

'운영체제'에 해당되는 글 4건
- 2020.08.22 :: 운영체제 - 디스크 사용량 및 정보 확인
- 2019.07.28 :: 운영체제 - 병행 프로세스란?
- 2019.07.27 :: 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching
- 2019.07.22 :: 운영체제 - 컴퓨터 하드웨어의 구성(CPU,RAM 등)
UNIX/LINUX : 용량 확인 명령어 (df/du)
unix/linux Unix/Linux 디스크 용량 확인 (df/du) 디스크 용량을 확인하는 명령어들이다. df : 디스크의 남은 용량을 확인 df -k : 킬로바이트 단위로 현재 남은 용량을 확인 df -m : 메가바이트 단위로 남은 �
ra2kstar.tistory.com
디스크의 남은 용량 확인
- df -k : 킬로바이트 단위로 현재 남은 용량을 확인
- df -m : 메가바이트 단위로 남은 용량을 왁인
- df -h : 보기 좋게 보여줌
- df . : 현재 디렉토리가 포함된 파티션의 남은 용량을 확인
> df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1s1 466Gi 10Gi 379Gi 3% 487648 4881965192 0% /
devfs 190Ki 190Ki 0Bi 100% 659 0 100% /dev
/dev/disk1s2 466Gi 73Gi 379Gi 17% 1142296 4881310544 0% /System/Volumes/Data
/dev/disk1s5 466Gi 2.0Gi 379Gi 1% 2 4882452838 0% /private/var/vm
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /System/Volumes/Data/home
현재 디렉토리의 용량 확인
- du -a : 현재 디렉토리의 사용량을 파일단위 출력
- du -s : 총 사용량을 확인
- du -h : 보기 좋게 바꿔줌
- du -sh * : 한단계 서브디렉토리 기준으로 보여준다.
> du -sh *
4.0K Dockerfile
4.0K HELP.md
12K README.md
34M build
4.0K build.gradle
60K gradle
8.0K gradlew
4.0K gradlew.bat
284K kube-logging
48K kube-resource
4.0K kube-sample.iml
24K nginx
4.0K settings.gradle
4.0K src
'인프라 > 운영체제' 카테고리의 다른 글
| 운영체제 - 상호배제와 동기화(뮤텍스,TAS,세마포어,모니터) (0) | 2019.07.28 |
|---|---|
| 운영체제 - 병행 프로세스란? (0) | 2019.07.28 |
| 운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드) (1) | 2019.07.27 |
| 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching (0) | 2019.07.27 |
| 운영체제 - 컴퓨터 하드웨어의 구성(CPU,RAM 등) (0) | 2019.07.22 |
2019/07/27 - [운영체제] - 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching
운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching
프로세스의 개념 프로세스는 다양한 정의가 있다. 실행 중인 프로그램 비동기적 행위 실행 중인 프로시저 실행 중인 프로시저의 제어 추적 운영체제에 들어 있는 프로세스 제어 블록(PCB) 프로세서에 할당하여 실..
coding-start.tistory.com
2019/07/27 - [운영체제] - 운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드)
운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드)
2019/07/27 - [운영체제] - 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching 프로세스의 개념 프로세스는 다양한 정의가 있다...
coding-start.tistory.com
컴퓨터는 프로그램 작업을 수행하는 데 사용할 수 있는 여러 자원으로 구성된다. 예를 들면, 명령을 실행하는 프로세서, 데이터를 저장하는 메인 메모리, 프로세서의 임시 저장소인 레지스터, 프로세서와 메인 메모리 사이의 속도 차를 조절해주는 캐시 등이 있다. 이 중에서 메모리 같은 자원은 공유 영역을 모든 프로세스가 동시에 공유한다. 즉, 이 메모리 자원은 공유 영역을 프로세스들이 병렬로 사용한다. 반면에 입출력장치 일부나 프로세서는 한 번에 프로세스 하나만 사용할 수 있는 공유자원이다.
프로세서 하나는 한 번에 프로세스 하나만 실행할 수 있다. 하지만 운영체제가 프로세서를 빠르게 전환하여 프로세서 시간을 나눠서 마치 프로세스 여러 개를 동시에 실행하는 것처럼 보이게 하는 것을 병행 프로세스라고 한다. 그리고 하나의 프로세스 내에 스레드들을 커널 수준의 스레드로 구현하면 각 스레드에 별도의 프로세서를 할당하여 병렬로 하나의 프로그램을 수행할 수도 있다.
- 단일 프로그래밍 : 프로세서를 사용 중이던 프로세스를 완료한 후 다른 프로세스를 실행한다.
- 다중 프로그래밍 : 프로세스 여러 개가 프로세서 하나를 공유한다.
- 다중 처리 : 프로세서를 2개 이상 사용하여 동시에 프로그램 여러 개를 병렬로 실행한다. 프로세스는 한 번에 프로세서 하나에서 실행하지만, 동일한 시스템에서는 서로 다른 시간에 서로 다른 프로세서에서 실행할 수 있다.
이러한 병행 프로세스를 사용하기 위해서는 꼭 해결해야할 과제가 있다.
- 공유 자원을 상호 배타적으로 사용해야 한다. 예를 들어, 프린터, 통신망 등은 한순간에 프로세스 하나만 사용해야 한다.
