
'메시지큐'에 해당되는 글 7건
- 2020.07.26 :: RabbitMQ - 레빗엠큐 개념 및 동작방식, 실습
- 2019.07.06 :: Apache Kafka - Kafka(카프카)란 ? 분산 메시징 플랫폼 - 1
- 2019.03.30 :: Kafka - Kafka Stream API(카프카 스트림즈) - 2
- 2019.03.28 :: Kafka - Spring cloud stream kafka(스프링 클라우드 스트림 카프카)
- 2019.03.24 :: Kafka - Kafka Consumer(카프카 컨슈머) Java&CLI 2
- 2019.03.13 :: Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법
- 2019.03.12 :: Kafka - Kafka(카프카)의 동작 방식과 원리

yoonyeoseong/rabbitmq-sample
Contribute to yoonyeoseong/rabbitmq-sample development by creating an account on GitHub.
github.com
오늘 포스팅할 내용은 래빗엠큐이다. 그 동안에는 카프카를 사용할 일이 많아 카프카에 대한 포스팅이 주였는데, 이번에 래빗엠큐를 사용할 일이 생겨 간단히 래빗엠큐에 대해 간단히 다루어 볼것이다.(예제 코드는 위 깃헙에 올려놓았습니다.)
비동기 작업에 있어 큐를 사용하려면 중간에 메시지 브로커라는 개념이 존재하는데, 이러한 메시지 브로커에는 RabbitMQ, Kafka 등이 대표적으로 있다. 해당 포스트에서는 표준 MQ프로토콜인 AMQP를 구현한 RabbitMQ(래빗엠큐)에 대해 다루어볼 것이다.
간단하게 메시지큐는 아래 그림과 같은 워크 플로우로 이루어져있다.

대부분의 메시지큐는 프로듀서가 있고, 해당 프로듀서가 브로커로 메시지를 발행하면, 적절한 컨슈머가 해당 메시지를 구독(읽다)하는 구조이다. 그렇다면 래빗엠큐는 상세하게 어떠한 구조로 되어있을까?
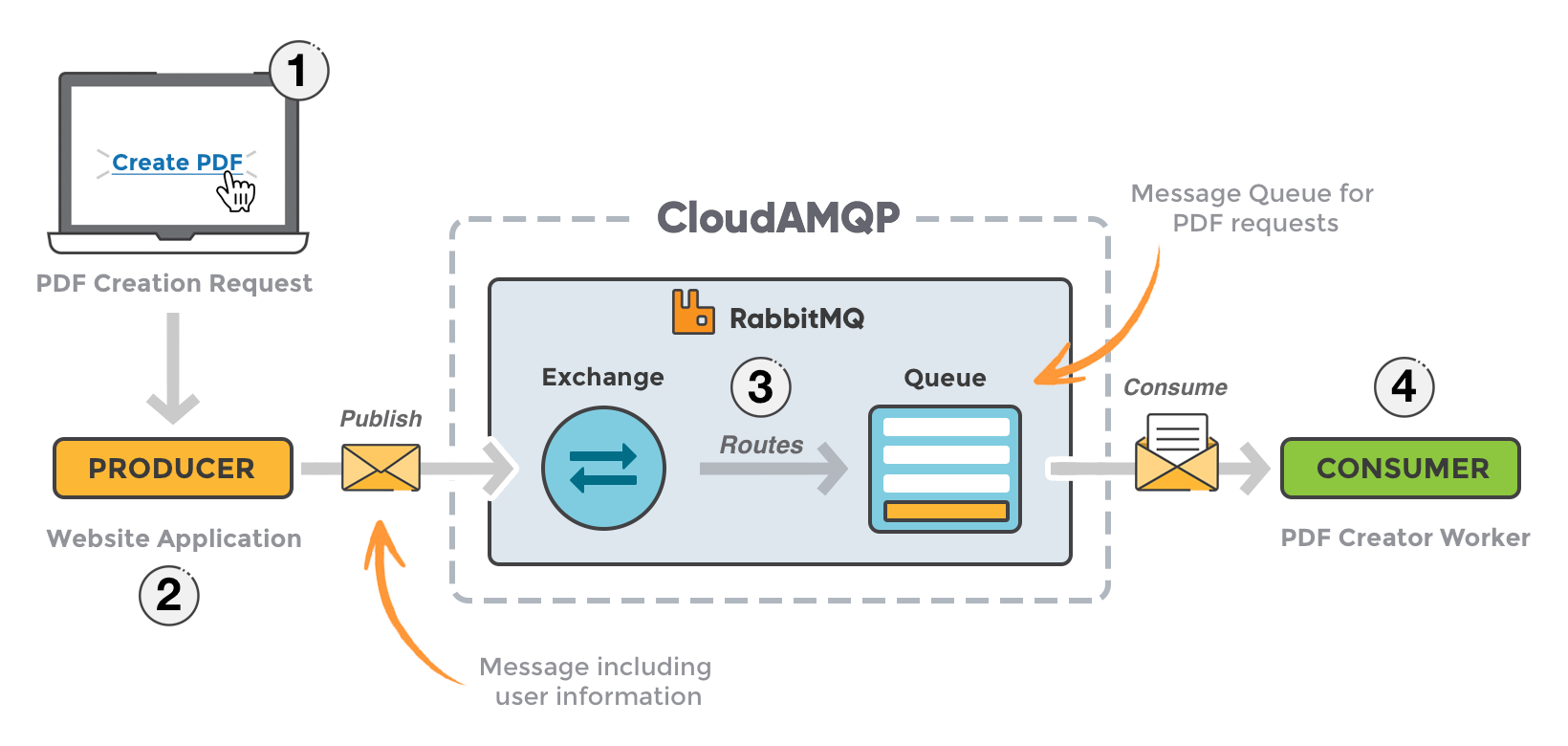
래빗엠큐는 단순히 프로듀서가 브로커로 메시지를 전달하여 컨슈머가 큐를 읽어가는 구조라는 면에서는 동일하지만, 프로듀싱하는 과정에서 조금 더 복잡한 개념이 들어간다. 바로 exchange와 route, queue라는 개념이다.
간단하게 워크 플로우를 설명하자면 아래와 같다.
- Producer는 Message를 Exchange에게 보내게 됩니다.
- Exchange를 생성할때 Exchange의 Type을 정해야 합니다.
- Exchange는 Routing Key를 사용하여 적절한 Queue로 Routing을 진행합니다.
- Routing은 Exchange Type에 따라 전략이 바뀌게 됩니다.
- Exchange - Queue와 Binding이 완료된 모습을 볼 수 있습니다.
- Message 속성에 따라 적절한 Queue로 Routing이 됩니다.
- Message는 Consumer가 소비할때까지 Queue에 대기하게 됩니다.
- Consumer는 Message를 소비하게 됩니다.
위에서 1번에 Exchange라는 개념이 등장하는데, Exchange는 정해진 규칙으로 메시지를 라우팅하는 기능을 가지고 있다. 여기서 정해진 규칙은 크게 4가지가 존재하는데, 규칙들은 아래와 같다.
exchange routeing 전략
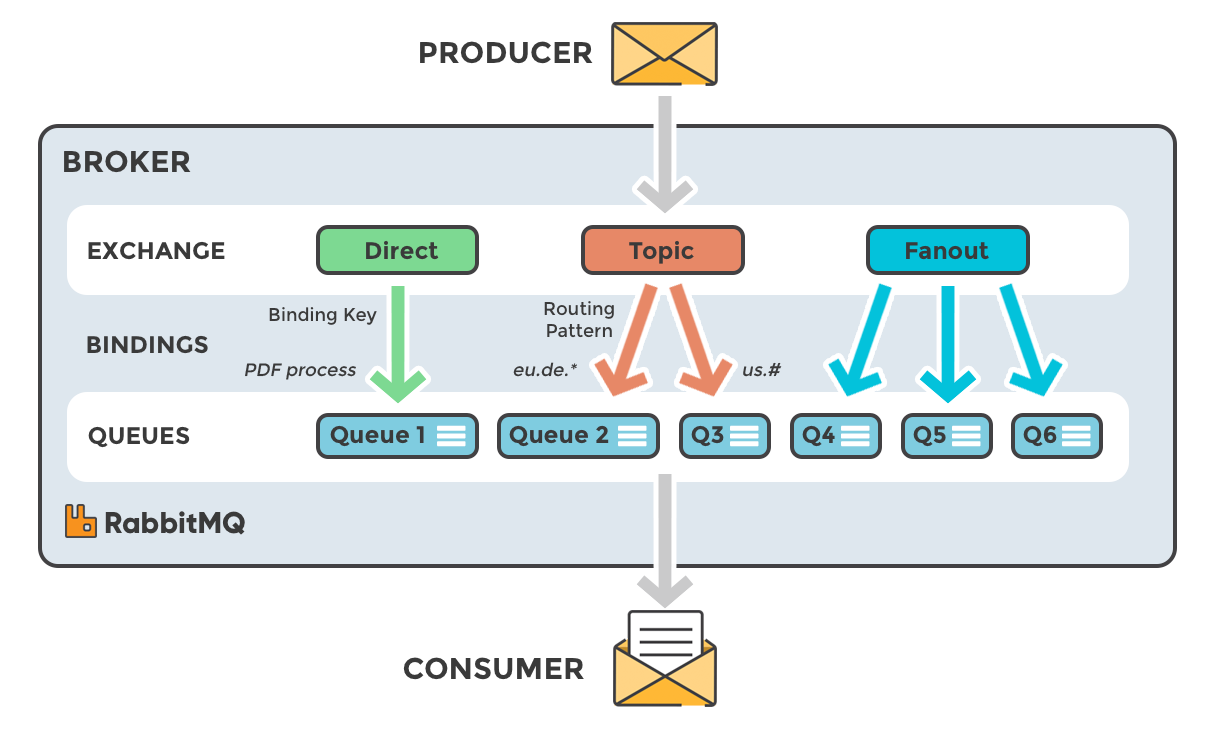
- Direct Exchange
- Message의 Routing Key와 정확히 일치하는 Binding된 Queue로 Routing
- Fanout Exchange
- Binding된 모든 Queue에 Message를 Routing
- Topic Exchange
- 특정 Routing Pattern이 일치하는 Queue로 Routing
- Headers Exchange
- key-value로 정의된 Header 속성을 통한 Routing

