
'도커'에 해당되는 글 11건
- 2020.07.19 :: Kubernetes - kubernetes(쿠버네티스) resources(cpu/momory) 할당 및 관리
- 2020.07.18 :: Docker - 도커 이미지 만들기 ! (Dockerfile)
- 2020.06.04 :: Docker - 도커를 이용해 Single node Kafka 띄우기
- 2020.04.21 :: Docker - DOOD로 띄웠을 경우 proxy(프록시) 설정
- 2020.04.16 :: Elasticsearch - Elasticsearch custom docker image 빌드(엘라스틱서치 커스텀 도커 이미지 생성)
- 2020.04.09 :: Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때
- 2019.11.26 :: Kubernetes - Kubernetes 아키텍쳐
- 2019.11.26 :: Kubernetes - Kubernetes 용어설명

오늘 간단히 다루어볼 내용은 쿠버네티스 리소스(cpu, memory) 할당과 관리에 대한 이야기이다.
리소스 관리
쿠버네티스에서 Pod를 어느 노드에 배포할지 결정하는 것을 스케쥴링이라고 한다. 팟에 대한 스케쥴링시, 노드에 애플리케이션이 동작할 수 있는 충분한자원(CPU, 메모리 등)이 확보되어야 배포가 가능하다. 이때문에 쿠버네티스 manifast 파일에 아주 중요한 설정이 있는데, 그것은 request, limit 에 대한 설정이다.
Request&Limit

컨테이너에 적용될 리소스의 양을 정의하는데, request와 limit이라는 설정을 사용한다. request는 컨테이너가 생성될때 최소한 있어야하는 자원 요청이고, limit은 request만큼 할당된 것보다 더 많은 리소스가 필요할때, 해당 컨테이너에게 최대로 줄 수 있는 자원의 양을 뜻한다. 간단히 예를 들어보면, request가 500이고, limit이 1000 이라면, 컨테이너는 처음 시작될때 500을 할당 받고 실행되며, 많은 트래픽이 몰려 리소스가 부족하다면 최대 500만큼의 자원을 더 받을 수 있다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-service
spec:
replicas: 4
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 2 //팟을 시작&종료할때 2개씩 작업한다.
maxUnavailable: 0 //롤링 업뎃시 모든 팟(4개)이 서비스 가능하도록.
만약 1이면, 리플리카 4개중 1개는 작업불능
template:
spec:
containers:
- name: web-service
resources:
requests:
cpu: 2000m
memory: 2Gi
limits:
cpu: 4000m
memory: 4Gi
Request&Limit을 지정해야하는 이유는? Overcommitted 상태
이 request와 limit의 개념이 있기 때문에 생기는 문제인데, request 된 양에 따라서 컨테이너를 만들었다고 하더라도, 컨테이너가 운영이되다가 자원이 모자르면 limit 에 정의된 양까지 계속해서 리소스를 요청하게 된다. 컨테이너의 총 Limit의 양이 실제 시스템이 가용한 resource의 양보다 많을 수 있는 경우가 발생한다. 이를 overcommitted 상태라고 한다. Overcommitted 상태가 발생하면, CPU의 경우에는 실제 사용량을 requested 에 정의된 상태까지 낮춘다. 예를 들어 limit이 500, request가 100인 경우, 현재 500으로 가동되고 있는 컨테이너의 CPU할당량을 100으로 낮춘다. 그래도 Overcommitted 상태가 해결되지 않는 경우, 우선 순위에 따라서 운영중인 컨테이너를 강제 종료 시킨다. 메모리의 경우에는 할당되어 사용중인 메모리의 크기를 줄일 수 는 없기 때문에, 우선 순위에 따라서 운영 중인 컨테이너를 강제 종료 시킨다. Deployment,RS/RC에 의해 관리되고 있는 컨테이너는 다시 리스타트가 되고 초기 requested 상태의 만큼만 자원 (메모리/CPU)를 요청해서 사용하기 때문에, overcommitted 상태가 해제된다.
Best practice
구글 문서에 따르면 데이타 베이스등 아주 무거운 애플리케이션이 아니면, 일반적인 경우에는 CPU request를 100m 이하로 사용하기를 권장한다. 또한 세밀하게 클러스터를 운영하기 어려운 경우에는 request와 limit의 사이즈를 같게 하는 것을 권장한다. limit이 request보다 클 경우 overcommitted 상태가 발생할 수 있는데, 이때 CPU가 throttle down 되면, 실제 필요한 CPU양 보다 작은 CPU양으로 줄어들기 때문에 성능저하가 발생할 수 있다.
<참조>
쿠버네티스 #21 - 리소스(CPU/Memory) 할당과 관리
쿠버네티스 리소스(CPU/Memory)할당과 관리 조대협 리소스 관리 쿠버네티스에서 Pod를 어느 노드에 배포할지를 결정하는 것을 스케쥴링이라고 한다. Pod에 대한 스케쥴링시에, Pod내의 애플리케이션�
bcho.tistory.com
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - 볼륨(Volume),퍼시스턴트 볼륨&볼륨 클레임(persistent volume&claim) (0) | 2020.08.15 |
|---|---|
| Kubernetes - ingress nginx 설치 및 사용법 (3) | 2020.08.02 |
| Docker - 도커 이미지 만들기 ! (Dockerfile) (0) | 2020.07.18 |
| Docker - 도커를 이용해 Single node Kafka 띄우기 (0) | 2020.06.04 |
| Docker - DOOD로 띄웠을 경우 proxy(프록시) 설정 (0) | 2020.04.21 |

오늘 다루어볼 포스팅은 "도커 이미지 만들기"이다. 이전에 한번 정리해야지해야지 하면서 미뤄왔었는데, 간단하게 다루어 볼것이다. 필자도 대충은 알았지, 뭔가 깊게 이해하지 못하고 이미지를 빌드했었는데, 이참에 기초부터 한번 정리해봐야겠다.
