
'2020/08'에 해당되는 글 11건
- 2020.08.30 :: Kubernetes - kustomize를 이용한 쿠버네티스 오브젝트 관리
- 2020.08.25 :: Elasticsearch - 클러스터, 샤드, 인덱스 상태 확인하기
- 2020.08.24 :: Kubernetes - 쿠버네티스 클러스터 로깅(logging, fluentd + kafka + elk)
- 2020.08.22 :: Web Server - Nginx 설치 및 사용방법(nginx cache, reverse proxy, 프록시, 캐시)
- 2020.08.22 :: 운영체제 - 디스크 사용량 및 정보 확인
- 2020.08.19 :: Elasticsearch - 퍼포먼스 튜닝하는 방법 by ebay 1
- 2020.08.17 :: Gradle - Could not initialize class org.codehaus.groovy.runtime.InvokerHelper(Spring, gradle project)
- 2020.08.16 :: MongoDB - 백업하고 복구하기(mongodump&mongorestore) 1

오늘 다루어볼 내용은 kustomize이다. Kustomize는 kustomization 파일을 이용해 kubernetes 오브젝트를 사용자가 원하는 대로 변경(customize)하는 도구이다.
모든 예제는 아래 깃헙 kube-kustomize 디렉토리에 있다.
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
kustomization 파일을 포함하는 디렉터리 내의 리소스를 보거나 실제 클러스터에 리소스를 적용하려면 다음 명령어를 이용한다.
#kustomize가 적용된 설정파일 결과를 보여준다.
> kubectl kustomize <kustomization_directory>
#실제 kustomize 리소스를 클러스터에 적용한다.
> kubectl apply -k <kustomization_directory>
Kustomize
Kustomize는 쿠버네티스 구성을 사용자 정의화하는 도구이다. 이는 애플리케이션 구성 파일을 관리하기 위해 다음 기능들을 가진다.
- 다른 소스에서 리소스 생성
- 리소스에 대한 교차 편집 필드 설정
- 리소스 집합을 구성하고 사용자 정의
교차 편집 필드 설정
프로젝트 내 모든 쿠버네티스 리소스에 교차 편집 필드를 설정하는 것은 꽤나 일반적이다. 교차 편집 필드를 설정하는 몇 가지 사용 사례는 다음과 같다.
- 모든 리소스에 동일한 네임스페이스를 설정
- 동일한 네임 접두사 또는 접미사를 추가
- 동일한 레이블들을 추가
- 동일한 어노테이션들을 추가
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
# deployment.yaml을 생성
cat <<EOF >./deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
EOF
cat <<EOF >./kustomization.yaml
namespace: my-namespace
namePrefix: dev-
nameSuffix: "-001"
commonLabels:
app: bingo
commonAnnotations:
oncallPager: 800-555-1212
resources:
- deployment.yaml
EOF> kubectl kustomize ./kube-kustomize/kustomize-upsert-field
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
oncallPager: 800-555-1212
labels:
app: bingo
name: dev-nginx-deployment-001
namespace: my-namespace
spec:
selector:
matchLabels:
app: bingo
template:
metadata:
annotations:
oncallPager: 800-555-1212
labels:
app: bingo
spec:
containers:
- image: nginx
name: nginx
구성(composition)
한 파일에 deployment, service 등을 정의하는 것은 일반적이다. kustomize는 서로 다른 리소스들을 하나의 파일로 구성할 수 있게 지원한다.
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
# deployment.yaml 파일 생성
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
# service.yaml 파일 생성
cat <<EOF > service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
EOF
# 이들을 구성하는 kustomization.yaml 생성
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
- service.yaml
EOF> kubectl kustomize /kube-kustomize/kustomize-composition
apiVersion: v1
kind: Service
metadata:
labels:
run: my-nginx
name: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 2
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: my-nginx
ports:
- containerPort: 80
사용자 정의(user patch define)
패치는 리소스에 다른 사용자 정의를 적용하는 데 사용할 수 있다. Kustomize는 patchesStrategicMerge와 patchesJson6902를 통해 서로 다른 패치 메커니즘을 지원한다. patchesStrategicMerge는 파일 경로들의 리스트이다. 각각의 파일은 patchesStrategicMerge로 분석될 수 있어야 한다. 패치 내부의 네임은 반드시 이미 읽혀진 리소스 네임(ex. deployment.yaml 안의 이름)과 일치해야 한다. 한 가지 일을 하는 작은 패치가 권장된다. 예를 들기 위해 디플로이먼트 레플리카 숫자를 증가시키는 하나의 패치와 메모리 상한을 설정하는 다른 패치를 생성한다.
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
# deployment.yaml 파일 생성
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
# increase_replicas.yaml 패치 생성
cat <<EOF > increase_replicas.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 3
EOF
# 다른 패치로 set_memory.yaml 생성
cat <<EOF > set_memory.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
template:
spec:
containers:
- name: my-nginx
resources:
limits:
memory: 512Mi
EOF
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
patchesStrategicMerge:
- increase_replicas.yaml
- set_memory.yaml
EOF> kubectl kustomize /kube-kustomize/kustomize-patchesStrategicMerge
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 3
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: my-nginx
ports:
- containerPort: 80
resources:
limits:
memory: 512Mi
모든 리소스 또는 필드가 patchesStrategicMerge를 지원하는 것은 아니다. 임의의 리소스 내 임의의 필드의 수정을 지원하기 위해, Kustomize는 patchesJson6902를 통한 JSON 패치 적용을 제공한다. Json 패치의 정확한 리소스를 찾기 위해, 해당 리소스의 group, version, kind, name이 kustomization.yaml 내에 명시될 필요가 있다. 예를 들면, patchesJson6902를 통해 디플로이먼트의 리소스만 증가시킬 수 있다. 또한 patchesStrategicMerge, patchesJson6902를 같이 혼합해서 사용도 가능하다.
#deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
resources:
limits:
memory: 256Mi
#patch-replica.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 3
#patch-resource.yaml
- op: replace
path: /spec/template/spec/containers/0/resources/limits/memory
value: 512Mi
#kustomization.yaml
resources:
- deployment.yaml
patchesStrategicMerge:
- patch-replica.yaml
patchesJson6902:
- target:
kind: Deployment
name: my-nginx
group: apps
version: v1
path: patch-resource.yaml> kubectl kustomize /kube-kustomize/kustomize-patchesJson6902
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 3
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: my-nginx
ports:
- containerPort: 80
resources:
limits:
memory: 512Mi
patchesJson6902는 "replace"라는 오퍼레이션 말고, add, remove, move, copy, test라는 오퍼레이션도 존재한다.
patch images
patch 파일을 생성하지 않고, 컨테이너의 이미지를 재정의 할 수 있다.