익스체인지는 위와 같은 전략으로 메시지를 라우팅하게 된다. 그리고 자주 사용되는 Exchange의 옵션으로는 아래와 같이 있다.
exchange options
- Durability
- 브로커가 재시작 될 때 남아 있는지 여부
- durable -> 재시작해도 유지가능
- transient -> 재시작하면 사라집니다.
- Auto-delete
- 마지막 Queue 연결이 해제되면 삭제
마지막으로 래빗엠큐에서 사용되는 용어가 있다.
- Vhost(virutal host)
- Virtual Host를 통해서 하나의 RabbitMQ 인스턴스 안에 사용하고 있는 Application을 분리할 수 있습니다.
- Connection
- 물리적인 TCP Connection, HTTPS -> TLS(SSL) Connection을 사용
- Channel
- 하나의 물리적인 Connection 내에 생성되는 가상의 Connection
- Consumer의 process나 thread는 각자 Channel을 통해 Queue에 연결 될 수 있습니다.
여기까지 간단하게 래빗엠큐의 동작과 용어에 대해서 다루어봤으니 실제 코드 레벨로 실습을 진행해본다.
docker rabbitmq 설치
sudo docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 \
--restart=unless-stopped -e RABBITMQ_DEFAULT_USER=username \
-e RABBITMQ_DEFAULT_PASS=password rabbitmq:management
위처럼 도커로 래빗엠큐를 설치해주고, http://localhost:15672(username/password)로 접속해보자.
springboot rabbitmq 예제
build.gradle
plugins {
id 'org.springframework.boot' version '2.3.2.RELEASE'
id 'io.spring.dependency-management' version '1.0.9.RELEASE'
id 'java'
}
group = 'com.levi'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '14'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-amqp'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
annotationProcessor "org.springframework.boot:spring-boot-configuration-processor"
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
testImplementation 'org.springframework.amqp:spring-rabbit-test'
}
test {
useJUnitPlatform()
}
application.yml
rabbitmq:
test:
username: username
password: password
host: localhost
port: 5672
virtualHost: levi.vhost
routeKey: test.route
exchangeName: test.exchange
queueName: testQueue
deadLetterExchange: dead.letter.exchange
deadLetterRouteKey: dead.letter.route
application.yml에서 프로퍼티를 읽어오는 클래스를 아래 하나 만들었다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
@Configuration
@ConfigurationProperties(prefix = "rabbitmq")
@Getter
@Setter
public class RabbitMqProperty {
private RabbitMqDetailProperty test;
@Getter
@Setter
public static class RabbitMqDetailProperty {
private String username;
private String password;
private String host;
private int port;
private String virtualHost;
private String routeKey;
private String exchangeName;
private String queueName;
private String deadLetterExchange;
private String deadLetterRouteKey;
}
}
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
@SpringBootApplication(exclude = {
RabbitAutoConfiguration.class
})
@EnableRabbit
@RestController
@RequiredArgsConstructor
public class RabbitmqApplication {
private final RabbitTemplate testTemplate;
public static void main(String[] args) {
SpringApplication.run(RabbitmqApplication.class, args);
}
@GetMapping("/")
public String inQueue() {
testTemplate.convertAndSend(SampleMessage.of("message!!"));
return "success";
}
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public static class SampleMessage {
private String message;
}
}
|
cs |
래빗엠큐 auto configuration을 꺼주었고, 메시지를 인큐하기 위한 컨트롤러를 하나 만들어 주었다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
@Slf4j
@Configuration
@RequiredArgsConstructor
public class RabbitMqConfig {
private final RabbitMqProperty rabbitMqProperty;
@Bean
public ConnectionFactory testConnectionFactory() {
final RabbitMqProperty.RabbitMqDetailProperty test = rabbitMqProperty.getTest();
final CachingConnectionFactory factory = new CachingConnectionFactory();
factory.setHost(test.getHost());
factory.setPort(test.getPort());
factory.setUsername(test.getUsername());
factory.setPassword(test.getPassword());
factory.setVirtualHost(test.getVirtualHost());
return factory;
}
@Bean
public SimpleRabbitListenerContainerFactory testContainer(final ConnectionFactory testConnectionFactory) {
final SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(testConnectionFactory);
factory.setConnectionFactory(testConnectionFactory);
factory.setErrorHandler(t -> log.error("ErrorHandler = {}", t.getMessage()));
factory.setDefaultRequeueRejected(false); //true일 경우 리스너에서 예외가 발생시 다시 큐에 메시지가 쌓이게 된다.(예외상황 해결안될 시 무한루프)
factory.setMessageConverter(jacksonConverter());
//예외 발생시 recover할 수 있는 옵션, 위 에러 핸들러와 잘 구분해서 사용해야할듯
//위 핸들러와 적용 순서등도 테스트가 필요(혹은 둘다 동시에 적용되나?) // factory.setAdviceChain(
// RetryInterceptorBuilder
// .stateless()
// .maxAttempts(3) //최대 재시도 횟수
// .recoverer() //recover handler
// .backOffOptions(2000, 4, 10000) //2초 간격으로, 4번, 최대 10초 내에 재시도
// .build()
// );
return factory;
}
@Bean
public RabbitTemplate testTemplate(final ConnectionFactory testConnectionFactory, final MessageConverter jacksonConverter) {
final RabbitMqProperty.RabbitMqDetailProperty property = rabbitMqProperty.getTest();
final RabbitTemplate template = new RabbitTemplate();
template.setConnectionFactory(testConnectionFactory);
template.setMessageConverter(jacksonConverter);
template.setExchange(property.getExchangeName());
template.setRoutingKey(property.getRouteKey());
return template;
}
@Bean
public MessageConverter jacksonConverter() {
return new Jackson2JsonMessageConverter();
}
//app에서 큐만들거나 바인딩 하기 위해서는 RabbitAdmin 필요 @Bean
public RabbitAdmin testAdmin(final ConnectionFactory testConnectionFactory) {
return new RabbitAdmin(testConnectionFactory);
}
}
|
cs |
브로커 연결 및 메시지를 프로듀싱하기 위한 RabbitTemplate 설정이다. 이중 RabbitAdmin 빈을 만들고 있는 수동이 아니라, 앱에서 큐를 만들고 바인딩 하기 위해서는 RabbitAdmin이 빈으로 떠있어야한다. 기타 설정은 주석을 참고하자 !
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
@Configuration
@RequiredArgsConstructor
public class RabbitMqBindingConfig {
private final RabbitMqProperty rabbitMqProperty;
@Bean
public TopicExchange testTopicExchange() {
return ExchangeBuilder
.topicExchange(rabbitMqProperty.getTest().getExchangeName())
.durable(true)
.build();
}
@Bean
public TopicExchange dlExchange() {
return ExchangeBuilder
.topicExchange(rabbitMqProperty.getTest().getDeadLetterExchange())
.durable(true)
.build();
}
@Bean
public Queue testQueue() {
final RabbitMqProperty.RabbitMqDetailProperty testDetail = rabbitMqProperty.getTest();
return QueueBuilder
.durable(testDetail.getQueueName())
.deadLetterExchange(testDetail.getDeadLetterExchange())
.deadLetterRoutingKey(testDetail.getDeadLetterRouteKey())
.build();
}
@Bean
public Queue dlq() {
return QueueBuilder
.durable("DEAD_LETTER_QUEUE")
.build();
}
@Bean
public Binding testBinding(final Queue testQueue, final TopicExchange testTopicExchange) {
return BindingBuilder
.bind(testQueue)
.to(testTopicExchange)
.with(rabbitMqProperty.getTest().getRouteKey());
}
@Bean
public Binding dlBinding(final Queue dlq, final TopicExchange dlExchange) {
