
'2019/09/16'에 해당되는 글 4건
- 2019.09.16 :: DB - MongoDB Text Search(본문 검색)
- 2019.09.16 :: DB - MongoDB와 자주 사용되는 SQL 비교
- 2019.09.16 :: DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 3
- 2019.09.16 :: DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 2

MongoDB는 문자열 내용의 텍스트 검색을 수행하는 쿼리를 지원한다. 텍스트 검색을 수행하기 위해 몽고디비는 텍스트 인덱스와 $text 연산자를 사용한다.(View는 텍스트 검색을 지원하지 않는다.)
예제 진행을 위해 아래 문서들을 삽입한다.
|
1
2
3
4
5
6
7
8
9
|
db.stores.insert(
[
{ _id: 1, name: "Java Hut", description: "Coffee and cakes" },
{ _id: 2, name: "Burger Buns", description: "Gourmet hamburgers" },
{ _id: 3, name: "Coffee Shop", description: "Just coffee" },
{ _id: 4, name: "Clothes Clothes Clothes", description: "Discount clothing" },
{ _id: 5, name: "Java Shopping", description: "Indonesian goods" }
]
)
|
cs |
Text Index
몽고디비는 문자열 컨텐츠에 대한 텍스트 검색 쿼리를 지원하기 위해 텍스트 인덱스을 제공한다. text 인덱스은 값이 문자열 또는 문자열 요소 배열인 필드를 포함할 수 있다.
텍스트 검색 쿼리를 수행하려면 컬렉션에 text 인덱스가 있어야한다. 컬렉션은 하나의 텍스트 검색 인덱스만 가질 수 있지만 해당 인덱스는 여러 필드를 포함할 수 있다.
> db.stores.createIndex({name:"text",description:"text"})
위 명령은 name 필드와 description 필드를 text 타입으로 인덱스를 생성한다. 위는 두 개의 텍스트 인덱스 필드를 지정하였다.
$text Operation
$text 쿼리 연산자를 이용하여 텍스트 인덱스가 있는 컬렉션에서 텍스트 검색을 할 수 있다.
$text는 공백과 대부분의 구두점을 구분 기호로 사용하여 검색 문자열을 토큰화하고 모든 토큰에 대해 OR 논리조건으로 쿼리를 수행한다.
> db.stores.find( { $text: { $search: "java coffee shop" } } )
위 텍스트 검색의 결과이다.

검색 조건의 "java coffee shop"이 java / coffee / shop 으로 토크나이징되고 각각의 토큰이 하나라도 포함되어 있다면 해당 문서를 결과값에 포함시킨다.
Exact Phrase
문자열 검색에 사용된 조건에 해당하는 문자열을 정확하게 일치하는 문서를 검색할 수도 있다.
> db.stores.find( { $text: { $search: "\"coffee shop\"" } } )
큰 따옴표로 검색 조건의 문자열을 묶으면 대소구분없이 "coffee shop"과 정확히 일치하는 문서만 결과값에 포함시킨다.
Term Exclustion
"-"연산자를 사용하여 검색에 제외할 텀을 지정할 수 있다. 밑의 명령은 java 또는 shop을 포함하고 coffee는 포함하지 않는 텍스트를 검색한다.
> db.stores.find( { $text: { $search: "java shop -coffee" } } )
Sort
몽고디비는 기본적으로 정렬되지 않은 검색 결과를 반환한다. 그러나 텍스트 검색 쿼리는 문서가 쿼리와 얼마나 잘 일치 하는지를 지정하는 각 문서에 대한 스코어를 계산하기 때문에 스코어링 기준으로 정렬이 가능하다.
> db.stores.find(
... { $text: { $search: "java coffee shop" } },
... { score: { $meta: "textScore" } }
... ).sort( { score: { $meta: "textScore" } } )
위 쿼리의 결과값이다. 결과값에 스코어값이 포함된 것을 볼 수 있다.

간단하게 몽고디비의 텍스트 검색에 대해 다루어봤습니다. 추후에 집계 부분에서도 또 다루어보겠지만, 텍스트 검색에 대해 다루어보지 않은 부분이 몇개 있으므로 나중에 다시 다루어 보겠습니다.
'Database > MongoDB' 카테고리의 다른 글
| DB - MongoDB OperationFailed Sort operation used more than the maximum 33554432 bytes of Ram. (0) | 2019.09.19 |
|---|---|
| DB - MongoDB Insert Ordered 옵션은? (0) | 2019.09.19 |
| DB - MongoDB와 자주 사용되는 SQL 비교 (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 3 (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 2 (0) | 2019.09.16 |

이번 포스팅 내용은 자주 사용되는 SQL문과 MongoDB와의 쿼리를 비교하는 포스팅입니다.
| SQL Schema Statements | MongoDB Schema Statements |
|
CREATE TABLE people( id MEDIUMINT NOT NULL AUTO_INCREMENT, user_id varchar(30), age number, status char(1), PRIMARY KEY(id) ) |
db.people.insertOne({ user_id:"abc123", age:55, status:"A" }) 암시적으로 삽입 작업에서 _id를 생략했다면 내부적으로 _id에 값을 추가한다. 컬렉션 또한 삽입시점에 생성된다.