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
images:
- name: nginx
newName: my.image.registry/nginx
newTag: 1.4.0
EOF> kubectl kustomize /kube-kustomize/kustomize-patch-images
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 2
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: my.image.registry/nginx:1.4.0
name: my-nginx
ports:
- containerPort: 80
Base&Overlay
Kustomize는 base와 overlay의 개념을 가지고 있다. base는 kustomization.yaml과 함께 사용되는 디렉터리다. 이는 사용자 정의와 관련된 리소스들의 집합을 포함한다. kustomization.yaml의 내부에 표시되는 base는 로컬 디렉터리이거나 원격 리포지터리의 디렉터리가 될 수 있다. overlay는 kustomization.yaml이 있는 디렉터리로 다른 kustomization 디렉터리들을 bases로 참조한다. base는 overlay에 대해서 알지 못하며 여러 overlay들에서 사용될 수 있다. 한 overlay는 다수의 base들을 가질 수 있고, base들에서 모든 리소스를 구성할 수 있으며, 이들의 위에 사용자 정의도 가질 수 있다.
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
# base를 가지는 디렉터리 생성
mkdir base
# base/deployment.yaml 생성
cat <<EOF > base/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
EOF
# base/service.yaml 파일 생성
cat <<EOF > base/service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
EOF
# base/kustomization.yaml 생성
cat <<EOF > base/kustomization.yaml
resources:
- deployment.yaml
- service.yaml
EOF
이 base는 다수의 overlay에서 사용될 수 있다. 다른 namePrefix 또는 다른 교차 편집 필드들을 서로 다른 overlay에 추가할 수 있다. 다음 예제는 동일한 base를 사용하는 두 overlay들이다.
> mkdir dev
cat <<EOF > dev/kustomization.yaml
#구버전 base 불러오는 방법
bases:
- ../base
#resources:
#- ../base/kustomization.yaml
namespace: dev-my-nginx
patchesStrategicMerge:
- patch-replica.yaml
patchesJson6902:
- target:
kind: Deployment
name: my-nginx
group: apps
version: v1
path: patch-resource.yaml
images:
- name: nginx
newName: my.image.registry/nginx
newTag: 1.4.0
EOF
mkdir prod
cat <<EOF > prod/kustomization.yaml
#구버전 base 불러오는 방법
bases:
- ../base
#resources:
#- ../base/kustomization.yaml
namespace: prod-my-nginx
patchesStrategicMerge:
- patch-replica.yaml
patchesJson6902:
- target:
kind: Deployment
name: my-nginx
group: apps
version: v1
path: patch-resource.yaml
images:
- name: nginx
newName: my.image.registry/nginx
newTag: 1.4.0
EOF
추가적으로 patch 파일들을 몇가지 작성하였다.
> cd dev
> kubectl kustomize ./
#dev
apiVersion: v1
kind: Service
metadata:
labels:
run: my-nginx
name: my-nginx
namespace: dev-my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
namespace: dev-my-nginx
spec:
replicas: 1
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: my.image.registry/nginx:1.4.0
name: my-nginx
ports:
- containerPort: 80
resources:
limits:
memory: 512Mi
> cd ../prod
> kubectl kustomize ./
#prod
apiVersion: v1
kind: Service
metadata:
labels:
run: my-nginx
name: my-nginx
namespace: prod-my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
namespace: prod-my-nginx
spec:
replicas: 3
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: my.image.registry/nginx:1.4.0
name: my-nginx
ports:
- containerPort: 80
resources:
limits:
memory: 1024Mi
여기까지 쿠버네티스 설정 파일들을 관리하기 위한 방법으로 kustomize에 대해 간단히 다루어보었다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - 쿠버네티스 클러스터 로깅(logging, fluentd + kafka + elk) (0) | 2020.08.24 |
|---|---|
| Kubernetes - 볼륨(Volume),퍼시스턴트 볼륨&볼륨 클레임(persistent volume&claim) (0) | 2020.08.15 |
| Kubernetes - ingress nginx 설치 및 사용법 (3) | 2020.08.02 |
| Kubernetes - kubernetes(쿠버네티스) resources(cpu/momory) 할당 및 관리 (0) | 2020.07.19 |
| Docker - 도커 이미지 만들기 ! (Dockerfile) (0) | 2020.07.18 |

오늘은 간단하게 클러스터 모니터링을 위한 API 몇개를 정리해본다.
- http://es-host:9200/_cat/allocation?v -> 클러스터 디스크 현황
- http://es-host:9200/_cluster/health?pretty -> 클러스터 헬스체크
- http://es-host:9200/_cat/indices?v -> 인덱스 상태 확인
- http://es-host:9200/_cat/shards -> 모든 샤드 상태 확인
- http://es-host:9200/_cat/shards/{index_name}?v -> 특정 인덱스의 샤드 상태확인
https://brunch.co.kr/@alden/43
ElasticSearch status 바로 알기
ElasticSearch | 오늘은 ElasticSearch (이하 ES)의 status 에 대한 이야기를 해볼까 합니다. ES의 status는 무엇을 의미하는지, 그리고 어떤 값들이 있으며 어떻게 확인할 수 있는지 살펴보겠습니다. ES status ��
brunch.co.kr
'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글
| Elasticsearch - 퍼포먼스 튜닝하는 방법 by ebay (1) | 2020.08.19 |
|---|---|
| Elasticsearch - Elasticsearch custom docker image 빌드(엘라스틱서치 커스텀 도커 이미지 생성) (0) | 2020.04.16 |
| Elasticsearch - 한글 자동완성(Nori Analyzer, Ngram, Edge Ngram) (0) | 2020.04.09 |
| Elasticsearch - Aggregation API(엘라스틱서치 집계,파이프라인(Pipeline Aggregations) 집계) -3 (0) | 2019.09.20 |
| Elasticsearch - Aggregation API(엘라스틱서치 집계,버킷(Bucket Aggregations) 집계) -2 (1) | 2019.09.20 |

이번 포스팅에서는 쿠버네티스 로깅 파이프라인 구성에 대해 다루어볼 것이다. 저번 포스팅에서는 Fluentd + ES + Kibana 조합으로 클러스터 로깅 시스템을 구성했었는데, 이번 시간에는 Fluentd + kafka + ELK 조합으로 구성해본다.
<fluentd + ES + kibana logging>
Kubernetes - Kubernetes 로깅 운영(logging), Fluentd
오늘 다루어볼 내용은 쿠버네티스 환경에서의 로깅운영 방법이다. 지금까지는 쿠버네티스에 어떻게 팟을 띄우는지에 대해 집중했다면 오늘 포스팅 내용은 운영단계의 내용이 될 것 같다. 사실
coding-start.tistory.com
중간에 카프카를 두는 이유는 여러가지가 있을 수 있을 것 같다. 첫번째 버퍼역할을 하기때문에 어느정도 파이프라인의 속도 조절이 가능하다. 두번째 로그를 카프카 큐에 담아두고, 여러 컨슈머 그룹이 각기의 목적으로 로그데이터를 사용가능하다. 바로 실습에 들어가보자.