<Dockerfile 작성을 위한 인스트럭션>
1. FROM : 도커 이미지의 바탕이 될 베이스 이미지를 지정한다. Dockerfile로 이미지를 빌드할 때 먼저 FROM 인스트럭션에 지정된 이미지를 내려받는다. FROM에서 받아오는 도커 이미지는 도커 허브(Docker Hub)라는 레지스트리를 참조한다. 도커 특정 버전 이상에서는 Multi stage build가 가능해져서, 하나의 베이스 이미지(FROM ..)가 아닌 여러 베이스 이미지를 사용하여 빌드가 가능하다(FROM을 여러번 사용)
2. RUN : 도커 이미지를 실행할 때 컨테이너 안에서 실행할 명령을 정의하는 인스트럭션이다. 인자로 도커 컨테이너 안에서 실행할 명령을 그대로 기술한다.
3. COPY : 도커가 동작 중인 호스트 머신의 파일이나 디렉터리를 도커 컨테이너 안으로 복사하는 인스트럭션이다.
4. CMD : 도커 컨테이너를 실행할 때 컨테이너 안에서 실행할 프로세스를 지정한다. 2번의 RUN 인스트럭션은 이미지를 빌드할 때 실행되고, CMD는 컨테이너를 시작할 때 한 번 실행된다.
"> go run /echo/main.go"를 CMD 인스트럭션에 기술하면 아래와 같다.
CMD ["go", "run", "/echo/main.go"]
5. ENTRYPOINT : CMD와 마찬가지로 컨테이너 안에서 실행할 프로세스를 지정하는 인스트럭션이다. ENTRYPOINT를 지정하면 CMD의 인자가 ENTRYPOINT에서 실행하는 파일(셸 등)에 인자로 전달된다. 즉, ENTRYPOINT에 지정된 값이 기본 프로세스를 지정하는 것이다.
FROM golang:1.10
#./entry.sh을 실행시키면서 ARG1, ARG2를 entry.sh의 인자로 전달한다.
ENTRYPOINT ["./entry.sh"]
CMD ["ARG1", "ARG2"]
6. LABEL : 이미지를 만든 사람의 이름 등을 적을 수 있다.
7. ENV : 도커 컨테이너 안에서 사용할 수 있는 환경변수를 지정한다.
8. ARG : 이미지를 빌드할 때 정보를 함께 넣기 위해 사용한다. 이미지를 빌드할 때만 사용할 수 있는 일시적인 환경변수다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - ingress nginx 설치 및 사용법 (3) | 2020.08.02 |
|---|---|
| Kubernetes - kubernetes(쿠버네티스) resources(cpu/momory) 할당 및 관리 (0) | 2020.07.19 |
| Docker - 도커를 이용해 Single node Kafka 띄우기 (0) | 2020.06.04 |
| Docker - DOOD로 띄웠을 경우 proxy(프록시) 설정 (0) | 2020.04.21 |
| Docker - Docker 다른 레포지토리에 push하기 (0) | 2020.04.20 |

이번 포스팅은 간단하게 싱글 노드 카프카를 도커로 띄우는 방법이다.
git clone https://github.com/wurstmeister/kafka-docker
cd kafka-docker
설정 파일은 docker-compoese로 되어있으며, 아래와 같다.
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
build: .
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_CREATE_TOPICS: "test:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
docker compose 명령으로 실제 컨테이너를 띄운다.
docker-compose -f docker-compose-single-broker.yml up -d
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - kubernetes(쿠버네티스) resources(cpu/momory) 할당 및 관리 (0) | 2020.07.19 |
|---|---|
| Docker - 도커 이미지 만들기 ! (Dockerfile) (0) | 2020.07.18 |
| Docker - DOOD로 띄웠을 경우 proxy(프록시) 설정 (0) | 2020.04.21 |
| Docker - Docker 다른 레포지토리에 push하기 (0) | 2020.04.20 |
| Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때 (0) | 2020.04.09 |

이번 포스팅에서 다루어볼 내용은 DOOD로 도커를 띄웠을 때, proxy 설정하는 방법이다. 그전에 간단하게 Docker in Docker(dind)와 Docker Out Of Dcoker(DooD)에 대해 알아보자.
Docker in Docker(dind)
도커 내부에 격리된 Docker 데몬을 실행하는 방법이다. CI(Jenkins docker agent) 측면에서 접근하면 Agent가 Docker client와 Docker Daemon 역할 두가지를 동시에 하게 된다. 하지만 이 방법은 단점이 존재한다. 내부의 도커 컨테이너가 privileged mode로 실행되어야 한다.
> docker run --privileged --name dind -d docker:1.8-dind
privileged 옵션을 사용하면 모든 장치에 접근할 수 있을뿐만 아니라 호스트 컴퓨터 커널의 대부분의 기능을 사용할 수 있기 때문에 보안에 좋지않은 방법이다. 하지만 실제로 실무에서 많이 쓰는 방법이긴하다.
