isRunning();
// Closure. 외부의 server 라는 변수를 참조
() -> server.isRunning();
즉, 자바에서 클로저는 외부 변수를 참조하는 익명 클래스이고, 람다는 메서드의 매개변수만 참조하는 익명클래스가 되는 것이다.
private Supplier<String> outerMethod() {
String str = "outer method local variable";
return new Supplier<String>() {
@Override
public String get() {
return str;
}
};
}
커링(Currying)
Currying 은 1967년 Christopher Strachey 가 Haskell Brooks Curry의 이름에서 착안한 것이다. Currying은 여러 개의 인자를 가진 함수를 호출 할 경우, 파라미터의 수보다 적은 수의 파라미터를 인자로 받으면서 누락된 파라미터를 인자로 받는 기법을 말한다. 즉 커링은 함수 하나가 n개의 인자를 받는 과정을 n개의 함수로 각각의 인자를 받도록 하는 것이다. 부분적으로 적용된 함수를 체인으로 계속 생성해 결과적으로 값을 처리하도록 하는 것이 그 본질이다.
private static List<Integer> calculate(List<Integer> list, Integer a) {
return list.map(new Function<Integer, Function<Integer, Function<Integer, Integer>>>() {
@Override
public Function<Integer, Function<Integer, Integer>> apply(final Integer x) {
return new Function<Integer, Function<Integer, Integer>>() {
@Override
public Function<Integer, Integer> apply(final Integer y) {
return new Function<Integer, Integer>() {
@Override
public Integer apply(Integer t) {
return x + y * t;
}
};
}
};
}
}.apply(b).apply(a));
}
위와 같이 매개변수를 하나씩 받고 해당 매개변수가 일부반영된 Function을 다시 리턴하는 식으로 마지막 적용될 함수에 매개변수를 일부씩 적용시키는 것이다. 이것을 조금더 간소화 시키면,
private Stream<Integer> calculate(Stream<Integer> stream, Integer a) {
return stream.map(((F3) x -> y -> z -> x + y * z).apply(b).apply(a));
}
위와 같이 적용도 가능하다.
https://futurecreator.github.io/2018/08/09/java-lambda-and-closure/
Java Lambda (7) 람다와 클로저
람다와 클로저 자바 커뮤니티에서는 클로저와 람다를 혼용하면서 개념 상 혼란이 있었습니다. 그래서 자바 8부터 클로저를 지원한다는 글을 보기도 합니다. 이번 포스트에서는 자바에서의 람다
futurecreator.github.io
http://egloos.zum.com/ryukato/v/1160506
Java 8의 문제점: 커링(currying)대 클로져(closure))
원문을 번역한 것입니다.Closure 예제커링 사용하기자동 커링currying의 다른 응용들정리
Java 8의 문제점: 커링(currying)대
egloos.zum.com
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - 자바 날짜&시간 java.time 패키지(LocalDateTime, ZoneDateTime) (0) | 2020.07.30 |
|---|---|
| Java - Reactor switchIfEmpty 사용시 주의점(Lambda, 람다 Lazy Evaluation) (2) | 2020.07.29 |
| Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스) (0) | 2020.05.14 |
| Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)! (0) | 2020.04.29 |
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |

오늘 다루어볼 내용은 java 14에서 도입된 record 타입의 클래스입니다.
record란?
레코드(record)란 "데이터 클래스"이며 순수하게 데이터를 보유하기 위한 특수한 종류의 클래스이다. 코틀린의 데이터 클래스와 비슷한 느낌이라고 보면 된다. 밑에서 코드를 보겠지만, record 클래스를 정의할때, 그 모양은 정말 데이터의 유형만 딱 나타내는 듯한 느낌이다. 훨씬더 간결하고 가볍기 때문에 Entity 혹은 DTO 클래스를 생성할때 사용되면 굉장히 좋을 듯하다.
sample code
간단하게 샘플코드를 살펴보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public class SampleRecord {
private final String name;
private final Integer age;
private final Address address;
public SampleRecord(String name, Integer age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
public Address getAddress() {
return address;
}
}
|
cs |
위와 같은 코드가 있다고 가정하자. 해당 클래스는 모든 인스턴스 필드를 초기화하는 생성자가 있고, 모든 필드는 final로 정의되어 있다. 그리고 각각 필드의 getter를 가지고 있다. 이러한 클래스 같은 경우는 record 타입의 클래스로 변경이 가능하다.
|
1
2
3
4
5
|
public record SampleRecord(
String name,
Integer age,
Address address
) {}
|
cs |
엄청 클래스가 간결해진 것을 볼 수 있다. 이 record 클래스에 대해 간단히 설명하면 아래와 같다.
- 해당 record 클래스는 final 클래스이라 상속할 수 없다.
- 각 필드는 private final 필드로 정의된다.
- 모든 필드를 초기화하는 RequiredAllArgument 생성자가 생성된다.
- 각 필드의 getter는 getXXX()가 아닌, 필드명을 딴 getter가 생성된다.(name(), age(), address())
만약 그런데 json serialize가 되기 위해서는 위와 같이 선언하면 안된다. 아래와 같이 jackson 어노테이션을 붙여줘야한다.
