
'동기화'에 해당되는 글 3건
- 2019.07.28 :: 운영체제 - 상호배제와 동기화(뮤텍스,TAS,세마포어,모니터)
- 2019.02.01 :: JAVA - Hashtable, HashMap, ConcurrentHashMap 비교
- 2019.01.04 :: java - synchronized 란? 사용법? 2
2019/07/28 - [운영체제] - 운영체제 - 병행 프로세스란?
운영체제 - 병행 프로세스란?
2019/07/27 - [운영체제] - 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching 프로세스의 개념 프로세스는 다양한 정의가 있다...
coding-start.tistory.com
이전 포스팅에서 병행 프로세스에 대해 간단히 개념을 다루어보았는데, 병행 프로세스에서 꼭 해결해야할 것 중 하나가 공유 자원에 대한 상호배제(동기화)였다. 오늘은 이런 상호배제에 대한 내용을 다루어볼 것이다.
상호배제의 개념
상호배제는 병행 프로세스에서 프로세스 하나가 공유 자원을 사용할 때 다른 프로세스들이 동일한 일을 할 수 없도록 하는 방법이다. 즉, 공유 자원에 있는 데이터에 접근하는 다른 프로세스를 이미 사용중인 프로세스 하나가 해당 데이터에 접근할 수 없게 하는 것을 상호배제(Mutual exclustion,Mutex)라고 한다. 물론 읽기 연산은 공유 데이터에 동시에 접근해도 문제가 발생하지 않지만, 변수나 파일은 프로세스 별로 하나씩 차례로 읽거나 쓰도록 해야한다. 예를 들면 하나의 프로세스가 순차적으로 파일을 읽는 작업을 하는 도중에 다른 프로세스가 파일의 내용을 변경해버리면 읽어오는 값이 예상과 다를 수 있기에 이러한 상황을 제어하는 동기화 작업이 필요한 것이다.
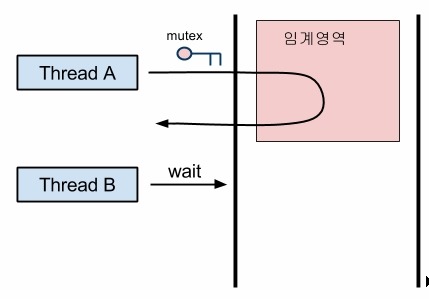
예를 들어 위의 그림에서 Thread A가 파일 쓰기 작업을 진행 중이다. 하지만 작업 도중에 Thread B가 파일을 읽기 위해 접근한다면 Thread B는 읽기 작업을 하지 못하고 대기하게 된다. 여기서 해당 파일(공유자원)을 가지고 주무르는 작업(코드)을 임계영역이라고 하고 먼저 해당 자원을 사용하는 임계코드를 실행중인 Thread A는 Lock(열쇠)을 손에 쥐게 된다. 그리고 그 이후에 Thread B가 접근하면 해당 스레드는 이미 Thread A가 Lock(열쇠)을 손에 쥐고 있기 때문에 임계영역에 접근할 수 없고 대기하게 되며 추후에 Thread A가 Lock(열쇠)를 반환하면 그때서야 Thread B가 임계영역에 진입할 수 있게 되는 것이다.
여기서 특징은 상호배제(Mutex)의 특징이 나온다. 바로 해당 자원에는 한순간 하나의 프로세스만 접근할 수 있기 때문에 Lock은 딱 한 프로세스에게만 쥐어주는 것이다. 또한 공유 자원을 사용하는 프로세스만 다른 프로세스를 차단하는 것을 알 수 있다.
<상호배제의 조건>
- 두 프로세스는 동시에 공유 자원에 진입할 수 없다.
- 프로세스의 속도나 프로세서 수에 영향을 받지 않는다.
- 공유 자원을 사용하는 프로세스만 다른 프로세스를 차단할 수 있다.
- 프로세스가 공유 자원을 사용하려고 너무 오래 기다려서는 안 된다.
여기서 임계영역은 어떤 전역 변수일 수도 있고 입출력을 위한 버퍼가 될 수도 있다. 이러한 임계영역을 이용하여 효과적으로 상호배제를 구현할 수 있는 것이다.
상호배제 방법들
상호배제를 해결하는 다양한 방법이 있다. 아래 표에는 상호배제를 구현하는 방법들을 정리해 놓은 것이다.
| 수준 | 방법 | 종류 |
| 고급 | 소프트웨어로 해결 |
|
| 소프트웨어가 제공 : 프로그래밍 언어와 운영체제 수준에서 제공 |
|
|
| 저급 | 하드웨어로 해결 |
|
모든 것을 다 다루어 보지는 않을 것이다. 몇 가지만 살펴보자.
<데커 알고리즘>
데커 알고리즘은 병행 프로그래밍의 상호배제 문제를 풀 수 있는 첫 번째 해결책으로 알려졌다. 두 프로세스가 동시에 임계영역에 진입하려고 시도하면 순서에 따라 오직 하나만 임계영역에 들어가도록 허용한다. 데커 알고리즘에서 각 프로세스는 플래그를 설정할 수 있고, 다른 프로세스를 확인한 후 플래그를 재설정할 수도 있다. 프로세스가 임계 영역에 진입하고 싶으면 플래그를 설정하고 차례를 기다린다. 즉, 임계 영역에 다른 프로세스가 이미 있으면 해당 프로세스를 종료할 때까지 while 문에서 순환한다. 여기서는 임계 영역 진입, 두 프로세스 간의 순서를 나타내는 turn 변수를 입력했다는 의미로 flag[0] 플래그와 flag[1] 플래그를 사용한다. 간단한 코드로 살펴보자.