Docker out of Docker(dood)
Docker out of Docker는 호스트 머신에서 동작하고 있는 Docker의 Docker socket과 내부에서 실행되는 Docker socket을 공유하는 방법이다. 간단하게 볼륨을 마운트하여 두 Docker socket을 공유한다.
> docker run -v /var/run/docker.sock:/var/run/docker.sock ...
이 방식을 그나마 Dind보다는 권장하고 있는 방법이긴하다. 하지만 이 방식도 단점은 존재한다. 내부 도커에서 외부 호스트 도커에서 실행되고 있는 도커 컨테이너를 조회할 수 있고 조작할 수 있기 때문에 보안상 아주 좋다고 이야기할 수는 없다.
DooD proxy 설정
dood로 도커를 띄운 경우, 호스트 머신에 동작하고 있는 도커에 proxy 설정이 되어있어야 내부 도커에도 동일한 proxy 설정을 가져간다.
방법1. /etc/sysconfig/docker에 프록시 설정
> sudo vi /etc/sysconfig/docker
HTTP_PROXY="http://proxy-domain:port"
HTTPS_PROXY="http://proxy-domain:port"
#docker restart
> service docker restart
방법2. 환경변수 설정
> mkdir /etc/systemd/system/docker.service.d
> cd /etc/systemd/system/docker.service.d
> vi http-proxy.conf
[Service]
Environment="HTTP_PROXY=http://proxy-domain:port"
Environment="HTTPS_PROXY=http://proxy-domain:port"
Environment="NO_PROXY=hostname.example.com, 172.10.10.10"
> systemctl daemon-reload
> systemctl restart docker
> systemctl show docker --property Environment
Environment=GOTRACEBACK=crash HTTP_PROXY=http://proxy-domain:port HTTPS_PROXY=http://proxy-domain:port NO_PROXY= hostname.example.com,172.10.10.10
여기까지 dood로 도커 엔진을 띄웠을 때, proxy 설정하는 방법이다.
참고
How to configure docker to use proxy – The Geek Diary
www.thegeekdiary.com
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Docker - 도커 이미지 만들기 ! (Dockerfile) (0) | 2020.07.18 |
|---|---|
| Docker - 도커를 이용해 Single node Kafka 띄우기 (0) | 2020.06.04 |
| Docker - Docker 다른 레포지토리에 push하기 (0) | 2020.04.20 |
| Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때 (0) | 2020.04.09 |
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |

이번에 다루어볼 포스팅은 도커로 ES를 띄우기전에 뭔가 커스텀한 이미지를 만들어서 올릴수없을까 하는 생각에 간단히 ES 기본 이미지에 한글 형태소 분석기(Nori) 플러그인이 설치가된 ES docker image를 커스텀하게 만들어보았다.
#Dockerfile
FROM docker.elastic.co/elasticsearch/elasticsearch:7.6.2
ENV ES_VOLUME=/usr/share/elasticsearch/data
ENV ES_BIN=/usr/share/elasticsearch/bin
RUN mkdir $ES_VOLUME/dictionary
RUN $ES_BIN/elasticsearch-plugin install --batch analysis-nori
간단히 설명하면, 베이스 이미지로 공식 elasticsearch image를 사용하였고, 나중에 사용자 사전이 위치할 도커 볼륨 디렉토리를 잡아주었고, 거기에 사전이 담기는 디렉토리를 생성했다. 그리고 마지막으로 한글 형태소분석기 플러그인을 설치하는 쉘을 실행시켰다. 이렇게 빌드된 elasticsearch image는 한글 형태소분석기가 이미 설치가된 elasticsearch image가 된다. 그래서 굳이 plugin directory를 마운트해서 직접 플러그인을 설치할 필요가 없다. 물론 추후에 필요에 의해서 설치해야한다면 어쩔수 없지만 말이다.
여기에 추후 더 커스텀할 내용을 넣으면 될듯하다.
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - 클러스터, 샤드, 인덱스 상태 확인하기 (0) | 2020.08.25 |
|---|---|
| Elasticsearch - 퍼포먼스 튜닝하는 방법 by ebay (1) | 2020.08.19 |
| Elasticsearch - 한글 자동완성(Nori Analyzer, Ngram, Edge Ngram) (0) | 2020.04.09 |
| Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3 (0) | 2019.09.20 |
| Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2 (1) | 2019.09.20 |

Dockerfile 파일이 아니라, 커스텀한 파일명으로 docker manifest를 작성하였을 때, 로컬 빌드하는 명령이다. Dockerfile로 작성되어 있을 때 로컬빌드 명령은 아래와 같다.
docker build -t 1223yys/web-project:latest .
만약 Dockerfile이 아닌 다른 파일명으로 image manifest를 작성하였을 때는 아래와 같다.
docker build -t 1223yys/web-project -f ./custom_file_name .
위 명령을 실행한 후에 이미지가 잘 빌드되었는지 확인해보자.
docker image ls'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Docker - DOOD로 띄웠을 경우 proxy(프록시) 설정 (0) | 2020.04.21 |
|---|---|
| Docker - Docker 다른 레포지토리에 push하기 (0) | 2020.04.20 |
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |
| Kubernetes - Kubernetes 아키텍쳐 (0) | 2019.11.26 |
| Kubernetes - Kubernetes 용어설명 (0) | 2019.11.26 |

이전 포스팅에서 쿠버네티스에 대한 용어와 개념을 다루어봤는데, 이번 포스팅에서는 실제 쿠버네티스가 어떤 구조로 되어 있는지 아키텍쳐에 대해 다루어본다.