- 병행 프로세스 간에는 협력이나 동기화가 되어야 한다. 상호배제도 동기화의 한 형태이다.
- 두 프로세스 사이에서는 데이터를 교환할 수 있도록 통신이 되어야 한다.
- 프로세스는 동시에 수행하는 다른 프로세스의 실행 속도와 관계없이 항상 일정한 실행 결과를 보장하도록 해야한다.
- 교착 상태를 해결하고 병행 프로세스들의 병렬 처리 능력을 극대화해야 한다.
- 실행 검증 문제를 해결해야 한다.
- 병행 프로세스를 수행하는 과정에서 발생하는 상호배제, 즉 어떤 프로세스가 작업을 실행 중일때 나머지 프로세스는 그것과 관련된 작업을 수행할 수 없도록 보장해야 한다.
다중 처리 시스템에서는 프로세서들이 모든 입출력장치와 메모리를 참조할 수 있어 동시에 동일한 자원에 접근할 때 충돌이 발생할 수 있다. 따라서 프로세서 간의 충돌을 해결하는 방법이 필요하다.
'인프라 > 운영체제' 카테고리의 다른 글
| 운영체제 - 디스크 사용량 및 정보 확인 (0) | 2020.08.22 |
|---|---|
| 운영체제 - 상호배제와 동기화(뮤텍스,TAS,세마포어,모니터) (0) | 2019.07.28 |
| 운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드) (1) | 2019.07.27 |
| 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching (0) | 2019.07.27 |
| 운영체제 - 컴퓨터 하드웨어의 구성(CPU,RAM 등) (0) | 2019.07.22 |
프로세스의 개념
프로세스는 다양한 정의가 있다.
- 실행 중인 프로그램
- 비동기적 행위
- 실행 중인 프로시저
- 실행 중인 프로시저의 제어 추적
- 운영체제에 들어 있는 프로세스 제어 블록(PCB)
- 프로세서에 할당하여 실행할 수 있는 개체 디스패치가 가능한 대상
이 중 가장 일반적인 프로세스 정의는 "실행 중인 프로그램"이다. 프로그램이 실행 중이라는 의미는 디스크에 있던 프로그램을 메모리에 적재하여 운영체제의 제어를 받는 상태가 되었다는 것이다. 이는 자신만의 메모리 영역(주소 공간)이 있음을 의미한다.
프로세스가 실행 중인 프로그램이 되려면 프로세서 점유 시간, 메모리, 파일, 입출력장치 같은 자원이 필요한데, 프로세스를 생성하거나 실행할 때 이 자원을 할당한다. 그리고 프로세스는 현재의 활동 상태를 나타내는 프로그램 카운터(PC), 프로세서의 현재 활동(레지스터 내용)도 포함한다. 프로그램은 컴파일한 코드와 초기화 전역변수, 문자열과 문자열 상수 등 정적 데이터를 포함하는 정적인 개체이다. 반면에 프로세스는 아래와 같이 메모리 구조를 이루고, 프로그램 카운터나 레지스터처럼 현재 어떤 자원을 사용하는지 관련 정보가 들어 있는 동적인 개체이다.
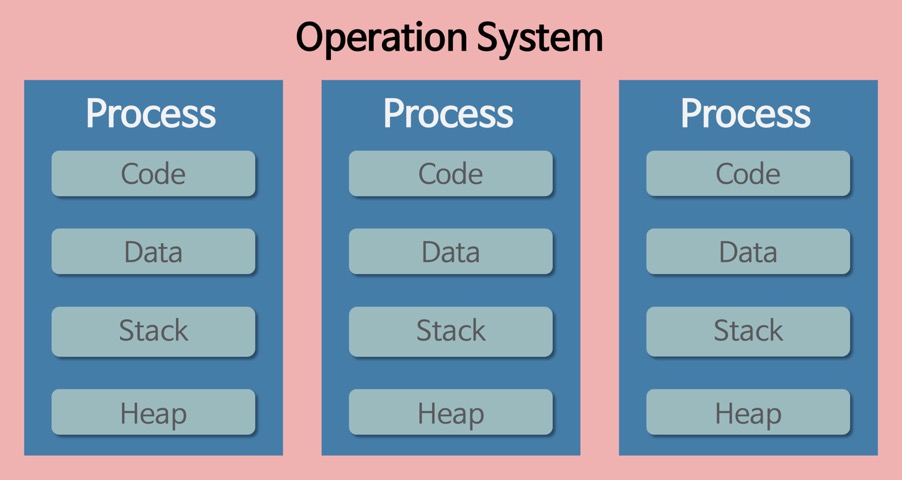
스택은 데이터를 일시적으로 저장하는 영역이다. 지역변수에 사용하고, 변수가 범위 밖으로 이동하면 공간을 해제한다. 호출한 함수의 반환 주소, 반환 값, 매개변수 등에 사용하고, 함수를 호출할수록 커지고 반환하면 줄어든다. 보통 힙과 인접한 방향으로 점점 커져 스택 포인터와 힙 포인터를 만나면 메모리가 소진되었다는 의미이다.