======================데커 알고리즘 간단한 코드=========================
flag[0]=false;
flag[1]=false;
turn=0;
===================프로세스 P0 임계 영역 진입 코드=======================
//프로세스 P0의 임계 영역 진입 절차
flag[0]=true; //P0의 임계 영역 진입 표시
while(flag[1]==true){ //P1의 임계 영역 진입 여부 확인
if(turn==1){ //P1이 임계영역에 진입할 차례가 되면
flag[0]=false; //플래그를 재설정하여 P1에 진입 순서 양보
while(turn==1){ //P0이 임계영역에 진입할 차례가 될 때까지
//프로세스 P0의 바쁜 대기
}
flag[0]=true; //P1이 임계 영역에 진입할 차례가 되면 플래그 값 변경
}
}
/*임계 영역 코드*/
turn=1; //임계 영역 코드 수행 이후 P1에게 진입 turn을 양보.
flag[0]=false;
/*나머지 코드 수행부분*/
===================프로세스 P1 임계 영역 진입 코드=======================
//프로세스 P1의 임계 영역 진입 절차
flag[1]=true;
while(flag[0]==true){
if(turn==0){
flag[1]=false;
while(turn==0){
//프로세스 P1의 바쁜 대기
}
flag[1]=true;
}
}
/*임계 영역 코드*/
turn=0; //임계 영역 코드 수행 이후 P0에게 진입 turn을 양보.
flag[1]=false;
/*나머지 코드 수행부분*/
======================데커 알고리즘 간단한 코드=========================
상호배제 문제를 소프트웨어적으로 해결하는 데커 알고리즘의 특징
- 특별한 하드웨어 명령문이 필요 없다.
- 임계 영역 바깥에서 수행 중인 프로세스가 다른 프로세스들이 임계 영역에 들어가려는 것을 막지 않는다.
- 임계 영역에 들어가기를 원하는 프로세서를 무한정 기다리게 하지 않는다.
<TestAndSet(TAS) 명령어>
공유 변수를 수정하는 동안 인터럽트 발생을 억제하여 임계 영역 문제를 간단하게 해결할 수 있지만, 이 방법은 항상 적용할 수 없고 실행 효율이 현저히 떨어진다. 또 소프트웨어적인 해결책은 더 복잡하고 프로세스가 2개 이상일 때는 더 많이 대기할 수 있다. 메모리 영역의 값에 대해 검사와 수정을 원자적으로 수행할 수 있는 하드웨어 명령이 TAS를 이용하여 간단한 방법으로 임계 영역 문제를 해결할 수 있다.
//target을 검사하고 target 값을 true로 설정
boolean TestAndSet(boolean *target){
boolean temp=*target;
*target=true;
return temp;
}
//전역변수 영역(프로세스들의 공유변수들)
boolean waiting[n]; //배열을 선언함으로써 프로세스가 2개 이상와서 대기할 수 있도록 한다.
boolean lock=false;
int j; //0..n-1
boolean key;
do{ //프로세스 Pi의 진입 영역
waiting[i]=true
key=true;
while(waiting[i]&&key){
key=TestAndSet(&lock);
}
waiting[i]=false;
/*임계영역*/
/*탈출영역*/
j=(i+1)%n;
while((j!=i)&&!waiting[j]){ //대기 중인 프로세스를 찾음
j=(j+1)%n;
}
if(j==i){ //대기 중인 프로세스가 없다면
lock=false; //다른 프로세스의 진입 허용
}else{ //대기 중인 프로세스가 있으면 다음 순서로 임계 영역에 진입
waiting[j]=false; //Pj가 임계 영역에 진입할 수 있도록
}
//나머지 영역
}while(true);
프로세스 Pi의 진입 영역에서 waiting[i]가 true이므로 Pi는 임계 영역에 들어가려고 시도한다. 처음에 lock을 false로 초기화했다. 그러므로 임계 영역에 들어가는 첫 번째 Pi 프로세스는 TestAndSet(&lock)으로 key가 false가 되어 while문을 벗어 나게 되어 임계 영역을 진행한다. lock은 TestAndSet(&lock)으로 true가 되므로 다른 프로세스의 임계 영역 진입 코드의 while 문에서는 key가 true이기에 계속 while문에서 대기하게 된다. Pi가 임계 영역에 들어가기 전에 waiting[i]는 false로 설정하고 임계 영역으로 진입한다. 여기서 중요한 것은 lock이 true가 되어 다른 프로세스의 임계 영역 진입 코드의 while문에서 key가 true로 계속 반환되어 while 문에 머물고 있는 것을 기억해야한다.
Pi가 임계 영역을 떠날 때는 대기 프로세스 중에서 다음으로 진입할 수 있는 프로세스를 선택해야 한다. j=(i+1)%n; 코드로 차례가 높은 프로세스를 선택한 후 다음 while 문에서 각 프로세스를 검사한다. waiting 배열을 i+1,i+2,...n-1,0 순서로 조사하여 waiting 값이 true인 첫 번째 프로세스가 임계 영역으로 진입할 다음 프로세스가 된다.(임계 영역에 진입하기 위해 대기하는 프로세스는 임계 영역 초반 waiting[i]가 true가 된 상태로 while 문에서 대기중) 만약 대기 중인 프로세스가 없다면 lock을 false로 해제하고, 다음 프로세스가 Pj이면 임계 영역에 진입할 수 있도록 Pi는 waiting[j]를 false로 변경한다.(waiting[j]를 false로 변경하면 임계 영역을 진입하기 위해 대기중인 Pj가 while(waiting[j]&&key)에서 벗어 나게 되고 임계영역으로 진입한다.)