구성

구성은 위 그림과 같다. fluentd는 컨테이너 로그를 tail하고 있고, tail한 데이터를 카프카로 프로듀싱한다. 그리고 아웃풋으로 로그스태시로 보내고 로그 스태시는 엘라스틱서치에 색인을하게 된다.
실습이전에 본 실습에서 진행하는 예제중 카프카 구성과 엘라스틱서치의 구성은 별도로 옵션 튜닝 및 물리머신에 구성하는 것이 좋다. 필자는 구성의 편의를 위해 아무런 옵션을 튜닝하지 않은채 같은 쿠버네티스 클러스터에 카프카와 엘라스틱서치를 구성하였다.
kafka install & deploy on kubernetes unsing helm
TheOpenCloudEngine/uEngine-cloud-k8s
Contribute to TheOpenCloudEngine/uEngine-cloud-k8s development by creating an account on GitHub.
github.com
<헬름 설치>
> curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bash
> kubectl --namespace kube-system create sa tiller
> kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller
> helm init --service-account tiller
> helm repo update위 명령어로 헬름을 다운로드 받는다.
<카프카 헬름 차트 설치 및 배포>
> kubectl create ns kafka
> helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
> helm install --name my-kafka --namespace kafka incubator/kafka
kafka라는 별도의 네임스페이스를 생성하여 그 안에 카프카를 배포하였다.
<헬름차트 삭제>
차트 삭제가 필요하면 아래 명령어를 이용하자.
# --purge 옵션으로 관련된 모든 정보를 지운다.
helm delete my-kafka --purge
<fluentd가 데이터를 보낼 토픽생성>
> kubectl -n kafka exec my-kafka-0 -- /usr/bin/kafka-topics \
--zookeeper my-kafka-zookeeper:2181 --topic fluentd-container-logging \
--create --partitions 3 --replication-factor 3
Created topic "fluentd-container-logging".
"fluentd-container-logging"이라는 이름으로 토픽을 생성하였다.
<생성된 topic 확인>
> kubectl -n kafka exec my-kafka-0 -- /usr/bin/kafka-topics --zookeeper my-kafka-zookeeper:2181 --list
fluentd-container-logging
토픽리스트를 조회해서 우리가 생성한 토픽이 있는지 조회해본다.
<fluentd가 보낸 데이터가 큐로 잘들어오는지 확인하기 위해 컨슘머 실행>
> kubectl -n kafka exec -ti my-kafka-0 -- /usr/bin/kafka-console-consumer \
--bootstrap-server my-kafka:9092 --topic fluentd-container-logging --from-beginning
이제 실제로 카프카와 주키퍼가 쿠버네티스에 잘 떠있는지 확인해보자 !
> kubectl get pod,svc -n kafka
NAME READY STATUS RESTARTS AGE
pod/my-kafka-0 1/1 Running 2 4m14s
pod/my-kafka-1 1/1 Running 0 116s
pod/my-kafka-2 1/1 Running 0 78s
pod/my-kafka-zookeeper-0 1/1 Running 0 4m14s
pod/my-kafka-zookeeper-1 1/1 Running 0 3m32s
pod/my-kafka-zookeeper-2 1/1 Running 0 3m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-kafka ClusterIP 10.108.104.66 <none> 9092/TCP 4m14s
service/my-kafka-headless ClusterIP None <none> 9092/TCP 4m14s
service/my-kafka-zookeeper ClusterIP 10.97.205.63 <none> 2181/TCP 4m14s
service/my-kafka-zookeeper-headless ClusterIP None <none> 2181/TCP,3888/TCP,2888/TCP 4m14s
위와 같이 팟과 서비스 목록이 보인다면 다음으로 넘어간다.
ELK Stack 구성
<elasticsearch 실행>
아래 deployment와 service 설정파일을 이용하여 쿠버네티스 위에 엘라스틱서치를 구성한다.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk-stack
spec:
selector:
app: elasticsearch
ports:
- port: 9200
protocol: TCP
targetPort: 9200
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
namespace: elk-stack
labels:
app: elasticsearch
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elastic/elasticsearch:6.8.6
ports:
- containerPort: 9200
name: http
- containerPort: 9300
name: tcp
위 설정 파일은 볼륨을 구성하지 않아서 일회성(테스트)로만 가능하다. 실제로 운영환경에서는 물리머신에 클러스터를 구성하던가, 혹은 쿠버네티스 볼륨을 붙여서 구성하자.
> kubectl apply -f ./kube-logging/fluentd-elasticsearch/elasticsearch.yaml
> kubectl get pod,svc -n elk-stack
NAME READY STATUS RESTARTS AGE
pod/elasticsearch-654c5b6b77-l8k2z 1/1 Running 0 50s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP 10.101.27.73 <none> 9200/TCP 50s
<kibana 실행>
키바나는 아래 설정파일을 예제로 구성하였다.
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: elk-stack
spec:
selector:
app: kibana
ports:
- protocol: TCP
port: 5601
targetPort: 5601
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: elk-stack
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: elastic/kibana:6.8.6
ports:
- containerPort: 5601
name: http
위 설정중 조금 살펴봐야할 것은 서비스 타입을 NodePort로 준 점이다. 실제로 외부로 포트를 개방해 localhost로 접근 가능하다. 실제 운영환경에서는 ingress까지 구성하여 배포하자.
> kubectl apply -f ./kube-logging/fluentd-elasticsearch/kibana.yaml
> kubectl get pod,svc -n elk-stack | grep kibana
NAME READY STATUS RESTARTS AGE
pod/kibana-6d474df8c6-fsfc7 1/1 Running 0 24s
NAME READY STATUS RESTARTS AGE
service/kibana NodePort 10.97.240.55 <none> 5601:30578/TCP 24s
http://localhost:30578로 접근해 키바나가 잘 떠있는지와 엘라스틱서치와 잘 연동되었는지 확인하자.
<logstash 실행>
로그스태시는 아래 예시 설정 파일로 구성하였다.
