2019. 6. 17. 22:49ㆍSearch-Engine/Elasticsearch&Solr
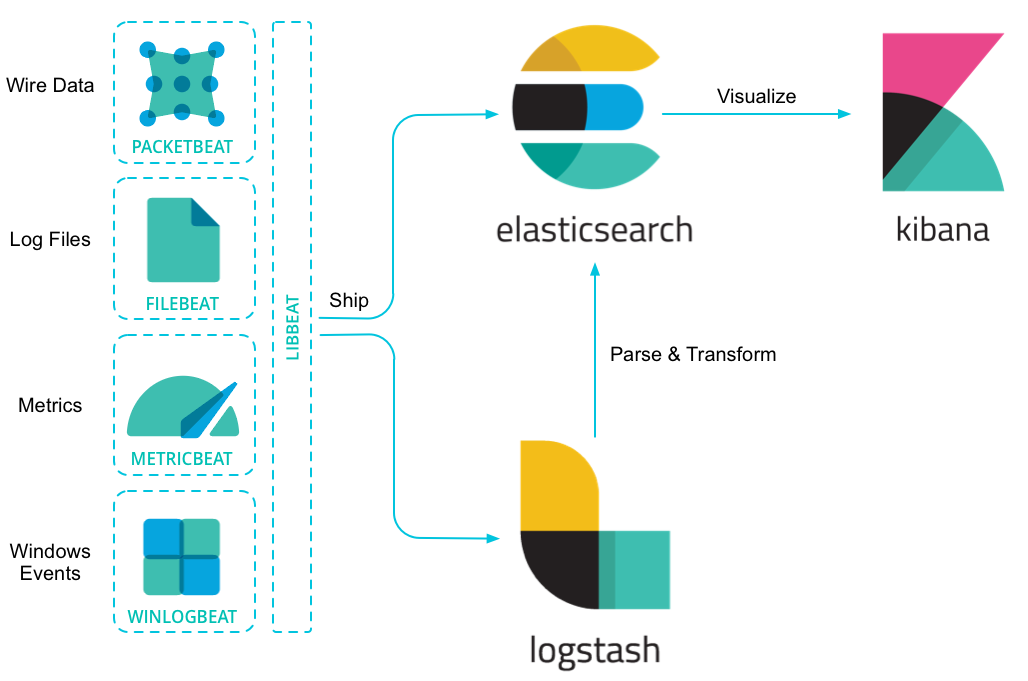
오늘 포스팅할 내용은 ELK Stack에서 중요한 보조 수단 중 하나인 Filebeat(파일비트)에 대해 다루어볼 것이다. 우선 Filebeat를 이용하는 사례를 간단하게 하나 들어보자면, 운영중인 애플리케이션에서 File을 통한 로그데이터를 계속 해서 쌓고 있다면 이러한 로그데이터를 단순 파일로 가지고 있는 것이 유용할까? 물론 모니터링하는 시스템이 존재 할 수 있다. 하지만 이러한 모니터링 시스템이 아닌 로그데이터를 계속해서 축적하여 통계를 내고 싶고, 데이터의 증가,하강 추이를 시각화하여 보고 싶을 수도 있다. 이렇게 특정 로그파일을 주기적으로 스캔하여 쌓이고 있는 데이터를 긁어오는 역할을 하는 것이 파일비트이다. 물론 록그스태시만 이용하여 파일에 쌓이는 행데이터를 가져올 수 있다. 하지만 이러한 로그스태시를 엔드서버에 설치하지 못하는 상황이 있을 수 있기에 가벼운 파일비트를 이용하곤 한다.

파일비트 아키텍쳐
파일비트는 Prospectors, Harvesters, Spooler라는 주요 구성 요소를 가지고 있다. Prospector는 로그를 읽을 파일 목록을 구분하는 역할을 담당한다. 여러 파일 경로를 설정하면 로그를 읽을 파일을 식별하고 각 파일에서 로그를 읽기 시작한다. 이때 파일 컨텐츠, 즉 이벤트 데이터(로그)를 읽는 역할은 Harvester가 담당한다. 파일을 행 단위로 읽고 출력으로 보낸다. 하나의 Harvester가 개별로 파일을 담당하며 파일을 열고 닫는다. 읽어올 파일 수가 여러개가 되면 그에 따라 Harvester도 여러개가 되는 것이다. 이벤트가 발생하여 읽어온 로그데이터는 Spooler에게 보낸다. 그리고 Spooler는 이벤트를 집계하고 설정할 출력으로 전달한다.