그러나 컬렉션을 명시적으로 생성가능하다.
db.createCollection("people")
|
| ALTER TABLE people ADD join_date DATETIME |
컬렉션은 문서 구조를 설명하거나 강제하지 않는다. 그러나, 문서 레벨에서 updateMany() 오퍼레이션은 $set 오퍼레이션을 사용하여 존재하는 문서에 새로운 필드를 추가할 수 있다.
db.people.updateMany({},{$set:{join_date:new Date()}}) |
| ALTER TABLE people DROP COLUMN join_date |
컬렉션은 문서 구조를 설명하거나 강제하지 않는다.
그러나, 문서 레벨에서 updateMany() 오퍼레이션은 $unset 오퍼레이션을 사용하여 이미 존재하는 문서의 필드를 제거할 수 있다.
db.people.updateMany({},{$unset:{"join_date":""}}) |
| CREATE INDEX idx_user_id_asc ON people(user_id) | db.people.createIndex({user_id:1}) |
| CREATE INDEX idx_user_id_asc_age_desc ON people(user_id,age DESC) | db.people.createIndex({user_id:1,age:-1}) |
| DROP TABLE people | db.people.drop() |
위는 테이블 수준에서 자주 사용되는 SQL과 비교한 몽고디비 명령이다.
Insert
| SQL Insert Statements | MongoDB insertOne() Statements |
| INSERT INTO people(user_id,age,status) VALUES ("bcd001",45,"A") | db.people.insertOne({user_id:"bcd001",age:45,status:"A"}) |
Select
암묵적으로 몽고디비는 _id 필드를 결과에 포함시킨다. 만약 _id 필드를 결과에서 제외시키고 싶다면 명시적으로 옵션을 지정해야한다.
| SQL Select Statements | MongoDB find() Statements |
| SELECT * FROM PEOPLE | db.people.find() |
| SELECT id,user_id,status FROM people | db.people.find({},{user_id:1,status:1}) |
| SELECT * FROM people WHERE status = "A" | db.people.find({status:"A"}) |
| SELECT user_id,status FROM people WHERE status = "A" | db.people.find({status:"A"},{user_id:1,status:1,_id:0}) |
| SELECT * FROM people WHERE status != "A" | db.people.find({status:{$ne:"A"}}) |
| SELECT * FROM people WHERE status = "A" AND age = 50 | db.people.find({status:"A",age:50}) |
| SELECT * FROM people WHERE status = "A" OR age = 50 | db.people.find({$or:[{status:"A"},{age:50}]}) |
| SELECT * FROM people WHERE age > 25 AND age <=50 | db.people.find({age:{$gt:25,$lte:50}}) |
| SELECT * FROM people WHERE user_id LIKE "%bc%" |
db.people.find({user_id:/bc/}) or db.people.find({user_id:{$regex:/bc/}}) |
| SELECT * FROM people WHERE user_id LIKE "bc%" |
db.people.find({user_id:/^bc/}) or db.people.find({user_id:{$regex:/^bc/}}) |
| SELECT * FROM people WHERE status = "A" ORDER BY user_id ACS | db.people.find({status:"A"}).sort({user_id:1}) |
| SELECT * FROM people WHERE status="A" ORDER BY user_id DESC | db.people.find({status:"A"}).sort({user_id:-1}) |
| SELECT COUNT(*) FROM people |
db.people.count() or db.people.find().count() |
| SELECT COUNT(user_id) FROM people |
db.people.count({user_id:{$exist:true}}) or db.people.find({user_id:{$exist:true}}).count() |
| SELECT COUNT(*) FROM people WHERE age > 30 |
db.people.count({age:{$gt:30}}) or db.people.find({age:{$gt:30}}).count() |
| SELECT DISTINCT(status) FROM people |
db.people.aggregate([{$group:{_id:"$status"}}]) or db.people.distinct("status") |
| SELECT * FROM people LIMIT 1 |
db.people.findOne() or db.people.find().limit(1) |
| SELECT * FROM people LIMIT 5 SKIP 10 | db.people.find().limit(5).skip(10) |
Update Records
| SQL Update Statements | MongoDB updateMany() Statements |
| UPDATE people SET status = "C" WHERE age > 25 | db.people.updateMany({age:{$gt:25}},{$set:{status:"C"}}) |
| UPDATE people SET age = age +3 WHERE status = "A" | db.people.updateMany({status:"A"},{$inc:{age:3}}) |
Delete Records
| SQL Delete Statements | MongoDB deleteMany() Statements |
| DELETE FROM people WHERE status = "D" | db.people.deleteMany({status:"D"}) |
| DELETE FROM people | db.people.deleteMany({}) |
여기까지 자주 사용되는 SQL에 대한 MongoDB 쿼리 비교였습니다. 이보다 더 많은 기능들이 있지만 추후 천천히 다루어보겠습니다.