|
1
2
3
4
5
|
public record SampleRecord(
@JsonProperty("name") String name,
@JsonProperty("age") Integer age,
@JsonProperty("address") Address address
) {}
|
cs |
record 클래스는 static 변수를 가질 수 있고, static&public method를 가질 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public record SampleRecord(
@JsonProperty("name") String name,
@JsonProperty("age") Integer age,
@JsonProperty("address") Address address
) {
static String STATIC_VARIABLE = "static variable";
@JsonIgnore
public String getInfo() {
return this.name + " " + this.age;
}
public static String get() {
return STATIC_VARIABLE;
}
}
|
cs |
또한 record 클래스의 생성자를 명시적으로 만들어서 생성자 매개변수의 validation 로직등을 넣을 수도 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public record SampleRecord(
@JsonProperty("name") String name,
@JsonProperty("age") Integer age,
@JsonProperty("address") Address address
) {
public SampleRecord {
if (name == null || age == null || address == null) {
throw new IllegalArgumentException();
}
}
static String STATIC_VARIABLE = "static variable";
@JsonIgnore
public String getInfo() {
return this.name + " " + this.age;
}
public static String get() {
return STATIC_VARIABLE;
}
}
|
cs |
이러한 record 클래스를 spring의 controller와 연계해서 사용하면 더 간결한 injection이 가능해지기 때문에 훨씬 깔끔한 컨트롤러 클래스작성이 가능하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
======================================================================================
public record SampleRecord(
@JsonProperty("name") String name,
@JsonProperty("age") Integer age,
@JsonProperty("address") Address address
) {
static String STATIC_VARIABLE = "static variable";
@JsonIgnore
public String getInfo() {
return this.name + " " + this.age;
}
public static String get() {
return STATIC_VARIABLE;
}
}
======================================================================================
public record Address(
@JsonProperty("si") String si,
@JsonProperty("gu") String gu,
@JsonProperty("dong") String dong
) {}
======================================================================================
@Service
public class SampleRecordService {
public Mono<SampleRecord> sampleRecordMono(SampleRecord sampleRecord) {
return Mono.just(sampleRecord);
}
}
======================================================================================
@RestController
public record SampleController(SampleRecordService sampleRecordService) {
@PostMapping("/")
public Mono<SampleRecord> sampleRecord(@RequestBody SampleRecord sampleRecord) {
System.out.println(sampleRecord.getInfo());
return sampleRecordService.sampleRecordMono(sampleRecord);
}
}
======================================================================================
|
cs |
여기까지 간단하게 jdk 14의 new feature인 record 클래스에 대해 간단하게 다루어 보았다. 모든 코드는 아래 깃헙을 참고하자.
yoonyeoseong/jdk_14_record_sample
Contribute to yoonyeoseong/jdk_14_record_sample development by creating an account on GitHub.
github.com
참조 : https://dzone.com/articles/jdk-14-records-for-spring-devs
JDK 14 Records for Spring - DZone Java
In this article, we'll discuss several use cases for JDK 14 Records to write cleaner and more efficient code.
dzone.com
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - Reactor switchIfEmpty 사용시 주의점(Lambda, 람다 Lazy Evaluation) (2) | 2020.07.29 |
|---|---|
| Java - 자바 클로져(Closure) & 커링(currying) (0) | 2020.07.22 |
| Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)! (0) | 2020.04.29 |
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |
| Java - CopyOnWriteArraySet 클래스 (0) | 2019.12.19 |

오늘 다루어볼 내용은 Model mapping을 아주 쉽게 해주는 Mapstruct라는 라이브러리를 다루어볼 것이다. 그 전에 Model mapping에 많이 사용되는 ModelMapper와의 간단한 차이를 이야기해보면, Model Mapper는 Runtime 시점에 reflection으로 모델 매핑을 하게 되는데, 이렇게 런타임시에 리플렉션이 자주 이루어진다면 앱성능에 아주 좋지 않다. 하지만 Mapstruct는 컴파일 타임에 매핑 클래스를 생성해줘 그 구현체를 런타임에 사용하는 것이기 때문에 앱 사이즈는 조금 커질수 있지만 성능상 크게 이슈가 없어서 ModelMapper보다 더 부담없이 사용하기 좋다. 그리고 아주 다양한 기능을 제공하기 때문에 조금더 세밀한 매핑이 가능해진다.
바로 간단하게 Mapstruct를 맛보자.
build.gradle
build.gradle를 채워넣어보자 !
buildscript {
ext {
mapstructVersion = '1.3.1.Final'
}
}
...
// Mapstruct
implementation "org.mapstruct:mapstruct:${mapstructVersion}"
annotationProcessor "org.mapstruct:mapstruct-processor:${mapstructVersion}"
testAnnotationProcessor "org.mapstruct:mapstruct-processor:${mapstructVersion}"
...
compileJava {
options.compilerArgs = [
'-Amapstruct.suppressGeneratorTimestamp=true',
'-Amapstruct.suppressGeneratorVersionInfoComment=true'
]
}
Java
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class CarDto {
private String name;
private String color;
}
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class Car {
private String modelName;
private String modelColor;
}
@Mapper
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
Car to(CarDto carDto);
}
|
cs |
사실 간단한 것이라, 어노테이션만 보아도 어떠한 기능을 제공하는지 확실하다. 하지만 각 클래스에 getter/setter 및 기본생성자는 꼭 생성해주자.(필드명이 동일할 일은 많이 없겠지만, 각 객체의 필드명이 동일하면 @Mapping 어노테이션은 생략가능하다.) 해당 코드로 테스트코드를 간단하게 작성하자.
|
1
2
3
4
5
6
7
8
9
10
11
|
public class MapstructTest {
@Test
public void test() {
CarDto carDto = CarDto.of("bmw x4", "black");
Car car = CarMapper.INSTANCE.to(carDto);
assertEquals(carDto.getName(), car.getModelName());
assertEquals(carDto.getColor(), car.getModelColor());
}
}
|
cs |
테스트가 성공하는 것을 볼 수 있다. 아주 간단하면서도 파워풀한 라이브러리인 것 같다. 그러면 실제로 생성된 코드를 한번 볼까?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
public class CarMapperImpl implements CarMapper {
@Override
public Car to(CarDto carDto) {
if ( carDto == null ) {
return null;
}
Car car = new Car();
car.setModelName( carDto.getName() );
car.setModelColor( carDto.getColor() );
return car;
}
}
|
cs |
우리가 작성하지 않았지만, 코드가 생성되었다. 리플렉션과 같이 비용이 큰 기술이 사용되지 않았다. 간단한 validation 코드와 생성자, getter, setter 코드 뿐이다. 이제 더 많은 Mapstruct 기능들을 살펴보자.