2019/11/26 - [인프라/Docker&Kubernetes] - Kubernetes - Kubernetes 용어설명
Kubernetes - Kubernetes 용어설명
지금까지 쿠버네티스에 대한 포스팅을 여러개 했는데, 더 진행하기 앞서 쿠버네티스에서 사용하는 용어 및 개념들을 정리하면 좋을듯 해서 포스팅한다. 마스터&노드 쿠버네티스의 클러스터의 구조에서 전체 클러..
coding-start.tistory.com

마스터&노드
쿠버네티스 클러스터는 크게 마스터와 노드로 구성된다. 마스터는 쿠버네티스 클러스터의 전반적인 것을 관리하고 노드는 Pod이나 Service등처럼 쿠버네티스 위에서 동작하는 워크로드를 호스팅하는 역할을 한다.
1) 마스터
클러스터 전체를 관장하는 시스템이며 크게 API 서버, 스케줄러, 컨트롤러 매니저, etcd로 구성되어 있다.
-API서버 : 쿠버네티스는 모든 명령과 통신을 API를 통해서 하는데, 그 중심이 되는 서버가 API 서버이다.
-Etcd : 쿠버네티스 클러스터의 데이터 베이스 역할을 하는 Key/Value Store이다. 쿠버네티스 클러스터의 상태나 설정 정보를 저장한다.
-스케줄러 : 스케줄러는 Pod, 서비스 등 각 리소스들을 적절한 노드에 할당하는 역할을 한다.
-컨트롤러 매니저 : 컨트롤러 매니저는 컨트롤러(RC,SC,VC,NC)를 생성하고 이를 각 노드에 배포하며 관리하는 역할을 한다.
-DNS : 쿠버네티스는 리소스의 엔드포인트를 DNS로 맵핑하고 관리한다. Pod이나 서비스등은 IP를 배정받는데, 동적으로 생성되는 값이기 때문에 그 리소스에 대한 정보를 DNS로 해결한다. 이러한 패턴을 Service Discovery 패턴이라 한다. 새로운 리소스가 생성되면, 그 리소스의 IP와 DNS를 매핑하여 등록하고 DNS 이름을 기반으로 리소스에 접근할 수 있도록 한다.
2) 노드
노드는 마스터에 의해 명령을 받고 실제 워크로드를 생성하여 서비스 하는 시스템이다. 노드에는 Kubelet, Kube-Proxy, cAdvisor 그리고 컨테이너 런타임이 배포된다.
-Kubelet : 노드에 배포되는 에이전트로, 마스터의 API서버와 통신을 하면서, 노드가 수행해야 할 명령을 받아서 수행하고, 반대로 노드의 상태등을 마스터로 전달하는 역할을 한다.
-Kube-Proxy : 노드로 들어오는 네트워크 트래픽을 적절한 컨테이너로 라우팅하고, 로드밸런싱등 노드로 들어오고 나가는 네트워크 트래픽을 프록시하며 노드와 마스터간의 네트워크 통신을 관리한다.
-Container Runtime : Pod을 통해 배포된 컨테이너를 실행하는 컨테이너 런타임이다.
-cAdvisor : 각 노드에서 기동되는 모니터링 에이전트로, 노드내에서 기동되는 컨테이너들의 상태와 성능등의 정보를 수집하여, 마스터 서버의 API 서버로 전달한다.
여기까지 쿠버네티스 클러스터의 구조에 대해 간단히 살펴봤다. 사실 쿠버네티스를 사용할 때, 이 정보들을 몰라도 사용이 가능할지는 모르겠지만, 원리 혹은 구동방식, 아키텍쳐를 알고 모르고는 이슈 트랙킹하는 데 큰 차이가 있다고 생각이 들기 때문에 꼭 알고 넘어가야하는 개념들인 것 같다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때 (0) | 2020.04.09 |
|---|---|
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |
| Kubernetes - Kubernetes 용어설명 (0) | 2019.11.26 |
| Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법 (0) | 2019.11.22 |
| Kubernetes - 쿠버네티스 서비스,인그레스(Service,Ingress) (1) | 2019.11.20 |

지금까지 쿠버네티스에 대한 포스팅을 여러개 했는데, 더 진행하기 앞서 쿠버네티스에서 사용하는 용어 및 개념들을 정리하면 좋을듯 해서 포스팅한다.
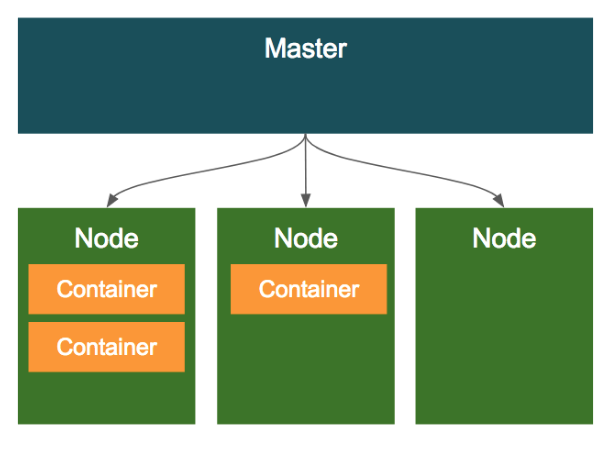
마스터&노드
쿠버네티스의 클러스터의 구조에서 전체 클러스터를 관리하는 마스터 노드가 있고, 도커 컨테이너가 배포되는 노드가 존재한다.