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-configmap
namespace: elk-stack
data:
logstash.yml: |
http.host: "127.0.0.1"
path.config: /usr/share/logstash/pipeline
pipeline.workers: 2
logstash.conf: |
# all input will come from filebeat, no local logs
input {
kafka {
bootstrap_servers => "my-kafka.kafka.svc.cluster.local:9092"
topics => "fluentd-container-logging"
group_id => "fluentd-consumer-group"
enable_auto_commit => "true"
auto_offset_reset => "latest"
consumer_threads => 4
codec => "json"
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch.elk-stack.svc.cluster.local:9200"]
manage_template => false
index => "kubernetes-container-log-%{+YYYY-MM-dd}"
}
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash-deployment
namespace: elk-stack
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: docker.elastic.co/logstash/logstash:5.6.0
ports:
- containerPort: 5044
volumeMounts:
- name: config-volume
mountPath: /usr/share/logstash/config
- name: logstash-pipeline-volume
mountPath: /usr/share/logstash/pipeline
volumes:
- name: config-volume
configMap:
name: logstash-configmap
items:
- key: logstash.yml
path: logstash.yml
- name: logstash-pipeline-volume
configMap:
name: logstash-configmap
items:
- key: logstash.conf
path: logstash.conf
---
apiVersion: v1
kind: Service
metadata:
name: logstash-service
namespace: elk-stack
spec:
selector:
app: logstash
ports:
- protocol: TCP
port: 5044
targetPort: 5044
type: ClusterIP
설정에서 잘 살펴볼 것은 input과 output의 호스트 설정이다. 우리는 모든 모듈을 같은 클러스터에 설치할 것이기 때문에 쿠버네티스 내부 DNS를 사용하였다.(실습에 편의를 위한 것이기도 하지만, 실제 운영환경에서도 내부 시스템은 종종 클러스터 내부 DNS를 사용하기도 한다. 그러면 실제로 통신하기 위해 클러스터 밖으로 나갔다 오지 않는다.)
또 한가지 설정은 Deployment에 볼륨을 마운트 하는 부분이다. 실제 쿠버네티스에서 ConfigMap은 볼륨으로 잡히기 때문에 그 ConfigMap을 logstash pod 내부로 마운트하여 실행시점에 해당 설정파일을 물고 올라가도록 하였다.
> kubectl apply -f ./kube-logging/fluentd-elasticsearch/logstash.yaml
> kubectl get pod,svc -n elk-stack | grep logstash
NAME READY STATUS RESTARTS AGE
pod/logstash-deployment-556cfb66b5-6xrs6 1/1 Running 0 34s
service/logstash-service ClusterIP 10.96.13.170 <none> 5044/TCP 33s
<fluentd 실행>
이제는 실제 컨테이너 로그를 tail하여 수집하는 fluentd를 실행시켜보자.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-system
labels:
app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
app: fluentd-logging
template:
metadata:
labels:
app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: 1223yys/fluentd-kafka:latest
imagePullPolicy: Always
env:
- name: FLUENT_KAFKA_BROKERS
value: "my-kafka.kafka.svc.cluster.local:9092"
- name: FLUENT_KAFKA_DEFAULT_TOPIC
value: "fluentd-container-logging"
- name: FLUENT_KAFKA_OUTPUT_DATA_TYPE
value: "json"
- name: FLUENT_KAFKA_COMPRESSION_CODEC
value: "snappy"
- name: FLUENT_KAFKA_MAX_SEND_LIMIT_BYTES
value: "4096"
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
fluentd 설정파일은 몇가지 짚고 넘어갈 것들이 있다. 첫번째는 컨테이너를 tail하기 위해 마운트한 설정이다. /var/log, /var/lib/docker/container를 마운트하였다. 실제 호스트머신에 해당 디렉토리에 들어가면 파일이 보이지 않을 것이다. 만약 파일을 보고 싶다면 아래 설정을 통해 도커 컨테이너를 실행시키고 볼 수 있다.
> docker run -it --rm -v /var/lib/docker/containers:/json-log alpine ash
위 도커이미지를 실행한후 /json-log 디렉토리에 들어가면 호스트머신에 쌓인 컨테이너 로그들을 볼 수 있다.
두번째, tail한 로그를 내보내기 위한 env 설정이다. 아웃풋은 카프카로 두었고, 역시 도메인은 내부 클러스터 DNS로 잡아주었다. 그리고, 우리가 미리 생성한 토픽에 데이터를 보내고 있고 타입은 json으로 보내고 있다.(사실상 튜닝할 설정은 많지만 실습의 편의를 위해 대부분 기본 설정으로 잡았다.)
그리고 필자가 fluentd 이미지를 새로 빌드한 이유는 카프카로 보내는 로그 포맷을 수정하기 위하여 fluentd 설정파일들을 조금 수정하였기 때문이다. 혹시나 fluentd 설정 파일들이 궁금하다면 포스팅 마지막 Github을 참조하자.(https://github.com/yoonyeoseong/kubernetes-sample/tree/master/kube-logging/fluentd-kafka)
> kubectl apply -f ./kube-logging/fluentd-kafka/fluentd-kafka-daemonset.yaml
> kubectl get pod,daemonset -n kube-system | grep fluentd
NAME READY STATUS RESTARTS AGE
pod/fluentd-bqmnl 1/1 Running 0 34s
daemonset.extensions/fluentd 1 1 1 1 1 <none> 34s
이제 로그 출력을 위해 샘플 앱을 실행시켜보자. 로그 출력을 위한 앱은 꼭 아래 필자가 빌드한 웹 어플리케이션을 실행시킬 필요는 없다. 만약 아래 애플리케이션을 실행시키려면 ingress 설정 혹은 service node port를 설정하자.
> kubectl apply -f ./kube-resource/deployment-sample.yaml
> kubectl get pod
NAME READY STATUS RESTARTS AGE
sample-deployment-5fbf569554-4pzrf 0/1 Running 0 17s
이제 요청을 보내보자.
> kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.97.27.106 <none> 80:30431/TCP,443:31327/TCP 21d
ingress-nginx-controller-admission ClusterIP 10.96.76.113 <none> 443/TCP 21d
> curl localhost:30431/api
이제 키바나에 접속해보면 앱에서 출력하고 있는 로그 데이터를 볼 수 있다. 모든 예제 설정 및 코드는 아래 깃헙을 참고하자 !
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - kustomize를 이용한 쿠버네티스 오브젝트 관리 (0) | 2020.08.30 |
|---|---|
| Kubernetes - 볼륨(Volume),퍼시스턴트 볼륨&볼륨 클레임(persistent volume&claim) (0) | 2020.08.15 |
| Kubernetes - ingress nginx 설치 및 사용법 (3) | 2020.08.02 |
| Kubernetes - kubernetes(쿠버네티스) resources(cpu/momory) 할당 및 관리 (0) | 2020.07.19 |
| Docker - 도커 이미지 만들기 ! (Dockerfile) (0) | 2020.07.18 |

오늘 포스팅해볼 내용은 Web server 중 하나인 Nginx의 설치 및 사용방법에 대해 다루어본다. 우선 Nginx는 무엇인가 알아보자.
예제 설정은 아래 깃헙사이트에 있다.
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
Wiki(https://ko.wikipedia.org/wiki/Nginx)
Nginx(엔진 x라 읽는다)는 웹 서버 소프트웨어로, 가벼움과 높은 성능을 목표로 한다. 웹 서버, 리버스 프록시 및 메일 프록시 기능을 가진다.