return BindingBuilder
.bind(dlq)
.to(dlExchange)
.with(rabbitMqProperty.getTest().getDeadLetterRouteKey());
}
}
|
cs |
프로듀싱과 컨슈밍을 위해 브로커에 exchange와 queue를 binding하는 설정이다. 하나 추가적으로는 컨슈밍에서 예외가 발생하였을 때, Recover를 위한 Dead Letter Queue를 선언하였다.
이제 앱을 실행시키고, localhost:8080으로 요청을 보내보자 ! 요청을 보내면 메시지를 프로듀싱 할것이고, 해당 메시지를 컨슈밍해서 로그를 찍게 될 것이다. 여기까지 간단하게 래빗엠큐에 대해 다루어봤다.
https://jonnung.dev/rabbitmq/2019/02/06/about-amqp-implementtation-of-rabbitmq/
조은우 개발 블로그
jonnung.dev
Spring Boot와 RabbitMQ 초간단 설명서
이번 포스트에서는 Spring boot 프로젝트에서 RabbitMQ를 사용하는 간단한 방법을 알아보겠습니다. Consumer 코드와 Producer 코드는 GitHub에 있습니다. 먼저 RabbitMQ 서버를 실행해야 하는데 Docker를 사용하�
velog.io
https://nesoy.github.io/articles/2019-02/RabbitMQ
RabbitMQ에 대해
nesoy.github.io
'Middleware > Kafka&RabbitMQ' 카테고리의 다른 글
| [Kafka] Parallel Consumers, 메시지별 병렬 처리 (0) | 2023.10.30 |
|---|---|
| Spring cloud stream kafka - concurrency (1) | 2022.07.27 |
| Apache Kafka - Kafka Producer(카프카 프로듀서) - 2 (1) | 2019.07.06 |
| Apache Kafka - Kafka(카프카)란 ? 분산 메시징 플랫폼 - 1 (0) | 2019.07.06 |
| Kafka - Kafka Stream API(카프카 스트림즈) - 2 (0) | 2019.03.30 |

이전 포스팅들에서 이미 카프카란 무엇이고, 카프카 프로듀서부터 컨슈머, 스트리밍까지 다루어보았다. 하지만 이번 포스팅을 시작으로 조금더 내용을 다듬고 정리된 상태의 풀세트의 카프카 포스팅을 시작할 것이다.
카프카 시스템의 목표
- 메시지 프로듀서와 컨슈머 사이의 느슨한 연결
- 다양한 형태의 데이터 사용 시나리오와 장애 처리 지원을 위한 메시지 데이터 유지
- 빠른 처리 시간을 지원하는 구성 요소로 시스템의 전반적인 처리량을 최대화
- 이진 데이터 형식을 사용해서 다양한 데이터 형식과 유형을 관리
- 기존의 클러스터 구성에 영향을 주지 않고 일정한 서버의 확장성을 지원
카프카의 구조
카프카 토픽에서 모든 메시지는 바이트의 배열로 표현되며, 카프카 프로듀서는 카프카 토픽에 메시지를 저장하는 애플리케이션이다. 이렇게 프로듀서가 보낸 데이터를 저장하고 있는 모든 토픽은 하나 이상의 파티션으로 나뉘어져있다. 각 토픽에 대해 여러개로 나뉘어져 있는 파티션은 메시지를 도착한 순서에 맞게 저장한다.(내부적으로는 timestamp를 가지고 있다.) 카프카에서는 프로듀서와 컨슈머가 수행하는 두 가지 중요한 동작이 있다. 프로듀서는 로그 선행 기입 파일 마지막에 메시지를 추가한다. 컨슈머는 주어진 토픽 파티션에 속한 로그 파일에서 메시지를 가져온다. 물리적으로 각 토픽은 자신에게 할당된 하나 이상의 파티션을 다른 브로커(카프카 데몬 서버)들에게 균등하게 분배된다.
이상적으로 카프카 파이프라인은 브로커별로 파티션과 각 시스템의 모든 토픽에 대해 균등하게 분배되어야 한다. 컨슈머는 토픽에 대한 구독 또는 이런 토픽에서 메시지를 수신하는 애플리케이션이다.
이러한 카프카 시스템은 고가용성을 위한 클러스터를 지원한다. 전형적인 카프카 클러스터는 다중 브로커로 구성된다. 클러스터에 대한 메시지 읽기와 쓰기 작업의 부하 분산을 돕는다. 각 브로커는 자신의 상태를 저장하지 않지만 Zookeeper를 사용해 상태 정보를 유지한다. 각각의 토픽 파티션에는 리더로 활동하는 브로커가 하나씩 있고, 0개 이상의 팔로워를 갖는다. 여느 리더/팔로워 관계와 비슷하게 리더는 해당하는 파티션의 읽기나 쓰기 요청을 관리한다. 여기서 Zookeeper는 카프카 클러스터에서 중요한 요소로, 카프카 브로커와 컨슈머를 관리하고 조정한다. 그리고 카프카 클러스터 안에서 새로운 브로커의 추가나 기존 브로커의 장애를 감시한다. 예전 카프카 버전에서는 파티션 오프셋 관리도 Zookeeper에서 관리하였지만 최신 버전의 카프카는 오프셋 관리를 위한 토픽이 생성되어 오프셋관련된 데이터를 하나의 토픽으로 관리하게 된다.
메시지 토픽
메시징 시스템에서 메시지는 어디간에 저장이 되어 있어야한다. 카프카는 토픽이라는 곳에 메시지를 바이트 배열 형태로 저장한다. 각 토픽은 비즈니스 관점에서 하나의 카테고리가 될 수 있다. 다음은 메시지 토픽에 대한 용어 설명이다.
- 보관 기간 : 토픽 안의 메시지는 처리 시간과 상관없이 정해진 기간 동안에만 메시지를 저장하고 있는다. 기본 값은 7일이며 사용자가 값 변경이 가능하다.
- 공간 유지 정책 : 메시지의 크기가 설정된 임계값에 도달하면 메시지를 지우도록 설정가능하다. 카프카 시스템 구축시 충분한 용량 계획을 수립해야 원치않은 삭제가 발생하지 않는다.
- 오프셋 : 카프카에 할당된 각 메시지는 오프셋이라는 값이 사용된다. 토픽은 많은 파티션으로 구성돼 있으며, 각 파티션은 도착한 순서에 따라 메시지를 저장하고, 컨슈머는 이러한 오프셋으로 메시지를 인식하고 특정 오프셋 이전의 메시지는 컨슈머가 수신했던 메시지로 인식한다.
- 파티션 : 카프카 메시지 토픽은 1개 이상의 파티션으로 구성되어 분산 처리된다. 해당 파티션의 숫자는 토픽 생성시 설정가능하다. 만약 순서가 아주 중요한 데이터의 경우에는 파티션 수를 1개로 지정하는 것도 고려할 수 있다.(아무리 파티션이 시계열로 데이터가 저장되지만 여러 파티션에 대한 메시지 수신은 어떠한 순서로 구독될지 모르기 때문이다.)
- 리더 : 파티션은 지정된 복제 팩터에 따라 카프카 클러스터 전역에 걸쳐 복제된다. 각 파티션은 리더 브로커와 팔로워 브로커를 가지며 파티션에 대한 모든 읽기와 쓰기 요청은 리더를 통해서만 진행된다.
메시지 파티션
각 메시지는 파티션에 추가되며 각 단위 메시지는 오프셋으로 불리는 숫자에 맞게 할당된다. 카프카는 유사한 키를 갖고 있는 메시지가 동일한 파티션으로 전송되도록 하며, 메시지 키의 해시 값을 산출하고 해당 파티션에 메시지를 추가한다. 여기서 중요하게 짚고 넘어가야 할 것이 있다. 각 단위 메시지에 대한 시간적인 순서는 토픽에 대해서는 보장되지 않지만, 파티션 안에서는 항상 보장된다. 즉, 나중에 도착한 메시지가 항상 파티션의 끝 부분에 추가됨을 의미한다. 예를 들어 설명하자면,
A 토픽은 a,b,c라는 파티션으로 구성된다는 가정이다. 만약 라운드 로빈 방식으로 메시지가 각 파티션에 분배가 되는 옵션을 적용했다고 생각해보자. 1,2,3,4,5,6이라는 메시지가 pub되었고 각 메시지는 a-1,4 / b-2,5 / c-3,6 와 같이 파티션에 분배된다. 1,2,3,4,5,6이라는 순서로 메시지가 들어왔고 해당 메시지는 시간적인 순서와 라운드로빈 방식으로 a,b,c라는 파티션에 배분되었다. 또한 각 파티션 안을 살펴보면 확실히 시간 순서로 배분되었다. 하지만 컨슈머 입장에서는 a,b,c파티션에서 데이터를 수신했을 경우 1,4,2,5,3,6이라는 메시지 순서로 데이터를 수신하게 될것이다.(a,b,c순서로 수신, 하지만 파티션 수신순서는 바뀔수 있다.) 무엇을 의미할까? 위에서 말한것과 같이 파티션 내에서는 시간적인 순서를 보장하지만 전체적인 토픽관점에서는 순서가 고려되지 않는 것이다. 즉, 순서가 중요한 데이터는 동일한 키를 사용해 동일 파티션에만 데이터를 pub하거나 혹은 토픽에 파티션을 하나만 생성해 하나의 파티션에 시간적인 순서로 데이터를 저장되게 해야한다.
많은 수의 파티션을 구성하는 경우의 장단점
- 높은 처리량 보장 : 파티션을 여러개 구성한다면 병렬 처리되어 높은 처리량을 보장할 것이다. 왜냐하면 여러 파티션에 대해 쓰기 동작이 여러 스레드를 이용해 동시에 수행되기 때문이다. 또한 하나의 컨슈머 그룹 내에서 하나의 파티션에 대해 하나의 컨슈머가 할당되기 때문에 여러 파티션의 메시지를 여러 컨슈머가 동시에 수신하여 병렬처리가 가능하다. 여기서 중요한 것은 동일한 컨슈머 그룹 안의 하나의 파티션에 대해 여러 컨슈머가 읽을 수 없다는 것이다.
- 프로듀서 메모리 증가 : 만약 파티션 수가 많아 진다면 일시적으로 프로듀서의 버퍼의 메모리가 과도해질 수 있어, 토픽에 메시지를 보내는데 문제가 생길 수 있으므로 파티션 수는 신중히 고려해야한다.
- 고가용성 문제 : 여러 파티션을 생성하므로서 카프카 클러스터의 고가용성을 지원한다. 즉, 리더인 파티션이 중지되면 팔로워중에 하나가 리더로 선출될 것이다. 하지만 너무 과중한 파티션 수는 리더 선출에 지연이 생길 가능성이 있기 때문에 신중히 고려해야한다.
복제와 복제로그
복제는 카프카 시스템에서 신뢰성있는 시스템을 구현하기 위해 가장 중요한 부분이다. 각 토픽 파티션에 대한 메시지 로그의 복제본은 카프카 클러스터 내의 여러 서버에 걸쳐서 관리되고, 각 토픽마다 복제 팩터를 다르게 지정가능하다.
일반적으로 팔로워는 리더의 로그 복사본을 보관하는데, 이는 리더가 모든 팔로워로부터 ACK를 받기 전까지는 메시지를 커밋하지 않는다는 것을 의미한다.(ack=all 설정시)
메시지 프로듀서
일반적으로 프로듀서는 파티션으로 데이터를 쓰기 않고, 메시지에 대한 쓰기 요청을 생성해서 리더 브로커에게 전송한다. 그 이후 파티셔너가 메시지의 해시 값을 계산하여 프로듀서로 하여금 어느 파티션에 메시지를 pub할지 알 수 있도록 한다.
일반적으로 해시 값은 메시지 키를 갖고 계산하며, 메시지 키는 카프카의 토픽으로 메시지를 기록할 때 제공된다. null 키를 갖는 메시지는 분산 메시징을 지원하는 파티션에 대해 라운드 로빈 방식으로 분배된다. 카프카에서의 각 파티션은 한 개의 리더를 가지며, 각 읽기와 쓰기 요청은 리더를 통해 진행된다.
프로듀서는 설정에 따라 메시지의 ACK를 기다리며, 일반적으로 모든 팔로워 파티션에 대해 복제가 완료되면 커밋을 완료한다. 또한 커밋이 완료되지 않으면 읽기 작업은 허용되지 않는다. 이는 메시지의 손실을 방지한다. 그렇지만 ACK 설정을 1로 설정할 수 있는데, 이경우 리더 파티션이 하나의 팔로워에게만 복제 완료 응답을 받으면 커밋을 완료한다. 이 경우 처리 성능은 좋아지지만 메시지의 손실은 어느정도 감수 해야한다. 즉, 메시지의 손실을 허용하고 빠른 처리 시간을 원하는 경우에 사용할 수 있는 설정이다.
메시지 컨슈머
카프카 토픽을 구독하는 역할을 하는 애플리케이션이다. 각 컨슈머는 컨슈머 그룹에 속해 있으며, 일부 컨슈머 그룹은 여러개의 컨슈머를 포함한다. 위에서도 간단히 설명하였지만 동일 그룹의 컨슈머들은 동시에 같은 토픽의 서로다른 파티션에서 메시지를 읽어온다. 하지만 서로 다른 그룹의 컨슈머들은 같은 토픽에서 데이터를 읽어와 서로 영향을 미치지 않으면서 메시지 사용이 가능하다.
주키퍼의 역할
- 컨트롤러 선정 : 컨트롤러는 파티션 관리를 책임지는 브로커 중에 하나이며, 파티션 관리는 리더 선정, 토픽 생성, 파티션 생성, 복제본 관리 등을 포함한다. 하나의 노드 또는 서버가 꺼지면 카프카 컨트롤러는 팔로워 중에서 파티션 리더를 선정한다. 카프카는 컨트롤러를 선정하기 위해 주키퍼의 메타데이터를 정보를 이용한다.
- 브로커 메타데이터 : 주키퍼는 카프카 클러스터의 일부인 각 브로커에 대해 상태 정보를 기록한다.
- 토픽 메타데이터 : 주키퍼는 또한 파티션 수, 특정한 설정 파라미터 등의 토픽 메타 데이터를 기록한다.
이외에 주키퍼는 더 많은 역할을 담당하고 있다.
여기까지 간단히 카프카에 대한 소개였다. 이후 포스팅들에서는 프로듀서,컨슈머,스트리밍,클러스터 구축 등의 내용을 몇 차례에 거쳐 다루어 볼 것이다.
'Middleware > Kafka&RabbitMQ' 카테고리의 다른 글
| RabbitMQ - 레빗엠큐 개념 및 동작방식, 실습 (0) | 2020.07.26 |
|---|---|
| Apache Kafka - Kafka Producer(카프카 프로듀서) - 2 (1) | 2019.07.06 |
| Kafka - Kafka Stream API(카프카 스트림즈) - 2 (0) | 2019.03.30 |
| Kafka - Spring Cloud Stream Kafka Streams API(스프링 클라우드 스트림 카프카 스트림즈 API) (0) | 2019.03.30 |
| Kafka - Spring cloud stream kafka(스프링 클라우드 스트림 카프카) (0) | 2019.03.28 |
Kafka - Kafka Stream API(카프카 스트림즈) - 2