Pod
Pod는 쿠버네티스에서 가장 기본적인 배포 단위로, 하나 이상의 도커 컨테이너의 묶음이다. 쿠버네티스는 컨테이너 단위로 배포하는 것이 아니라, Pod이라는 하나 이상의 도커 컨테이너로 이루어진 단위로 배포가 된다.
그렇다면 개별적인 컨테이너로 배포하지 않고, Pod이라는 단위로 배포하는 이유는 무엇일까?
- Pod 내의 컨테이너는 IP와 Port를 공유한다. 즉, 서로 localhost로 통신이 가능한 것이다.
- Pod 내에 배포된 컨테이너 간에는 디스크 볼륨 공유가 가능하다.
위와 같은 특징을 가지고 있기 때문에 보통 하나 이상의 컨테이너를 포함한 Pod 단위로 배포한다. 그렇다면 이러한 예제로는 어떤 것이 있을 까? 요즘 애플리케이션을 배포할 때는 애플리케이션 하나만 배포하는 것이 아니라, Nginx와 로그 수집기, 예거 등을 같이 배포하는 경우가 많은 데, 보통 이런 조합은 디스크를 공유해야 하거나 서로 HTTP 통신을 해야한다. 하지만 이럴때 서로 다른 컨테이너로 배포할 경우 굉장히 구성이 까다로워질 것이다. 즉, 하나의 Pod 내에 여러 컨테이너로 띄울 경우 위 문제가 어느정도 해결된다.
이렇게 애플리케이션과 애플리케이션이 사용하는 주변 프로그램을 같이 배포하는 패턴을 MSA(Micro Service Architecture)에서 사이드카패턴이라고 한다.
Volume
Pod가 뜰때, 컨테이너마다 로컬 디스크를 생성해서 기동되는데, 이 로컬 디스크의 경우 영구적이지 못하다. 즉, 컨테이너가 리스타트 되거나 새로 배포될때 로컬 디스크의 내용이 유실된다. 그런데 보통 데이터베이스와 같이 영구적으로 파일을 저장해야 하는 경우에는 컨테이너의 리스타트와 상관없이 파일을 영구적으로 저장해야 하는데, 이럴때 볼륨을 마운트해서 사용한다. 즉, Pod에 볼륨을 할당한다는 뜻이다. 이러한 볼륨은 하나의 Pod 내에서 여러 컨테이너가 공유가능하다는 특징을 가지고 있다.
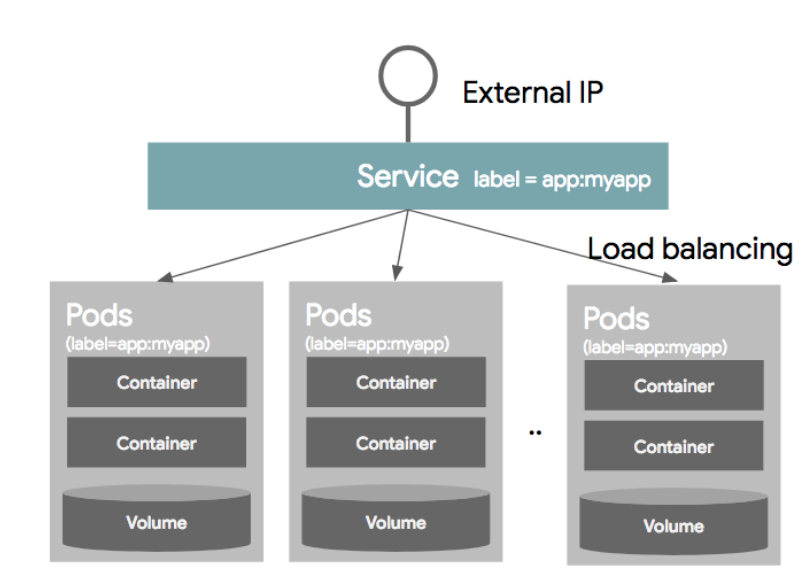
Service
보통의 경우 하나의 Pod으로만 서비스를 제공하지 않는다. 보통은 여러개의 동일한 Pod을 띄워 로드밸런싱하여 서비스를 제공한다. 이럴 경우에 Pod은 동적으로 생성되고 삭제되고, 생성되는 IP는 그때그때 다르기 때문에 이러한 Pod의 디스커버리를 IP로 묶는 것을 쉽지 않다. 그래서 사용되는 것이 Service이고 이는 내부적으로 라벨과 라벨 셀렉터를 이용하여 가용 가능한 Pod을 디스커버리한다.
서비스를 정의할때, 어떤 Pod을 하나의 서비스라는 개념으로 묶을 것인지 정의하는데, 이를 라벨 셀렉터라고 한다. 각 Pod의 Object를 정의할 때, 메타정보에 라벨정보를 넣을 수 있는데, 이 라벨을 Service Object를 정의할때 라벨셀렉터에 넣어준다. 이러면 동일한 라벨을 같은 여러개의 같은 Pod이 동일한 Service 단위로 묶이게 되는 것이다.