2017년 10월 기준으로 실질적으로 작동하는 웹 사이트(active site)들에서 쓰이는 웹 서버 소프트웨어 순위는 아파치(44.89%), 엔진엑스(20.65%), 구글 웹 서버(7.86%), 마이크로소프트 IIS(7.32%)순이다.[1] 이 조사에서 생성은 되어있으나 정상적으로 작동하지 않는 웹 사이트들은 배제되었으며[2] 특히 MS의 인터넷 정보 서비스(IIS)를 설치한 웹 사이트들의 상당수가 비활성 사이트였다. 그런 사이트들도 포함하면 MS IIS가 1위이다. 2017년 6월 현재 Nginx는 한국 전체 등록 도메인 중 24.73%가 사용하고 있다.[3]
Nginx는 요청에 응답하기 위해 비동기 이벤트 기반 구조를 가진다. 이것은 아파치 HTTP 서버의 스레드/프로세스 기반 구조를 가지는 것과는 대조적이다. 이러한 구조는 서버에 많은 부하가 생길 경우의 성능을 예측하기 쉽게 해준다.
또한 nginx는 하나의 마스터 프로세스와 여러 워커 프로세스가 있고, 마스터 프로세스는 주로 설정 파일을 읽고 적용하며 워커 프로세스들을 관리하는 역할을 하게 된다. 워커 프로세스는 실제 요청에 대한 처리를 하게 된다. nginx는 event driven 모델을 메커니즘으로 사용하여 실제 워커 프로세스간 요청을 효율적으로 분산한다.
실습은 Mac os 기준으로 실습을 진행해 볼것이다. 우선 nginx를 설치해보자.
Nginx install
> brew install nginx
brew로 설치를 아래와 같은 디렉터리들이 생성된다. 우선 아래 디렉토리를 실습을 진행하면서 전부 알아볼 것이다.
Docroot is: /usr/local/var/www
The default port has been set in /usr/local/etc/nginx/nginx.conf to 8080 so that
nginx can run without sudo.
nginx will load all files in /usr/local/etc/nginx/servers/.
To have launchd start nginx now and restart at login:
brew services start nginx
Or, if you don't want/need a background service you can just run:
nginx
==> Summary
🍺 /usr/local/Cellar/nginx/1.19.2: 25 files, 2.1MB
==> Caveats
==> nginx
Docroot is: /usr/local/var/www
The default port has been set in /usr/local/etc/nginx/nginx.conf to 8080 so that
nginx can run without sudo.
nginx will load all files in /usr/local/etc/nginx/servers/.
To have launchd start nginx now and restart at login:
brew services start nginx
Or, if you don't want/need a background service you can just run:
nginx
Nginx 구동 명령어(nginx -s <signal>
- nginx : 서버시작
- nginx -s stop : 서버종료(워커들이 요청을 처리중이더라도 그냥 종료한다.)
- nginx -s quit : 워커 프로세스가 현재 요청 처리를 완료할 때까지 대기하고 모두 처리완료된 후에 서버 종료.
- nginx -s reload : nginx config를 새로 로드한다. 마스터 프로세스가 설정을 다시 로드하라는 요청을 받으면 설정 유효성 검사후 새로운 워커 프로세스를 시작하고, 이전 워커 프로세스에게 종료 메시지를 보내게 되고 이전 워커 프로세스는 요청을 완료하게 되면 종료된다.
위 명령어로 nginx를 시작 해보자 !
> nginx
> lsof -i:8080
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 88891 yun-yeoseong 6u IPv4 0x7370b7ed168f296f 0t0 TCP *:http-alt (LISTEN)
nginx 88892 yun-yeoseong 6u IPv4 0x7370b7ed168f296f 0t0 TCP *:http-alt (LISTEN)
#실행중인 모든 nginx 프로세스 목록을 가져온다.
> ps -ax | grep nginx
88891 ?? 0:00.00 nginx: master process nginx
88892 ?? 0:00.01 nginx: worker process
89201 ttys000 0:00.03 vi nginx.conf
89695 ttys001 0:00.00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn nginx
디폴트 포트인 8080으로 nginx 프로세스가 잘 떠있다. 이제 웹브라우저에서 localhost:8080으로 접속해보자.
> curl localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
브라우저에 welcome to nginx가 보인다면 설치 및 실행이 잘된 것이다 ! 어 그렇다면, 여기서 조금 의아한 것이 있을 것이다. 과연 저 html은 어디서 응답을 준것일까?
Docroot
답은 도큐먼트 루트에 있다. 설치를 하면 아래와 같은 로그가 출력되어있을 것인데, 해당 디렉토리 내에 html 파일이 존재한다.
Docroot is: /usr/local/var/www
기본적으로 웹서버는 다른 서버로 프록시 하지 않는 이상 uri로 명시한 path로 도큐먼트 루트 디렉토리를 찾아서 응답을 주게 된다. 사실 localhost:8080은 localhost:8080/index.html과 같다고 보면된다. 그렇다면 index.html의 위치를 바꾸면 어떻게 될까?
> cd /usr/local/var/www
> mkdir backup
> mv index.html ./backup
이제 아래 요청을 보내보자.
> curl localhost:8080/index.html
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.19.2</center>
</body>
</html>
우리는 index.html을 다른 디렉토리로 옮겼기 때문에 404 not found가 뜨게 된다. 그렇다면 옮긴 디렉토리 path를 명시해서 요청을 보내보자.
> curl http://localhost:8080/backup/index.html
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
응답이 잘 도착하였다. 보통 도큐멘트 루트는 어떻게 사용이 될까? 보통은 정적인 리소스 파일(css, html)을 위치시키게 된다. 그렇다면 정적인 리로스 파일을 위치시키는 이유는 무엇일까? 만약 WAS에 해당 정적인 리소스 파일을 위치시키게 되면, 사실상 서버 동작과 관련이 적은 정적 리소스를 가져오기 위한 요청도 모두 WAS로 들어가기 때문에 앱에 부하가 많이 가게 될수 있다. 그렇기 때문에 보통 정적인 리소스는 nginx(웹서버)에서 처리하고 WAS는 백엔드 데이터만 제공하게 하여 WAS의 부담을 줄여줄 수 있다.
이제는 본격적으로 Nginx의 설정을 커스터마이징해보자.
Configuration file's structure
nginx의 설정 파일은 simple directives(단순 지시문)과 block directives(블록 지시문)으로 나뉜다. 단순 지시문을 공백으로 구분 된 이름과 매개변수로 구성되며 세미콜론(;)으로 끝난다. 블록 지시문은 단순 지시문과 구조가 동일하지만 세미콜론 대신 중괄호({})로 명령 블록을 지정한다. 또한 블록지시문을 블록지시문의 중첩구조로도 이루어 질 수 있다. 이러한 지시문으로 nginx에 플러그인 된 여러 모듈을 제어하게 된다.