이전 카프카 스트림즈 포스팅에서는 간단하게 카프카 스트림즈 API를 다루어보았습니다. 이번 2번째 카프카 스트림즈 포스팅은 조금더 깊게 카프카 스트림즈에 대해 알아보려고 합니다.
Kafka Streams는 Kafka 프로듀서 및 컨슈머를 이용하여 들어오는 메시지를 즉각적으로 가공하여 또 다른 토픽으로 메시지를 내보낼 수 있습니다. 이러한 카프카 스트림즈를 사용하는 기업들을 소개하자면 New York Times는 카프카와 카프카 스트림즈를 이용하여 독자들을 위한 실시간 컨첸츠를 저장하고 배포합니다.그리고 라인 같은 경우는 서비스끼리 통신하기 위한 중앙 데이터 허브로 카프카를 사용합니다. 그리고 카프카 스트림즈를 이용하여 토픽을 데이터를 안정적으로 가공하고 필터링하여 컨슈머가 효율적으로 메시지를 컨슘할 수 있게 합니다. 이러한 많은 기업들이 안정적으로 실시간 데이터를 처리하기 위해 카프카와 카프카 스트림즈를 이용합니다.

카프카 메시징 계층은 데이터를 저장하고 전송하기 위해 데이터를 파티션 단위로 분할한다. 카프카 스트림즈 역시 파티션된 토픽을 기반으로 병렬 처리 모델의 논리 단위로 작업을 진행한다. 카프카 스트림즈는 키/값 형태의 스트림 데이터이므로 스트림 데이터의 키값으로 토픽내 특정 파티션으로 라우팅된다. 일반적으로 파티션 개수만큼 컨슈머 그룹안의 컨슈머들이 생성되듯이 카프카 스트림즈도 역시 파티션 개수만큼 태스크가 생성되어 병렬로 데이터 스트림을 처리할 수 있다. 또한 작업스레드 수를 조정할 수 있어 더욱 효율적인 병렬처리가 가능하다.
Required configuration parameters
- application.id - 스트림 처리 응용 프로그램의 식별자 아이디이다. Kafka 클러스터 내에서 유일한 값이어야 한다.
- bootstrap.servers - Kafka 인스턴스 호스트:포트 정보이다.
Optional configuration parameters(중요도 보통이상의 설정값)
- cache.max.bytes.buffering - 모든 스레드에서 레코드 캐시에 사용할 최대 메모리 바이트 수입니다.(default 10485760 bytes)
- client.id - 요청시 서버에 전달할 ID 문자열이다. 카프카 스트림즈 내부적으로 프로듀서,컨슈머에게 전달된다(default empty string)
- default.deserialization.exception.handler - DeserializationExceptionHandler인터페이스를 구현하는 예외 처리 클래스이다.
(default LogAndContinueExceptionHandler)
- default.production.exception.handler - ProductionExceptionHandler인터페이스를 구현하는 예외 처리 클래스이다.
(default DefaultProductionExceptionHandler)
- key.serde - record key에 대한 직렬화/역직렬화 클래스이다. Serde 인터페이스를 구현한다.(default Serdes.ByteArray().getClass().getName() )
- num.standby.replicas - 각 태스크의 대기 복제본 수이다.(default 0)
- num.stream.threads - 스트림을 처리할 스레드 수이다.(default 1)
- replication.factor - 복제본 수이다.(default 1)
- retries - 처리 실패시 재시도 횟수(default 0)
- retry.backoff.ms - 재시도 요청 간격 시간(default 100밀리세컨드)
- state.dir - 상태 저장소 디렉토리 위치(default /tmp/kafka-streams)
- value.serde - record value에 대한 직렬화/역직렬화 클래스이다. key.serde와 동일.
default.deserialization.exception.handler
기본 deserialization 예외 처리기를 사용하면 deserialize에 실패한 레코드의 예외를 관리할 수 있다. 예외 처리기는 throw된 예외에 따라 FAIL 또는 CONTINUE를 반환해야한다. FAIL은 스트림이 종료될 것이고, CONTINUE는 예외를 무시하고 계속해서 처리를 진행할 것이다. 내부적으로 제공하는 예외 핸들어가 있다.
- LogAndContinueExceptionHandler - 예외가 발생하여도 계속해서 프로세스를 진행한다.
- LogAndFailExceptionHandler - 예외가 발생하면 프로세스를 중지한다.
기본적으로 제공하는 핸들러 이외에도 사용자가 직접 정의하여 예외 핸들러를 구현할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public class SendToDeadLetterQueueExceptionHandler implements DeserializationExceptionHandler { KafkaProducer<byte[], byte[]> dlqProducer; String dlqTopic; @Override public DeserializationHandlerResponse handle(final ProcessorContext context, final ConsumerRecord<byte[], byte[]> record, final Exception exception) { log.warn("Exception caught during Deserialization, sending to the dead queue topic; " + "taskId: {}, topic: {}, partition: {}, offset: {}", context.taskId(), record.topic(), record.partition(), record.offset(), exception); dlqProducer.send(new ProducerRecord<>(dlqTopic, record.timestamp(), record.key(), record.value(), record.headers())).get(); return DeserializationHandlerResponse.CONTINUE; } @Override public void configure(final Map<String, ?> configs) { dlqProducer = .. // get a producer from the configs map dlqTopic = .. // get the topic name from the configs map } } | cs |
위의 예제코드는 예외가 발생하면 DLQ 토픽에 메시지를 보낸 이후 계속해서 프로세스를 진행하는 예외 핸들러이다. 위에서 이야기하였듯이 반드시 FAIL,CONTINUE 둘중하나를 반환해야 한다.
- default.production.exception.handler
프로덕션 예외 처리기를 사용하여 너무 큰 메시지 데이터를 생성하는 등 브로커와 상호 작용하려고 할때 트리거되는 예외를 컨트롤 할 수 있습니다. 기본적으로 카프카는 DefaultProductionExceptionHandler를 제공한다. 이 예외 처리기도 역시 FAIL,CONTINUE등 하나를 반환하여 프로세스 진행여부를 결정해주어야 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import java.util.Properties; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.common.errors.RecordTooLargeException; import org.apache.kafka.streams.errors.ProductionExceptionHandler; import org.apache.kafka.streams.errors.ProductionExceptionHandler.ProductionExceptionHandlerResponse; public class IgnoreRecordTooLargeHandler implements ProductionExceptionHandler { public void configure(Map<String, Object> config) {} public ProductionExceptionHandlerResponse handle(final ProducerRecord<byte[], byte[]> record, final Exception exception) { if (exception instanceof RecordTooLargeException) { return ProductionExceptionHandlerResponse.CONTINUE; } else { return ProductionExceptionHandlerResponse.FAIL; } } } Properties settings = new Properties(); // other various kafka streams settings, e.g. bootstrap servers, application id, etc settings.put(StreamsConfig.DEFAULT_PRODUCTION_EXCEPTION_HANDLER_CLASS_CONFIG, IgnoreRecordTooLargeHandler.class); | cs |
Stream DSL
- branch - 제공되는 predicate에 따라서 적절히 여러개의 KStream으로 분할한다.(KStream[] 반환)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | /** * branch * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam { public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.foreach((key,value)->log.info("key,value ={}",key+" "+value)); KStream<String, String>[] streamArr = source.branch( (key,value) -> value.startsWith("A"), (key,value) -> value.startsWith("B"), (key,value) -> true ); streamArr[0].to("stream-exam-output1"); streamArr[1].to("stream-exam-output2"); streamArr[2].to("stream-exam-output3"); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
위의 코드는 stream-exam-input이라는 토픽에 "A"로 시작하는 데이터가 들어오면 stream-exam-output1, "B"로 시작하는 데이터가 들어오면 stream-exam-output2, 그 밖의 데이터는 stream-exam-output3으로 보내는 간단한 branch 예제이다. branch에는 적절하게 Predicate를 리스트 형태로 작성한다. 데이터의 값에 따라 다른 처리를 해야할때에는 branch를 사용하면 각각 다른 처리를 하는 토픽으로 메시지를 내보낼 수 있을 것 같다.
- filter - 적절한 Predicate을 인자로 받아 메시지를 필터링한다.(KStream 반환)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | /** * filter * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam2 { public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.filter( (key,value)->value.length()>3 ).to("stream-exam-output");; //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
위의 예제는 토픽으로 메시지를 입력받아 value 값의 길이가 3보다 크다면 stream-exam-output 토픽으로 메시지를 내보내는 예제이다.
- filterNot - filter와 반대되는 개념이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | /** * filterNot * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam3 { public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.filterNot( (key,value)->value.length()>3 ).to("stream-exam-output");; //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
- flatMap - 하나의 레코드를 이용해 0개 혹은 하나 이상의 레코드를 생성한다. flatMap은 key,value가 바뀔 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | /** * flatMap * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam4 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.flatMap( new KeyValueMapper() { @Override public Object apply(Object key, Object value) { List<KeyValue<Object, Object>> list = new LinkedList<>(); String keyStr = (String)key; String valueStr = (String)value; list.add(KeyValue.pair(valueStr.toUpperCase(),value)); list.add(KeyValue.pair(valueStr.toLowerCase(),value)); return list; } } ).to("stream-exam-output");; //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
- flatMapValues - 원본 레코드의 키를 유지하면서 하나의 레코드를 가져와서 0개 혹은 하나 이상의 레코드를 생성한다. value의 값과 값의 타입이 바뀔 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | /** * flatMapValue * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam5 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.flatMapValues(value->Arrays.asList(value.split(" "))).to("stream-exam-output"); // source.flatMapValues( // new ValueMapper() { // @Override // public Object apply(Object value) { // String valueStr = (String)value; // return Arrays.asList(valueStr.split(" ")); // } // } // ); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
- GroupByKey - 기존 키로 레코드를 그룹핑한다. 스트림이나 테이블을 집계하고 후속작업을 위해 키로 그룹화하여 파티션하는 것을 보장한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | /** * GroupByKey * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam6 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); KGroupedStream<String, String> groupedStream = source.flatMap( new KeyValueMapper() { @Override public Object apply(Object key, Object value) { List<KeyValue<Object, Object>> list = new LinkedList<>(); String keyStr = (String)key; String valueStr = (String)value; list.add(KeyValue.pair(value,valueStr.toUpperCase())); list.add(KeyValue.pair(value,valueStr.toLowerCase())); return list; } } ).groupByKey(); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
스트림의 기존 키값을 이용하여 그룹핑한다.
GroupBy - 새로운 키로 그룹핑한다. 테이블을 그룹핑할 때는 새로운 값과 값 유형을 지정할 수도 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | /** * GroupBy * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam7 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); KGroupedStream<String, String> groupedStream = source.groupBy( (key,value)->value, Serialized.with(Serdes.String(),Serdes.String()) ); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
위의 예제와 같이 기존 스트림에서 받은 키값을 그대로 사용하는 것이 아니라 변경하여 사용할 수 있다.(예제는 value를 키로 사용한다)
- map - 하나의 레코드를 가져와서 다른 하나의 레코드를 생성한다. 타입을 포함하여 키와 값을 수정할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | /** * map * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam8 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.map( (key,value)->KeyValue.pair(value, key) ); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
메시지를 받아서 키와 값을 바꿔주는 map 예제이다.
- mapValues - 하나의 레코드를 받아서 값을 바꿔준다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | /** * mapValues * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam9 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.mapValues( (value)->value+"_map" ).to("stream-exam-output"); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
메시지를 받아서 값에 "_map"이라는 문자열을 추가하여 수정하였다.
- merge - 두 스트림의 레코드를 하나의 스트림으로 merge한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | /** * merge * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam10 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.foreach((key,value)->log.info("key,value ={}",key+" "+value)); KStream<String, String>[] streamArr = source.branch( (key,value) -> value.startsWith("A"), (key,value) -> value.startsWith("B"), (key,value) -> true ); KStream<String, String> merge1 = streamArr[0].merge(streamArr[1]); merge1.merge(streamArr[2]).to("stream-exam-output"); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
- selectKey - 각 레코드에 새키를 할당한다. 마치 map을 이용하여 key값을 바꾸는 것과 동일하다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | /** * selectKey * @author yun-yeoseong * */ @Slf4j public class KafkaStreamExam11 { @SuppressWarnings("unchecked") public static void main(String[] args) { // TODO Auto-generated method stub Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-stream-exam"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("stream-exam-input"); source.selectKey( //리턴되는 값이 키가된다. (key,value)->value.charAt(0)+"" ).to("stream-exam-output"); //최종적인 토폴로지 생성 final Topology topology = builder.build(); log.info("Topology info = {}",topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); streams.start(); } } | cs |
- toStream - KTable을 스트림으로 가져온다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | @Slf4j public class WordCounter { public static void main(String[] args) { Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); final StreamsBuilder builder = new StreamsBuilder(); NoriAnalyzer analyzer = new NoriAnalyzer(); KStream<String, String> source = builder.stream("streams-plaintext-input"); source.flatMapValues(value -> Arrays.asList(analyzer.analyzeForString(value).split(" "))) //return하는 value가 키가 된다. 리턴값으로 그룹핑된 카프카스트림 객체를 리턴한다. KGroupedStream .groupBy(new KeyValueMapper<String, String, String>() { @Override public String apply(String key, String value) { log.info("key = {},value = {}",key,value); return value; } }) //count()를 호출하여 해당 키값으로 몇개의 요소가 있는지 체크한다. 그리고 해당 데이터를 스토어에(KeyValueStore<Bytes,byte[]> counts-store) 담고 //변경이 있는 KTable에 대해서만 결과값을 리턴한다. .count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store")) .toStream() //KTable -> Stream .to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long())); final Topology topology = builder.build(); System.out.println(topology.describe()); final KafkaStreams streams = new KafkaStreams(topology, props); try { streams.start(); } catch (Throwable e) { System.exit(1); } } } | cs |
지금까지는 메시지의 상태가 없는 StreamDSL이었다. 다음으로 알아볼 DSL은 이전 메시지의 상태를 참조하는 상태기반 스트림이다. 아마 실시간으로 데이터 스트림을 처리할때 상태가 필요없는 처리도 있겠지만, 오늘하루 사용자가 많이 문의한 단어등 단어의 빈도수를 계산해야하는 스트림이 있다고 해보자. 그렇다면 지금 이순간 전까지 해당 단어는 몇번이 누적되었는지를 알아야 이시간 이후로 들어오는 같은 단어도 이전 빈도수에 누적하여 통계를 낼 것이다. 이렇게 상태에 기반하여 처리해야하는 스트림을 처리하는 것이 상태기반 스트림이다.
다음 포스팅에서 다루어볼 내용은 Stateful transformations이다. 레퍼런스의 양이 굉장히 많은 부분으로 조금 정리한 후 포스팅하려한다.
'Middleware > Kafka&RabbitMQ' 카테고리의 다른 글
| Apache Kafka - Kafka Producer(카프카 프로듀서) - 2 (1) | 2019.07.06 |
|---|---|
| Apache Kafka - Kafka(카프카)란 ? 분산 메시징 플랫폼 - 1 (0) | 2019.07.06 |
| Kafka - Spring Cloud Stream Kafka Streams API(스프링 클라우드 스트림 카프카 스트림즈 API) (0) | 2019.03.30 |
| Kafka - Spring cloud stream kafka(스프링 클라우드 스트림 카프카) (0) | 2019.03.28 |
| Kafka - Kafka Streams API(카프카 스트림즈) - 1 (2) | 2019.03.26 |
Kafka - Spring cloud stream kafka(스프링 클라우드 스트림 카프카)

이전 포스팅까지는 카프카의 아키텍쳐, 클러스터 구성방법, 자바로 이용하는 프로듀서,컨슈머 등의 글을 작성하였다. 이번 포스팅은 이전까지 작성된 지식을 바탕으로 메시징 시스템을 추상화한 구현체인 Spring Cloud Stream을 이용하여 카프카를 사용하는 글을 작성하려고 한다. 혹시라도 카프카에 대해 아직 잘모르는 사람들이 이 글을 본다면 이전 포스팅을 한번 참고하고 와도 좋을 것같다.(이번에 작성하는 포스팅은 Spring Cloud stream 2.0 레퍼런스 기준으로 작성하였다.)
그리고 이번 포스팅에서 진행하는 모든 예제는 카프카를 미들웨어로 사용하는 예제이고, 카프카는 클러스터를 구성하였다.
▶︎▶︎▶︎Spring Cloud Stream v2.0 Reference
▶︎▶︎▶︎2019/03/12 - [Kafka&RabbitMQ] - Kafka - Kafka(카프카)의 동작 방식과 원리
▶︎▶︎▶︎2019/03/13 - [Kafka&RabbitMQ] - Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법
▶︎▶︎▶︎2019/03/16 - [Kafka&RabbitMQ] - Kafka - Kafka Producer(카프카 프로듀서) In Java&CLI
▶︎▶︎▶︎2019/03/24 - [Kafka&RabbitMQ] - Kafka - Kafka Consumer(카프카 컨슈머) Java&CLI
▶︎▶︎▶︎2019/03/26 - [Kafka&RabbitMQ] - Kafka - Kafka Streams API(카프카 스트림즈)
스프링 클라우드 스트림을 이용하면 RabbitMQ,Kafka와 같은 미들웨어 메시지 시스템과는 종속적이지 않게 추상화된 방식으로 메시지 시스템을 이용할 수 있다.(support RabbitMQ,Kafka) 아래 그림은 스프링 클라우드 스트림의 애플리케이션 모델이다.