TestAndSet 명령어의 장단점
| 장점 |
사용자 수준에서 가능하다.
|
| 단점 |
-바쁜 대기 발생
-기아 상태 발생 : 프로세스가 임계 영역을 떠날 때 프로세스 하나 이상을 대기하는 경우가 가능하다. -교착 상태 발생 : 플래그는 우선순위가 낮은 프로세스가 재설정할 수 있지만, 우선순위가 높은 프로세스가 선점한다. 따라서 우선순위가 낮은 프로세스는 lock을 가지고, 우선순위가 높은 프로세스가 이것을 얻으려 시도할 때 높은 우선순위 프로세스는 무한정 바쁜 대기가 될 것이다. |
<세모포어,semaphore>
앞서 제시한 상호배제의 해결 방법들은 좀 더 복잡한 문제에서는 일반화하기 어렵다. 또 프로세스가 임계 영역에 진입할 수 없을 때는 진입 조건이 true가 될 때까지 반복적으로 조사하고 바쁜 대기를 하게 되어 프로세스를 낭비한다. 진입 조건을 반복 조사하지 않고 true일 때 프로세스 상태를 확인한다면 프로세서 사이클을 낭비하지 않을 것이다. 다익스트라가 제안한 세모포어라는 동기화 도구는 상호배제 이외에도 다양한 연산의 순서도 제공한다.
세모포어는 값이 음이 아닌 정수인 플래그 변수이다.(음수 값을 가질 수 있는 세마포어는 음수 값을 할당하여 대기 중인 프로세스 갯수를 알고 처리하는 방법이 있다고는 하는데..음수가 되는 순간 해당 프로세스는 대기큐에 넣은 후에 S가 0보다 커지는 순간 대기큐에서 가져와 임계영역 코드를 수행시키는 원리.) 또한 P와 V 연산과 관련되어 있고 세마포어를 의미하는 S라는 변수를 갖는다. 임계 영역에 진입하는 프로세스는 P연산(wait)을 수행하여 S>=0이라면 S값을 하나 감소시키고 임계영역에 들어가고 만약 S<=0이라면 S값을 하나 감소시키고(S값이 음수로 된다) 대기큐로 들어간다.(지속적으로 S>=0일때가지 반복문을 도는 것이 아니라 대기 큐에 들어가 멈춰있는 상태-sleep가 된다. 바쁜 대기 문제 해결) 그리고 임계영역의 코드를 모두 수행하면 V연산(signal)로 S값을 하나 증가시키고 S값이 0보다 커지면 대기큐에서 sleep 중인 프로세스를 깨우는 행동을 하게 된다.
<Info>
음수 값을 가질 수 없는 세마포어는 뮤텍스와 같이 바쁜대기가 발생한다. 하지만 음수를 가지는 세마포어는 대기큐에 프로세스를 중단시킨 상태로 넣어놓으니 바쁜 대기가 발생하지 않는다.
바쁜 대기 : 자원을 사용할 수 있는 상태인지 반복해서 체크
P,V 연산은 운영체제가 실행하고, 임의의 프로세스가 시스템 호출을 하는 것이다.
P(S) : wait(S){
S -> count--;
if(S -> count < 0) {
add this process to S -> queue; //프로세스를 준비 큐에 추가
block(); //프로세스 중단(일시정지)
}
}
V(S) : signal(S){
S -> count++;
if(S -> count > 0){
remove a process P from S -> queue; // 준비 큐에서 P 프로세스 제거
wakeup(P); //신호를 보내 프로세스를 실행
}
}
P와 V 연산에 있는 세마포어 S의 정수 값 변경은 개별적으로 실행하고, 누군가가 이 연산을 수행하고 있다면 다른 프로세스는 해당 연산을 수행할 수 없다. 즉, P,V 연산이 다른 프로세스들이 동시에 할 수 없도록 조정해야한다. 여기서 일반 상호배제(뮤텍스)와는 조금 다른 것이 S값을 1보다 큰 값으로 초기화하여 여러 프로세스가 동시에 임계 영역을 진입하게 할 수 있다는 것이다.(S값만큼 공유 영역을 만들어서 각각의 공유 영역에 서로 다른 프로세스를 통과시킬 수 있다.)
즉, S가 1로 초기화된다면 바이너리 세마포어, S가 1보다 크다면 계수형 세마포어가 된다. 밑의 그림은 계수형 세마포어가 된다.