하나의 객체로 합치기
여러 객체의 필드값을 하나의 객체로 합치기가 가능하다. 특별히 다른 옵션을 넣는 것은 아니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class UserDto {
private String name;
}
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class AddressDto {
private String si;
private String dong;
}
@Mapper
public interface UserInfoMapper {
UserInfoMapper INSTANCE = Mappers.getMapper(UserInfoMapper.class);
@Mapping(source = "user.name", target = "userName")
@Mapping(source = "address.si", target = "si")
@Mapping(source = "address.dong", target = "dong")
UserInfo to(UserDto user, AddressDto address);
}
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
public class UserInfoMapperImpl implements UserInfoMapper {
@Override
public UserInfo to(UserDto user, AddressDto address) {
if ( user == null && address == null ) {
return null;
}
UserInfo userInfo = new UserInfo();
if ( user != null ) {
userInfo.setUserName( user.getName() );
}
if ( address != null ) {
userInfo.setDong( address.getDong() );
userInfo.setSi( address.getSi() );
}
return userInfo;
}
}
|
cs |
이미 생성된 객체에 매핑
새로운 인스턴스를 생성하는 것이 아니라, 기존에 이미 생성되어 있는 객체에 매핑이 필요한 경우이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
@Mapper
public interface UserInfoMapper {
UserInfoMapper INSTANCE = Mappers.getMapper(UserInfoMapper.class);
@Mapping(source = "user.name", target = "userName")
@Mapping(source = "address.si", target = "si")
@Mapping(source = "address.dong", target = "dong")
void write(UserDto user, AddressDto address, @MappingTarget UserInfo userInfo);
}
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
public class UserInfoMapperImpl implements UserInfoMapper {
@Override
public void write(UserDto user, AddressDto address, UserInfo userInfo) {
if ( user == null && address == null ) {
return;
}
if ( user != null ) {
userInfo.setUserName( user.getName() );
}
if ( address != null ) {
userInfo.setDong( address.getDong() );
userInfo.setSi( address.getSi() );
}
}
}
|
cs |
타입 변환
대부분의 암시적인 자동 형변환이 가능하다. (Integer -> String ...) 다음은 조금 유용한 기능이다.
|
1
2
3
4
5
6
7
8
9
|
@Mapper
public interface CarMapper {
@Mapping(source = "price", numberFormat = "$#.00")
CarDto carToCarDto(Car car);
@IterableMapping(numberFormat = "$#.00")
List<String> prices(List<Integer> prices);
}
|
cs |
만약 클래스에 있는 List<Integer> 필드값을 List<String>의 다른 포맷으로 변경하고 싶다면 @IterableMapping 어노테이션을 이용하자. 위와 비슷하게 날짜 데이터를 문자열로 변환하는 dateFormat이라는 옵션도 존재한다.
Source, Target mapping policy
매핑될 필드가 존재하지 않을 때, 엄격한 정책을 가져가기 위한 기능을 제공한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
ja@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class Car {
private String modelName;
private String modelColor;
private String modelPrice;
private String description;
}
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class CarDto {
private String name;
private String color;
private Integer price;
}
@Mapper(unmappedTargetPolicy = ReportingPolicy.ERROR)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
Car to(CarDto carDto);
}
|
cs |
위 코드는 타겟이 되는 오브젝트 필드에 대한 정책을 가져간다. Car 클래스에는 description 필드가 있는데, CarDto 클래스에는 해당 필드가 존재하지 않기때문에 컴파일시 컴파일에러가 발생한다.(ERROR, IGNORE, WARN 정책존재) 만약 특정 필드는 해당 정책을 피하고 싶다면 아래와 같이 어노테이션하나를 달아준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
@Mapper(unmappedTargetPolicy = ReportingPolicy.ERROR)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(target = "description", ignore = true)
Car to(CarDto carDto);
}
|
cs |
null 정책
Source가 null이거나 혹은 Source의 특정 필드가 null일때 적용가능한 정책이 존재한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_DEFAULT
)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(target = "description", ignore = true)
Car to(CarDto carDto);
}
|
cs |
위 코드는 Source 오브젝트가 null일때, 기본생성자로 필드가 비어있는 Target 오브젝트를 반환해준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_NULL
)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(
source = "description",
target = "description",
ignore = true,
nullValuePropertyMappingStrategy = NullValuePropertyMappingStrategy.SET_TO_DEFAULT
)
Car to(CarDto carDto);
}
|
cs |
위 코드는 각 필드에 대해 null 정책을 부여한다. 만약 SET_TO_DEFAULT로 설정하면, List 일때는 빈 ArrayList를 생성해주고, String은 빈문자열, 특정 오브젝트라면 해당 오브젝트의 기본 생성자 등으로 기본값을 생성해준다.
