2022. 1. 20. 10:49ㆍ머신러닝

해당 포스팅은 위 이미지의 책의 챕터3을 읽은 리뷰입니다. :)
자연어 처리 개요
단어 표현
텍스트를 자연어 처리를 위한 모델에 적용할 수 있게 언어적인 특성을 반영해서 단어를 수치화하는 방법을 찾는 것이다. 보통 단어를 수치화할 때는 주로 벡터로 표현한다. 따라서 단어 표현은 "단어 임베딩(word embedding)" 또는 "단어 벡터(word vector)"로 표현한다.
단어 임베딩 기법
- 원-핫 인코딩(one-hot encoding) : 단어를 하나의 벡터로 표현하며 각 단어는 벡터 값 가운데 하나만 1이라는 값을 가지고 나머지는 모두 0값을 가짐.
- 분포 가설(Distributed hypothesis)
- 카운트 기반 방법 : 어떤 글의 문맥 안에 단어가 동시에 등장하는 횟수를 세는 방법(동시 등장 횟수를 하나의 행렬로 나타낸 뒤 그 행렬을 수치화해서 단어 벡터를 만듬)
- 예측 방법
- Word2vec
- CBOW(Continuous Bag of Words) : 어떤 단어를 문백 안의 주변 단어들을 통해 예측하는 방법(창욱은 냉장고에서 _____ 꺼내서 먹었다.)
- Skip-Gram : 어떤 단어를 가지고 특정 문맥 안의 주변 단어들을 예측하는 방법(____ ________ 음식을 _____ _____)
- NNLM(Neural Network Language Model)
- RNNLM(Recurrent Neural Network Language Model)
- Word2vec
- 카운트 기반 방법과 예측 방법 모두를 차용해서 쓰는 단어 임베딩 기법
- Glove
텍스트 분류
텍스트 분류는 자연어 처리 문제 중 가장 대표적이고 많이 접하는 문제다. 자연어 처리 기술을 활용해 특정 텍스트를 사람들이 정한 몇 가지 범주(class) 중 어느 범주에 속하는지 분류하는 문제다.
분류해야 할 범주의 수에 따라 문제를 구분
- 이진 분류(binary classification) : 2가지 범주에 대해 구분하는 문제
- 다중 범주 분류(Multi classfication) : 3가지 이상의 범주에 대해 구분하는 문제
지도 학습을 통한 텍스트 분류
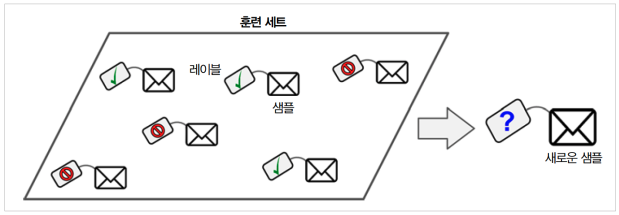
위 그림과 같이 지도 학습은 샘플(데이터)에 대해 각각 속한 범주에 대한 값(레이블)이 이미 주어져 있다. 따라서 주어진 범주로 글들을 모두 학습한 후 학습한 결과를 이용해 새로운 글의 범주를 예측하는 방법이다.
- KNN
- 나이브 베이즈 분류
- 서포트 벡터 머신
- 신경망
- 선형 분류
- 로지스틱 분류
- 랜덤 포레스트
비지도 학습을 통한 텍스트 분류
비지도 학습에서는 데이터만 존재하고, 각 데이터는 범주로 미리 나눠져 있지 않다. 따라서 특성을 찾아내서 적당한 범주를 만들어 각 데이터를 나눈다.
비지도 학습을 통한 분류는 어떤 특정한 분류가 있는 것이 아니라 데이터의 특성에 따라 비슷한 데이터끼리 묶어주는 개념이다.
- K-means Clustering
- Hierarchical Clustering

텍스트 유사도
텍스트 유사도란 말 그대로 텍스트가 얼마나 유사한지를 표현하는 방식 중 하나다. 유사도를 판단하는 척도는 매우 주관적이기 때문에 데이터를 구성하기가 쉽지 않고 정량화하는 데 한계가 있다. 이를 최대한 정량화해서 모델을 만드는 것이 중요하다.
일반적으로 유사도를 측정하기 위해 정량화하는 방법에는 여러 가지가 있다. 단순히 같은 단어의 개수를 사용해서 유사도를 판단하는 방법, 형태소로 나누어 형태소를 비교하는 방법, 자소 단위로 나누어 단어를 비교하는 방법 등 다양하다.
또한 딥러닝을 기반으로 텍스트의 유사도를 측정하는 방식도 있다. 단어, 형태소, 유사도의 종류에 상관 없이 텍스트를 벡터화한 후 벡터화된 각 문장 간의 유사도를 측정하는 방식이다.
자카드 유사도
두 집합(각 문자을 형태소 분리한 형태소의 집합)의 교집합인 공통된 단어의 개수를 두 집합의 합집합, 즉 전체 단어의 수로 나눈다.
유클리디언 유사도
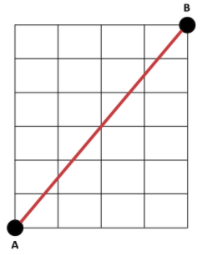
n차원 공간에서 두 점 사이의 최단 거리를 구하는 접근법이다.
맨하탄 유사도

유클리디언 유사도처럼 출발점과 도착점까지를 가로지르지 않고 갈수 있는 최단 거리를 구하는 공식이다.
코사인 유사도
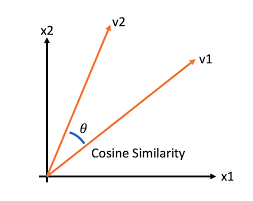
코사인 유사도는 두 개의 벡터값에서 코사인 각도를 구하는 방법이다. 코사인 유사도 값은 -1과 1 사이의 값을 가지고 1에 가까울수록 유사하다는 것을 의미한다. 다른 유사도 접근법에 비해 일반적으로 성능이 좋은데,
이는 단순히 좌표상의 거리를 구하는 다른 유사도 측정 방법에 비해 코사인 유사도는 말 그대로 두 벡터 간의 각도를 구하는 것이라서 방향성의 개념이 더해지기 때문이다.
'머신러닝' 카테고리의 다른 글
| Transformer - 어텐션 원리 설명 (0) | 2023.08.30 |
|---|---|
| 딥러닝 - BERT(Bidirectional Encoder Representations from Transformers) (0) | 2022.02.17 |
| 딥러닝 - 트랜스포머(Transformer) (0) | 2022.02.15 |
| 딥러닝 - 어텐션 메커니즘(Attention Mechanism) (0) | 2022.02.15 |