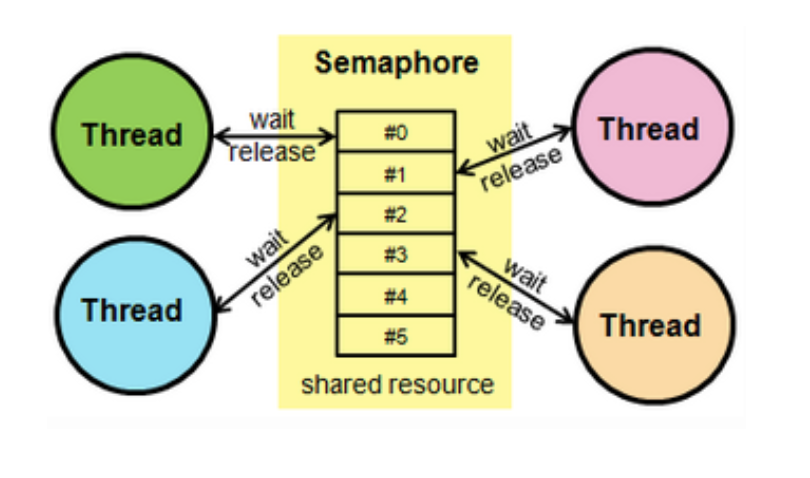
그렇다면 세마포어와 뮤텍스의 차이점을 무엇일까? 기본적인 차이점을 세마포어는 시그널링 메커니즘이라는 것이다. 즉, 프로세스는 wait() 및 signal() 작업을 수행하여 자원 획득 또는 해제여부를 나타낸다. 뮤텍스는 잠금 메커니즘이며, 프로세는 Lock을 획득해야한다. 아래는 세마포어와 뮤텍스의 차이점을 정리해 놓은 표이다.
| 세마포어 | 뮤텍스 |
| 세마포어는 시그널링 메커니즘이다. | 뮤텍스는 잠금 메커니즘이다. |
| 세마포어는 정수 변수이다. | 뮤텍스는 Object이다. |
| 세마포어는 여러 프로세스가 여러 유한한 자원에 액세스할 수 있게 한다. | 뮤텍스는 여러 프로세스가 단일 리소스에 액세스할 수 있지만 동시에 수행할 수 없게 한다. |
| 세마포어 값은 자원을 얻거나 해제하는 프로세스에 의해 변경 될 수 있다. | 뮤텍스 Lock은 반드시 획득한 프로세스에 의해서만 해제된다. |
| 세마포어는 계수형(count) 세마포어와 바이너리 세마포어로 분류된다. | 더 이상의 분류는 없다. |
| 세마포어 값은 wait() 및 signal() 연산을 사용하여 수정된다. | 리소스를 요청하거나 해제하는 프로세스에 의해 Lock&Unlock이 된다. |
| 모든 리소스가 사용 중이면 리소스를 요청하는 프로세스는 wait() 작업을 수행하고 대기큐에 들어가 있으면서 세마포어 값이 1이상이 될때 다른 프로세스에 의해 wakeup한다. | Lock이 걸려있으면 Lock의 소유 프로세스가 잠금을 풀때까지 프로세스가 대기하고 있는다(바쁜 대기) |
<모니터>
세마포어는 상호배제와 프로세스 사이를 조정하는 유연성 있고 강력한 도구이지만 wait&signal 연산 순서를 바꿔 실행하거나 둘 중 하나 이상을 생략하면 상호배제를 위반하거나 교착 상태가 발생한다. wait과 signal 연산이 프로그램 전체에 퍼져 있고 이들 연산이 각 세마포어에 주는 영향을 전체적으로 파악하기가 쉽지 않기에 세마포어를 잘못 사용하면 여러 가지 오류가 쉽게 발생하여 프로그램을 작성하기가 어렵다. (즉, 타이밍 문제가 발생할 수 있다.)모니터는 이러한 단점을 극복하려고 등장하였다.
모니터의 개념과 구조
모니터는 프로그래밍 언어 수준에서 제공해준다. 모니터를 사용하여 상호배제를 하는 예제로는 Java 언어가 있다.
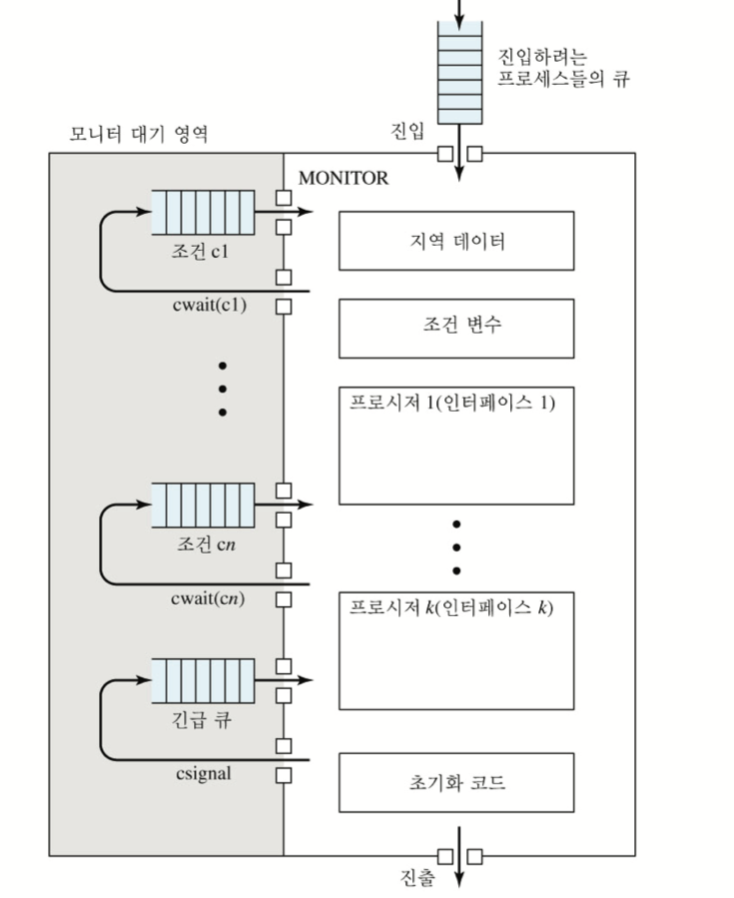
프로세스들은 모니터의 프로시저를 호출하여 모니터 안에 진입한 후 지역(공유) 데이터에 접근할 수 있다. 무엇보다 언제나 한 번에 프로세스 하나만 모니터에 진입할 수 있도록 제한하여 상호배제를 실현한다는 것이 중요하다. 만약 다른 프로세스가 모니터를 점유하고 있으면 프로세스는 외부의 모니터 준비 큐에서 진입을 기다리게 되어 상호배제를 실현한다. 위에서 초기화 코드는 모니터를 생성할 때 한번 사용된다.