'Database > MongoDB' 카테고리의 다른 글
| DB - MongoDB Insert Ordered 옵션은? (0) | 2019.09.19 |
|---|---|
| DB - MongoDB Text Search(본문 검색) (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 3 (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 2 (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 1 (0) | 2019.09.13 |

이번 포스팅은 몽고디비 CRUD 3번째 글입니다. 이번 내용은 문서 update부터 다루어볼 예정입니다. 혹시나 이전 포스팅을 못 보신분들은 간단히 아래 링크에서 참고 부탁드립니다.
DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 1
이번 포스팅은 간단하게 MongoDB 사용법에 대해 다루어봅니다. 모든 쿼리는 특정 클라이언트 드라이버를 이용하는 것이 아니라, Shell을 이용하여 직접 쿼리를 작성해보는 내용입니다. 실습 이전에 혹시나 몽고디..
coding-start.tistory.com
DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 2
몽고디비 CRUD 사용방법을 다루는 포스팅 2번째 글입니다. 만약 첫번째 글을 못보신 분은 아래 링크를 참조하시길 바랍니다. DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 1 이번 포스팅은 간단하게 MongoDB..
coding-start.tistory.com
Update Documents
예제에 앞서 아래 문서들을 삽입해줍니다. 아래 문서들을 이용해서 예제를 진행할 것입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
db.inventory.insertMany( [
{ item: "canvas", qty: 100, size: { h: 28, w: 35.5, uom: "cm" }, status: "A" },
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "mat", qty: 85, size: { h: 27.9, w: 35.5, uom: "cm" }, status: "A" },
{ item: "mousepad", qty: 25, size: { h: 19, w: 22.85, uom: "cm" }, status: "P" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "P" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" },
{ item: "sketchbook", qty: 80, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "sketch pad", qty: 95, size: { h: 22.85, w: 30.5, uom: "cm" }, status: "A" }
] );
|
cs |
-Update Documents in a Collection
몽고디비에선 문서 업데이트를 위해 $set와 같은 업데이트 연산자를 제공하여 필드값을 수정한다. $set과 같은 몇몇 수정 연산자는 필드가 존재하지 않을 경우 필드를 생성해준다.
-Update a Single Document
db.collection.updateOne() 명령어를 이용해서 단일 문서 수정을 수행한다.
> db.inventory.updateOne({item:"paper"},{$set:{"size.uom":"cm",status:"P"},$currentDate:{lastModified:true}})
위 쿼리는 item이 paper인 첫번째 문서의 임베디드 문서 필드인 size 필드의 uom값을 cm으로 status필드의 값을 P로 바꾸어준다. 그리고 $currentDate 연산자를 사용하여 lastModified 필드의 값을 현재 날짜로 업데이트한다. 만약 lastModified 필드가 없으면 $currentDate가 필드를 만들어 값을 넣어준다.
-Update Multiple Documents
db.collection.updateMany() 명령어를 이용해서 다수의 문서를 한번에 수정한다.
> db.inventory.updateMany({qty:{$lt:50}},{$set:{"size.uom":"in",status:"P"},$currentDate:{lastModified:true}})
위 쿼리는 qty 필드의 값이 50보다 작은 모든 문서에 대해 $set 연산자에 대한 필드를 수정하고, lastModified 필드에 변경 날짜와 시간을 넣어준다.
-Replace a Document
_id 필드를 제외한 문서의 전체 내용을 바꾸려면 완전히 새로운 문서를 두 번째 인수로 db.collection.replaceOne()에 전달한다.
문서를 교체 할 때 교체 문서는 필드 / 값 쌍으로 만 구성되어야한다. 즉, 업데이트 연산자 표현식을 포함하면 안된다.
대체 문서는 원본 문서와 다른 필드를 가질 수 있다. 대체 문서에서 _id 필드는 변경할 수 없으므로 _id 필드를 생략 할 수 있다. 그러나 _id 필드를 포함 시키면 현재 값과 동일한 값을 가져야한다.