Nginx Configuration
nginx.conf 파일에는 nginx의 설정 내용이 들어간다. 해당 파일의 전체적인 구조(모듈)는 아래와 같이 이루어져있다.
user nginx;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
#응답의 기본 default mime type을 지정
default_type application/octet-stream;
charset utf-8;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
#지정된 에러 코드에 대해 응답나갈 document root의 html 파일을 지정
#docroot의 html말고 다른 URL로 리다이렉션 가능하다.
error_page 500 502 503 504 /50x.html;
#error_page 500 502 503 504 http://example.com/error.html
sendfile on;
tcp_nopush on;
keepalive_timeout 65;
#keepalive로 유지되는 커넥션으로 최대 처리할 요청수를 지정
#keepalive_requests 100;
#nginx의 버전을 숨길 것인가에 대한 옵션이다. 보안상 활성화하는 것을 권장한다.
server_tokens on;
#응답 컨텐츠를 압축하는 옵션, 해당 옵션말고 gzip관련 다양한 옵션 존재(압축 사이즈 등등)
gzip on;
#context : http, server, location
#클라이언트 요청 본문을 읽기 위한 버퍼 크기를 설정 64bit platform default 16k
client_body_buffer_size 16k;
#클라이언트 요청 본문을 읽기 위한 타임아웃 시간 설정
client_body_timeout 60s;
#클라이언트 요청 헤더를 읽기위한 버퍼 크기 설정
client_header_buffer_size 1k;
client_header_timeout 60s;
#클라이언트가 보낸 요청 본문의 최대 사이즈
client_max_body_size 1m;
server {
listen 80;
location / {
root html;
index index.html index.htm;
}
}
}
- Core 모듈 설정 : 위 예제의 worker_processes와 같은 지시자 설정 파일 최상단에 위치하면서 nginx의 기본적인 동작 방식을 정의한다.
- http 모듈 블록 : 밑에서 설명할 server, location의 루트 블록이라고 할 수 있고, 여기서 설정된 값을 하위 블록들은 상속한다. http 블록은 여러개를 사용할 수 있지만 관리상의 이슈로 한번만 정의하는 것을 권장한다. http, server, location 블록은 계층구조를 가지고 있고 많은 지시어가 각각의 블록에서 동시에 사용될 수 있는데, http의 내용은 server의 기본값이 되고, server의 지시어는 location의 기본값이 된다. 그리고 하위의 블록에서 선언된 지시어는 상위의 선언을 무시하고 적용된다.
- server 블록 : server 블록은 하나의 웹사이트를 선언하는데 사용된다. 가상 호스팅(vhost)의 개념이다.
- location 블록 : location 블록은 server 블록 안에 정의하며 특정 URL을 처리하는 방법을 정의한다. 예를 들어 uri path마다 다르게 요청을 처리하고 싶을 때 해당 블록 내에 정의한다.
- events 블록 : nginx는 event driven을 메커니즘으로 동작하는데, 이 event driven 동작 방식에 대한 설정을 다룬다.
nginx.conf
"user"
user의 값이 root로 되어 있다면 일반 계정으로 변경하는 것이 좋다. nginx는 마스터 프로세스와 워커 프로세스로 동작하고, 워커 프로세스가 실질적인 웹서버의 역할을 수행하는데 user 지시어는 워커프로세스의 권한을 지정한다. 만약 user의 값이 root로 되어 있다면 워커 프로세스를 root의 권한으로 동작하게 되고, 워커 프로세스를 악의적으로 사용자가 제어하게 된다면 해당 머신을 루트 사용자의 권한으로 원격제어하게 되는 셈이기 때문에 보안상 위험하다.
user 설정의 값으로는 대표성있는 이름(nginx)로 사용하고, 이 계정은 일반 유저의 권한으로 쉘에 접속할 수 없어야 안전하다.
> useradd --shell /sbin/nologin www-data
"worker_process"
worker_process는 워커 프로세스를 몇개 생성할 것인지를 지정하는 지시어이다. 이 값이 1이라면 모든 요청을 하나의 프로세스로 실행하겠다는 뜻인데, 여러개의 CPU 코어가 있는 시스템이라면 CPU 코어수만큼 지정하길 권장한다.
"events.worker_connections"
이 값은 몇개의 접속을 동시에 처리할 것인가를 지정하는 값이다. 이 값과 worker_process의 값을 조합해 동시에 최대로 처리할 수 있는 커넥션의 양을 산출할 수 있다.(worker_process*worker_connections)
"http.incloud"
가상 호스트 설정이나, 반복되는 설정들을 파일로 저장해놓고, incloude를 통해 불러올 수 있다.
"http.log_format"
access 로그에 남길 로그 포맷을 지정한다. 보통 어떠한 장애가 났을 때, 가장 먼저보는 것이 로그 파일이기 때문에 디버깅하기 위해 유용한 값들을 로그에 남겨두는 것이 중요하다. 특히나, 여러 프록시 서버를 지나오는 서버 구성인 경우에는 x-forwarded-ip 등을 지정하면 지나온 프록시들의 아이피들을 할 수 있다.
"http.access_log"
access로그를 어느 디렉토리에 남길지 설정한다.
"http.keepalive_timeout"
소켓을 끊지 않고 얼마나 유지할지에 대한 설정이다. 자세한 내용은 keepalive 개념을 확인하자.
"http.server_tokens"
nginx의 버전을 숨길 것인가에 대한 옵션이다. 보안상 활성화하는 것을 권장한다.
기타 설정들은 위 예제 파일에 주석으로 달아놓았다.
다음은 실제 프록시 설정이 들어가는 server 블록 설정을 다루어 보자.
server {
listen 80;
server_name levi.local.com;
access_log logs/access.log;
error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_pass http://app;
}
}
upstream app {
server localhost:8080;
}
위 설정은 http 블록 하위로 들어가게 된다. 크게 어려운 설정은 없고, "levi.local.com:80/"으로 요청이 들어오면 upstream(요청받는 서버)으로 요청을 리버스 프록시 한다라는 뜻이다. 실제로 앱하나를 띄워보고 프록시 되는지 확인해보자.
> curl levi.local.com/api
new api ! - 7
위처럼 응답이 잘오는 것을 볼 수 있다. 그런데 사실 server 블록이 하나일때는 server_name에 적혀있는 도메인으로 오지않아도 응답을 준다. server_name이 진짜 도메인네임을 구분하기 위한 server_name으로 사용되기 위해서는 listen 포트가 같은 server 블록이 두개 이상 존재할때 이다. 아래 예제를 보자.
server {
listen 80;
server_name levi.local.com;
#access_log logs/access.log;
#error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_pass http://app;
}
}
upstream app {
server localhost:8080;
}
server {
listen 80;
server_name local.yoon.com;
#access_log logs/access.log;
#error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_pass http://app2;
}
}
upstream app2 {
server localhost:7070;
}
위와 같이 설정하고, 각 도메인을 분리해서 요청을 보내보자. server_name으로 분리되어 요청이 프록시 될것이다.