힙은 코드 영역과는 별도로 유지되는 자유 영역이다. 동적으로 메모리를 할당하려고 프로그램 실행 중 시스템 호출을 사용했다가 해제하는 방법으로 활용한다. 프로세스의 공유 라이브러리와 동적으로 적재된 모듈이 서로 공유하는데, 동적 메모리 할당이 발생하면 스택영역 쪽인 위쪽으로 커진다.
데이터는 프로그램의 가상 주소 공간이다. 전역변수나 정적변수를 저장하거나 할당하고 실행하기 전에 초기화한다. 읽기&쓰기가 가능한 영역이다.
코드는 실행 명령을 포함하는 메모리이거나 목적 파일에 있는 프로그램 영역이다. 프로그램을 시작할 때 프로세서가 디스크에서 읽어 실행하는 컴파일한 프로그램을 저장한다. 프로세스로 변경할 수 없고, 읽기 전용이므로 프로그램이 코드 영역을 침범하여 쓰기를 시도하면 오류가 발생해서 프로그램을 종료한다.
이러한 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 자원 영역에 접근할 수 없다. 만약 한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신(IPC)을 사용해야한다. (파이프, 파일, 소켓 등)
프로세스는 수행하는 역할에 따라 시스템(커널) 프로세스와 사용자 프로세스로 구분하고, 병행 수행 방법에 따라 독립 프로세스와 협력 프로세스로 구분한다.
| 구분 | 종류 | 설명 |
| 역할 | 시스템(커널)프로세스 | 모든 시스템 메모리와 프로세서의 명령에 액세스할 수 있는 프로세스이다. 프로세스 실행 순서를 제어하거나 다른 사용자 및 커널 영역을 침범하지 못하게 감시하고, 사용자 프로세스를 생성하는 기능을한다. |
| 사용자 프로세스 | 사용자 코드를 수행하는 프로세스이다. | |
| 병행 수행 방법 | 독립 프로세스 | 다른 프로세스에 영향을 주지 않거나 다른 프로세스의 영향을 받지 않으면서 수행하는 병행 프로세스이다. |
| 협력 프로세스 | 다른 프로세스에 영향을 주거나 다른 프로세스에서 영향을 받는 병행 프로세스이다. |
프로세스의 상태 변화와 상태 정보
운영체제는 프로세스의 실행을 제어한다. 그리고 프로세스는 실행하면서 상태가 변하므로 운영체제는 프로세스 제어에 필요한 상태를 점검하고 프로세스를 제어한다.
프로세스의 상태는 크게 실행 상태와 비실행 상태로 구분할 수 있다. 운영체제가 프로세스를 생성하면 비실행 상태로 초기화해서 실행을 기다린다. 실행 중인 프로세스를 종료하거나 인터럽트가 발생하면 비실행 프로세스 중에서 선택한 프로세스를 실행 상태로 바꾼다.(디스패치)이때 인터럽트된 프로세스를 비실행 상태가 된다. 실행 중인 프로세스는 새로운 자원을 할당받으려고 프로세서를 기다리는 비실행 상태로 바뀌기도 한다.
프로세스의 상태 변화는 운영체제가 작업 스케쥴러와 프로세스 스케쥴러를 이용하여 관리한다. 작업 스케쥴러는 스풀러가 디스크에 저장한 작업 중 실행할 작업을 선정하고 준비 리스트에 삽입하여 다중 프로그래밍의 정도를 결정하며, 프로세스 스케쥴러는 선정한 작업의 상태를 변화시키며 프로세스의 생성에서 종료까지의 과정을 수행한다.
실행 상태의 프로세스가 프로세서를 자발적으로 반환하기 전에 할당된 CPU점유 시간이 지나면 이 프로세스는 준비 상태가 된다. 그리고 프로세스를 실행하다 입출력 명령이 발생하면 대기 상태가 된다. 대기 상태인 프로세스는 대기 원인을 제거하면 준비 상태로 바뀌고, 디스패처가 준비 상태인 프로세스에 프로세서를 할당하면 다시 실행 상태로 바뀐다. 여기서 디스패처는 스케쥴러가 선택한 프로세스에 프로세서를 할당하는 모듈이다.
| 상태변화 | 표기방법 |
| 1.준비->실행 | dispatch(프로세스 이름) |
| 2.실행->준비 | timeout(프로세스 이름) |
| 3.실행->대기 | block(프로세스 이름) |
| 4.대기->준비 | wakeup(프로세스 이름) |
준비->실행
준비 큐 맨 앞에 있던 프로세스가 프로세서를 점유하는 것을 디스패치라고 한다.(스케쥴 알고리즘에 따라 다름) 다중 프로그래밍 운영체제에서는 실행 상태인 프로세스가 할당된 CPU점유 시간만큼만 프로세서를 사용하도록 하여 특정 프로세스가 프로세서를 계속 독점하는 것을 방지한다.
실행->준비
운영체제는 실행 상태의 프로세스가 프로세서를 계속 독점하지 않도록 인터럽트 클록을 두어 특정 프로세스가 할당된 CPU점유 시간동안만 프로세서를 점유하게 한다. 프로세스가 일정 시간이 지나도 프로세서를 반환하지 않으면 클록이 인터럽트를 발생시켜 운영체제에 프로세서 제어권을 부여하는 것이다. 그러면 실행 상태의 프로세스는 준비 상태가 되고, 준비리스트의 첫 번째 프로세스가 실행 상태가 된다.(스케쥴 알고리즘에 따라 다름)
실행->대기
할당된 시간 이전에 실행 상태의 프로세스에 입출력 연산 등이 필요하거나 새로운 자원 요청 등의 문제로 프로세서를 스스로 양도하면 대기 상태가 된다.