스프링 클라우드 스트림 애플리케이션과 메시지 미들웨어 시스템은 직접 붙지는 않는다. 중간에 스프링 클라우드 스트림이 제공하는 바인더 구현체를 중간에 두고 통신을 하기 때문에 애플리케이션에서는 미들웨어 독립적으로 추상화된 방식으로 개발 진행이 가능하다. 그리고 애플리케이션과 바인더는 위의 그림과 같이 inputs, outputs 채널과 통신을 하게 된다.
- Binder : 외부 메시징 시스템과의 통합을 담당하는 구성 요소입니다.
- Binding(input/output) : 외부 메시징 시스템과 응용 프로그램 간의 브리지 (대상 바인더에서 생성 한 메시지 생성자 및 소비자 ).
- Middleware : RabbitMQ, Kafka와 같은 메시지 시스템.
바인더 같은 경우는 스프링이 설정에서 읽어 미들웨어에 해당하는 바인더를 구현체로 제공해준다. 물론 RabbitMQ, Kafka를 동시에 사용 가능하다. 그리고 바인딩 같은 경우는 기본으로 Processor(input,output),Source(output),Sink(input)라는 바인딩을 인터페이스로 제공한다. 이러한 스프링 클라우드 스트림을 이용하여 작성한 완벽히 동작하는 코드의 예제이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | @SpringBootApplication @EnableBinding(Processor.class) public class MyApplication { public static void main(String[] args) { SpringApplication.run(MyApplication.class, args); } @StreamListener(Processor.INPUT) @SendTo(Processor.OUTPUT) public String handle(String value) { System.out.println("Received: " + value); return value.toUpperCase(); } } | cs |
이 코드는 Processor라는 바인딩 채널을 사용하고, handle이라는 메소드에서 Processor의 input 채널에서 메시지를 받아서 값을 한번 출력하고 그대로 output 채널로 메시지를 보내는 코드이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | public interface Sink { String INPUT = "input"; @Input(Sink.INPUT) SubscribableChannel input(); } public interface Source { String OUTPUT = "output"; @Output(Source.OUTPUT) MessageChannel output(); } public interface Processor extends Source, Sink {} | cs |
스프링 클라우드 스트림에서 기본적으로 제공하는 바인딩 채널이다. 만약 이 채널들 이외에 채널을 정의하고 싶다면 위와 같이 인터페이스로 만들어주고, @EnableBinding에 매개변수로 넣어주면된다.(매개변수는 여러개의 인터페이스를 받을 수 있다.)
1 2 3 4 5 6 7 8 9 10 11 | public interface Barista { @Input SubscribableChannel orders(); @Output MessageChannel hotDrinks(); @Output MessageChannel coldDrinks(); } | cs |
1 | @EnableBinding(value = { Orders.class, Payment.class }) | cs |
1 2 3 4 5 6 | public interface PolledBarista { @Input PollableMessageSource orders(); . . . } | cs |
지금까지는 이벤트 기반 메시지이지만 위처럼 Pollable한 채널을 바인딩 할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | @Autowire private Source source public void sayHello(String name) { source.output().send(MessageBuilder.withPayload(name).build()); } @Autowire private MessageChannel output; public void sayHello(String name) { output.send(MessageBuilder.withPayload(name).build()); } @Autowire @Qualifier("myChannel") private MessageChannel output; | cs |
정의한 채널에 대한 @Autowired하여 직접 사용도 가능하다. 그리고 @Qualifier 어노테이션을 이용해 다중 채널이 정의되어 있을 경우 특정한 채널을 주입받을 수 있다.
@StreamListener 사용
스프링 클라우드 스트림은 다른 org.springframework.messaging의 어노테이션도 같이 사용가능하다.(@Payload,@Headers,@Header)
1 2 3 4 5 6 7 8 9 10 11 | @EnableBinding(Sink.class) public class VoteHandler { @Autowired VotingService votingService; @StreamListener(Sink.INPUT) public void handle(Vote vote) { votingService.record(vote); } } | cs |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | @Component @Slf4j public class KafkaListener { @StreamListener(ExamProcessor.INPUT) @SendTo(ExamProcessor.OUTPUT2) public Exam listenMessage(@Payload Exam payload,@Header("contentType") String header) { log.info("input message = {} = {}",payload.toString(),header); return payload; } } =>결과 : input message = Exam(id=id_2, describe=test message !) = application/json | cs |
또한 @SendTo 어노테이션을 추가로 붙여서 메시지를 수신하고 어떠한 처리를 한 후에 메시지를 출력채널로 내보낼 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 | @EnableBinding(Processor.class) public class TransformProcessor { @Autowired VotingService votingService; @StreamListener(Processor.INPUT) @SendTo(Processor.OUTPUT) public VoteResult handle(Vote vote) { return votingService.record(vote); } } | cs |
바로 위의 코드는 즉, 인바운드 채널에서 메시지를 받아서 그대로 해당 데이터를 리턴하여 아웃바운드 채널에 내보내는 예제이다. 실제로는 메소드 내에 비지니스 로직이 들어가 적절히 데이터 조작이 있을 수 있다.
@StreamListener for Content-based routing
조건별로 @StreamListener 주석처리가 된 인입채널 메소드로 메시지를 유입시킬 수 있다. 하지만 이 기능에는 밑에와 같은 조건을 충족해야한다.
- 반환값이 있으면 안된다.
- 개별 메시지 처리 메소드여야한다.
조건은 어노테이션 내의 condition 인수에 SpEL 표현식에 의해 지정된다. 그리고 조건과 일치하는 모든 핸들러는 동일한 스레드에서 호출되며 핸들러에 대한 호출이 발생하는 순서는 가정할 수 없다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | @EnableBinding(Sink.class) @EnableAutoConfiguration public static class TestPojoWithAnnotatedArguments { @StreamListener(target = Sink.INPUT, condition = "headers['type']=='bogey'") public void receiveBogey(@Payload BogeyPojo bogeyPojo) { // handle the message } @StreamListener(target = Sink.INPUT, condition = "headers['type']=='bacall'") public void receiveBacall(@Payload BacallPojo bacallPojo) { // handle the message } } | cs |
위에서 얘기한 것과 같이 조건별로 메시지를 분기하는 경우 해당 채널로 @StreamListener된 메소드들은 모두 반환값이 void여야한다.(Sink.INPUT) 만약 위에서 위는 void, 아래에는 반환값이 있는 메소드로 선언한다면 예외가 발생한다.
Error Handler
Spring Cloud Stream은 오류 처리를 유연하게 처리하는 메커니즘을 제공한다. 오류 처리에는 크게 두가지가 있다.
- application : 사용자 정의 오류처리이며, 애플리케이션 내에서 오류 처리를 진행한다.
- system : 오류 처리가 기본 메시징 미들웨어의 기능에 따라 달라진다.
Application Error Handler
애플리케이션 레벨 오류 처리에는 두 가지 유형이 있다. 오류는 각 바인딩 subscription에서 처리되거나 전역 오류 핸들러가 모든 바인딩 subscription의 오류를 처리한다. 각 input 바인딩에 대해, Spring Cloud Stream은 <destinationName>.<groupName>.errors 설정으로 전용 오류 채널을 생성한다.
1 | spring.cloud.stream.bindings.input.group=myGroup | cs |
컨슈머 그룹을 설정한다.(만약 그룹명을 지정하지 않았을 경우 익명으로 그룹이 생성된다.)
1 2 3 4 5 6 7 8 9 | @StreamListener(Sink.INPUT) // destination name 'input.myGroup' public void handle(Person value) { throw new RuntimeException("BOOM!"); } //만약 Sink.INPUT의 input 채널이름이 input이고, 해당 채널의 consumer group이 myGroup이라면 //해당 채널 단독의 에러 처리기의 inputChannel 매개변수의 값은 아래와 같다.("input.myGroup.errors") @ServiceActivator(inputChannel = "input.myGroup.errors") //channel name 'input.myGroup.errors' public void error(Message<?> message) { System.out.println("Handling ERROR: " + message); } | cs |
위와 같은 코드를 작성하면 Sink.INPUT.myGroup 채널의 전용 에러채널이 생기는 것이다. 하지만 이렇게 채널별이 아닌 전역 에러 처리기를 작성하려면 아래와 같은 코드를 작성하면 된다.
1 2 3 4 | @StreamListener("errorChannel") public void error2(Message<?> message) { log.error("Global Error Handling !"); } | cs |
System Error Handling
System 레벨의 오류 처리는 오류가 메시징 시스템에 다시 전달되는 것을 의미하며, 모든 메시징 시스템이 동일하지는 않다. 즉, 바인더마다 기능이 다를 수 있다. 내부 오류 처리기가 구성되어 있지 않으면 오류가 바인더에 전파되고 바인더가 해당 오류를 메시징 시스템에 전파한다. 메시징 시스템의 기능에 따라 시스템은 메시지를 삭제하고 메시지를 다시 처리하거나 실패한 메시지를 DLQ로 보낼 수 있다. 해당 내용은 뒤에서 더 자세히 다룬다.
바인딩 정보 시각화
1 2 3 4 | <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> | cs |
의존성을 추가해준다.
1 | management.endpoints.web.exposure.include=bindings | cs |
application.propertis에 해당 설정을 추가해준 후에, host:port/actuator/bindings 를 호출하면 바인딩된 정보를 JSON형태로 받아볼 수 있다.
Binder Configuration Properties
Spring Auto configuration을 사용하지 않고 사용자 정의 바인더를 등록할때 다음 등록 정보들을 사용할 수 있다. 이 속성들은 모두 org.springframework.cloud.stream.config.BinderProperties 패키지에 정의되어있다. 그리고 해당 설정들은 모두 spring.cloud.stream.binders. 접두어가 붙는다. 밑에서 설명할 설정들은 모두 접두어가 생략된 형태이므로 실제로 작성할때는 접두어를 붙여준다.
- type
바인더의 타입을 지정한다.(rabbit,kafka)
- inheritEnvironment
애플리케이션 자체 환경을 상속하는지 여부
기본값 : true
- environment
바인더 환경을 사용자가 직접 정의하는데 사용할 수 있는 설정이다.
기본값 : empty
- defaultCandidate
바인더 구성이 기본 바인더로 간주되는지 또는 명시적으로 참조할 때만 사용할 수 있는지 여부 이 설정을 사용하면 기본 처리를 방해하지 않고 바인더 구성이 가능하다.
기본값 : true
Common Binding Properties
binding 설정입니다. 해당 설정은 spring.cloud.stream.bindings.<channelName> 접두어가 붙는다. 밑에서 설명할 설정은 모두 접두어가 생략된 설정이므로, 직접 애플리케이션을 설정할때에는 꼭 접두어를 붙여줘야한다.
- destination
해당 채널을 메시지 시스템 토픽과 연결해주는 설정이다. 채널이 consumer로 바인딩되어 있다면, 여러 대상에 바인딩 될 수 있으며 대상 이름은 쉼표로 구분된 문자열이다.
- group
컨슈머 그룹명설정이다. 해당 설정은 인바운드 바인딩에만 적용되는 설정이다.
기본값 : null
- contentType
메시지의 컨텐츠 타입이다.
기본값 : null
- binder
사용될 바인더를 설정한다.
기본값 : null
Consumer Properties
- concurrency
인바운드 소비자의 동시성
기본값 : 1.
- partitioned
컨슈머가 파티션된 프로듀서로부터 데이터를 수신하는지 여부입니다.
기본값 : false.
- headerMode
none으로 설정하면 입력시 헤더 구문 분석을 사용하지 않습니다. 기본적으로 메시지 헤더를 지원하지 않으며 헤더 포함이 필요한 메시징 미들웨어에만 유효합니다. 이 옵션은 원시 헤더가 지원되지 않을 때 비 Spring Cloud Stream 애플리케이션에서 데이터를 사용할 때 유용합니다. 로 설정 headers하면 미들웨어의 기본 헤더 메커니즘을 사용합니다. 로 설정 embeddedHeaders하면 메시지 페이로드에 헤더가 포함됩니다.
기본값 : 바인더 구현에 따라 다릅니다.
- maxAttempts
처리가 실패하면 다시 메시지를 처리하는 시도 횟수 (첫 번째 포함). 1로 설정하면 다시 메시지 처리를 시도하지 않는다.
기본값 : 3.
- backOffInitialInterval
다시 시도 할 때 백 오프 초기 간격입니다.
기본값 : 1000.
- backOffMaxInterval
최대 백 오프 간격.
기본값 : 10000.
- backOffMultiplier
백 오프 승수입니다.
기본값 : 2.0.
- instanceIndex
0보다 큰 값으로 설정하면이 소비자의 인스턴스 색인을 사용자 정의 할 수 있습니다 (다른 경우spring.cloud.stream.instanceIndex). 음수 값으로 설정하면 기본값은로 설정됩니다.(카프카의 경우 autoRebalence 설정이 false 일 경우)
기본값 : -1.
- instanceCount
0보다 큰 값으로 설정하면이 소비자의 인스턴스 수를 사용자 정의 할 수 있습니다 (다른 경우 spring.cloud.stream.instanceCount). 음수 값으로 설정하면 기본값은로 설정됩니다.(카프카의 경우 autoRebalence 설정이 false 일 경우)
기본값 : -1.
Producer Properties
- partitionKeyExpression
아웃 바운드 데이터를 분할하는 방법을 결정하는 SpEL 식입니다. set 또는 ifpartitionKeyExtractorClass가 설정되면이 채널의 아웃 바운드 데이터가 분할됩니다.partitionCount효과가 있으려면 1보다 큰 값으로 설정해야합니다.
기본값 : null.
- partitionKeyExtractorClass
PartitionKeyExtractorStrategy구현입니다. set 또는 if partitionKeyExpression가 설정되면이 채널의 아웃 바운드 데이터가 분할됩니다. partitionCount효과가 있으려면 1보다 큰 값으로 설정해야합니다.
기본값 : null.
- partitionSelectorClass
PartitionSelectorStrategy구현입니다.
기본값 : null.
- partitionSelectorExpression
파티션 선택을 사용자 정의하기위한 SpEL 표현식.
기본값 : null.
- partitionCount
파티셔닝이 사용 가능한 경우 데이터의 대상 파티션 수입니다. 제작자가 분할 된 경우 1보다 큰 값으로 설정해야합니다. 카프카에서는 힌트로 해석됩니다. 이것보다 크고 대상 항목의 파티션 수가 대신 사용됩니다.
기본값 : 1.
Content-Type
Spring Cloud Stream은 contentType에 대해 세 가지 메커니즘을 제공한다.
- Header
contentType 자체를 헤더로 제공한다.
- binding
spring.cloud.stream.bindings.<inputChannel>.content-type 설정으로 타입을 설정한다.
- default
contentType이 명시적으로 설정되지 않은 경우 기본 application/json 타입으로 적용한다.
위의 순서대로 우선순위 적용이 된다.(Header>bindings>default) 만약 메소드 반환 타입이 Message 타입이면 해당 타입으로 메시지를 수신하고, 만약 일반 POJO로 반환타입이 정의되면 컨슈머에서 해당 타입으로 메시지를 수신한다.
Apache Kafka Binder
1 2 3 4 | <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> </dependency> | cs |
의존성을 추가해준다.
Kafka Binder Properties
- spring.cloud.stream.kafka.binder.brokers
Kafka 바인더가 연결될 브로커 목록이다.
기본값 : localhost
- spring.cloud.stream.kafka.binder.defaultBrokerPort
brokers 설정에 포트 정보가 존재하지 않는다면 해당 호스트 리스트들이 사용할 포트를 지정해준다.
기본값 : 9092
- spring.cloud.stream.kafka.binder.configuration
바인더로 작성된 모든 클라이언트에 전달 될 클라이언트 속성(프로듀서,컨슈머)의 키/값 맵이다. 이러한 속성은 프로듀서와 컨슈머 모두가 사용한다.
기본값 : empty map
- spring.cloud.stream.kafka.binder.headers
바인더에 의해 전송되는 사용자 지정 헤더 목록이다.
기본값 : null
- spring.cloud.stream.kafka.binder.healthTimeout
파티션 정보를 얻는 데 걸리는 시간(초).
기본값 : 10
- spring.cloud.stream.kafka.binder.requiredAcks
브로커에서 필요한 ack수이다.(해당 설명은 이전 포스팅에 설명되어있다.)
기본값 : 1
- spring.cloud.stream.kafka.binder.minPartitionCount
autoCreateTopics,autoAddPartitions true를 설정했을 경우에만 적용되는 설정이다. 바인더가 데이터를 생성하거나 소비하는 주제에 대해 바인더가 구성하는 최소 파티션 수이다.
기본값 : 1
- spring.cloud.stream.kafka.binder.replicationFactor
autoCreateTopics true를 설정했을 경우에 자동 생성된 토픽 복제요소 수이다.
기본값 : 1
- spring.cloud.stream.kafka.binder.autoCreateTopics
true로 설정하면 토픽이 존재하지 않을 경우 자동으로 토픽을 만들어준다. 만약 false로 설정되어있다면 미리 토픽이 생성되어 있어야한다.
기본값 : true
- spring.cloud.stream.kafka.binder.autoAddPartitions
true로 설정하면 바인더가 필요할 경우 파티션을 추가한다. 예를 들어 사용자의 메시지 유입이 증가하여 컨슈머를 추가하여 파티션수가 하나더 늘었다고 가정하자. 그러면 기존의 토픽의 파티션 수는 증설한 파티션의 총수보다 작을 것이고, 이 설정이 true라면 바인더가 자동으로 파티션수를 증가시켜준다.
기본값 : false
Kafka Consumer Properties
spring.cloud.stream.kafka.bindings.<inputChannel>.consumer 접두어가 붙는다.
- autoRebalanceEnabled
파티션 밸런싱을 자동으로 처리해준다.
기본값 : true
- autoCommitOffset
메시지가 처리되었을 경우, 오프셋을 자동으로 커밋할지를 설정한다.
기본값 : true
- startOffset
새 그룹의 시작 오프셋이다. earliest, latest
기본값 : null(==eariest)
- resetOffsets
Kafka Producer Properties
- bufferSize
kafka 프로듀서가 전송하기 전에 일괄 처리하려는 데이터 크기이다.
기본값 : 16384
- batchTimeout
프로듀서가 메시지를 보내기 전에 동일한 배치에 더 많은 메시지가 누적될 수 있도록 대기하는 시간. 예를 들어 버퍼사이즈가 꽉 차지 않았을 경우 얼마나 기다렸다고 메시지 처리할 것인가를 정하는 시간이다.
기본값 : 0
Partitioning with the Kafka Binder
순서가 중요한 메시지가 있을 경우가 있다. 이럴 경우에는 어떠한 키값을 같이 포함시켜 메시지를 발신함으로써 하나의 파티션에만 데이터를 보내 컨슈머쪽에서 데이터의 순서를 정확히 유지하여 데이터를 받아올 수 있다.
1 2 3 | #partition-key-expression spring.cloud.stream.bindings.exam-output.producer.partition-key-expression=headers['partitionKey'] spring.cloud.stream.bindings.exam-output.producer.partition-count=4 | cs |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | @Autowired private ExamProcessor processor; public void sendMessage(Exam exam,String partitionId) { log.info("Sending Message = {}",exam.toString()); MessageChannel outputChannel = processor.outboundChannel(); outputChannel.send(MessageBuilder .withPayload(exam) .setHeader(MessageHeaders.CONTENT_TYPE, MimeTypeUtils.APPLICATION_JSON) .setHeader("partitionKey", partitionId) .build()); } @StreamListener(ExamProcessor.INPUT) public void listenMessage(@Payload Exam payload,@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int header) { log.info("input message = {} partition_id= {}",payload.toString(),header); } | cs |
application.properties에 파티션키로 사용할 헤더의 키값을 설정하고, 프로듀서 쪽에서 키값을 포함시켜 데이터를 보낸 후에 컨슈머쪽에서 어떠한 파티션에서 데이터를 받았는지 확인해본다. 키값을 동일하게 유지한채 메시지를 보내면 하나의 파티션에서만 메시지를 받아온다. 그러나 파티션 키값을 적용하지 않고 메시지를 보내면 컨슈머가 받아오는 파티션 아이디는 계속해서 변경이 된다.
이번 포스팅은 내용이 조금 길어져서 여기까지만 작성하고 다음 포스팅에서 Spring Cloud Stream 기반에서 사용하는 kafka stream API에 대해 포스팅할 것이다. 이번 포스팅에서는 많은 설명들이 레퍼런스에 비해 빠져있다. 아는 내용은 작성하고 모르는 내용은 포함시킬경우 틀릴 가능성이 있기 때문에 레퍼런스와 비교해 내용에 차이가 있다. 혹시나 더 많은 설명이 필요하다면 직접 레퍼런스를 보면 될것 같다.
'Middleware > Kafka&RabbitMQ' 카테고리의 다른 글
| Kafka - Kafka Stream API(카프카 스트림즈) - 2 (0) | 2019.03.30 |
|---|---|
| Kafka - Spring Cloud Stream Kafka Streams API(스프링 클라우드 스트림 카프카 스트림즈 API) (0) | 2019.03.30 |
| Kafka - Kafka Streams API(카프카 스트림즈) - 1 (2) | 2019.03.26 |
| Kafka - Kafka Consumer(카프카 컨슈머) Java&CLI (2) | 2019.03.24 |
| Kafka - Kafka Producer(카프카 프로듀서) In Java&CLI (0) | 2019.03.16 |
Kafka - Kafka Consumer(카프카 컨슈머) Java&CLI