특정 필드 매핑 무시
특정 필드는 매핑되지 않길 원한다면 @Mapping 어노테이션에 ignore = true 속성을 넣어준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_NULL
)
public interface CarMapper {
CarMapper INSTANCE = Mappers.getMapper(CarMapper.class);
@Mapping(source = "name", target = "modelName")
@Mapping(source = "color", target = "modelColor")
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
@Mapping(target = "description", ignore = true)
Car to(CarDto carDto);
}
public class MapstructTest {
@Test
public void test() {
CarDto carDto = CarDto.of(
"bmw x4",
"black",
10000,
"description");
Car car = CarMapper.INSTANCE.to(carDto);
System.out.println(car.toString());
}
}
result =>
Car(modelName=bmw x4, modelColor=black, modelPrice=$10000.00, description=null)
|
cs |
매핑 전처리, 후처리
매핑하기 이전과 매핑 이후 특정 로직을 주입시킬 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
@Mapper(
unmappedTargetPolicy = ReportingPolicy.ERROR,
nullValueMappingStrategy = NullValueMappingStrategy.RETURN_NULL,
componentModel = "spring"
)
public abstract class CarMapper {
@BeforeMapping
protected void setColor(CarDto carDto, @MappingTarget Car car) {
if (carDto.getName().equals("bmw x4")) {
car.setModelColor("red");
} else {
car.setModelColor("black");
}
}
@Mapping(source = "name", target = "modelName")
@Mapping(target = "modelColor", ignore = true)
@Mapping(source = "price", target = "modelPrice", numberFormat = "$#.00")
public abstract Car to(CarDto carDto);
@AfterMapping
protected void setDescription(@MappingTarget Car car) {
car.setDescription(car.getModelName() + " " + car.getModelColor());
}
}
<Generate Code>
@Generated(
value = "org.mapstruct.ap.MappingProcessor"
)
@Component
public class CarMapperImpl extends CarMapper {
@Override
public Car to(CarDto carDto) {
if ( carDto == null ) {
return null;
}
Car car = new Car();
setColor( carDto, car );
car.setModelName( carDto.getName() );
if ( carDto.getPrice() != null ) {
car.setModelPrice( new DecimalFormat( "$#.00" ).format( carDto.getPrice() ) );
}
car.setDescription( carDto.getDescription() );
setDescription( car );
return car;
}
}
|
cs |
전처리와 후처리를 위한 메서드는 private을 사용해서는 안된다. 그 이유는 generate된 코드에 전,후 처리 메서드가 들어가는 것이 아니라 추상 클래스에 있는 메서드를 그대로 사용하기 때문이다.
이외에도 지원하는 기능이 너무 많다.. 다 못쓰겠다. 아래 공식 레퍼런스를 살펴보자..
MapStruct 1.3.1.Final Reference Guide
The mapping of collection types (List, Set etc.) is done in the same way as mapping bean types, i.e. by defining mapping methods with the required source and target types in a mapper interface. MapStruct supports a wide range of iterable types from the Jav
mapstruct.org
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - 자바 클로져(Closure) & 커링(currying) (0) | 2020.07.22 |
|---|---|
| Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스) (0) | 2020.05.14 |
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |
| Java - CopyOnWriteArraySet 클래스 (0) | 2019.12.19 |
| Java - HashMap 동작 방법(jdk1.7,1.8 차이점) (0) | 2019.08.05 |

오늘 다루어볼 내용은 자바에서 Stream(java 8 stream, reactor ...)을 사용할때 유용한 팁이다. 많은 사람들이 아는 해결법일 수도 있고, 혹은 필자와 같은 스타일을 선호하지 않는 사람들도 있을 것이다. 하지만 필자가 개발할때 이러한 상황에서 조금 유용했던 Stream pipeline Tip을 간단히 소개한다.
중첩이 많고, 이전 스트림보다 더 이전의 스트림의 결과 값을 사용해야 할때
상황은 아래와 같은데, 간단히 바로 이전 스트림의 결과가 아닌, 더 전의 스트림 원자를 로직에서 사용하려면 대게 아래와 같이 스트림 파이프 라인을 이어나간다.
Mono.just("id")
.flatMap(id ->
return Mono.just(service.getById(id))
.map(entity -> {
...
})
)
파이프라인의 시작인 id 값을 파이프라인의 중간에서 사용하려면 Stream의 pipeline을 점점 안으로 중첩해 나가면서 사용해야한다. 이렇게 된다면 복잡한 로직일 수록 점점 안쪽으로 파고드는 파이프라인이 될 것이다. 그렇다면 훨씬 가독성 좋은 코드는 어떻게 작성해 볼 수 있을까?
Tuple을 사용해서 넘겨주자.
reactor에 있는 Tuple을 사용해서 이전 파이프라인의 값을 뒤로 넘겨줘보자.
void stream() {
Mono.just("id")
.flatMap(str -> {
...
return Mono.just(Tuples.of(str, "str2"));
})
.flatMap(tuple -> {
final String str = tuple.getT1();
...
return Mono.just("result");
})
}
위처럼 튜플을 이용하여 해당 스트림의 결과와 이전 스트림의 결과가 나중에 쓰일 수 있도록 튜플에 값을 넣어서 넘겨준다. 이렇게 파이프라이닝하면 같은 depth로 파이프라인을 이어나갈 수 있기 때문에 가독성이 훨씬 좋다. 만약 튜플을 사용하지 않았다면 점점 depth가 깊어지는 중첩 파이프라인을 이어나가야하기 때문에 가독성도 훨씬 떨어지게 될 것이다.
여기까지 중첩이 많고, 이전 스트림의 결과를 미래 파이프라인에서 사용할 때 이용할 수 있는 팁이었다.
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - jdk 14 record(레코드) 란?! Data class(데이터 클래스) (0) | 2020.05.14 |
|---|---|
| Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)! (0) | 2020.04.29 |
| Java - CopyOnWriteArraySet 클래스 (0) | 2019.12.19 |
| Java - HashMap 동작 방법(jdk1.7,1.8 차이점) (0) | 2019.08.05 |
| Java - Garbage Collection(GC,가비지 컬렉션) 란? (1) | 2019.07.29 |

크기가 일반적으로 작고 읽기 전용 작업이 변경 작업보다 훨씬 많을 때 사용하면 좋은 라이브러리이다. iteration 중, 스레드 간의 간섭이 없어야 할때 사용하기 좋다. 즉, 스레드 안전하다.