> db.inventory.replaceOne({item:"paper"},{ item:"paper", instock:[{warehouse:"A",qty:60},{warehouse: "B", qty: 40}]})
위 쿼리는 item이 paper인 첫번째 문서를 두번째 인자인 문서로 교체해준다. _id 필드를 생략하였으므로 기존과 동일한 _id필드를 가지며, 혹시나 _id 필드를 넣더라도 대체하길 원하는 문서의 _id값과 동일하게 넣어줘야한다.
여기까지 간단히 수정 쿼리을 다루어봤는데, 조금더 자세히 수정쿼리에 대해 다루어보자.
| Method | 설명 |
| db.collection.updateOne() |
여러 문서가 지정된 필터와 일치하더라도 지정된 필터와 일치하는 최대 하나의 문서를 업데이트한다. 버전 3.2의 새로운 기능. |
| db.collection.updateMany() | 지정된 필터와 일치하는 모든 문서를 업데이트한다. |
| db.collection.replaceOne() |
여러 문서가 지정된 필터와 일치하더라도 지정된 필터와 일치하는 최대 하나의 문서를 대체한다.
버전 3.2의 새로운 기능 |
| db.collection.update() |
지정된 필터와 일치하는 단일 문서를 업데이트하거나 지정된 필터와 일치하는 모든 문서를 업데이트한다. 기본적으로 해당 Method는 단일 문서를 업데이트한다. 여러 문서를 업데이트하려면 multi 옵션을 사용한다. |
-추가적인 업데이트 Method
| Method |
| db.collection.findOneAndReplace() |
| db.collection.findOneAndUpdate() |
| db.collection.findAndModify() |
| db.collection.save() |
| db.collection.bulkWrite() |
Delete Documents
문서 삭제에 대한 예제를 다루어봅니다.
-Delete All Documents
특정 컬렉션의 모든 문서를 삭제하기 위해서는 필터 값에 아무런 값을 넣지 않고 db.collection.deleteMany() 메서드를 작성하면 된다.
> db.inventory.deleteMany({})
해당 컬렉션에 모든 문서를 삭제하고 삭제대상이 된 문서의 갯수를 결과로 반환한다.
-Delete All Documents that Match a Condition
삭제할 문서를 식별하는 기준 또는 필터를 지정할 수 있다. 필터는 조회 쿼리와 동일한 구문을 사용한다.
> db.inventory.deleteMany({status:"A"})
위 쿼리는 status 값이 A인 모든 문서를 삭제한다.
-Delete Only One Document that Matches a Condition
지정된 필터와 일치하는 문서를 하나만 삭제할때 db.collection.deleteOne()을 사용한다.
> db.inventory.deleteOne({status:"D"})
Delete Behavior
-Indexes
컬렉션에서 모든 문서를 삭제하더라도 인덱스는 삭제하지 않는다. (이것은 인덱스의 내부 구조에 대한 내용까지 들어갈 듯한데, 보통 B+Tree에서 인덱스 삭제 연산이 있더라도 삭제 플래그값만 남기고 값은 바로 삭제하지 않았던 걸로 기억. 정확히 아시는 분은 댓글로 좀 부탁드립니다...)
삭제 연산에 사용되는 Method들은 아래와 같다.
| Method | 설명 |
| db.collection.deleteOne() |
여러 문서가 지정된 필터와 일치하더라도 지정된 필터와 일치하는 문서를 하나만 삭제한다. 버전 3.2의 새로운 기능. |
| db.collection.deleteMany() |
지정된 필터와 일치하는 모든 문서를 삭제한다. 버전 3.2의 새로운 기능. |
| db.collection.remove() | 지정된 필터와 일치하는 단일 문서 또는 모든 문서를 삭제한다. |
-추가적인 문서삭제 Method
| Method | 설명 |
| db.collection.findOneAndDelete() | 해당 메서드는 정렬 옵션을 제공한다. 이 옵션을 사용하면 지정된 순서대로 정렬된 첫번째 문서를 삭제한다. |
| db.collection.findAndModify() | 해당 메서드는 정렬 옵션을 제공한다. 이 옵션을 사용하면 지정된 순서대로 정렬된 첫번째 문서를 삭제할 수 있다. |
| db.collection.bulkWrite() |
Bulk Write Operations
몽고디비는 클라이언트에게 벌크작업을 수행할 수 있는 기능을 제공한다. 벌크작업은 단일 컬렉션에 대해서만 수행가능하다. 몽고디비는 애플리케이션이 벌크작업에 필요한 수용 가능한 Acknowledgement 수준을 결정할 수 있도록한다.
db.collection.bulkWrite() 메소드는 대량 삽입, 업데이트 및 제거 작업을 수행하는 기능을 제공한다. MongoDB는 db.collection.insertMany()를 통한 대량 삽입도 지원한다.
-Ordered vs Unordered Operations
벌크작업은 작업에 순서가 있거나 순서가 맞지 않을 수 있다.