또한 중요한 개념중 하나가 조건 변수이다. 특정 조건이 부합하지 않아 모니터 실행 도중 cwait(c1)을 호출한 프로세스는 모니터 내부의 조건 c1 준비큐에 들어가 대기한다. 그리고 새로운 프로세스가 모니터 안에서 수행을 진행하고 해당 프로세스가 c1.signal을 호출하면 c1 대기 큐에 있던 프로세스가 중단되어 있다 다시 실행하러 들어온다. 즉, 단순히 세마포어처럼 signal 연산을 보내는 것이 아니라 특정 조건 대기큐에 대한 signal을 보내 작업을 시작시키는 것이다.
예를 들어 프로세스 하나가 모니터 내부에서 임계영역 코드를 수행하고 c1에 시그널을 보내면 모니터 내부에 있는 c1 준비큐에서 프로세스 하나가 나와 임계영역 코드에 진입하고, 만약 조건 signal을 보내지 않고 빠져 나온다면 외부에 있는 큐중에 한 프로세스를 꺼내어 임계영역에 진입시킨다. 물론 c1 시그널을 보냈는 데 c1에 대기하고 있는 프로세스가 없다면 아무런 효과가 없어 외부에 있는 대기 큐에서 프로세스를 꺼내온다.
Java의 wait(),notify(),notifyAll()이 모니터를 사용하기 위한 조건 변수라고 볼 수 있다. 모니터 내부에서 wait()을 호출하면 모니터 내부에 있는 WaitSet에 들어가 중단된 상태로 대기하고 있는 상태가 되는 것이고 누군가가 notify(),notifyAll()을 호출하면 모니터 내부에 있는 WaitSet에 있는 프로세스중 하나를 실행상태로 만들어주는 것이다. 물론 synchronized가 걸려 모니터 내부에 들어오지 못한 프로세스(스레드)들은 EntrySet이라는 외부 준비큐에 들어가 있는 상태가 되는 것이다.

-참조
Difference Between Semaphore and Mutex (with Comaprison Chart) - Tech Differences
The basic difference between semaphore and mutex is that semaphore is a signalling mechanism i.e. processes perform wait() and signal() operation to indicate whether they are acquiring or releasing the resource, while Mutex is locking mechanism, the proces
techdifferences.com
Difference Between Semaphore and Monitor in OS (with Comparison Chart) - Tech Differences
Semaphore and Monitor both allow processes to access the shared resources in mutual exclusion. Both are the process synchronization tool.
techdifferences.com
'인프라 > 운영체제' 카테고리의 다른 글
| 운영체제 - 디스크 사용량 및 정보 확인 (0) | 2020.08.22 |
|---|---|
| 운영체제 - 병행 프로세스란? (0) | 2019.07.28 |
| 운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드) (1) | 2019.07.27 |
| 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching (0) | 2019.07.27 |
| 운영체제 - 컴퓨터 하드웨어의 구성(CPU,RAM 등) (0) | 2019.07.22 |
Hashtable, HashMap, ConcurrentHashMap 비교
1. Hashtable, HashMap, ConcurrentHashMap
위에 나열된 클래스들은 Map 인터페이스를 구현한 콜렉션들입니다. 이 콜렉션들은 비슷한 역할을 하는것 같으면서도 다르게 구현되어 있습니다. 기본적으로 Map 인터페이스를 구축한다면 <key, value>구조를 가지게 됩니다. 하나씩 살펴봅시다.
2. Hashtable
Hashtable은 put, get과 같은 주요 메소드에 synchronized 키워드가 선언 되어 있습니다. 또한 key, value에 null을 허용하지 않습니다.
3. HashMap
HashMap은 주요 메소드에 synchronized 키워드가 없습니다. 또한 Hashtable과 다르게 key, value에 null을 입력할 수 있습니다.
하지만 HashMap도
"Map<String,Integer> map = Collections.synchronizedMap(new HashMap<String,Integer>());"
와 같이 선언하면 Thread-safe한 맵으로 사용가능하다.
4. ConcurrentHashMap
HashMap을 thread-safe 하도록 만든 클래스가 ConcurrentHashMap입니다. 하지만 HashMap과는 다르게 key, value에 null을 허용하지 않습니다. 또한 putIfAbsent라는 메소드를 가지고 있습니다.