하지만 변경 작업 같은 경우(add, set, remove) snapshot(복제본)을 이용하여 변경작업을 하기 때문에 비용이 비싸다. 내부적으로 object lock, synchronized 등이 사용되기 때문에 읽기 작업이 많고 변경작업이 적은 경우에 사용하는 것이 좋다. 그리고 해당 라이브러리는 iteration 중 remove를 지원하지 않는다.
해당 라이브러리가 스레드 안전한 이유는 iteration을 사용할때, iteration을 새로 생성하지 않는 이상 내부적으로 가지고 있는 List의 스냅샷에 의존하기 때문에 여러 스레드에 안전하다.
즉, 변경 작업과 읽기 작업에 사용되는 오브젝트가 서로 다르다.(복제본)
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - Model(Object) mapping을 위한 Mapstruct (맵스트럭트)! (0) | 2020.04.29 |
|---|---|
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |
| Java - HashMap 동작 방법(jdk1.7,1.8 차이점) (0) | 2019.08.05 |
| Java - Garbage Collection(GC,가비지 컬렉션) 란? (1) | 2019.07.29 |
| Java - JVM이란? JVM 메모리 구조 (1) | 2019.07.29 |
네이버의 d2 블로그에 Java Hashmap 동작에 대해 아주 상세히 설명한 자료가 있어 참조해보았다. 해시맵에 대해 아주 상세하게 작성한 글이라 알아두면 아주 좋을 것 같다.
참조 : https://d2.naver.com/helloworld/831311
Java HashMap은 어떻게 동작하는가?
이 글은 Java 7과 Java 8을 기준으로 HashMap이 어떻게 구현되어 있는지 설명합니다. HashMap 자체의 소스 코드는 Oracle JDK나 OpenJDK나 같기 때문에, 이 글이 설명하는 HashMap 구현 방식은 Oracle JDK와 OpenJDK 둘 모두에 해당한다고 할 수 있습니다. Java가 아닌 다른 언어를 주로 사용하는 개발자라 하더라도, Java의 HashMap이 현재 어떻게 구현되어 있고, 어떻게 발전되었는지 알면 라이브러리나 프레임워크 구현에 대한 혜안을 얻을 수 있을 것이라고 기대합니다.
HashMap은 Java Collections Framework에 속한 구현체 클래스입니다. Java Collections Framework는 1998년 12월에 발표한 Java 2에서 정식으로 선보였습니다. Map 인터페이스 자체는 Java 5에서 Generic이 적용된 것 외에 처음 선보인 이후 변화가 없지만, HashMap 구현체는 성능을 향상시키기 위해 지속적으로 변화해 왔습니다.
이 글에서는 어떤 방식으로 HashMap 구현체의 성능을 향상시켰는지 소개합니다. 구체적으로 다루는 내용은 Amortized Constant Time을 위하여 어떻게 해시 충돌(hash collision) 가능성을 줄이고 있는가에 대한 것입니다.
HashMap과 HashTable
이 글에서 말하는 HashMap과 HashTable은 Java의 API 이름이다. HashTable이란 JDK 1.0부터 있던 Java의 API이고, HashMap은 Java 2에서 처음 선보인 Java Collections Framework에 속한 API다. HashTable 또한 Map 인터페이스를 구현하고 있기 때문에 HashMap과 HashTable이 제공하는 기능은 같다. 다만 HashMap은 보조 해시 함수(Additional Hash Function)를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable에 비하여 해시 충돌(hash collision)이 덜 발생할 수 있어 상대으로 성능상 이점이 있다. 보조 해시 함수가 아니더라도, HashTable 구현에는 거의 변화가 없는 반면, HashMap은 지속적으로 개선되고 있다. HashTable의 현재 가치는 JRE 1.0, JRE 1.1 환경을 대상으로 구현한 Java 애플리케이션이 잘 동작할 수 있도록 하위 호환성을 제공하는 것에 있기 때문에, 이 둘 사이에 성능과 기능을 비교하는 것은 큰 의미가 없다고 할 수 있다.
HashMap과 HashTable을 정의한다면, '키에 대한 해시 값을 사용하여 값을 저장하고 조회하며, 키-값 쌍의 개수에 따라 동적으로 크기가 증가하는 associate array'라고 할 수 있다. 이 associate array를 지칭하는 다른 용어가 있는데, 대표적으로 Map, Dictionary, Symbol Table 등이다.
예제 1 HashTable과 HashMap의 선언부
associative array를 지칭하기 위하여 HashTable에서는 Dictionary라는 이름을 사용하고, HashMap에서는 그 명칭이 그대로 말하듯이 Map이라는 용어를 사용하고 있다.
map(또는 mapping)은 원래 수학 함수에서의 대응 관계를 지칭하는 용어로, 경우에 따라서는 함수 자체를 의미하기도 한다. 즉 HashMap이란 이름에서 알 수 있듯이, HashMap은 키 집합인 정의역과 값 집합인 공역의 대응에 해시 함수를 이용한다.

그림 1 함수에서의 사상(map)
해시 분포와 해시 충돌
동일하지 않은 어떤 객체 X와 Y가 있을 때, 즉 X.equals(Y)가 '거짓'일 때 X.hashCode() != Y.hashCode()가 같지 않다면, 이때 사용하는 해시 함수는 완전한 해시 함수(perfect hash functions)라고 한다(
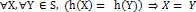
: S는 모든 객체의 집합, h는 해시 함수).
Boolean같이 서로 구별되는 객체의 종류가 적거나, Integer, Long, Double 같은 Number 객체는 객체가 나타내려는 값 자체를 해시 값으로 사용할 수 있기 때문에 완전한 해시 함수 대상으로 삼을 수 있다. 하지만 String이나 POJO(plain old java object)에 대하여 완전한 해시 함수를 제작하는 것은 사실상 불가능하다.