대기->준비
프로세스는 입출력 작업이 끝나면 wake up으로 대기에서 준비 상태가 된다.
프로세스 제어 블록(PCB,Process Control Block)
운영체제가 프로세스를 제어할 때 필요한 프로세스 상태 정보는 프로세스 제어 블록에 저장된다. 프로세스 제어 블록은 특정 프로세스가 생성될 때 마다 생성되는 것이며 특정 프로세스 정보를 저장하는 데이터 블록이나 레코드로, 작업 제어 블록(TCB,Task Controll Block)이라고도 한다. 프로세스가 생성되면 메모리에 PCB를 생성하고, 프로세스가 실행을 종료하면 PCB도 삭제한다. PCB에 들어있는 정보들을 아래와 같다.
| 정보 | 설명 |
| 프로세스 식별자 | 각 프로세스의 고유 식별자 |
| 프로세스 상태 | 생성,준비,실행,대기,중단 등 상태표시 |
| 프로그램 카운터(PC) | 프로세스를 실행하는 다음 명령어의 주소 |
| 레지스터 저장 영역 | 누산기, 인덱스 레지스터, 스택 포인터, 범용 레지스터, 조건 코드 등 정보로 컴퓨터 구조에 따라 수나 형태가 다르다. 인터럽트가 발생하면 프로그램 카운터와 함께 저장하여 재실행할 때 원래대로 복귀할 수 있게 한다. |
| 프로세서 스케줄링 정보 | 프로세스의 우선순위, 스케줄링 큐의 포인터, 기타 스케줄 매개변수 |
| 계정정보 | 프로세서 사용 시간, 실제 사용시간, 사용 상한 시간, 계정 번호, 작업이나 프로세스 번호 등 |
|
입출력 상태 정보 메모리 관리 정보 ... |
특별한 입출력 요구 프로세스에 할당된 입출력장치, 열린 파일 리스트 등 운영체제가 사용하는 메모리 시스템에 따른 상한,하한 레지스터(경계 레지스터), 페이지 테이블이나 세그먼트 테이블 값 등 |
프로세스 Context Switching
인터럽트나 시스템 호출 등으로 실행 중인 프로세스의 제어를 다른 프로세스에 넘겨 실행 상태가 되도록 하는 것을 프로세스 Context Switching이라고 한다. 프로세스 문맥 교환이 일어나면 프로세서의 레지스터에 있던 내용을 나중에 사용할 수 있도록 저장한다.
예) 프로세스 A가 실행 상태에 있던 도중 프로세스 B에 제어권을 넘겨주는 Context Switching 가정
- 인터럽트 신호
- PCB_A에 프로세스 A 상태 저장
- PCB_B에 저장되어 있던 프로세스 B 상태를 다시 적재
- 인터럽트 신호
- PCB_B에 프로세스 B 상태 저장
- PCB_A에 저장되어 있던 프로세스 A 상태를 다시 적재
Context Switching에서는 오버헤드가 발생하는데, 이는 메모리 속도, 레지스터 수, 특수 명령어의 유무에 따라 다르다. 그리고 Context Switching은 프로세스가 "준비->실행" 상태로 바뀌거나 "실행->준비, 실행->대기" 상태로 바뀔 때 발생한다.
현재 실행 중인 프로세스에서 Context Switching을 요청하면, 우선 사용자 모드에서 커널 모드로 프로세스 제어가 넘어가면서 프로세스를 종료한다. 그리고 다시 시작할 수 있도록 프로세스의 현재 상태를 PCB에 저장하고 다음에 실행할 프로세스를 선택한다. 새로 실행될 프로세스 정보를 PCB에서 얻어와 프로세서에 재저장하고는 사용자 모드로 돌아와서 새로운 프로세스를 실행한다.
이러한 Context Switching은 시간 비용이 들어가는 오버헤드이고, 이 오버헤드는 메모리 속도, 레지스터 수, 특수 명령어의 유무에 따라 시스템마다 다르다. 그래서 운영체제를 설계할 때, 최대한 불필요한 Context Switching을 줄이는 것을 목표로 정한다. Context Switching은 레지스터 Context 교환, 작업 Context 교환, 쓰레드 Context 교환, 프로세스 Context 교환이 가능하다.
<프로세스 구조>
프로세스는 실행 중에 프로세스 생성 시스템 호출을 이용하여 새로운 프로세스를 생성할 수 있다. 이때 프로세스 생성 순서를 저장하고 부모-자식 관계를 유지하여 계층적으로 생성한다.
프로세스의 생성
운영체제나 응용 프로그램에서 요청을 받아 프로세스를 생성하면, 운영체제는 해당 프로세스에서 프로세스 제어 블록을 만들어 주소 공간을 할당한다.