순서가 지정된 작업 목록을 사용하여 MongoDB는 작업을 순차적으로 실행한다. 쓰기 작업 중 하나를 처리하는 동안 오류가 발생하면 MongoDB는 목록에 남아있는 쓰기 작업을 처리하지 않고 반환한다.
정렬되지 않은 작업 목록을 사용하면 MongoDB가 작업을 병렬로 실행할 수 있지만이 동작은 보장되지 않는다. 쓰기 작업 중 하나를 처리하는 동안 오류가 발생하면 MongoDB는 목록에 남아있는 쓰기 작업을 계속 처리한다.
분할 된 컬렉션에서 정렬 된 작업 목록을 실행하면 정렬 된 목록을 사용하여 정렬되지 않은 목록을 실행하는 것보다 일반적으로 속도가 느려진다. 각 작업은 이전 작업이 완료 될 때까지 기다려야한다.
기본적으로 bulkWrite ()는 순서가 지정된 작업을 수행한다. 순서가없는 쓰기 작업을 지정하려면 옵션 문서에서 ordered : false를 설정하면 된다.
즉, 벌크 연산은 아래와 같은 오퍼레이션과 동일한 역할을 수행할 수 있다.
| insertOne |
| insertMany |
| updateOne |
| updateMany |
| replaceOne |
| deleteOne |
| deleteMany |
|
1
2
3
|
{ "_id" : 1, "char" : "Brisbane", "class" : "monk", "lvl" : 4 },
{ "_id" : 2, "char" : "Eldon", "class" : "alchemist", "lvl" : 3 },
{ "_id" : 3, "char" : "Meldane", "class" : "ranger", "lvl" : 3 }
|
cs |
characters 컬렉션에는 위와 같은 문서가 있다고 가정한다. 이 컬렉션에 아래와 같이 벌크 연산을 수행할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
try {
db.characters.bulkWrite(
[
{ insertOne :
{
"document" :
{
"_id" : 4, "char" : "Dithras", "class" : "barbarian", "lvl" : 4
}
}
},
{ insertOne :
{
"document" :
{
"_id" : 5, "char" : "Taeln", "class" : "fighter", "lvl" : 3
}
}
},
{ updateOne :
{
"filter" : { "char" : "Eldon" },
"update" : { $set : { "status" : "Critical Injury" } }
}
},
{ deleteOne :
{ "filter" : { "char" : "Brisbane"} }
},
{ replaceOne :
{
"filter" : { "char" : "Meldane" },
"replacement" : { "char" : "Tanys", "class" : "oracle", "lvl" : 4 }
}
}
]
);
}
catch (e) {
print(e);
}
|
cs |
벌크 연산의 결과는 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
{
"acknowledged" : true,
"deletedCount" : 1,
"insertedCount" : 2,
"matchedCount" : 2,
"upsertedCount" : 0,
"insertedIds" : {
"0" : 4,
"1" : 5
},
"upsertedIds" : {
}
}
|
cs |
샤드 컬렉션에 벌크 연산 전략
초기 데이터 삽입 또는 일상적인 데이터 가져오기를 포함한 벌크삽입 연산 작업은 샤드 클러스터 성능에 영향을 줄 수 있다. 벌크삽입의 경우 다음 전략들을 고려할 수 있다.
-컬렉션 사전 분할
샤딩된 컬렉션이 비어 있다면, 컬렉션은 하나의 초기화된 청크만 갖고 있는다. 그런 다음 몽고디비는 데이터를 수신한 이후에 분할을 생성하고 분할 청크를 사용 가능한 샤드에 분배한다. 즉, 리소스가 어느정도 큰 작업이 될것이다. 이 성능 비용을 줄이기위해 벌크작업 이전에 컬렉션을 사전 분할 할 수 있다.
Split Chunks in a Sharded Cluster — MongoDB Manual
Split Chunks in a Sharded Cluster Normally, MongoDB splits a chunk after an insert if the chunk exceeds the maximum chunk size. However, you may want to split chunks manually if: you have a large amount of data in your cluster and very few chunks, as is th
docs.mongodb.com
-순서없는 벌크 연산
샤드 클러스터에 대한 쓰기 성능을 향상시키려면 벌크연산의 선택적인 매개변수인 orderded를 false로 설정하면 된다. 이 설정은 순서없이 작업을 수행하는데, 병렬로 수행하기 때문에 여러 샤드에 동시에 작업수행이 가능하다. 하지만 이 작업을 하기 전에는 컬렉션이 미리 분할되어 있어야한다.
여기까지 수정,삭제,벌크 연산에 대해 다루어봤습니다. 이후 포스팅에서 더 다양한 연산들을 다루어보겠습니다.