이전 포스팅에서 kafka producer를 java 소스기반으로 예제를 짜보았습니다. 이번 포스팅은 kafka consumer를 java 소스로 다루어보려고 합니다.
Kafka Producer(카프카 프로듀서)가 메시지를 생산해서 카프카의 토픽으로 메시지를 보내면 그 토픽의 메시지를 가져와서 소비(consume)하는 역할을 하는 애플리케이션, 서버 등을 지칭하여 컨슈머라고 한다. 컨슈머의 주요 기능은 특정 파티션을 관리하고 있는 파티션 리더에게 메시지를 가져오기 요청을 하는 것이다. 각 요청은 컨슈머가 메시지 오프셋을 명시하고 그 위치로부터 메시지를 수신한다. 그래서 컨슈머는 가져올 메시지의 위치를 조정할 수 있고, 필요하다면 이미 가져온 데이터도 다시 가져올 수 있다. 이렇게 이미 가져온 메시지를 다시 가져올 수 있는 기능은 여타 다른 메시지 시스템(래빗엠큐,RabbitMQ)들은 제공하지 않는 기능이다.(내부 구동방식이 다른 이유도 있음) 최근의 메시지큐 솔루션 사용자들에게 이러한 기능은 필수가 되고 있다.
카프카에서 컨슈머라고 불리는 컨슈머는 두 가지 종류가 있는데, 올드 컨슈머(Old Consumer)와 뉴 컨슈머(New Consumer)이다. 두 컨슈머의 큰 차이점은 오프셋에 대한 주키퍼 사용 유무이다. 구 버전의 카프카에서는 컨슈머의 오프셋을 주키퍼의 znode에 저장하는 방식을 지원하다가 카프카 0.9버전부터 컨슈머의 오프셋 저장을 주키퍼가 아닌 카프카의 도픽에 저장하는 방식으로 변경되었다. 아마 성능상의 이슈때문에 오프셋 저장 정책을 바꾼것 같다. 두가지 방식을 특정 버전이전까지는 지원하겠지만 아마 추후에는 후자(뉴 컨슈머)의 방식으로 변경되지 않을까싶다. 코드 레벨로 카프카 컨슈머를 다루기전 카프카 컨슈머의 주요 옵션을 본다.
컨슈머 주요 옵션(Consumer option)
-bootstrap.servers : 카프카 클러스터에 처음 연결을 하기 위한 호스트와 포트 정보로 구성된 리스트 정보이다.
-fetch.min.bytes : 한번에 가져올 수 있는 최소 데이터 사이즈이다. 만약 지정한 사이즈보다 작은 경우, 요청에 대해 응답하지 않고 데이터가 누적될 때까지 기다린다.
-group.id : 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자이다.
-enable.auto.commit : 백그라운드에서 주기적으로 오프셋을 자동 커밋한다.
-auto.offset.reset : 카프카에서 초기 오프셋이 없거나 현재 오프셋이 더 이상 존재하지 않은 경우에 다음 옵션으로 리셋한다.
1)earliest : 가장 초기의 오프셋값으로 설정
2)latest : 가장 마지막의 오프셋값으로 설정
3)none : 이전 오프셋값을 찾지 못하면 에러를 발생
-fetch.max.bytes : 한번에 가져올 수 있는 최대 데이터 사이즈
-request.timeout.ms : 요청에 대해 응답을 기다리는 최대 시간
-session.timeout.ms : 컨슈머와 브로커사이의 세션 타임 아웃시간. 브로커가 컨슈머가 살아있는 것으로 판단하는 시간(기본값 10초) 만약 컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않고 session.timeout.ms이 지나면 해당 컨슈머는 종료되거나 장애가 발생한 것으로 판단하고 컨슈머 그룹은 리밸런스(rebalance)를 시도한다. session.timeout.ms는 하트비트 없이 얼마나 오랫동안 컨슈머가 있을 수 있는지를 제어하는 시간이며, 이 속성은 heartbeat.interval.ms와 밀접한 관련이 있다. session.timeout.ms를 기본값보다 낮게 설정하면 실패를 빨리 감지 할 수 있지만, GC나 poll 루프를 완료하는 시간이 길어지게 되면 원하지 않게 리밸런스가 일어나기도 한다. 반대로는 리밸런스가 일어날 가능성은 줄지만 실제 오류를 감지하는 데 시간이 오래 걸릴 수 있다.
-hearbeat.interval.ms : 그룹 코디네이터에게 얼마나 자주 KafkaConsumer poll() 메소드로 하트비트를 보낼 것인지 조정한다. session.timeout.ms와 밀접한 관계가 있으며 session.timeout.ms보다 낮아야한다. 일반적으로 1/3 값정도로 설정한다.(기본값 3초)
-max.poll.records : 단일 호출 poll()에 대한 최대 레코드 수를 조정한다. 이 옵션을 통해 애플리케이션이 폴링 루프에서 데이터를 얼마나 가져올지 양을 조정할 수 있다.
-max.poll.interval.ms : 컨슈머가 살아있는지를 체크하기 위해 하트비트를 주기적으로 보내는데, 컨슈머가 계속해서 하트비트만 보내고 실제로 메시지를 가져가지 않는 경우가 있을 수도 있다. 이러한 경우 컨슈머가 무한정 해당 파티션을 점유할 수 없도록 주기적으로 poll을 호출하지 않으면 장애라고 판단하고 컨슈머 그룹에서 제외한 후 다른 컨슈머가 해당 파티션에서 메시지를 가져갈 수 있게한다.
-auto.commit.interval.ms : 주기적으로 오프셋을 커밋하는 시간
-fetch.max.wait.ms : fetch.min.bytes에 의해 설정된 데이터보다 적은 경우 요청에 응답을 기다리는 최대 시간
기타 많은 설정들이 있다. 혹시나 인증과 ssl 등의 다양한 설정들을 알고 싶다면 공식 홈페이지를 참고하길 바란다.(https://kafka.apache.org/documentation/#consumerconfigs)
콘솔 컨슈머로 메시지 가져오기
▶︎▶︎▶︎2019/03/13 - [Kafka&RabbitMQ] - Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법
클러스터 환경 구축 후에 예제로 토픽하나를 생성했다는 가정하게 진행한다.
Kafka console producer로 접속하여 메시지를 보내보면 위의 컨슈머로 메시지가 전달 될 것이다. 이러한 컨슈머를 실행할 때는 항상 컨슈머 그룹이라는 것이 필요하다. 토픽의 메시지를 가져오기 위한 kafka-console-consumer.sh 명령어를 실행하면서 추가 옵션으로 컨슈머 그룹 이름을 지정해야 하는데, 만약 추가 옵션을 주지 않고 실행한 경우에는 자동으로 console-consumer-xxxxx(숫자)로 컨슈머 그룹이 생성된다.

필자가 예제로 생성한 그룹아이디도 보인다. 이렇게 그룹아이디 리스트를 볼 수 있는 명령어도 제공한다. 혹시나 모르시는 분들을 위해 토픽 리스트를 볼 수 있는 명령어도 있다.

보면 필자가 사용하고 있는 카프카 버전은 뉴 컨슈머를 이용하는 것을 알 수 있다. 바로 메시지 오프셋을 저장하기 위한 __consumer_offsets가 토픽에 존재하기 때문이다.

또한 컨슈머를 실행시킬 때에 위에서 설명한 것과 같이 그룹아이디 값 옵션을 추가하여 실행시킬 수도 있다.
자바코드를 이용한 컨슈머
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | import java.util.Arrays; import java.util.Properties; import java.time.Duration; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import lombok.extern.slf4j.Slf4j; /** * Kafka Consumer Exam * @author yun-yeoseong * */ @Slf4j public class KafkaBookConsumer1 { public static Properties init() { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094,localhost:9095"); props.put("group.id", "exam-consumer-group"); props.put("enable.auto.commit", "true"); props.put("auto.offset.reset", "latest"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); return props; } /** * 컨슈머예제 */ public static void consume() { try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(init());){ //토픽리스트를 매개변수로 준다. 구독신청을 한다. consumer.subscribe(Arrays.asList("test-topic")); while (true) { //컨슈머는 토픽에 계속 폴링하고 있어야한다. 아니면 브로커는 컨슈머가 죽었다고 판단하고, 해당 파티션을 다른 컨슈머에게 넘긴다. ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) log.info("Topic: {}, Partition: {}, Offset: {}, Key: {}, Value: {}\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } } finally {} } public static void main(String[] args) { // TODO Auto-generated method stub consume(); } } | cs |
소스에 대해 간단히 설명하면 우선 컨슈머 옵션들을 Properties 객체로 정의한다. 오프셋 리셋 옵션을 lastest로 주어 토픽의 가장 마지막부터 메시지를 가져온다. 메시지의 키와 값의 역직렬화 옵션을 문자열로 해준다. 이렇게 컨슈머 옵션을 설정하고 해당 옵션값을 이용하여 KafkaConsumer 객체를 생성해준다. 해당 객체는 사용이 후에 꼭 close 해줘야 하기 때문에 try문 안에 객체 생성코드를 넣어놔 자동으로 자원반납을 할 수 있게 해주었다. 그리고 해당 컨슈머 객체로 토픽에 대해 구독신청을 해준다. 구독 대상이 되는 토픽은 리스트로 여러개 지정가능하다. 이것 또한 카프카의 장점중 하나이다.(하나의 컨슈머가 여러 메시지큐를 구독하는 것)
그리고 해당 컨슈머는 계속해서 폴링한다. 무한 루프로 계속해서 폴링하지 않으면 컨슈머가 종료된 것으로 간주되어 컨슈머에 할당된 파티션은 다른 컨슈머에게 전달되고 다른 컨슈머에 의해 메시지가 컨슘된다. poll() 메소드의 매개변수는 타임아웃 주기이다. 이 타임아웃주기는 데이터가 컨슈머 버퍼에 없다면 poll()은 얼마 동안 블록할지를 조정하는 것이다. 또한 poll()은 레코드 전체를 리턴하고, 레코드에는 토픽,파티션,파티션의 오프셋,키,값을 포함하고 있다. 한 번에 하나의 메시지만 가져오는 것이 아니라 여러개의 메시지를 가져오기 때문에 for-each로 데이터들을 처리하고 있다.
메시지의 순서


파티션이 3개인 토픽을 새로 만들어서 해당 토픽으로 메시지를 a,b,c,d,e 순서대로 보내보았다. 그리고 컨슈머 실행후 결과를 보니 a,d,b,e,c 순서대로 메시지가 들어왔다. 컨슈머에 문제가 있는 것인가? 아니면 진짜 내부적으로 문제가 있어서 순서가 보장되지 않은 것인가 궁금할 수 있다. 하지만 지극히 정상인 결과값이다.
먼저 해당 토픽에 메시지가 어떻게 저장되어 있는지 부터 확인해봐야 한다. 해당 토픽은 파티션이 3개로 구성되어 있기 때문에 각 파티션별로 메시지가 어떻게 저장되어 있는지 확인해봐야한다.