- 새로운 프로세스에 프로세스 식별자를 할당
- 프로세스의 모든 구성 요소를 포함할 수 있는 주소 공간과 프로세스 제어 블록 공간을 할당한다.
- 프로세스 제어 블록을 초기화한다. 프로세스 상태, 프로그램 카운터 등 초기화, 자원 요청, 프로세스 제어 정보(우선순위) 등을 포함한다.
- 준비큐에 삽입
프로세스가 작업을 수행하려면 프로세서 점유 시간, 메모리, 파일, 입출력장치 등 자원이 필요하다. 자식 프로세스는 운영체제에서 직접 필요한 자원을 얻거나 부모 프로세스의 자원을 일부 사용할 수 있다. 이때 부모 프로세스는 자식 프로세스가 사용하는 자원을 제한해서 특정 프로세스가 자식 프로세스를 너무 많이 생성하여 시스템에 부담을 주는 것을 막을 수 있다.
프로세스의 종료
프로세스가 마지막 명령을 실행하면 종료하여 운영체제에 프로세스의 삭제를 요청한다. 또한 부모 프로세스는 자식 프로세스가 할당된 자원을 초과하여 자원을 사용할 때나 자식 프로세스에 할당한 작업이 더는 없을 때 자식 프로세스를 종료한다.
프로세스의 제거
프로세스 제거는 프로세스를 파괴하는 것이다. 프로세스를 제거하면 사용하던 자원을 시스템에 돌려주고, 해당 프로세스는 시스템 리스트나 테이블에서 사라져 프로세스 제어 블록을 회수한 후 디스크에 저장한다.
프로세스의 중단과 재시작
프로세스의 준비, 실행, 대기 상태만 이용하면 입출력 동작이 일반 연산보다 느려 시스템이 대부분 유휴 상태이다. 다중 프로그래밍 환경에서도 프로세서의 동작시간이 입출력보다 짧아 프로세스 문맥 교환이 일어난 후에도 기다리게 되므로 대부분 유휴시간이 된다.
시스템의 유휴시간 문제는 프로세스 중단(일시중단) 상태를 이용하여 해결할 수 있다. 운영체제는 새로운 프로세스를 생성하여 실행하거나 실행 중인 프로세스를 중단했다가 다시 실행하여 사용할 수 있다. 후자의 방법을 이용하면 시스템 전체의 부하를 증기시키지 않으면서 프로세스에 서비스를 제공할 수 있다. 중단 상태를 추가하면 실행에서 대기가 아닌 중단 상태로 전환하여 특정 이벤트의 발생을 기다리면서 대기 상태가 된다. 그리고 해당 이벤트가 발생할 때 준비상태로 가서 실행을 기다리는 것이 아닌 즉시 실행 상태로 바꿀 수 있는 이점이 있다.
프로세스를 중단한 원인을 제거하여 다시 실행하는 것을 재시작이라고 한다.
프로세스 중단과 재시작은 시스템 부하를 조절하는 데 상당히 중요하고, 다음 상황에서 주로 발생한다.
- 시스템에 장애가 발생하면 실행 중인 프로세스는 잠시 중단했다가 시스템이 기능을 회복할 때 다시 재시작할 수 있다.
- 프로세스에 의심스러운 부분이 있으면 실행 중인 프로세스를 중단하여 확인한 후 재시작하거나 종료할 수 있다.
- 처리할 작업이 너무 많아 시스템에 부담이 되면 프로세스 몇 개를 중단했다가 시스템이 정상 상태로 다시 돌아왔을 때 재시작할 수 있다.
대다수 시스템은 프로세스를 실행하기 전에 자원을 할당받고 실행을 시작하지만, 다중 프로그래밍 환경에서는 지원의 이용률과 시스템 효율을 높이려고 자원을 동적으로 할당한다. 이때 자원을 할당받으려고 기다리는 상태가 "대기"이고, 할당받은 자원을 기다리는 상태가 "중단"이다.
중단된 상태는 프로세스가 보조 메모리에 있고 이벤트를 대기 중인 상태이다. 중단 상태는 프로세스가 보조 메모리에 있지만 즉시 메인 메모리로 적재하여 실행할 수 있는 상태이다.
'인프라 > 운영체제' 카테고리의 다른 글
| 운영체제 - 디스크 사용량 및 정보 확인 (0) | 2020.08.22 |
|---|---|
| 운영체제 - 상호배제와 동기화(뮤텍스,TAS,세마포어,모니터) (0) | 2019.07.28 |
| 운영체제 - 병행 프로세스란? (0) | 2019.07.28 |
| 운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드) (1) | 2019.07.27 |
| 운영체제 - 컴퓨터 하드웨어의 구성(CPU,RAM 등) (0) | 2019.07.22 |

컴퓨터 시스템은 데이터를 처리하는 물리적인 기계장치인 하드웨어와 어떤 작업을 지시하는 명령어로 작성한 프로그램인 소프트웨어로 구성된다. 운영체제는 컴퓨터 하드웨어를 관리하는 소프트웨어이다. 그러므로 운영체제를 이해하려면 먼저 컴퓨터 하드웨어에 대해 아는 것이 중요하다. 이번 포스팅에서는 하드웨어를 하나하나 깊숙히 알아간다기 보다는 어떠한 하드웨어가 있고 해당 하드웨어가 어떻게 구성되며 어떠한 역할을 하는지 정도만 알아보는 포스팅이 될듯하다.