5. Common Methods
위의 세종류의 클래스들은 put, get 메소드 외에도 기본적인 메소드들을 구현하고 있습니다. 대표적인 몇가지의 메소드들만 알아봅시다.
- clear()
해당 콜렉션의 데이터를 초기화 합니다.
- containsKey(key)
해당 콜렉션에 입력 받은 key를 가지고 있는지 체크합니다.
- containsValue(value)
해당 콜렉션에 입력 받은 value를 가지고 있는지 체크합니다.
- remove(key)
해당 콜렉션에 입력 받은 key의 데이터(key도 포함)를 제거합니다.
- isEmpty()
해당 콜렉션이 비어 있는지 체크합니다.
- size()
해당 콜렉션의 엔트리(Entry) 또는 세그먼트(Segment) 사이즈를 반환합니다.
6. In Multi Threads(ConcurrentModificationException...)
HashMap에 대한 부분은 동기화가 이루어지지 않습니다. 하지만 HashMap을 쓰더라도 synchronized 블록을 선언해 주면 정상으로 동작을 합니다. 따라서 동기화 이슈가 있다면 일반적인 HashMap을 쓰지 말거나 쓰더라도 동기화를 보장하는 HashMap 콜렉션 또는 synchronized 키워드를 이용해 동기화 처리를 반드시 해주는 것이 좋아보입니다. 혹은 Thread-safe한 ConcurrentHashMap을 쓰시는 것을 권장합니다.
만약 하나의 스레드가 Map에 접근하여 요소들을 삭제,수정,삽입 등을 작업하고 있는 도중에 다른 스레드가 해당 Map에 접근 해 무엇인가를 작업한다면 동기화 문제가 발생할 수 있습니다.
밑의 소스에서 일반 HashMap을 사용한다면 위에서 말한 예외가 발생할 경우가 생깁니다. 이 경우를 ConcurrentHashMap을 사용해 Thread-safe한 코드로 변경하였습니다.
@Service
public class SessionService {
private static final Logger log = LoggerFactory.getLogger(SessionService.class);
/*Map<String, SessionInfo> sessionMap = new HashMap<>();*/
/*
*
* 설명 : HashMap을 썼을 경우, ConcurrentModificationException 발생(Thread간의 동기화문제)
* HashMap -> ConcurrentHashMap
*/
Map<String, SessionInfo> sessionMap = new ConcurrentHashMap<>();
Boolean runFlag = true;
private Thread itsThread = null;
@Value("${app.session.expire.sec}")
private int expiredSec;
@PostConstruct
private void dropExptiredSession() {
itsThread = new Thread(() -> {
try {
while (runFlag) {
/*
* yeoseong_yoon
* 설명 : 바로 밑에 메소드 주석 풀면 10초마다 스레드가 돌아가면서 세션만료시간이 된
* 채팅세션을 remove한다.
*/
checkExpiredSession();
Thread.sleep(10000);
}
} catch (InterruptedException e) {
log.warn("thread interrupt occured", e);
}
});
itsThread.start();
}
@PreDestroy
private void stop() {
runFlag = false;
itsThread.interrupt();
}
private void checkExpiredSession() {
for (Map.Entry entry : sessionMap.entrySet()) {
String sessionKey = (String) entry.getKey();
SessionInfo sessionInfo = (SessionInfo) entry.getValue();
long duration = TimeUtils.getCurrentSec() - sessionInfo.getLastTimeSec();
if (duration > expiredSec) {
sessionMap.remove(sessionKey);
log.info("session time out, sessionkey={}", sessionKey);
}
}
}
}
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - JDK1.7(JAVA 7) 특징 try-with-resource 등 (0) | 2019.02.11 |
|---|---|
| Mac OS - Eclipse & Lombok(롬복 사용방법) (2) | 2019.02.02 |
| 객체지향 design pattern - composite pattern 예제 (0) | 2019.01.29 |
| 객체지향 design pattern - strategy pattern 예제 (0) | 2019.01.04 |
| java - synchronized 란? 사용법? (2) | 2019.01.04 |
java - synchronized 란? 사용법?
멀티스레드를 잘 사용하면 프로그램적으로 좋은 성능을 낼 수 있지만,
멀티스레드 환경에서 반드시 고려해야할 점인 스레드간 동기화라는 문제는 꼭 해결해야합니다.
예를 들어 스레드간 서로 공유하고 수정할 수 있는 data가 있는데 스레드간 동기화가 되지 않은 상태에서
멀티스레드 프로그램을 돌리면, data의 안정성과 신뢰성을 보장할 수 없습니다.
따라서 data의 thread-safe 를 하기 위해 자바에서는 synchronized 키워드를 제공해 스레드간 동기화를 시켜 data의 thread-safe를 가능케합니다.
자바에서 지원하느 Synchronized 키워드는 여러개의 스레드가 한개의 자원을 사용하고자 할 때,
현재 데이터를 사용하고 있는 해당 스레드를 제외하고 나머지 스레드들은 데이터에 접근 할 수 없도록 막는 개념입니다.
Synchronized 키워드는 변수와 함수에 사용해서 동기화 할 수 있습니다.
하지만 Synchronized 키워드를 너무 남발하면 오히려 프로그램 성능저하를 일으킬 수 있습니다.
그 이윤 Synchronized 키워드를 사용하면 자바 내부적으로 메서드나 변수에 동기화를 하기 위해 block과 unblock을 처리하게 되는데
이런 처리들이 만약 너무 많아지게 되면 오히려 프로그램 성능저하를 일으킬수 있는 것입니다.