Namespace
네임스페이스는 한 쿠버네티스 클러스터 내의 논리적인 분리단위이다. Object들을 네임스페이스 단위로 별도 생성 및 관리가 가능하고, 사용자의 권한 역시 이 네임스페이스 단위로 부여할 수 있다. 보통 개발/운영/테스트 환경을 간혹 네임스페이스 단위로 나누기도 하는데, 왠만하면 클러스터 자체를 분리하는 것이 좋다. 네임스페이스로 나눈다고 해서 물리적인 환경을 분리하는 것이 아니고 단순 논리적인 분리밖에 되지 않아 머신의 리소스를 같이 사용하기 때문이다.
Label
라벨은 쿠버네티스의 리소스를 선택하는데 사용된다. 각 리소스는 라벨을 가질 수 있고, 라벨 검색 조건에 따라 특정 라벨을 가진 리소스만 선택이 가능하다. 라벨은 metadata 부분에 키/값으로 정의 가능하며 하나의 리소스에는 하나 이상의 라벨을 가질 수 있다.
"metadata": {
"labels": {
"key1": "value1",
"key2": "value2"
}
}
라벨 셀렉터를 사용하는 방법으로 2가지 방법을 제공한다. 하나는 Equality based selector와, Set based selector가 있다.
Equality based selector는 단순히 같고,다르다는 조건을 이용하여 라벨을 셀렉하는 방법이다.
- env = dev
- env != product
Set based selector는 집합 개념을 이용한다.
- env in (dev,qa)
- env notin (product,stage)
Controller
컨트롤러는 기본 오브젝트(Pod,Service,Volume,Namespace)들을 생성하고 관리하는 역할을 한다. 컨트롤러는 Replicaion Controller, Replication Set, DaemonSet, Job, StatefulSet, Deployment 들이 있다.
1) Replication Controller
Replication Controller는 Pod을 관리해주는 역할을 하는데, 지정된 숫자로 Pod을 기동시키고, 관리하는 역할을 한다. Replication Controller는 크게 3가지 파트로 구성되는데, Replica의 수, Pod Selector, Pod Template(Spec)으로 구성된다.
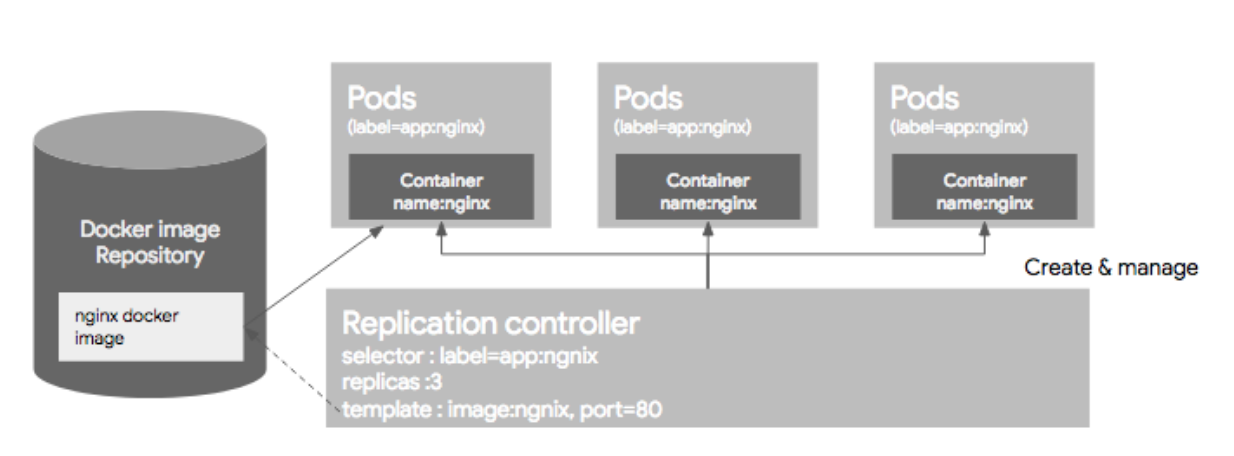
이미 기동된 Pod이 있다면 주의해야할 점이 있다. Pod이 이미 떠있는 상태에서 RC 리소스를 생성하고 그 Pod의 라벨이 RC와 라벨 셀렉터와 일치하면 Pod들은 새롭게 생성된 RC의 컨트롤을 받는다. 만약 해당 Pod들이 RC에서 정의한 replica 수보다 많으면, replica 수에 맞게 Pod들을 삭제하고, 모자르면 template(Spec)에 정의된 되로 Pod을 띄우게 된다. 하지만 여기서 주의할 점이 template(Spec)에 정의된 Pod 리소스 설정과 라벨셀렉터에 의해 픽된 Pod의 리소스 설정이 다르더라도 기존 Pod을 내렸다가 올리지 않는 다는 점이다. 이말은 즉, 싱크가 맞지 않는 형상이 다른 Pod이 뜰 가능성이 있다.
2) ReplicaSet
ReplicaSet은 RC의 새버전이라 생각하면 된다. RC는 Equality 기반 셀럭터를 사용하는데, ReplicaSet은 Set 기반 셀렉터를 이용한다.
3) Deployment
Deployment는 RC와 RS의 좀더 상위 개념이다. 셀제 운영에서는 RC,RS 보다 Deployment를 이용한다. Deployment를 설명하기 전에 배포 방식에 대한 이해가 필요하므로 설명한다.