컴퓨터 하드웨어는 크게 프로세서(CPU), 메모리(기억장치,RAM), 주변장치로 구성되고, 이들은 시스템 버스로 연결한다.
1.프로세서(CPU)
프로세서는 컴퓨터 하드웨어에 부착한 모든 장치의 동작을 제어하고 명령을 실행한다. 중앙처리장치(Central Processing Unit)라고도 한다. 프로세서는 밑의 그림과 같이 연산장치와 제어장치, 레지스터로 구성되고, 이들은 내부 버스로 연결한다.
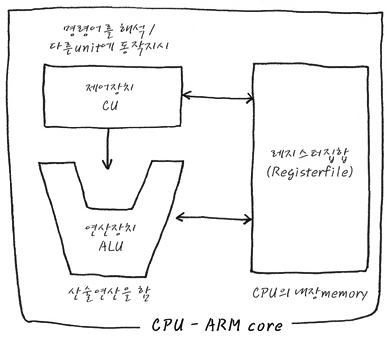
제어장치에서 연산장치와 레지스터로 나가는 화살표는 제어흐름이고 레지스터와 연산장치 사이의 흐름은 데이터의 흐름이다. 위의 레지스터는 종류와 크기가 다양하다. 레지스터는 여러 관점으로 구분할 수 있다. 용도에 따라 전용 레지스터와 범용 레지스터로 구분할 수 있고, 사용자가 정보를 변경할 수 있는가에 따라 사용자 가시 레지스터와 사용자 불가시 레지스터로 구분할 수 있다. 그리고 저장하는 정보의 종류에 따라 데이터 레지스터, 주소 레지스터, 상태 레지스터 등으로 세분화할 수 있다. 사용자 가시 레지스터와 사용자 비가시 레지스터로 구분하면 아래표와 같이 레지스터들을 구분할 수 있다.
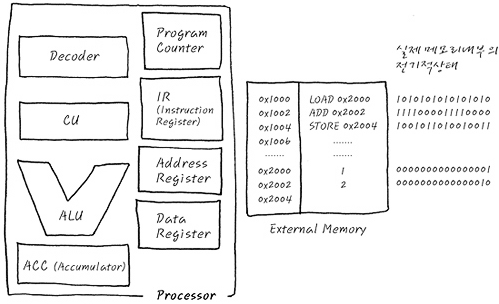
1-1 사용자 가시 레지스터
| 종류 | 설명 | |
| 데이터 레지스터(DR) | 함수 연산에 필요한 데이터를 저장한다. 값, 문자 등을 저장하므로 산술 연산이나 논리 연산에 사용하며, 연산 결과로 플래그 값을 저장한다. | |
| 주소 레지스터(AR) | 주소나 유효 주소를 계산하는 데 필요한 주소의 일부분을 저장한다. 주소 레지스터에 저장한 값을 사용하여 산술 연산을 할 수 있다. | |
| 기준 주소 레지스터 | 프로그램을 실행할 때 사용하는 기준 주소 값을 저장한다. 기준 주소는 하나의 프로그램이나 일부처럼 서로 관련 있는 정보를 저장하며, 연속된 저장 공간을 지정하는 데 참조할 수 있는 주소이다. 따라서 기준 주소 레지스터는 페이지나 세그먼트처럼 블록화된 정보에 접근하는 데 사용한다. | |
| 인덱스 레지스터 | 유효 주소를 계산하는 데 사용하는 주소 정보를 저장한다. | |
| 스택 포인터 레지스터 | 메모리에 프로세서 스택을 구현하는 데 사용한다. 많은 프로세서와 주소 레지스터를 데이터 스택 포인터와 큐 포인터로 사용한다. 보통 반환 주소, 프로세서 상태 정보, 서브루틴의 임시 변수를 저장한다. | |
1-2 사용자 불가시 레지스터
사용자가 정보를 변경할 수 없는 레지스터이다. 보통 프로세서의 상태와 제어를 관리한다.
| 종류 | 설명 |
| 프로그램 카운터(PC) | 다음에 실행할 명령어의 주소를 보관하는 레지스터이다. 계수기로 되어 있어 실행할 명령어를 메모리에서 읽으면 명령어의 길이만큼 증가하여 다음 명령어를 가리키며, 분기 명령어는 목적 주소로 갱신할 수 있다. |
| 명렁어 레지스터(IR) | 현재 실행하는 명령어를 보관하는 레지스터이다. |
| 누산기(ACC) | 데이터를 일시적으로 저장하는 레지스터이다. |
| 메모리 주소 레지스터(MAR) | 프로세서가 참조하려는 데이터의 주소를 명시하여 메모리에 접근하는 버퍼 레지스터이다. |
| 메모리 버퍼 레지스터(MBR) | 프로세서가 메모리에서 읽거나 메모리에 저장할 데이터 자체를 보관하는 버퍼 레지스터이다. 메모리 데이터 레지스터(MDR)라고도한다. |
세분화된 레지스터로 프로세서(CPU)그림을 표현하면 대략 아래와 같다.