Nginx cache
마지막으로 location 블록에 대한 설정중 nginx cache에 설정에 대해 주로 다루어보자.
- /path/to/cache ==> 캐시 내용이 local disk 에 저장될 위치
- levels=1:2 ==> directory depth 와 사용할 name 길이.
- ex ) /data/nginx/cache/c/29/b7f54b2df7773722d382f4809d65029c
- keys_zone ==> 캐시 키로 사용될 이름과 크기. 1MB 는 약 8천개의 이름 저장. 10MB면 8만개.
- max_size ==> 캐시 파일 크기의 maximum. size 가 over 되면 가장 오래전에 사용한 데이터 부터 삭제한다.
- inactive ==> access 되지 않았을 경우 얼마 뒤에 삭제 할 것인가.
- use_temp_path ==> 설정된 path 외에 임시 저장 폴더를 따로 사용할 것인가? 따로 설정하지 않는 것이 좋다.
- proxy_cache <namev> ==> 캐시로 사용할 메모리 zone 이름.
- proxy_cache_methods ==> request method를 정의한다. default : GET, HEAD
- proxy_cache_key ==> 캐시 할 때 사용할 이름.
- proxy_cache_bypass ==> 예를 들어 "http://www.example.com/?nocache=true" 이러한 요청이 왔을 때 캐싱되지 않은 response 를 보낸다. 이 설정이 없다면 nocache 아규먼트는 동작하지 않는다. http_pragma==> 헤더 Pragma:no-cache
- proxy_cache_lock ==> 활성화 시키면 한 번에 단 하나의 요청만 proxy server로 전달되어 proxy_cache_key 에 따라 캐싱된 데이터로 사용합니다. 다른 request 들은 캐싱된 데이터를 사용하거나 proxy_cache_lock_timeout의 설정에 따라 proxy server로 전달 될 수 있습니다.
- proxy_cache_valid ==> 기본적으로 캐싱할 response code 와 시간을 정의한다.
예제 설정으로는 아래와 같다.
proxy_cache_path /usr/local/etc/nginx/cache levels=1:2 keys_zone=myapp:10m max_size=10g inactive=60s use_temp_path=off;
server {
listen 80;
server_name levi.local.com;
access_log logs/access.log;
error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_cache myapp;
proxy_cache_methods GET;
proxy_cache_key "$uri$is_args$args";
proxy_cache_bypass $cookie_nocache $arg_nocache $http_pragma;
proxy_ignore_headers Expires Cache-Control Set-Cookie;
#proxy_cache_lock on;
#200ok인 응답을 1분동안 캐싱
proxy_cache_valid 200 1m;
proxy_pass http://app;
}
}
upstream app {
server localhost:8080;
}
실제로 캐싱이 잘되는지 요청을 보내보고 실제 캐싱이 저장되는 디렉토리로 들어가보자.
> cd /usr/local/etc/nginx/cache
> ls
8
> cd 8
> ls
68
> cd 68
> ls
5d198634e5fa00f3cf3a478fcdf57688
> vi 5d198634e5fa00f3cf3a478fcdf57688
^E^@^@^@^@^@^@^@û½@_^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ÿÿÿÿÿÿÿÿ¿½@_^@^@^@^@#Y|^V^@^@d^Aè^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
KEY: /api?arg=args
HTTP/1.1 200 ^M
Content-Type: text/html;charset=UTF-8^M
Content-Length: 13^M
Date: Sat, 22 Aug 2020 06:39:59 GMT^M
Connection: close^M
^M
new api ! - 5
응답이 잘 캐싱된것을 볼수 있다. 그리고 대략 1분후에는 해당 캐싱 파일 지워져있다.
여기까지 간단하게 Nginx 설치 및 사용방법에 대해 다루어보았다. 맘 같아선 캐싱에 대해 더 자세히 다루고 싶었다. 대규모 웹사이트 같은 경우는 정말 장비를 늘리는 것으로는 트래픽을 받는데 한계가 있기 때문에 사실상 캐싱 싸움이 될것이기 때문이다. 이번 포스팅에서는 Nginx에 대해 맛보기 정도만 하였지만, 다음 시간에는 조금더 딥한 내용까지 다루어 볼 계획이다.
참조
nginx cache
1. cache dir 설정 proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=cache:2m 2. cache 사용 설정 server { listen 80; server_name cached.test.co.kr; access_log /var/log/nginx/cache-access.log c..
semode.tistory.com
'인프라 > Web Server & WAS' 카테고리의 다른 글
| Web - Http Header의 뜻 (0) | 2019.04.03 |
|---|---|
| 웹 취약성 검사 대비하기 ! (2) | 2018.10.26 |
| tomcat WAS에 spring(spring boot) 여러개의 war파일 배포(여러개 context) (0) | 2018.09.12 |
UNIX/LINUX : 용량 확인 명령어 (df/du)
unix/linux Unix/Linux 디스크 용량 확인 (df/du) 디스크 용량을 확인하는 명령어들이다. df : 디스크의 남은 용량을 확인 df -k : 킬로바이트 단위로 현재 남은 용량을 확인 df -m : 메가바이트 단위로 남은 �
ra2kstar.tistory.com
디스크의 남은 용량 확인
- df -k : 킬로바이트 단위로 현재 남은 용량을 확인
- df -m : 메가바이트 단위로 남은 용량을 왁인
- df -h : 보기 좋게 보여줌
- df . : 현재 디렉토리가 포함된 파티션의 남은 용량을 확인
> df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1s1 466Gi 10Gi 379Gi 3% 487648 4881965192 0% /
devfs 190Ki 190Ki 0Bi 100% 659 0 100% /dev
/dev/disk1s2 466Gi 73Gi 379Gi 17% 1142296 4881310544 0% /System/Volumes/Data
/dev/disk1s5 466Gi 2.0Gi 379Gi 1% 2 4882452838 0% /private/var/vm
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /System/Volumes/Data/home
현재 디렉토리의 용량 확인
- du -a : 현재 디렉토리의 사용량을 파일단위 출력
- du -s : 총 사용량을 확인
- du -h : 보기 좋게 바꿔줌
- du -sh * : 한단계 서브디렉토리 기준으로 보여준다.
> du -sh *
4.0K Dockerfile
4.0K HELP.md
12K README.md
34M build
4.0K build.gradle
60K gradle
8.0K gradlew
4.0K gradlew.bat
284K kube-logging
48K kube-resource
4.0K kube-sample.iml
24K nginx
4.0K settings.gradle
4.0K src
'인프라 > 운영체제' 카테고리의 다른 글
| 운영체제 - 상호배제와 동기화(뮤텍스,TAS,세마포어,모니터) (0) | 2019.07.28 |
|---|---|
| 운영체제 - 병행 프로세스란? (0) | 2019.07.28 |
| 운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드) (1) | 2019.07.27 |
| 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching (0) | 2019.07.27 |
| 운영체제 - 컴퓨터 하드웨어의 구성(CPU,RAM 등) (0) | 2019.07.22 |

'Search-Engine > Elasticsearch&Solr' 카테고리의 다른 글

그래들 프로젝트를 사용중인데, 간혹 idea에서 "Could not initialize class org.codehaus.groovy.runtime.InvokerHelper"라는 에러 메시지가 뜨는 경우가 있다. 여러가지 요인이 있을 수 있지만, 필자가 저 에러를 보았던 순간은 jdk 1.8에서 jdk14 버전으로 올리면서 났던 에러 메시지 인데, 이유는 gradle version이 jdk14를 지원하지 못하는 낮은 버전이었기 때문이다.