'Database > MongoDB' 카테고리의 다른 글
| DB - MongoDB Text Search(본문 검색) (0) | 2019.09.16 |
|---|---|
| DB - MongoDB와 자주 사용되는 SQL 비교 (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 2 (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 1 (0) | 2019.09.13 |
| DB - MongoDB 조건으로 일부 문자열만 사용하여 인덱스이용하기 (0) | 2019.09.13 |

몽고디비 CRUD 사용방법을 다루는 포스팅 2번째 글입니다. 만약 첫번째 글을 못보신 분은 아래 링크를 참조하시길 바랍니다.
DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 1
이번 포스팅은 간단하게 MongoDB 사용법에 대해 다루어봅니다. 모든 쿼리는 특정 클라이언트 드라이버를 이용하는 것이 아니라, Shell을 이용하여 직접 쿼리를 작성해보는 내용입니다. 실습 이전에 혹시나 몽고디..
coding-start.tistory.com
예제를 위해서 아래 문서들을 삽입합니다.
|
1
2
3
4
5
6
7
|
db.inventory.insertMany( [
{ item: "journal", instock: [ { warehouse: "A", qty: 5 }, { warehouse: "C", qty: 15 } ] },
{ item: "notebook", instock: [ { warehouse: "C", qty: 5 } ] },
{ item: "paper", instock: [ { warehouse: "A", qty: 60 }, { warehouse: "B", qty: 15 } ] },
{ item: "planner", instock: [ { warehouse: "A", qty: 40 }, { warehouse: "B", qty: 5 } ] },
{ item: "postcard", instock: [ { warehouse: "B", qty: 15 }, { warehouse: "C", qty: 35 } ] }
]);
|
cs |
Query for a Document Nested in an Array
> db.inventory.find({instock:{warehouse:"A",qty:5}})
위 쿼리는 instock라는 중첩 필드에 조건에 일치하는 배열 요소가 있다면 쿼리 결과에 포함시킨다. 이전 포스팅에서도 간단하게 얘기했듯이 중첩 필드가 특정 문서이고 문서 전체의 일치를 조건에 넣으면 필드의 순서가 결과에 영향을 미친다. 위 쿼리에서 필드의 순서를 바꾸면 결과값은 나오지 않는다.
> db.inventory.find({instock:{qty:5,warehouse:"A"}})
Specify a Query Condition on a Field Embedded in an Array of Document
중첩된 필드가 배열이며 배열의 요소가 특정 문서일 경우 "배열이름.배열요소의필드"로 조회조건을 걸수 있다.
> db.inventory.find({"instock.qty":{$lte: 20}})
위 쿼리는 instock 필드 안에 들어있는 배열 요소(문서) qty 필드 값중 20보다 작거나 같은 문서가 하나라도 포함되어 있다면 결과값에 포함시킨다.
Use the Array Index to Query for a Field in the Embedded Document
배열 요소 인덱스에 접근하여 쿼리 조건을 작성할 수 있다.
> db.inventory.find({"instock.0.qty":{$lte:20}})
위 쿼리는 instock 필드 배열의 첫번째 요소의 qty 필드 값이 20보다 작거나 같은 요소가 포함되어 있다면 결과에 포함시킨다.
두 개 이상의 조건을 모두 만족하는 배열의 요소를 조건으로 쿼리 작성이 가능하다.
> db.inventory.find({instock:{$elemMatch:{qty:5,warehouse:"A"}}})
위 쿼리는 instock 배열의 요소중 qty가 5이고 그리고 warehouse가 A 요소인 두 개의 조건을 모두 만족하는 배열요소가 있다면 결과에 포함시킨다.
> db.inventory.find({instock:{$elemMatch:{qty:{$gt:10,$lte:20}}}})
위 쿼리는 instock 배열의 요소의 필드인 qty의 값이 10보다 크거나 20보다 작거나 같은 필드 값이 하나라도 존재한다면 결과값에 포함시킨다.(AND)
> db.inventory.find( { "instock.qty": { $gt: 10, $lte: 20 } } )
위 쿼리 같은 경우 바로 위에 쿼리랑은 다르게 10보다 크거나 20보다 작은 필드 조건을 하나씩이라도 만족하는 문서가 있다면 결과값에 포함시킨다.

결과값을 보면 4개의 문서 모두 10보다 큰 값을 가지고 있는 요소, 20보다 작거나 같은 값을 가진 요소를 하나씩 가지고 있다.