적은 연산만으로 빠르게 동작할 수 있는 완전한 해시 함수가 있다고 하더라도, 그것을 HashMap에서 사용할 수 있는 것은 아니다. HashMap은 기본적으로 각 객체의 hashCode() 메서드가 반환하는 값을 사용하는 데, 결과 자료형은 int다. 32비트 정수 자료형으로는 완전한 자료 해시 함수를 만들 수 없다. 논리적으로 생성 가능한 객체의 수가 232보다 많을 수 있기 때문이며, 또한 모든 HashMap 객체에서 O(1)을 보장하기 위해 랜덤 접근이 가능하게 하려면 원소가 232인 배열을 모든 HashMap이 가지고 있어야 하기 때문이다.
따라서 HashMap을 비롯한 많은 해시 함수를 이용하는 associative array 구현체에서는 메모리를 절약하기 위하여 실제 해시 함수의 표현 정수 범위

보다 작은 M개의 원소가 있는 배열만을 사용한다. 따라서 다음과 같이 객체에 대한 해시 코드의 나머지 값을 해시 버킷 인덱스 값으로 사용한다.
예제 2 해시를 사용하는 associative array 구현체에서 저장/조회할 해시 버킷을 계산하는 방법
이 코드와 같은 방식을 사용하면, 서로 다른 해시 코드를 가지는 서로 다른 객체가 1/M의 확률로 같은 해시 버킷을 사용하게 된다. 이는 해시 함수가 얼마나 해시 충돌을 회피하도록 잘 구현되었느냐에 상관없이 발생할 수 있는 또 다른 종류의 해시 충돌이다. 이렇게 해시 충돌이 발생하더라도 키-값 쌍 데이터를 잘 저장하고 조회할 수 있게 하는 방식에는 대표적으로 두 가지가 있는데, 하나는 Open Addressing이고, 다른 하나는 Separate Chaining이다. 이 둘 외에도 해시 충돌을 해결하기 위한 다양한 자료 구조가 있지만, 거의 모두 이 둘을 응용한 것이라고 할 수 있다.

그림 2 Open Addressing과 Separate Chaining 구조
Open Addressing은 데이터를 삽입하려는 해시 버킷이 이미 사용 중인 경우 다른 해시 버킷에 해당 데이터를 삽입하는 방식이다. 데이터를 저장/조회할 해시 버킷을 찾을 때에는 Linear Probing, Quadratic Probing 등의 방법을 사용한다.
Separate Chaining에서 각 배열의 인자는 인덱스가 같은 해시 버킷을 연결한 링크드 리스트의 첫 부분(head)이다.
둘 모두 Worst Case O(M)이다. 하지만 Open Addressing은 연속된 공간에 데이터를 저장하기 때문에 Separate Chaining에 비하여 캐시 효율이 높다. 따라서 데이터 개수가 충분히 적다면 Open Addressing이 Separate Chaining보다 더 성능이 좋다. 하지만 배열의 크기가 커질수록(M 값이 커질수록) 캐시 효율이라는 Open Addressing의 장점은 사라진다. 배열의 크기가 커지면, L1, L2 캐시 적중률(hit ratio)이 낮아지기 때문이다.
Java HashMap에서 사용하는 방식은 Separate Channing이다. Open Addressing은 데이터를 삭제할 때 처리가 효율적이기 어려운데, HashMap에서 remove() 메서드는 매우 빈번하게 호출될 수 있기 때문이다. 게다가 HashMap에 저장된 키-값 쌍 개수가 일정 개수 이상으로 많아지면, 일반적으로 Open Addressing은 Separate Chaining보다 느리다. Open Addressing의 경우 해시 버킷을 채운 밀도가 높아질수록 Worst Case 발생 빈도가 더 높아지기 때문이다. 반면 Separate Chaining 방식의 경우 해시 충돌이 잘 발생하지 않도록 '조정'할 수 있다면 Worst Case 또는 Worst Case에 가까운 일이 발생하는 것을 줄일 수 있다(여기에 대해서는 "보조 해시 함수"에서 설명하겠다).
예제 3 Java 7에서의 해시 버킷 관련 구현
Separate Chaining 방식을 사용하기 때문에, Java 7에서의 put() 메서드 구현은 예제 4에서 보는 것과 같다.
예제 4 put() 메서드 구현
그러나 Java 8에서는 예제 4에서 볼 수 있는 것보다 더 발전된 방식을 사용한다.
Java 8 HashMap에서의 Separate Chaining
Java 2부터 Java 7까지의 HashMap에서 Separate Chaining 구현 코드는 조금씩 다르지만, 구현 알고리즘 자체는 같았다. 만약 객체의 해시 함수 값이 균등 분포(uniform distribution) 상태라고 할 때, get() 메서드 호출에 대한 기댓값은
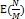
이다. 그러나 Java 8에서는 이보다 더 나은

을 보장한다. 데이터의 개수가 많아지면, Separate Chaining에서 링크드 리스트 대신 트리를 사용하기 때문이다.
데이터의 개수가 많아지면

과

의 차이는 무시할 수 없다. 게다가 실제 해시 값은 균등 분포가 아닐뿐더러, 설사 균등 분포를 따른다고 하더라도 birthday problem이 설명하듯 일부 해시 버킷 몇 개에 데이터가 집중될 수 있다. 그래서 데이터의 개수가 일정 이상일 때에는 링크드 리스트 대신 트리를 사용하는 것이 성능상 이점이 있다.