2.메모리
메모리는 컴퓨터 성능과 밀접하다. 당연히 크고 빠른 메모리는 가격이 비싸기 나름이다. 그렇기 때문에 메모리를 비용, 속도, 용량, 접근시간 대비 효율성을 높히기 위해 메모리 계층구조를 구성하여 상호보완한다. 메모리 계층구조는 아래와 같다.
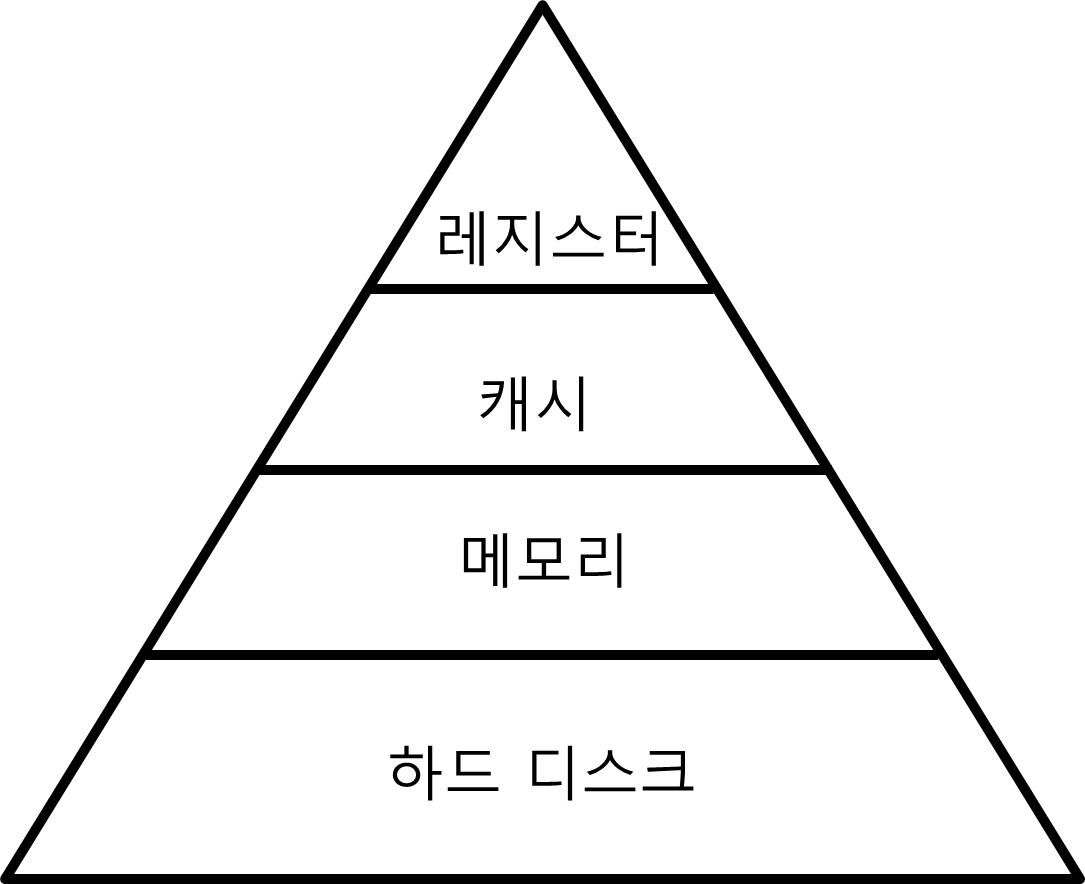
위의 그림에서 메인 메모리를 중심으로 아래에는 대용량의 자기디스크, 이동이 편리한 광디스크, 파일을 저장하는 속도가 느린 자기테이프등이 있다.(현 시점에는 메모리 기술이 발달하면서 SSD라는 디스크가 나왔는데, 자기디스크로 된 하드디스크보다 입출력 속도가 빠르고 플래시 메모리로 구성되어 있다.) 그리고 메인 메모리 위에는 메인 메모리와 프로세서의 속도 차이를 보완하는 캐시가 있다. 최상위에는 프로세서가 사용한 데이터를 보관하는 가장 빠른 레지스터가 있다.
프로그램을 실행하거나 데이터를 참조하려면 모두 메인 메모리에 올려야 한다. 그렇다고 무작정 메인 메모리를 크게할 수 없는데, 불필요한 프로그램과 데이터는 보조기억장치에 저장했다가 실행,참조할 때만 메인 메모리에 옮기는 원리를 적용하고 CPU에서 자주 사용되는 데이터는 캐시메모리에 임시저장한다거나 해서 서로 상호보완한다. 그리고 레지스터와 캐시, 메인메모리(메모리)는 프로세서(CPU)가 직접 접근할 수 있지만 보조기억장치(하드 디스크)는 프로세서(CPU)가 직접 접근할 수 없고 메인메모리에 올려야 접근할 수 있다.
2-1 메인메모리(주기억장치)
프로세서(CPU) 외부에 있으며, 프로세서에서 즉각적으로 수행할 프로그램과 데이터를 저장하거나 프로세서에서 처리한 결과를 메인 메모리에 저장한다. 입출력장치도 메인 메모리에 데이터를 받거나 저장한다. 메인 메모리는 다수의 셀로 구성되며, 각 셀은 비트로 구성된다. 셀이 k비트면 셀에 2^k 값을 저장할 수 있다. 메인 메모리에 데이터를 저장할 때는 셀 한 개나 여러 개에 나눠서 자장한다. 셀은 주소로 참조하는데, n비트라면 주소 범위는 0~2^n-1이다.