위의 그림처럼 파일비트는 다수의 Prospector, Harvester로 이루어진다. 파일비트가 지원하는 Input 타입은 log와 stdin이 있다. log는 Prospectors에 정의된 파일을 읽어 데이터를 수집하며, stdin은 표준 입력에서 데이터를 읽는다. 그럼 여기서 의문이 드는 것이 있다. 물리적인 파일을 읽는데 어디까지 읽었고, 출력은 어디까지 보냈고 이런 정보를 어디서 유지하고 있는 것일까? 이러한 정보는 Harvester가 offset으로 디스크에 주기적으로 기록하며 이는 레지스트리 파일에서 관리한다. 엘라스틱서치,카프카,레디스 같은 출력 부분 미들웨어 시스템에 문제가 발생하면 파일비트는 마지막으로 보낸 행을 기록하고, 문제가 해결될때까지 계속 데이터를 수집하고 있는다. 이러한 관리 덕분에 파일비트를 내렸다 다시 올려도 데이터의 위치를 기억한 상태에서 기동되게 된다. 또한 Harvester 같은 경우 출력에게 데이터를 보낸 후에 출력 부분에서 데이터를 잘 받았다는 응답을 기다리는데 해당 응답을 받지 않은 경우 다시 데이터를 보내게됨으로 반드시 한번은 데이터 손실없이 보내게 된다.
파일비트 사용법(filebeat-6.6.2 버전기준으로 작성됨)
여기서 파일비트 설치법은 다루지 않는다. 예제에서 다루어볼 것은 Input(file-log type) output(es,logstash) 이다. 간단한 예제이므로 주석에 설명을 달아놓았고 별도의 설명은 하지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
filebeat.yml
#Filebeat prospectors
filebeat.prospectors:
- input_type: log
paths:
- /Users/yun-yeoseong/rnb-chatbot-rivescript/logs/*.log
#파일비트로 읽어오지 않을 패턴을 지정
#exclude_lines: ["^INFO"]
#파일비트로 읽어올 패턴을 지정
#include_liens: ["^ERR","^WARN"]
#파일비트가 파일을 output으로 내보낼때 밑의 tags도 추가해서 보낸다.(field -> tags)
#보통 수집기 별로 혹은 애플리케이션 별로 tags 필드의 값을 다르게 주어
#키바나와 로그스태시에서 이벤트를 필터링하는데 사용한다.
tags: ["app_logs"]
#output으로 보낼때 해당 필드를 추가해서 보낸다.(field -> fields.env)
fields:
env: dev
#여러라인의 로그를 어떻게 처리할지 패턴을 정의한다
#RE2 구문을 기반으로 정규식을 짠다(https://godoc.org/regexp/syntax)
#공백으로 시작하는 연속행을 발견한다.
multiline.pattern: '^[[:space:]]'
#정규식패턴 무효화 여부
multiline.negate: false
#공백으로 시작하는 구문을 공백으로 시작하지 않는 구문 어디로 합칠것인가(after,before)
multiline.match: after
#파일을 몇 초마다 스캔할 것인가(default 10s)
scan_frequency: 5s
#엘라스틱서치가 아웃풋이라면 document type을 무엇으로 할지
#document_type: doc
#Outputs
#Elasticsearch output
output.elasticsearch:
#enabled로 출력을 활성/비활성 할 수 있다.
enabled: true
#ES클러스터 노드 리스트를 지정할 수 있다. 각 노드의 데이터 분배는
#라운드로빈 방식을 이용한다.
hosts: ["localhost:9200","localhost:9300"]
#인증이 필요할 경우 username/password 지정이 가능
username: "elasticsearch"
password: "password"
#인제스트노드 파이프라인에 전달해 색인 이전에 데이터 전처리가 가능
#pipeline: "pipeline-name"
#logstash output, 로그스태시를 지정하려면 로그스태시에서
#비트 이벤트를 수신할 수 있는 비트 입력 플러그인을 설정해야한다.