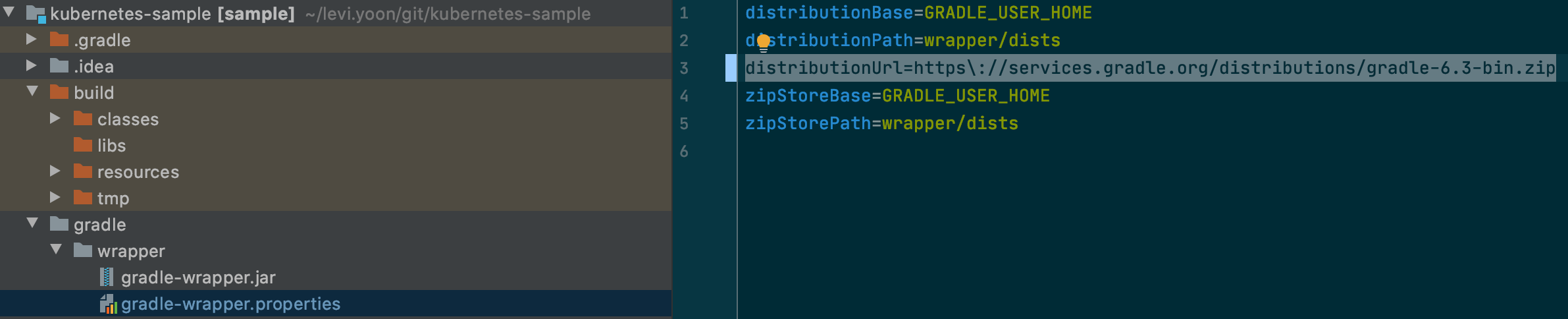
그래서, 프로젝트 디렉토리중 "gradle/wrapper/gradle-wrapper.properties"에서 gradle 버전을 올려주어서 해결하였다.(5.x -> 6,3)
'Web > Gradle' 카테고리의 다른 글
| Gradle - 캐시된 dependencies 라이브러리 삭제하기 (0) | 2020.06.23 |
|---|---|
| Gradle - Gradle 간단히 Task 작성하는 방법 (0) | 2019.10.21 |
| Gradle - Gradle로 자바 프로젝트 만들기 (0) | 2019.10.20 |
| Gradle - Gradle의 기본 (0) | 2019.10.20 |

이번에 다루어볼 내용은 몽고디비에서 데이터를 백업하고 복구하는 방법이다.
백업하기(덤프, dump)
몽고디비가 설치되어 있다면, mongodump라는 명령어로 몽고디비 데이터를 백업할 수 있다.
> mongodump --host 127.0.0.1 --port 27017
위 명령으로 데이터를 백업한다면, 현재 디렉토리에 /dump 디렉토리가 생기고 이 디렉토리 밑에 데이터가 복구되어 있다.(DB 별로 폴더가 생겨있고, 그 폴더안에 BSON으로 데이터가 백업되어 있다.)
> mongodump --out ~/mongo_backup --host 127.0.0.1 --port 27017
--out 옵션으로 데이터 백업의 디렉토리 위치를 정해줄 수 있다.
> mongodump --out <dump data path> --host 127.0.0.1 --port 27017 -u <username> -p <password>
username/password로 인증이 필요하다면, 위 명령어로 백업이 가능하다.
> mongodump --out <dump data path> --host 127.0.0.1 --port 27017 -u <username> -p <password> --db <덤프할 db명>
만약 몽고디비에서 특정 데이터베이스만 백업하고 싶다면, 위처럼 --db 옵션을 이용하면 된다.
> mongodump --out <dump data path> --host <dbhost> --port 27017 -u <username> -p <password> --db <dbname> --collection <collectionName>
특정 컬렉션 단위까지 세분화하여 백업하려면 --collection 옵션을 이용한다. 만약 mongodump&mongorestore에서 "error connecting to db server: server returned error on SASL authentication step:Authentication failed" 에러가 났다면, 아래와 같이 옵션하나를 넣어준다.
--authenticationDatabase admin
복구하기(restore)
다음은 위에서 덤프한 데이터를 복구하는 방법이다. 복구는 mongorestore라는 명령어를 이용한다.
> mongorestore --host 127.0.0.1 --port 27017 \
-u <username> -p <password> --drop <drop db name> \
--db <복구할 db name> <복구할 덤프데이터가 있는 디렉토리>
--drop 옵션은 복구전에 드랍시킬 데이터베이스 명을 입력하면 된다.(복구 전 원래 데이터베이스를 드랍시키고 백업 데이터로 새로 복구하는 것이다.) 위 명령을 간단하게 작성해보면 아래와 같다.
> mongorestore --host 127.0.0.1 --port 27017 --db local /mongo_backup/local
특정 데이터베이스를 복구하고 싶다면, 덤프 데이터가 있는 디렉토리에서 특정 데이터베이스의 디렉토리를 명시해야한다. 만약 모든 데이터를 전부다 백업하고 싶다면 아래 명령어를 입력한다.
> mongorestore --host 127.0.0.1 --port 27017 <dump data가 있는 디렉토리>
컬렉션 단위로 리스토어하기 위해서는 --collection 옵션을 사용하며, collectionName.bson까지 백업데이터 경로를 명시해주어야한다.
> mongorestore --host <dbhost> --port 27017 --db <dbname> --collection <collectionName> <data-dump-path/dbname/collection.bson> --drop
ex)
> mongorestore --port 27017 --db test2 --collection rest2 /mydata/restoredata/test/restaurants.bson --drop
여기까지 간단하게 몽고디비 데이터 백업 및 복구에 대해 다루어보았다.
'Database > MongoDB' 카테고리의 다른 글
| DB - MongoDB 맵리듀스(Map Reduce) (0) | 2019.09.21 |
|---|---|
| DB - MongoDB FindAndModify 란? (0) | 2019.09.19 |
| DB - MongoDB OperationFailed Sort operation used more than the maximum 33554432 bytes of Ram. (0) | 2019.09.19 |
| DB - MongoDB Insert Ordered 옵션은? (0) | 2019.09.19 |
| DB - MongoDB Text Search(본문 검색) (0) | 2019.09.16 |