0번 파티션에는 b,e 1번 파티션에는 a,d 2번 파티션에는 c 데이터가 저장되어 있는 것을 볼수 있다. 즉, 컨슈머는 프로듀서가 어떤 순서대로 메시지를 보내는지 알수 없다. 단지 파티션의 오프셋 기준으로만 메시지를 가져올 뿐이다. 이말은 무엇이냐면, 카프카 컨슈머에서의 메시지 순서는 동일한 파티션내에서만 유지되고 파티션끼리의 메시지 순서는 보장하지 않는 것이다.
카프카를 사용하면서 메시지의 순서를 보장해야 하는 경우에는 토픽의 파티션 수를 1로 설정한다. 하지만 단점도 존재한다. 메시지의 순서는 보장되지만 파티션 수가 하나이기 때문에 분산해서 처리할 수 없고 하나의 컨슈머에서만 처리할 수 있기 때문에 처리량이 높지 않다. 즉 처리량이 높은 카프카를 사용하지만 메시지의 순서를 보장해야 한다면 파티션 수를 하나로 만든 토픽을 사용해야 하며, 어느 정도 처리량이 떨어지는 부분은 감수해야한다.
컨슈머 그룹

기본적으로 컨슈머 그룹 안에서 컨슈머들은 메시지를 가져오고 있는 토픽의 파티션에 대해 소유권을 공유한다. 컨슈머 그룹 내 컨슈머의 수가 보족해 프로듀서가 전송하는 메시지를 처리하지 못하는 경우에는 컨슈머를 추가해야하며, 추가 컨슈머를 동일한 컨슈머 그룹 내에 추가시키면 하나의 컨슈머가 가져오고 있던 메시지를 적절하게 나누어 가져오기 시작한다.만약 위의 그림처럼 만약 Consumer Group A가 C1만 있었고, C2라는 컨슈머를 동일한 그룹내에 추가했다면 P2,P3의 소유권이 C1에서 C2로 이동한다. 이것이 초반에 이야기 했던 리밸런스라고한다. 이렇게 리밸런스라는 기능을 통해 컨슈머를 쉽고 안전하게 추가할 수 있고 제거할 수도 있어 높은 가용성과 확장성을 확보할 수 있다. 하지만 이러한 리밸런스도 단점은 있다. 리밸런스를 하는 동안 일시적으로 컨슈머는 메시지를 가져올 수 없다. 그래서 리밸런스가 발생하면 컨슈머 그룹 전체가 일시적으로 사용할 수 없다는 단점이 있다.
위의 그림에서 Consumer Group B에 4개의 컨슈머가 있음에도 불구하고 처리가 계속 지연된다면 어떻게 될까? 이전처럼 해당 컨슈머 그룹에 컨슈머만 추가하면 될까? 아니다. 이뉴는 토픽의 파티션에는 하나의 컨슈머만 연결 할 수 있기 때문이다. 이말은 즉슨, 토픽의 파티션 수 만큼 최대 컨슈머 수가 연결될수 있는 것이다. 토픽의 파티션 수와 동일하게 컨슈머 수를 늘렸는데도 프로듀서가 보내는 메시지의 속도를 따라가지 못한다면 컨슈머만 추가하는 것이 아니라, 토픽의 파티션 수까지 늘려주고 컨슈머 수도 늘려줘야한다.
이번에는 잘 동작하던 컨슈머 그룹 내에서 컨슈머 하나가 다운되는 경우를 생각해보자. 컨슈머가 컨슈머 그룹 안에서 멤버로 유지하고 할당된 파티션의 소유권을 유지하는 방법은 하트비트를 보내는 것이다. 반대로 생각해보면, 컨슈머가 일정한 주기로 하트비트를 보내다는 사실은 해당 파티션의 메시지를 잘 처리하고 있다는 것이다. 하트비트는 컨슈머가 poll 할때와 가져간 메시지의 오프셋을 커밋할 때 보내게 된다. 만약 컨슈머가 오랫동안 하트비트를 보내지 않으면 세션은 타임아웃되고, 해당 컨슈머가 다운되었다고 판단하여 리밸런스가 일어난다. 그 이후 다른 컨슈머가 다운된 컨슈머의 파티션의 할당 파티션을 맡게 되는 것이다.
커밋과 오프셋
자동커밋
오프셋을 직접 관리해도 되지만, 각 파티션에 대한 오프셋 정보관리, 파티션 변경에 대한 관리 등이 매우 번거로울 수 있다. 그래서 카프카에서는 자동커밋 기능을 제공해준다. 자동 커밋을 사용하고 싶을 때는 컨슈머 옵션 중 enable.auto.commit=true로 설정하면 5초마다 컨슈머는 poll을 호출할 때 가장 마지막 오프셋을 커밋한다. 5초 주기는 기본 값이며, auto.commit.interval.ms 옵션을 통해 조정이 가능하다. 컨슈머는 poll을 요청할 때마다 커밋할 시간이 아닌지 체크하게 되고, poll 요청으로 가져온 마지막 오프셋을 커밋한다. 하지만 이 옵션을 사용할 경우 커밋 직전 리밸런스등의 작업이 일어나면 동일한 메시지에 대한 중복처리가 일어날 수 있다. 물론 자동커밋 주기를 작게 잡아 최대한 중복을 줄일 수 있지만 중복등을 완전하게 피할 수 는없다.
수동커밋
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | import java.util.Arrays; import java.util.Properties; import java.time.Duration; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import lombok.extern.slf4j.Slf4j; /** * Kafka Consumer Exam * @author yun-yeoseong * */ @Slf4j public class KafkaBookConsumer1 { public static Properties init() { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094"); props.put("group.id", "yoon-consumer"); props.put("enable.auto.commit", "true"); props.put("auto.offset.reset", "latest"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); return props; } /** * 수동커밋 */ public static void commitConsume() { try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(init());){ //토픽리스트를 매개변수로 준다. 구독신청을 한다. consumer.subscribe(Arrays.asList("yoon")); while (true) { //컨슈머는 토픽에 계속 폴링하고 있어야한다. 아니면 브로커는 컨슈머가 죽었다고 판단하고, 해당 파티션을 다른 컨슈머에게 넘긴다. ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) log.info("Topic: {}, Partition: {}, Offset: {}, Key: {}, Value: {}\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); /* * DB로직(CRUD) 이후 커밋. */ consumer.commitSync(); ->수동으로 커밋하여 메시지를 가져온 것으로 간주하는 시점을 자유롭게 조정할 수있다. } } finally {} } public static void main(String[] args) { // TODO Auto-generated method stub commitConsume(); } } | cs |
특정 파티션 할당
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | package com.kafka.exam; import java.util.Arrays; import java.util.Properties; import java.time.Duration; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import lombok.extern.slf4j.Slf4j; /** * Kafka Consumer Exam * @author yun-yeoseong * */ @Slf4j public class KafkaBookConsumer1 { /** * 특정 파티션 할당 */ public static void specificPart() { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094"); //특정 파티션을 할당하기 위해서는 기존과는 다른 그룹아이디 값을 주어야한다. 왜냐하면 컨슈머 그룹내에 같이 있게되면 서로의 //오프셋을 공유하기 때문에 종료된 컨슈머의 파티션을 다른 컨슈머가 할당받아 메시지를 이어서 가져가게 되고, 오프셋을 커밋하게 된다. props.put("group.id", "specificPart"); props.put("enable.auto.commit", "false"); props.put("auto.offset.reset", "latest"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); String topicName = "yoon"; try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(init());){ //토픽리스트를 매개변수로 준다. 구독신청을 한다. TopicPartition partition0 = new TopicPartition(topicName, 0); TopicPartition partition1 = new TopicPartition(topicName, 1); consumer.assign(Arrays.asList(partition0,partition1)); while (true) { //컨슈머는 토픽에 계속 폴링하고 있어야한다. 아니면 브로커는 컨슈머가 죽었다고 판단하고, 해당 파티션을 다른 컨슈머에게 넘긴다. ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) log.info("Topic: {}, Partition: {}, Offset: {}, Key: {}, Value: {}\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); /* * DB로직(CRUD) 이후 커밋. */ consumer.commitSync(); } } finally {} } public static void main(String[] args) { // TODO Auto-generated method stub specificPart(); } } | cs |
특정 오프셋부터 메시지 가져오기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | package com.kafka.exam; import java.util.Arrays; import java.util.Properties; import java.time.Duration; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import lombok.extern.slf4j.Slf4j; /** * Kafka Consumer Exam * @author yun-yeoseong * */ @Slf4j public class KafkaBookConsumer1 { /** * 특정파티션에서 특정 오프셋의 메시지 가져오기 */ public static void specificOffset() { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094"); //특정 파티션을 할당하기 위해서는 기존과는 다른 그룹아이디 값을 주어야한다. 왜냐하면 컨슈머 그룹내에 같이 있게되면 서로의 //오프셋을 공유하기 때문에 종료된 컨슈머의 파티션을 다른 컨슈머가 할당받아 메시지를 이어서 가져가게 되고, 오프셋을 커밋하게 된다. props.put("group.id", "specificPartAndOffset"); props.put("enable.auto.commit", "false"); props.put("auto.offset.reset", "latest"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); String topicName = "yoon"; try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(init());){ //토픽리스트를 매개변수로 준다. 구독신청을 한다. TopicPartition partition0 = new TopicPartition(topicName, 0); TopicPartition partition1 = new TopicPartition(topicName, 1); consumer.assign(Arrays.asList(partition0,partition1)); //0,1번 파티션의 2번 오프셋의 메시지를 가져와라 consumer.seek(partition0, 2); consumer.seek(partition1, 2); while (true) { //컨슈머는 토픽에 계속 폴링하고 있어야한다. 아니면 브로커는 컨슈머가 죽었다고 판단하고, 해당 파티션을 다른 컨슈머에게 넘긴다. ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) log.info("Topic: {}, Partition: {}, Offset: {}, Key: {}, Value: {}\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); /* * DB로직(CRUD) 이후 커밋. */ consumer.commitSync(); } } finally {} } public static void main(String[] args) { // TODO Auto-generated method stub specificOffset(); } } | cs |
여기까지 자바소스로 다루어본 카프카 컨슈머 예제들이었습니다. 부족한 점이 많습니다. 혹시나 잘못된 점이 있다면 지적해주시면 감사하겠습니다!
'Middleware > Kafka&RabbitMQ' 카테고리의 다른 글
| Kafka - Spring cloud stream kafka(스프링 클라우드 스트림 카프카) (0) | 2019.03.28 |
|---|---|
| Kafka - Kafka Streams API(카프카 스트림즈) - 1 (2) | 2019.03.26 |
| Kafka - Kafka Producer(카프카 프로듀서) In Java&CLI (0) | 2019.03.16 |
| Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법 (0) | 2019.03.13 |
| Kafka - Kafka(카프카)의 동작 방식과 원리 (0) | 2019.03.12 |
Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법

▶︎▶︎▶︎카프카란?
이전 포스팅에서는 메시징 시스템은 무엇이고, 카프카는 무엇이며 그리고 카프카의 특징과 다른 메시지 서버와의 차이점에 대한
포스티이었습니다. 이번 포스팅은 간단하게 카프카3대를 클러스터링 구성을 하여 서버를 띄우고 CLI를 이용하여 간단히
카프카를 사용해보려고 합니다. 카프카는 중앙에서 많은 서비스 시스템의 데이터를 받아서 다른 시스템으로 받아주는 역할을 하는
메시지 시스템으로 MSA에서는 없어선 안되는 존재가 되었습니다. 그렇다면 이렇게 중요한 카프카를 한대만 띄워서 프로덕트 환경에서
운영한다는 것은 과연 안전한 생각일까요? 아닙니다. 여러대를 클러스터링 구성하여 고가용성을 높혀야 운영환경에서도 안전하고 신뢰성있는
메시지 시스템 구성이 될것입니다.

위의 그림은 카프카를 여러대 클러스터링을 했을 경우의 구성도 입니다. 일단 중요한 것은 Zookeeper라는 존재입니다. 주키퍼는
이전 포스팅에서 Zookeeper란 무엇인가? 그리고 Solr 클러스터링 구성을 했을 때 다뤘던 내용이므로 이번 포스팅에서는 생략합니다.