#output.logstash:
# enabled: true
#출력 노드를 여러개 지정할 수 있다. 기본적으로 임의의 노드를 선택해 데이터를 보내고,
#데이터를 보낸 호스트에서 응답을 하지 않으면 다른 노드들중 하나로 다시 데이터를 보낸다.
#hosts: ["localhost:5044","localhost:5045"]
#로그스태시 호스트들에서 이벤트데이터를 균등히 보내고 싶다면 로드벨런싱 설정을 넣어준다.
#loadbalance: true
#전역옵션
#파일 정보를 유지하는 데 사용하는 레지스트리 파일 위치를 지정한다.
#마지막으로 읽은 오프셋과 읽은 행이 설정 시 지정한 출력 지점의 응답 여부 등
#filebeat.registry_file: /Users/yun-yeoseong/elasticsearch-file/filebeat/registry
#파일비트 종료 시 데이터 송신이 끝마칠 때까지 대기하는 시간
#파일비트는 기본적으로 종료시 이벤트 송신 처리를 기다리지 않고 종료하기 때문에
#이벤트 송신이 잘되었는지 수신을 종료전에 기다리도록 시간설정을 할 수 있다.
filebeat.shutdown_timeout: 10s
#일반옵션
#네트워크 데이터를 발송하는 수집기의 이름 기본적으로 필드에는 호스트 이름을 지정한다.
name: "app_log_harvester"
#동시에 실행할 수 있는 최대 CPU 개수를 설정. 기본값은 시스템에서 사용 가능한 논리적인 CPU 개수
#max_procs: 2
|
cs |
./filebeat --c ./filebeat_exam.yml -> 해당 명령어로 실행시켜준다.
데이터는 spring boot 프로젝트를 실행시켰을 때, 올라가는 로그를 수집한 결과이다. kibana Discovery tab을 이용하여 데이터가 어떻게 들어왔는지 결과를 확인할 것이다.
Result

일부 예제에 들어간 설정과 다른 데이터가 들어간 것도 있다. 데이터는 고려하지 말고 어떤 필드들이 생겼고 어떤 데이터가 설정과 비교하여 들어왔는지 확인하자. 일반적으로 파일비트는 인덱스를 버전정보+날짜정보를 이용하여 일자별로 인덱스 생성을 진행한다.(매일 생긴다는 것은? 그만큼 인덱스가 많아진다는 것이기 때문에 백업 스케쥴을 잘 잡아줘야한다.)그리고 @timestamp를 찍어 데이터 색인 시간을 볼 수 있고, 모든 데이터는 message 필드에 저장된다. 또한 설정 부분에 tags, fields.env 설정이 들어간 것이 있을 것이다. 만약 성격이 다른 애플리케이션이 있고 각각 따로 통계를 내고 싶다면 해당 필드들을 이용하여 필터를 걸수도 있고 또한 Logstash를 이용하여 데이터 처리를 할때 해당 필드들을 이용하여 필터를 걸어 사용할 수도 있을 것이다.(Input의 파일 경로(- input_type)를 여러개 지정할 수 있으므로 각 패스마다 해당 필드의 값을 다르게 준다)
여기까지 간단히 파일비트가 뭔지 알아봤고 사용법도 알아보았다. 사실 운영환경에서는 이렇게 간단히 사용할 수 없는 환경이 대부분일 것이다. 레퍼런스를 활용하여 더 깊게 공부할 필요성이 있다.
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - Rest High Level Client를 이용한 Index Template 생성 (0) | 2019.06.27 |
|---|---|
| ELK Stack - Logstash(로그스태시)를 이용한 로그 수집 (1) | 2019.06.26 |
| Elasticsearch - 엘라스틱서치 노드의 종류 그리고 클러스터링 (4) | 2019.06.08 |
| Elasticsearch - 엘라스틱서치 자바 힙 메모리 변경(JVM Heap) (0) | 2019.06.08 |
| Elasticsearch - 엘라스틱서치와 루씬의 관계 - 2(세그먼트 불변성,Translog) (1) | 2019.05.25 |