위와 같은 RC와 Pod들이 있다고 생각하고 새로운 버전의 Pod을 띄우는 상황이라 가정하자. 보통이런 상황에서 Blue/Green 배포와 Rolling Update 배포 방식을 이용한다.
Blue/Green deployment
블루그린 배포 방식은 블루(예전) 버전으로 서비스 하고 있던 시스템은 그린(새로운)버전을 배포한 후, 트래픽을 블루에서 그린으로 한번에 돌리는 방식이다. 여러가지 방법이 있지만 가장 쉬운 방법은 새로운 RC와 Pod들을 모두 띄운 후에 Service의 트래픽을 한번에 새로운 Pod으로 돌리는 방법이다.
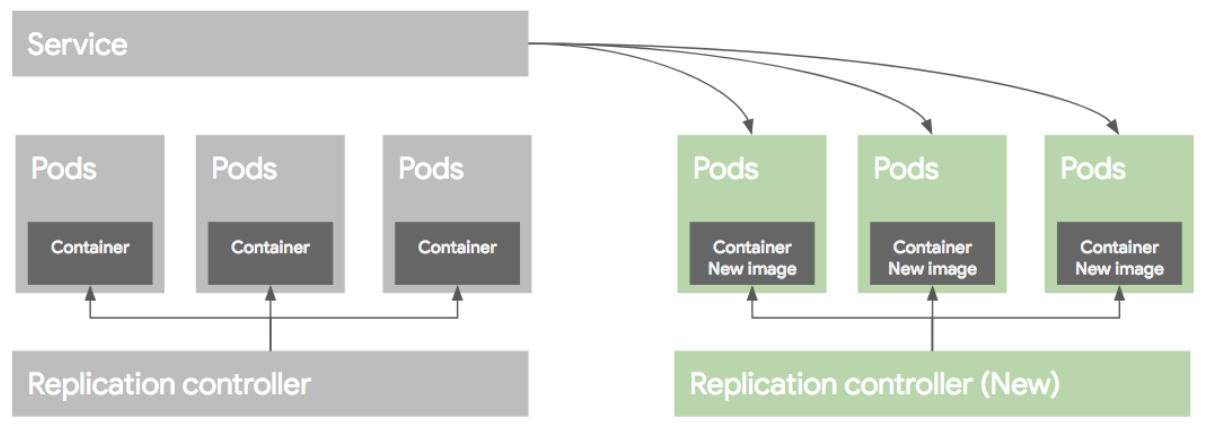
배포후 문제가 없다면 이전 RC와 Pod들을 내려준다.
Rolling update deployment
롤링 업데이트 배포 방식은 Pod을 하나씩 업그레이드 하는 방식이다. 이렇게 배포를 하려면 먼저 새로운 RC를 만든 후에, 기존 RC에서 replica 수를 하나 줄이고, 새로운 RC에는 replica 수를 하나 늘려준다. 이런식으로 하나 줄이고 하나늘리고 하는 방식으로 배포를 하게된다.
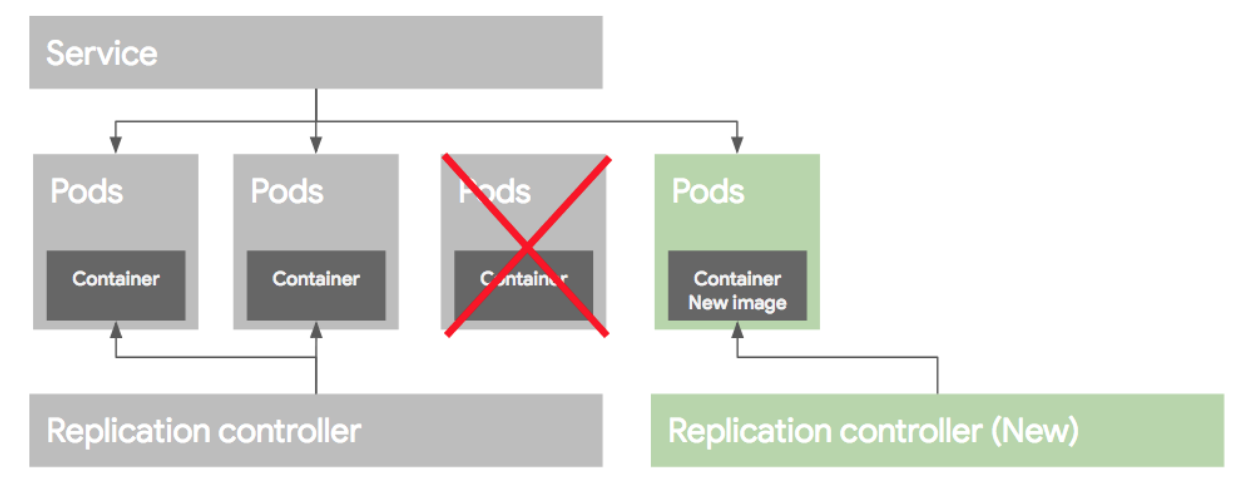

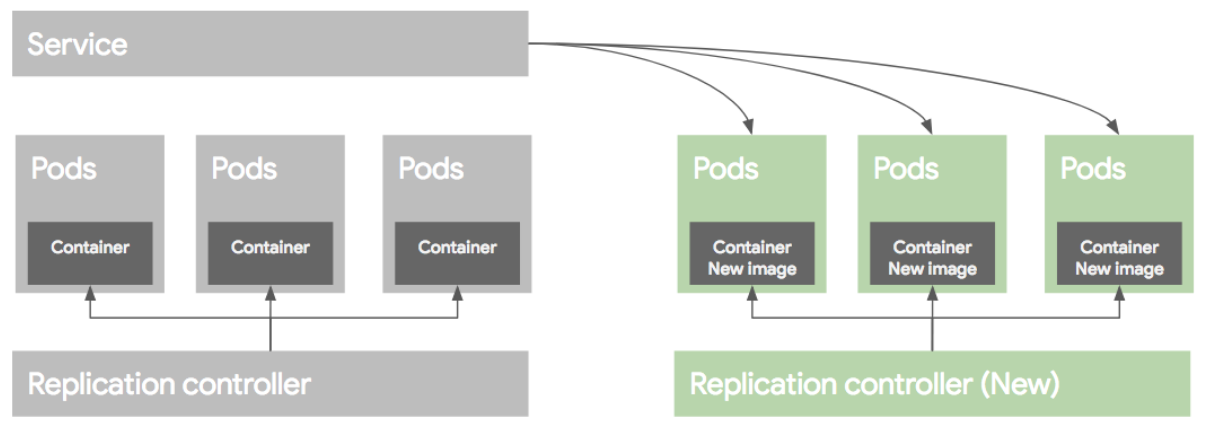
만약 배포가 잘못되었다면 기존 RC의 replica를 원래대로 올리고, 새버전의 replica 수를 0으로 만들어 롤백한다. 이런 롤링 업데이트 배포 방식을 RC 단위로도 가능하지만 여러가지 작업이 필요하다. 그래서 이러한 여러 과정을 추상화한 개념을 Deployment라고 보면 된다.