(block 과 unblock도 프로그램 내부적으로 어느정도 공수가 들어가는 작업입니다.)
따라서 적재적소에 Synchronized 키워드를 사용하는 것이 중요합니다!
// 1. 메서드에서 사용하는 경우
public synchronized void method(){// 코드}
// 2. 객체 변수에 사용하는 경우(block문)
private Object obj = new Object();
public void exampleMethod(){ synchronized(obj){//코드 }}
-
public class ThreadSynchronizedTest {
-
-
// TODO Auto-generated method stub
-
Task task = new Task();
-
</p><p>
-
t1.setName("t1-Thread");
-
t2.setName("t2-Thread");
-
-
t1.start();
-
t2.start();
-
}
-
-
}
-
-
class Account{
-
int balance = 1000;
-
-
public void withDraw(int money){
-
-
if(balance >= money){
-
try{
-
balance -= money;
-
-
-
}
-
}
-
}
-
-
Account acc = new Account();
-
-
@Override
-
public void run() {
-
while(acc.balance > 0){
-
// 100, 200, 300 중의 한 값을 임의로 선택해서 출금(withDraw)한다.
-
acc.withDraw(money);
-
-
}
-
}
-
}
위 예제에 대한 설명을 하면,
Account 라는 클래스에는 balance 잔액과 이 잔액을 삭감시키는 인출메서드가 있습니다.
지난시간 스레드를 만들때 Runnable 인터페이스를 구현하여 Task를 만들고 이 Task를 Thread 생성시 생성자에 매개변수로 넣으면
우리가 만든 스레드가 Task에 정의되어있는 대로 일을 실행한다고 했습니다.
Runnable을 구현하여 만든 Task에 100,200,300 중 랜덤하게 값을 전달받아 moneny 변수에 할당하고 그 금액만큼 Account 인스턴스의 인출메서드를 호출해
balance (잔액)을 출금시키는 일을 구현해놨습니다.
다음 main 메서드에서 스레드 t1, t2를 만들고 각각의 스레드 이름을 정의합니다.
t1, t2 스레드가 시작하면 잔액이 0이 될 때까지 두 스레드가 경쟁하며 출금시킬 것입니다.
결과화면

결과를 보면 분명 잔액이 0이 될때까지 출금을 하라고 햇는데 잔액이 마이너스가 됬습니다.
여기서 멀티스레드의 문제점이 발견됩니다. balance(잔액) thread-safe가 되지 않았기 때문에 t1 스레드가 잔액을 삭감하기 전에
t2가 balance(잔액)에 접근해 삭감을 해버리고 다시 t1이 slee()에서 깨어나 balance(잔액) 을 삭감해버리기 때문에
잔액이 0 이하의 마이너스 값을 가지게 됩니다.
해결하는 방법은 간단합니다.
공유데이터에 대한 접근과 수정이 이루어지는 메서드에 synchronized 키워드를 리턴타입 앞에 붙여주면 됩니다.
t1스레드가 먼저 공유데이터나 메서드에 점유하고 있는 상태인 경우 block으로 처리하기 때문에 t1 이외의 스레드의 접근을 막습니다.
t1스레드가 작업을 다 끝냈다면 .unblock으로 처리하여 t1 이외의 스레드의 접근을 허락합니다.
synchronized 키워드로 멀티스레드 동기화 처리
-
public class ThreadSynchronizedTest {
-
-
// TODO Auto-generated method stub
-
Task task = new Task();
-
-
t1.setName("t1-Thread");
-
t2.setName("t2-Thread");
-
-
t1.start();
-
t2.start();
-
}
-
-
}
-
-
class Account{
-
int balance = 1000;
-
-
public synchronized void withDraw(int money){
-
-
if(balance >= money){
-
try{
-
balance -= money;
-
-
-
}
-
}
-
}
-
-
Account acc = new Account();
-
-
@Override
-
public void run() {
-
while(acc.balance > 0){
-
// 100, 200, 300 중의 한 값을 임의로 선택해서 출금(withDraw)한다.
-
acc.withDraw(money);
-
-
}
-
}
-
}
결과화면

synchronized 키워드를 사용함으로써 balance 공유데이터에 대한 thread-safe를 시켰기 때문에
데이터나 메서드 점유하고 있는 스레드가 온전히 자신의 작업을 마칠 수 있습니다.
다른 블로그에 좋은 글이 있어서 펌해봅니다
메소드 레벨의 동기화는 해당 인스턴스 자체로 락을 걸어버린다.
자바 동기화 블록은 메소드나 블록 코드에 동기화 영역을 표시하며 자바에서 경합 조건을 피하기 위한 방법으로 쓰인다.
자바 synchronized 키워드
자바 코드에서 동기화 영역은 synchronizred 키워드로 표시된다. 동기화는 객체에 대한 동기화로 이루어지는데(synchronized on some object), 같은 객체에 대한 모든 동기화 블록은 한 시점에 오직 한 쓰레드만이 블록 안으로 접근하도록 - 실행하도록 - 한다. 블록에 접근을 시도하는 다른 쓰레드들은 블록 안의 쓰레드가 실행을 마치고 블록을 벗어날 때까지 블록(blocked) 상태가 된다.
synchronized 키워드는 다음 네 가지 유형의 블록에 쓰인다.