▶︎▶︎▶︎Zookeeper란?
▶︎▶︎▶︎Solr Cluster 구성
간단하게 이야기하면 주키퍼란 분산환경 애플리케이션을 중앙에서 관리해주는 디렉토리 구조의 분산 코디네이터라고 보시면 됩니다. 지금부터는
실습에 초점을 마추겠습니다.
우선은 주키퍼를 설치해줍니다. 이번 실습의 버전은 3.4.12 버전기준입니다.
설정파일을 만지기 전에 주키퍼를 위한 디렉토리 구성을 진행하겠습니다. 저는 카프카 실습을 위해 별도의 하나의 디렉토리를 구성하였고,
그안에 주키퍼와 카프카에 대한 파일들을 모두 넣어놓았습니다. 우선 다음 예제는 주키퍼와 카프카를 별도의 디렉토리에 설치했다는 가정하에 진행합니다.
주키퍼는 링크를 참조하셔서 총 3대로 띄워주시면 됩니다.(Master-slave 관계의 클러스터)
카프카도 동일한 디렉토리에 설치해줍니다. 편의상 카프카의 디렉토리 루트를 $KAFKA로 지칭합니다.
우선 진행하기 앞서 클러스터 구성에서 인스턴스 각각이 자신의 메타 데이터와 카프카가 데이터를 쓸 디렉토리를 만들어줍니다.
kdata1,kdata2,kdata3 디렉토리를 만들어줍니다. 그리고 $KAFKA/config 밑에 있는 server.properties를 2장 복사해줍니다.
그리고 해당 파일 안에 설정들을 클러스터 구성에 가장 기본이 되는 설정으로 바꿔줍니다.
broker.id = 1,broker.id = 2,broker.id = 3 으로 총 3개의 serverN.properties에 작성해줍니다. 이것은
주키퍼 myid와 비슷한 역할을 하는 클러스터 인스턴스 구분용 ID값입니다.
그리고 지금 실습은 로컬에 3대의 카프카서버를 띄워서 클러스터링 구성을 할것임으로 각각 서버의 포트를 달리 지정해줍니다.
listeners=PLAINTEXT://:9092,listeners=PLAINTEXT://:9093,listeners=PLAINTEXT://:9094 으로 각각 파일에 포트를 구분해줍니다.
log.dirs=$KAFAKA/kdata1,log.dirs=$KAFAKA/kdata2,log.dirs=$KAFAKA/kdata3 으로 각각 카프카 서버가 자신의
메타 데이터를 쓸 디렉토리를 구분지어줍니다. 필자는 처음에 하나의 디렉토리만 생성해서 공유했더니 충돌 문제가 있어
각각 별도의 디렉토리 구성을 가져갔습니다.
마지막으로 주키퍼와의 연동 설정입니다.
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183/kafka-broker 으로 각 설정 파일에 동일하게 작성해줍니다.
여기에서 조금 특이한것이 ~/kafka-broker 입니다. 이것은 무엇이냐면 만약 각각 다른 용도의 카프카 클러스터를 2세트 운영한다고 가정하고,
주키퍼는 같은 주키퍼 클러스터를 이용한다고 합니다. 만약 ~/kafka-broker를 입력하지 않으면 카프카 클러스터 2세트가 주키퍼의 루트 디렉토리에 동일한
구조의 데이터를 쓰게 되고 그러면 카프카 클러스터 2세트가 데이터 충돌이 나게됩니다. 그렇기 때문에 ~/kafka-broker라고 입력하여 주키퍼의 루트디렉토리가
아닌 /kafka-broker/.. 라는 디렉토리를 하나 새로 생성하여 아예 카프카 클러스터 1대의 전용 디렉토리를 구성해주는 겁니다. 여기까지 진짜 기본적인
설정으로 클러스터 설정을 마쳤습니다. 사실은 이정도 설정으로는 운영환경에서는 운영하기 힘들것입니다. 나머지 설정관련해서는 카프카 공식 홈페이지에
영어로 친절하게? 작성되어 있으니 참고 부탁드립니다.
이제 $KAFKA/bin/kafka-server-start.sh -daemon ../config/server.properties 명령으로 3개의 카프카를 실행시켜줍니다. 물론 선행조건은
주키퍼가 실행되었다는 조건입니다. 만약 지금까지 잘 따라오셨다면 문제없이 실행됩니다. 마지막으로 간단한 CLI를 이용한 producer,consumer 예제입니다.

위의 명령으로 큐의 역할로 사용될 토픽을 생성해줍니다. 만약 토픽을 잘못 생성하신 분들을 위해서 토픽을 삭제하는 명령입니다.

Noting 메시지와 함께 토픽이 삭제되었습니다.

프로듀서를 실행시켜줍니다. 설정 인자들은 설명없어도 직관적으로 보입니다.

메시지를 보냅니다.

또 한번 보냅니다.

컨슈머 쪽을 확인해보면 메시지가 잘와있는 것을 확인할 수 있습니다. 여기까지 카프카 클러스터 구성과 간단한 CLI를 이용하여 카프카를 사용해보았습니다.
'Middleware > Kafka&RabbitMQ' 카테고리의 다른 글
| Kafka - Kafka Streams API(카프카 스트림즈) - 1 (2) | 2019.03.26 |
|---|---|
| Kafka - Kafka Consumer(카프카 컨슈머) Java&CLI (2) | 2019.03.24 |
| Kafka - Kafka Producer(카프카 프로듀서) In Java&CLI (0) | 2019.03.16 |
| Kafka - Kafka(카프카)의 동작 방식과 원리 (0) | 2019.03.12 |
| Springboot - Rabbitmq를 이용한 비동기 메시징 서비스(리액티브 마이크로서비스) (2) | 2019.02.18 |
Kafka - Kafka(카프카)의 동작 방식과 원리

Kafka는 기본적으로 메시징 서버로 동작합니다. 여기서 메시징 시스템에 대해 간단히 살펴보자면
메시지라고 불리는 데이터 단위를 보내는 측(publisher,producer)에서 카프카에 토픽이라는 각각의 메시지 저장소에 데이터를 저장하면,
가져가는 측(subscriber, consumer)이 원하는 토픽에서 데이터를 가져가게 되어 있습니다. 즉, 메시지 시스템은 중앙에 메시징 시스템 서버를
두고 이렇게 메시지를 보내고(publish) 받는(subscriber) 형태의 통신 형태인 pub/sub 모델의 통신구조입니다.
여기서 미담이지만, 카프카의 창시자인 제이 크렙스는 대학 시절 문학 수업을 들으며 소설가 프란츠 카프카에 심취했습니다. 자신의 팀이 새로 개발할 시스템이
데이터 저장과 기록, 즉 쓰기에 최적화된 시스템이었기에 이런 시스템은 글을 쓰는 작가의 이름을 사용하는 것이 좋겠다 생각하여
카프카라는 이름으로 애플리케이션이 탄생하게 되었습니다.
pub/sub은 비동기 메시징 전송 방식으로서, 발신자의 메시지에는 수신자가 정해져 있지 않은 상태로 발행합니다. 구독을 신청한 수신자만이 정해진
메시지를 받을 수 있습니다. 또한 수신자는 발신자 정보가 없어도 원하는 메시지만을 수신가능합니다.
펍/섭 구조가 아닌 일반적인 통신은
A ---------------> B
C ---------------> D
형태로 통신을 하게 됩니다. 이럴 경우 빠른 전송 속도와 전송 결과를 신속하게 알 수 있는 장점이 있지만, 장애가 발생한 경우
적절한 처리를 수신자 측에서 해주지 않는다면 문제가 될 수 있습니다. 그리고 통신에 참여하는 개체수가 많아 질 수록
일일이 다 연결하고 데이터를 전송해야 하기 때문에 확장성이 떨어집니다.
하지만 펍/섭구조는
==========
A ---------------->=메시지서버= ---------->B
C ---------------->========== ---------->D
프로듀서가 메시지를 컨슈머에게 직접 전달하는 방식이 아니라 중간의 메시징 시스템에 전달합니다. 이때 메시지 데이터와 수신처 ID를
포함시킵니다. 메시징 시스템의 교환기가 메시지의 수신처ID 값을 확인한 다음 컨슈머들의 큐에 전달합니다. 컨슈머는 자신들의
큐를 모니터링하고 있다가, 큐에 메시지가 전달되면 이 값을 가져갑니다. 이렇게 구성할 경우 장점은 혹시나 통신 개체가 하나 빠지거나 수신 불가능 상태가 되었을
때에도, 메시징 시스템만 살아 있다면 프로듀서에서 전달된 메시지는 유실되지 않고, 장애에서 복구한 통신 개체가 살아나면 다시 메시지를
안전하게 전달할 수 있습니다. 그리고 메시징 시스템을 중심으로 연결되기 때문에 확장성이 용이합니다. 물론 직접 통신 하지 않기 때문에
메시지가 정확하게 전달되었는지 확인하는 등의 코드가 들어가 복잡해지고, 메시징 서버를 한번 거쳐서 가기에 통신속도가 느린 단점도 있습니다.
하지만 메시징 시스템이 주는 장점때문에 이러한 단점은 상쇄될만큼 크지 않다고 생각합니다.(비동기가 주는 장점 등)

(밑의 설명을 두고 넣은 그림은 아님)

기존 메시징 시스템을 사용하는 펍/섭 모델은 대규모 데이터(데이터 단건당 수MB 이상)를 메시징 시스템을 통해 전달하기 보다는 간단한 이벤트(수KB정도)를 서로 전송하는데 주로 사용되었습니다. 왜냐하면 메시징 시스템 내부의 교환기의 부하, 각 컨슈머들의 큐관리, 큐에 전달되고 가져가는 메시지의 정합성, 전달 결과를
정확하게 관리하기 위한 내부 프로세스가 아주 다양하고 복잡했기 때문입니다.
즉, 기존 메시징 시스템은 속도와 용량보단 메시지의 보관,교환,전달 과정에서의 신뢰성을 보장하는 것에 중점을 두었습니다.
카프카는 메시징 시스템이 지닌 성능의 단점을 극복하기 위해, 메시지 교환 전달의 신뢰성 관리를 프로듀서와 컨슈머 쪽으로 넘기고, 부하가 많이 걸리는 교환기 기능
역시 컨슈머가 만들 수 있게 함으로써 메시징 시스템 내에서의 적업량을 줄이고 이렇게 절약한 작업량을 메시지 전달 성능에 집중시켜
고성능 메시징 시스템을 만들어 냈습니다.

카프카의 특징
프로듀서와 컨슈머의 분리 - 카프카는 메시징 전송 방식 중 메시지를 보내는 역할과 받는 역할이 완벽하게 분리된 펍/섭 방식을 적용했습니다. 각 서비스서버들은 다른 시스템의 상태 유무와 관계없이 카프카로 메시지를 보내는 역할만 하면 되고, 마찬가지로 메시지를 받는 시스템도서비스 서버들의 상태유무와 관계없이 카프카에 저장되어 있는 메시지만 가져오면 됩니다.
멀티 프로듀서, 멀티 컨슈머 - 카프카는 하나의 토픽에 여러 프로듀서 또는 컨슈머들이 접근 가능한 구조로 되어있습니다. 하나의 프로듀서가 하나의토픽에만 메시지를 보내는 것이 아니라, 하나 또는 하나 이상의 토픽으로 메시지를 보낼 수 있습니다. 컨슈머는 역시 하나의 토픽에서만메시지를 가져오는 것이 아니라, 하나 또는 하나 이상의 토픽으로부터 메시지를 가져올 수 있습니다. 이렇게 멀티 프로듀서와 멀티 컨슈머를구성할 수 있기 때문에 카프카는 중앙 집중형 구조로 구성할 수 있게 됩니다.
디스크에 메시지 저장 - 카프카가 기존의 메시징 시스템과 가장 다른 특징 중 하나는 메모리에 데이터를 쓰는 것이 아니라, 바로 디스크에 메시지를 저장하고유지하는 것입니다. 일반적인 메시징 시스템들은 컨슈머가 메시지를 읽어가면 큐에서 바로 삭제하는데, 카프카는 컨슈머가 데이터를 가져가도 일정 기간동안데이터를 유지합니다. 트래픽이 급증해도 컨슈머는 디스크에 안전하게 저장된 데이터를 손실 없이 가져갈 수 있습니다. 또한 앞서 멀티 컨슈머가 가능한 것도이렇게 디스크에 데이터를 쓰기 때문입니다. 디스크에 데이터를 쓰기 때문에 처리가 느릴 것이라는 생각을 할 수 있기도한대, 기존의 디스크 사용법과는다르게 디스크를 나눠서 쓰는 것이 아니라, 특정 영역의 디스크에 순차적으로 쓰기 때문에 읽어가는 디스크의 영역의 범위를 확 줄일 수 있어 읽어가는 속도는조금은 빨라집니다. 그리고 카프카는 무조건 데이터를 디스크에 쓴다기 보다는 VM메모리의 일부를 페이지 캐싱으로 사용하기 때문에 속도가 빠릅니다.
확장성 - 카프카는 확장이 매우 용이하도록 설계되어 있습니다. 하나의 카프카 클러스터는 3대부터 수십대의 브로커로도 메시지 서버의 중지없이 확장 가능합니다.
높은성능 - 카프카는 내부적으로 고성능을 유지하기 위해 분산 처리, 배치 처리 등 다양한 기법을 사용하고 있습니다.(병렬 처리를 위한 토픽 파티셔닝 기능)
이러한 카프카의 사용으로 연동되는 애플리케이션들의 느슨한 결합도를 유지할 수 있게 됩니다. 이번 포스팅은 간단한 카프카의 소개였고,다음 포스팅부터는 진짜 카프카를 이용한 예제 포스팅이 될 것 같습니다.
'Middleware > Kafka&RabbitMQ' 카테고리의 다른 글
| Kafka - Kafka Streams API(카프카 스트림즈) - 1 (2) | 2019.03.26 |
|---|---|
| Kafka - Kafka Consumer(카프카 컨슈머) Java&CLI (2) | 2019.03.24 |
| Kafka - Kafka Producer(카프카 프로듀서) In Java&CLI (0) | 2019.03.16 |
| Kafka - Kafka(카프카) cluster(클러스터) 구성 및 간단한 CLI사용법 (0) | 2019.03.13 |
| Springboot - Rabbitmq를 이용한 비동기 메시징 서비스(리액티브 마이크로서비스) (2) | 2019.02.18 |