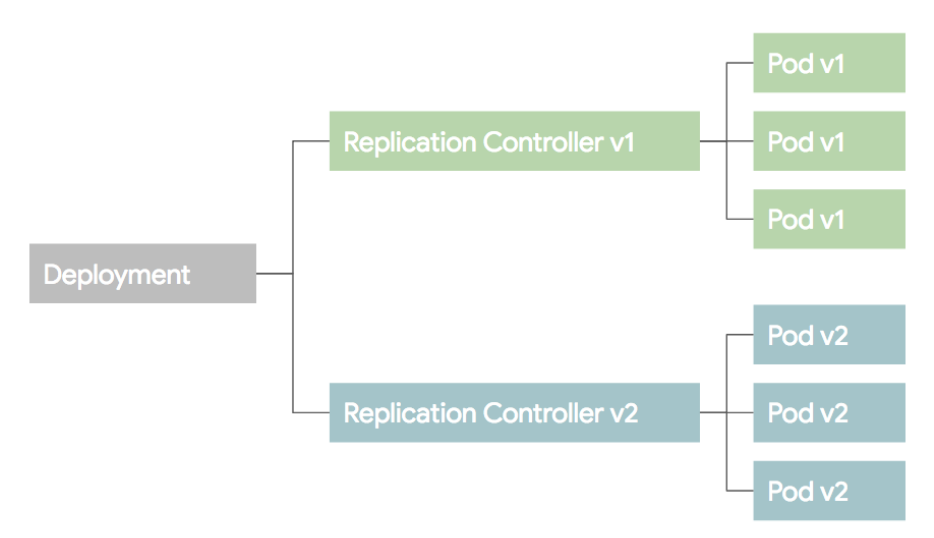
4) DaemonSet
DaemonSet은 Pod가 각각의 노드에서 하나씩만 돌게하는 형태로 Pod을 관리하는 컨트롤러이다. RC, RS 혹은 Deployment로 관리되는 Pod들은 클러스터 노드의 리소스 상황에 따라 비균등적으로 배포되는데, DS에 의해 관리되는 Pod는 모든 노드에 균등하게 하나씩만 배포된다. 보통 서버 모니터링 혹은 로그 수집용도로 많이 사용된다.
DS의 다른 특징중 하나는 특정 Node들에만 Pod들을 하나씩 배포되도록 설정이 가능 하다. 이렇게 특정 노드를 셀렉하기 위해 node selector를 제공하여 특정 노드를 선택가능하도록 지원한다.
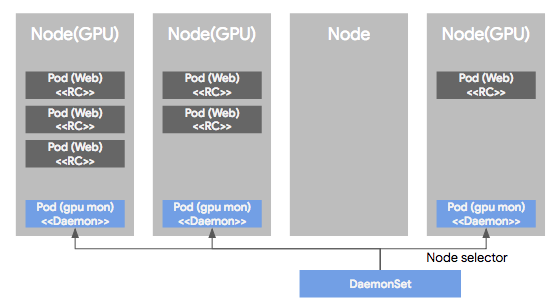
여기까지 간단히 쿠버네티스에서 사용되는 용어들을 다루어봤다. 사실 다루지 못한 용어들이 많이 있지만 추후에 더 다루어볼 예정이다. 다음 포스팅에서는 쿠버네티스 아키텍쳐에 대해 다루어볼 것이다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |
|---|---|
| Kubernetes - Kubernetes 아키텍쳐 (0) | 2019.11.26 |
| Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법 (0) | 2019.11.22 |
| Kubernetes - 쿠버네티스 서비스,인그레스(Service,Ingress) (1) | 2019.11.20 |
| Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트) (0) | 2019.11.19 |