> db.inventory.find({"instock.qty":5,"instock.warehouse":"A"})

위 쿼리의 결과를 보면 qty가 5인 문서를 요소로 가지고 있고 warehouse가 A인 문서를 가지고 있는 배열요소를 포함하는 문서가 결과값으로 노출되고 있다. 사실 조금 헷갈릴 수 있다. 첫번째 결과를 보면 instock의 첫번째 요소에 warehouse == A, qty ==5라는 조건을 모두 가지고 있기에 결과에 포함됬고 두번째 결과는 각 조건이 서로다른 문서에 매칭이 되므로 결과값에 포함되었다.(첫번째 요소에 warehouse == A, 두번째 요소에 qty == 5)
Project Fields to Return from Query
쿼리의 결과로 문서의 모든 필드를 반환하는 것이 아니라 특정 필드만 결과값으로 내보낼 수 있다.
예제를 들어가기 앞서 아래의 문서를 삽입한다.
|
1
2
3
4
5
6
7
|
db.inventory.insertMany( [
{ item: "journal", status: "A", size: { h: 14, w: 21, uom: "cm" }, instock: [ { warehouse: "A", qty: 5 } ] },
{ item: "notebook", status: "A", size: { h: 8.5, w: 11, uom: "in" }, instock: [ { warehouse: "C", qty: 5 } ] },
{ item: "paper", status: "D", size: { h: 8.5, w: 11, uom: "in" }, instock: [ { warehouse: "A", qty: 60 } ] },
{ item: "planner", status: "D", size: { h: 22.85, w: 30, uom: "cm" }, instock: [ { warehouse: "A", qty: 40 } ] },
{ item: "postcard", status: "A", size: { h: 10, w: 15.25, uom: "cm" }, instock: [ { warehouse: "B", qty: 15 }, { warehouse: "C", qty: 35 } ] }
]);
|
cs |
우선 결과값으로 모든 필드를 노출시키려면 아래와 같은 쿼리를 작성한다.
> db.inventory.find({status:"A"})
SQL에서는 위 쿼리가 SELECT * FROM inventory WHERE status = "A"와 같다.
만약 지정된 필드와 _id 필드만 반환하고 싶다면 아래와 같이 쿼리를 작성하면 된다.
> db.inventory.find({status:"A"},{item:1,status:1})
숫자 1이 의미하는 바는 쿼리 결과에 해당 필드를 포함시키겠다라는 뜻이다. 그렇다면 아래와 같은 쿼리의 결과는 어떻게 될까?
> db.inventory.find({status:"A"},{item:1,status:1,_id:0})
_id 필드를 포함시키지 않는 결과값을 반환한다. 즉, SQL에서는 SELECT item, status FROM inventory WHERE status ="A"와 같다.
임베디드된 문서의 특정 필드만 결과값으로 노출시킬 수 있다. 아래 쿼리를 참고하자.
> db.inventory.find({status:"A"},{item:1,status:1,"size.uom":1})
해당 쿼리의 결과값은 아래와 같으며 size라는 임베디드 문서 필드중 uom만 결과값으로 노출시킨다.

> db.inventory.find(
... { status: "A" },
... { "size.uom": 0 }
... )
만약 위와 같은 쿼리를 작성했다면 size의 uom 필드를 제외한 모든 필드를 결과값으로 반환한다.

Query for Null or Missing Fields
몽고디비의 쿼리에서 다루는 null은 우리가 생각하는 것과 조금 다르게 동작한다. 아래 문서를 삽입한 후에 다음 쿼리를 보자.
|
1
2
3
4
|
db.inventory.insertMany([
{ _id: 1, item: null },
{ _id: 2 }
])
|
cs |
> db.inventory.find( { item: null } )
우리는 위 쿼리가 어떻게 동작될 것이라고 예상할까? 필자는 item필드를 포함하며 item 필드의 값이 null인 문서가 결과값으로 나올 것이라 생각했다. 하지만 결과는 아래와 같다.

값이 null이거나 해당 필드 자체가 없는 문서도 결과값에 포함되게 된다.
> db.inventory.find( { item : { $type: 10 } } )
위 쿼리는 item 필드의 $type이 10인 필드를 조회하는 것인데 $type 10은 item 필드를 가지고 있으면서 값이 null인 문서만 결과값에 포함시킨다.
> db.inventory.find( { item : { $exists: false } } )
위 쿼리는 $type이 10인 쿼리와는 반대로(?) item 필드자체가 없는 문서를 결과값에 포함시킨다.
Iterate a Cursor in the mongo Shell
몽고디비에선 특정 조회의 결과 값으로 Cursor를 리턴한다. 하지만 var 키워드로 한 변수로 커서를 할당하지 않으면 몽고 디비는 결과 개수만큼 반복문을 통한 결과값 출력을 하게 된다. 그렇다면 커서를 특정 변수에 할당해서 우리가 직접 출력시켜보자.

위의 이미지 같이 우리는 커서를 특정 변수로 할당 받아 직접 반복문을 작성해 결과를 출력할 수 있다. 그리고 while 대신 아래와 같은 코드 작성도 가능하다.