인스턴스 메소드
스태틱 메소드
인스턴스 메소드 코드블록
스태틱 메소드 코드블록
어떤 동기화 블록이 필요한지는 구체적인 상황에 따라 달라진다.
인스턴스 메소드 동기화
다음은 동기화 처리된 인스턴스 메소드이다.
public synchronized void add(int value){
this.count += value;
}
메소드 선언문의 synchronized 키워드를 보자. 이 키워드의 존재가 이 메소드의 동기화를 의미한다.
인스턴스 메소드의 동기화는 이 메소드를 가진 인스턴스(객체)를 기준으로 이루어진다. 그러므로, 한 클래스가 동기화된 인스턴스 메소드를 가진다면, 여기서 동기화는 이 클래스의 한 인스턴스를 기준으로 이루어진다. 그리고 한 시점에 오직 하나의 쓰레드만이 동기화된 인스턴스 메소드를 실행할 수 있다. 결국, 만일 둘 이상의 인스턴스가 있다면, 한 시점에, 한 인스턴스에, 한 쓰레드만 이 메소드를 실행할 수 있다.
인스턴스 당 한 쓰레드이다.
스태틱 메소드 동기화
스태틱 메소드의 동기화는 인스턴스 메소드와 같은 방식으로 이루어진다.
public static synchronized void add(int value){
count += value;
}
역시 선언문의 synchronized 키워드가 이 메소드의 동기화를 의미한다.
스태틱 메소드 동기화는 이 메소드를 가진 클래스의 클래스 객체를 기준으로 이루어진다. JVM 안에 클래스 객체는 클래스 당 하나만 존재할 수 있으므로, 같은 클래스에 대해서는 오직 한 쓰레드만 동기화된 스태틱 메소드를 실행할 수 있다.
만일 동기화된 스태틱 메소드가 다른 클래스에 각각 존재한다면, 쓰레드는 각 클래스의 메소드를 실행할 수 있다.
클래스 -쓰레드가 어떤 스태틱 메소드를 실행했든 상관없이- 당 한 쓰레드이다.
인스턴스 메소드 안의 동기화 블록
동기화가 반드시 메소드 전체에 대해 이루어져야 하는 것은 아니다. 종종 메소드의 특정 부분에 대해서만 동기화하는 편이 효율적인 경우가 있다. 이럴 때는 메소드 안에 동기화 블록을 만들 수 있다.
public void add(int value){
synchronized(this){
this.count += value;
}
}
이렇게 메소드 안에 동기화 블록을 따로 작성할 수 있다. 메소드 안에서도 이 블록 안의 코드만 동기화하지만, 이 예제에서는 메소드 안의 동기화 블록 밖에 어떤 다른 코드가 존재하지 않으므로, 동기화 블록은 메소드 선언부에 synchronized 를 사용한 것과 같은 기능을 한다.
동기화 블록이 괄호 안에 한 객체를 전달받고 있음에 주목하자. 예제에서는 'this' 가 사용되었다. 이는 이 add() 메소드가 호출된 객체를 의미한다. 이 동기화 블록 안에 전달된 객체를 모니터 객체(a monitor object) 라 한다. 이 코드는 이 모니터 객체를 기준으로 동기화가 이루어짐을 나타내고 있다. 동기화된 인스턴스 메소드는 자신(메소드)을 내부에 가지고 있는 객체를 모니터 객체로 사용한다.
같은 모니터 객체를 기준으로 동기화된 블록 안의 코드를 오직 한 쓰레드만이 실행할 수 있다.
다음 예제의 동기화는 동일한 기능을 수행한다.
public class MyClass {
public synchronized void log1(String msg1, String msg2){
log.writeln(msg1);
log.writeln(msg2);
}
public void log2(String msg1, String msg2){
synchronized(this){
log.writeln(msg1);
log.writeln(msg2);
}
}
}
한 쓰레드는 한 시점에 두 동기화된 코드 중 하나만을 실행할 수 있다. 여기서 두 번째 동기화 블록의 괄호에 this 대신 다른 객체를 전달한다면, 쓰레드는 한 시점에 각 메소드를 실행할 수 있다. -동기화 기준이 달라지므로.
스태틱 메소드 안의 동기화 블록
다음 예제는 스태틱 메소드에 대한 것이다. 두 메소드는 각 메소드를 가지고 있는 클래스 객체를 동기화 기준으로 잡는다.
public class MyClass {
public static synchronized void log1(String msg1, String msg2){
log.writeln(msg1);
log.writeln(msg2);
}
public static void log2(String msg1, String msg2){
synchronized(MyClass.class){
log.writeln(msg1);
log.writeln(msg2);
}
}
}
같은 시점에 오직 한 쓰레드만 이 두 메소드 중 어느 쪽이든 실행 가능하다. 두 번째 동기화 블록의 괄호에 MyClass.class 가 아닌 다른 객체를 전달한다면, 쓰레드는 동시에 각 메소드를 실행할 수 있다.
▶︎▶︎▶︎박철우님의 블로그
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| JAVA - Hashtable, HashMap, ConcurrentHashMap 비교 (0) | 2019.02.01 |
|---|---|
| 객체지향 design pattern - composite pattern 예제 (0) | 2019.01.29 |
| 객체지향 design pattern - strategy pattern 예제 (0) | 2019.01.04 |
| JAXB - unmarshal , marshal (언마샬,마샬) (0) | 2018.06.03 |
| Servlet이란? (0) | 2018.05.30 |