링크드 리스트를 사용할 것인가 트리를 사용할 것인가에 대한 기준은 하나의 해시 버킷에 할당된 키-값 쌍의 개수이다. 예제 5에서 보듯 Java 8 HashMap에서는 상수 형태로 기준을 정하고 있다. 즉 하나의 해시 버킷에 8개의 키-값 쌍이 모이면 링크드 리스트를 트리로 변경한다. 만약 해당 버킷에 있는 데이터를 삭제하여 개수가 6개에 이르면 다시 링크드 리스트로 변경한다. 트리는 링크드 리스트보다 메모리 사용량이 많고, 데이터의 개수가 적을 때 트리와 링크드 리스트의 Worst Case 수행 시간 차이 비교는 의미가 없기 때문이다. 8과 6으로 2 이상의 차이를 둔 것은, 만약 차이가 1이라면 어떤 한 키-값 쌍이 반복되어 삽입/삭제되는 경우 불필요하게 트리와 링크드 리스트를 변경하는 일이 반복되어 성능 저하가 발생할 수 있기 때문이다.
예제 5 Java 8 HashMap의 TREEIFY_THRESHOLD와 UNTREEIFY_THRESHOLD
Java 8 HashMap에서는 Entry 클래스 대신 Node 클래스를 사용한다. Node 클래스 자체는 사실상 Java 7의 Entry 클래스와 내용이 같지만, 링크드 리스트 대신 트리를 사용할 수 있도록 하위 클래스인 TreeNode가 있다는 것이 Java 7 HashMap과 다르다.
이때 사용하는 트리는 Red-Black Tree인데, Java Collections Framework의 TreeMap과 구현이 거의 같다. 트리 순회 시 사용하는 대소 판단 기준은 해시 함수 값이다. 해시 값을 대소 판단 기준으로 사용하면 Total Ordering에 문제가 생기는데, Java 8 HashMap에서는 이를 tieBreakOrder() 메서드로 해결한다.
예제 6 Java 8 HashMap의 Node 클래스
해시 버킷 동적 확장
해시 버킷의 개수가 적다면 메모리 사용을 아낄 수 있지만 해시 충돌로 인해 성능상 손실이 발생한다. 그래서 HashMap은 키-값 쌍 데이터 개수가 일정 개수 이상이 되면, 해시 버킷의 개수를 두 배로 늘린다. 이렇게 해시 버킷 개수를 늘리면
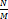
값도 작아져, 해시 충돌로 인한 성능 손실 문제를 어느 정도 해결할 수 있다.
해시 버킷 개수의 기본값은 16이고, 데이터의 개수가 임계점에 이를 때마다 해시 버킷 개수의 크기를 두 배씩 증가시킨다. 버킷의 최대 개수는 230개다. 그런데 이렇게 버킷 개수가 두 배로 증가할 때마다, 모든 키-값 데이터를 읽어 새로운 Separate Chaining을 구성해야 하는 문제가 있다. HashMap 생성자의 인자로 초기 해시 버킷 개수를 지정할 수 있으므로, 해당 HashMap 객체에 저장될 데이터의 개수가 어느 정도인지 예측 가능한 경우에는 이를 생성자의 인자로 지정하면 불필요하게 Separate Chaining을 재구성하지 않게 할 수 있다.
예제 7 Java 7 HashMap에서의 해시 버킷 확장
해시 버킷 크기를 두 배로 확장하는 임계점은 현재의 데이터 개수가 'load factor * 현재의 해시 버킷 개수'에 이를 때이다. 이 load factor는 0.75 즉 3/4이다. 이 load factor 또한 HashMap의 생성자에서 지정할 수 있다.
임계점에 이르면 항상 해시 버킷 크기를 두 배로 확장하기 때문에, N개의 데이터를 삽입했을 때의 키-값 쌍 접근 횟수는 다음과 같이 분석할 수 있다.

즉 기본 생성자로로 생성한 HashMap을 이용하여 많은 양의 데이터를 삽입할 때에는, 최적의 해시 버킷 개수를 지정한 것보다 약 2.5배 많이 키-값 쌍 데이터에 접근해야 한다. 이는 곧 수행 시간이 2.5배 길어진다고 할 수 있다. 따라서 성능을 높이려면, HashMap 객체를 생성할 때 적정한 해시 버킷 개수를 지정해야 한다.
그런데 이렇게 해시 버킷 크기를 두 배로 확장하는 것에는 결정적인 문제가 있다. 해시 버킷의 개수 M이 2a 형태가 되기 때문에, index = X.hashCode() % M을 계산할 때 X.hashCode()의 하위 a개의 비트만 사용하게 된다는 것이다. 즉 해시 함수가 32비트 영역을 고르게 사용하도록 만들었다 하더라도 해시 값을 2의 승수로 나누면 해시 충돌이 쉽게 발생할 수 있다.
이 때문에 보조 해시 함수가 필요하다.
보조 해시 함수
index = X.hashCode() % M을 계산할 때 사용하는 M 값은 소수일 때 index 값 분포가 가장 균등할 수 있다. 그러나 M 값이 소수가 아니기 때문에 별도의 보조 해시 함수를 이용하여 index 값 분포가 가급적 균등할 수 있도록 해야 한다.
보조 해시 함수(supplement hash function)의 목적은 '키'의 해시 값을 변형하여, 해시 충돌 가능성을 줄이는 것이다. 이 보조 해시 함수는 JDK 1.4에 처음 등장했다. Java 5 ~ Java 7은 같은 방식의 보조 해시 함수를 사용하고, Java 8부터는 다시 새로운 방식의 보조 해시 함수를 사용하고 있다.
예제 8 Java 7 HashMap에서의 보조 해시 함수
그런데 Java 8에서는 Java 7보다 훨씬 더 단순한 형태의 보조 해시 함수를 사용한다.