> myCursor.forEach(printjson);
그리고 Iterator 결과값을 일일이 반복문으로 출력하는 것이 아니라, 배열 요소로 컨버팅해서 특정 요소에만 접근 할수도 있다.
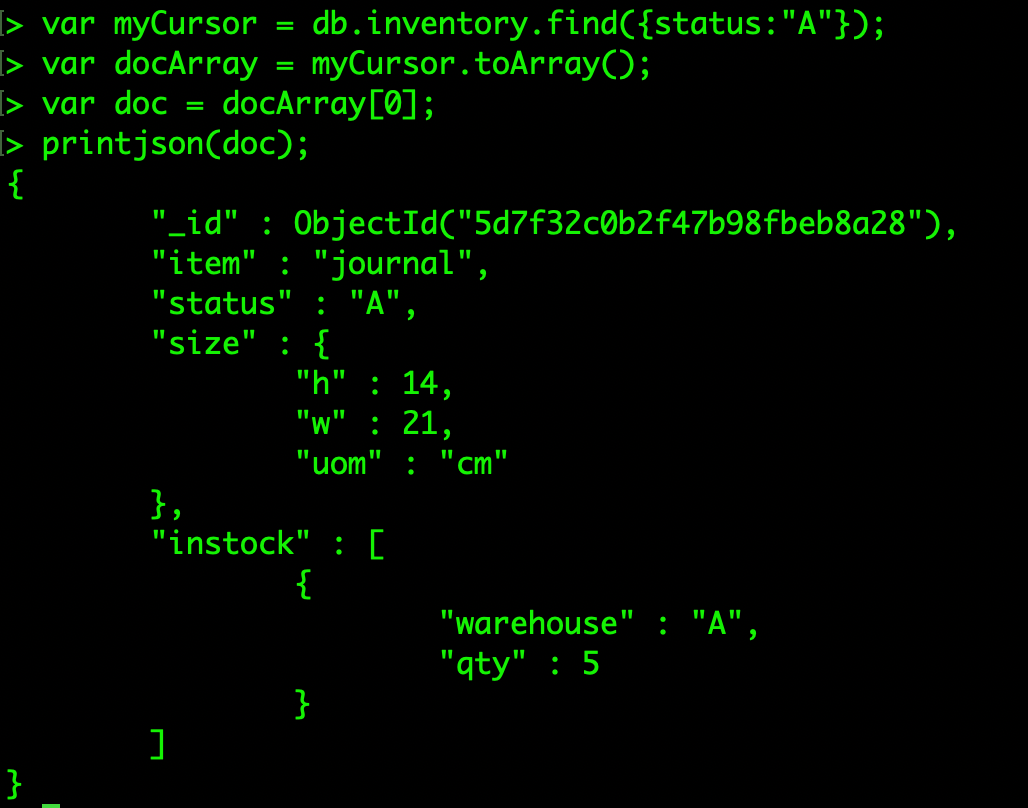
toArray() 메서드는 cursor가 참조하고 있는 모든 문서를 RAM에 로드시킨다. 또한 cursor를 소진시키기 때문에 더 이상 cursor는 사용할 수 없게 된다.

또한 위와 같이 일부 드라이버 장치는 직접 커서객체에 인덱스로 요소에 접근할 수 있게 한다. 하지만 위 같은 경우는 동일한 커서를 계속 사용할 수 있다.(myCursor[0]을 두번 호출해도 같은 결과값 반환. 즉 myCursor[0]으로 사용해도 커서는 소모되지 않는다.)
기본적으로, 서버는 10 분 동안 활동이 없거나 클라이언트가 커서를 모두 사용한 경우 커서를 자동으로 닫는다. mongo 셸에서이 동작을 재정의하려면 cursor.noCursorTimeout () 메서드를 사용하면 된다.
> var myCursor = db.inventory.find().noCursorTimeout();
noCursorTimeout 옵션을 설정 한 후 cursor.close ()를 사용하여 커서를 수동으로 닫거나 커서 결과를 소진해야한다.
기타 커서에 관한 많은 내용이 있지만 나머지는 추후에 다루어보도록 할 것이다. 여기까지 두번째 CRUD 포스팅을 마친다. 다음 포스팅은 Update Document부터 다룰 예정이다.
'Database > MongoDB' 카테고리의 다른 글
| DB - MongoDB와 자주 사용되는 SQL 비교 (0) | 2019.09.16 |
|---|---|
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 3 (0) | 2019.09.16 |
| DB - MongoDB CRUD 사용방법 및 기타 사용방법 - 1 (0) | 2019.09.13 |
| DB - MongoDB 조건으로 일부 문자열만 사용하여 인덱스이용하기 (0) | 2019.09.13 |
| DB - MongoDB 샤딩(Sharding,분산처리 등) (0) | 2019.09.12 |