예제 9 Java 8 HashMap에서의 보조 해시 함수
예제 9에서 볼 수 있는 것처럼, Java 8 HashMap 보조 해시 함수는 상위 16비트 값을 XOR 연산하는 매우 단순한 형태의 보조 해시 함수를 사용한다. 이유로는 두 가지가 있는데, 첫 번째는 Java 8에서는 해시 충돌이 많이 발생하면 링크드 리스트 대신 트리를 사용하므로 해시 충돌 시 발생할 수 있는 성능 문제가 완화되었기 때문이다. 두 번째로는 최근의 해시 함수는 균등 분포가 잘 되게 만들어지는 경향이 많아, Java 7까지 사용했던 보조 해시 함수의 효과가 크지 않기 때문이다. 두 번째 이유가 좀 더 결정적인 원인이 되어 Java 8에서는 보조 해시 함수의 구현을 바꾸었다.
개념상 해시 버킷 인덱스를 계산할 때에는 index = X.hashCode() % M처럼 나머지 연산을 사용하는 것이 맞지만, M값이 2a일 때는 해시 함수의 하위 a비트 만을 취한 것과 값이 같다. 따라서 나머지 연산 대신 '1 << a – 1' 와 비트 논리곱(AND, &) 연산을 사용하면 수행이 훨씬 더 빠르다.
String 객체에 대한 해시 함수
String 객체에 대한 해시 함수 수행 시간은 문자열 길이에 비례한다.
때문에 JDK 1.1에서는 String 객체에 대해서 빠르게 해시 함수를 수행하기 위해, 일정 간격의 문자에 대한 해시를 누적한 값을 문자열에 대한 해시 함수로 사용했다.
예제 10 JDK 1.1에서의 String 클래스 해시 함수
예제 10에서 볼 수 있듯이 모든 문자에 대한 해시 함수를 계산하는 게 아니라, 문자열의 길이가 16을 넘으면 최소 하나의 문자를 건너가며 해시 함수를 계산했다.
그러나 이런 방식은 심각한 문제를 야기했다. 웹상의 URL은 길이가 수십 글자에 이르면서 앞 부분은 동일하게 구성되는 경우가 많다. 이 경우 서로 다른 URL의 해시 값이 같아지는 빈도가 매우 높아질 수 있다는 문제가 있다. 따라서 이런 방식은 곧 폐기되었고, 예제 11에서 보는 방식을 현재의 Java 8까지도 계속 사용하고 있다.
예제 11 Java String 클래스 해시 함수
예제 11은 Horner's method를 구현한 것이다. Horner's method는 다항식을 계산하기 쉽도록 단항식으로 이루어진 식으로 표현하는 것이다. 즉 예제 11에서 계산하고자 하는 해시 값 h는 다음과 같다.
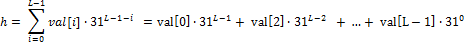

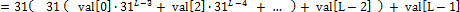
이렇게 단항식을 재귀적으로 사용하여 다항식 연산을 표현할 수 있다.
String 객체 해시 함수에서 31을 사용하는 이유는, 31이 소수이며 또한 어떤 수에 31을 곱하는 것은 빠르게 계산할 수 있기 때문이다. 31N=32N-N인데, 32는 25이니 어떤 수에 대한 32를 곱한 값은 shift 연산으로 쉽게 구현할 수 있다. 따라서 N에 31을 곱한 값은, (N << 5) – N과 같다. 31을 곱하는 연산은 이렇게 최적화된 머신 코드로 생성할 수 있기 때문에, String 클래스에서 해시 값을 계산할 때에는 31을 승수로 사용한다.
Java 7에서 String 객체에 대한 별도의 해시 함수
JDK 7u6부터 JDK 7u25까지는 HashMap에 저장된 키-값 쌍이 일정 개수 이상이면 String 객체에 한하여 별도의 해시 함수를 사용할 수 있게 하는 기능이 있다. 이 기능은 JDK 7u40부터는 삭제되었고, 당연히 Java 8에도 해당 기능은 없다. 여기서 말하는 '일정 개수 이상'이나 '별도의 해시 함수 사용 여부 지정'은 JVM을 가동할 때 옵션으로 지정할 수 있다.
예제 12 Java 7의 String에 대한 hash32() 메서드
JDK 7u6부터 JDK 7u25까지는 jdk.map.althashing.threshold 옵션을 지정하면, HashMap에 저장된 키-값 쌍이 일정 개수 이상일 때 String 객체에 String 클래스의 hashCode() 메서드 대신 sun.misc.Hashing.stringHash32() 메서드를 사용할 수 있게 했다. sun.misc.Hashing.stringHash32() 메서드는 String 클래스의 hash32() 메서드를 호출하게 한 것이고, hash32() 메서드는 MurMur 해시를 구현한 것이다. 이 MurMur 해시를 이용하여 String 객체에 대한 해시 충돌을 매우 낮출 수 있었다고 한다.
그러나 부작용도 있다. MurMur 해시는 hash seed를 필요로 하는데, 이를 위한 것이 sun.misc.Hashing.randomHashSeed() 메서드다. 이 메서드에서는 Random.nextInt() 메서드를 사용한다. Random.nextInt() 메서드는 compare and swap 연산(이하 CAS 연산)을 사용하는 AtomicLong을 사용하는데, CAS 연산은 코어가 많을수록 성능이 떨어진다. 즉 JDK 7u6부터 등장한 String 객체에 대한 별도의 해시 함수는 멀티 코어 환경에서는 성능이 하락했고, 이런 문제로 인해 JDK 7u40부터는 해당 기능을 사용하지 않는다. 당연히 Java 8도 사용하지 않는다.
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |
|---|---|
| Java - CopyOnWriteArraySet 클래스 (0) | 2019.12.19 |
| Java - Garbage Collection(GC,가비지 컬렉션) 란? (1) | 2019.07.29 |
| Java - JVM이란? JVM 메모리 구조 (1) | 2019.07.29 |
| Eclipse - Archive for required library 해결방법 (0) | 2019.06.18 |