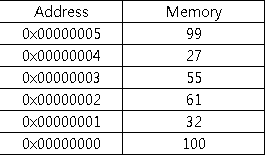
위처럼 컴퓨터에 주어진 주소를 물리적 주소라고 하는데, 프로그래머는 물리적 주소 대신 프로그래밍을 할때 함수(수식)나 변수를 사용한다. 그리고 컴파일러가 프로그램을 기계 명령어로 변환할 때 변수와 명령어에 주소를 할당하는데, 이 주소를 논리적 주소라고 한다. 논리적 주소는 별도의 주소 공간에 나타난다. 컴파일로 논리적 주소를 물리적 주소로 변환하는데, 이 과정을 매핑 또는 메모리 맵이라고 한다.
운영체제는 가상 메모리 방법을 사용하여 메인 메모리의 유효 크기를 늘릴 수도 있다. 메모리 속도는 메모리 접근시간과 메모리 사이클 시간으로 표현할 수 있다. 메모리 접근시간은 명령이 발생한 후 목표 주소를 검색하여 데이터 쓰기(읽기)를 시작할 때까지 걸린 시간이다(예:읽기 제어 신호를 가한 후 데이터를 메모리 버퍼 레지스터에 저장할 때까지 걸린 시간) 메모리 사이클 시간은 두 번의 연속적인 메모리 동작 사이에 필요한 최소 지연시간이다.(예:읽기 제어 신호를 가한 후 다음 읽기 제어 신호를 가할 수 있을 때까지 필요한 시간) 보통 사이클 시간이 접근시간보다 약간 길지만 메모리의 세부 구현 방법에 따라 다르다.
메인 메모리는 프로세서와 보조기억장치 사이에 있으며, 여기서 발생하는 디스크 입출력 병목 현상을 해결하는 역할도 한다. 그런데 프로세서와 메인 메모리 간에 속도 차이가 나면서 메인 메모리의 부담을 줄이려고 프로세서 내부나 외부에 캐시 메모리를 구현하기도 한다.
3. 캐시
프로세서 내부나 외부에 있으며, 처리 속도가 빠른 프로세서와 상대적으로 느린 메인 메모리의 속도 차이를 보완하는 고속 버퍼이다. 캐시는 메인메모리에서 데이터를 블록 단위로 가져와 프로세서에 워드 단위로 전달하여 속도를 높인다. 그리고 데이터가 이동하는 통로(대역폭)를 확대하여 프로세서와 메모리의 속도 차이를 줄인다.(캐시는 메인 메모리와 크기가 동일한 블록 여러 개로 구성되는데, 보통 8~64바이트 정도 크기의 블록으로 구성된다.)
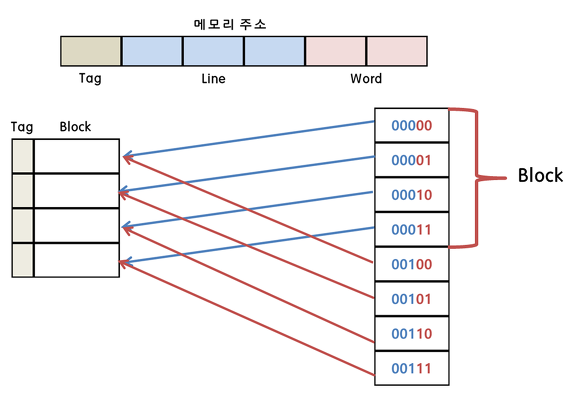
캐시는 주소 영역을 한 번 읽어 들일 수 있는 크기로 나눈 후 각 블록에 번호를 부여하여 이 번호를 태그로 저장한다. 프로세서는 메인 메모리에 접근하기 전에 캐시에 해당 주소의 자료가 있는지 먼저 확인한다. 이를 위해 접근하려는 주소 24비트 중 태그에 해당하는 처음 22비트를 캐시의 모든 라인과 비교하여 일치하는 라인을 찾는다. 일치하는 라인이 있으면, 주소의 나머지 2비트를 이용하여 데이터 라인의 4개 바이트 중 해당하는 바이트를 가져온다.
만약 해당 주소로 캐시에 자료가 있다면 캐시 적중, 없다면 캐시 실패(미스) 라고 한다. 보통 캐시에 데이터를 적재할 때, 적용하는 이론이 있다. 공간적 지역성(대부분의 프로그램이 참조한 주소와 인접한 주소의 내용을 다시 참조),시간적 지역성(한번 참조한 주소를 곧 다시 참조하는 특성)이다.
- 프로그램이 명령어를 순차적으로 실행하는 경향이 있어 명렁어가 특정 지역 메모리에 인접해 있다.
- 순환 때문에 프로그램을 반복하더라도 메모리는 일부 영역만 참조한다.
- 대부분의 컴파일러를 메모리에 인접한 블록에 배열로 저장한다. 따라서 프로그램이 배열 원소에 순차적으로 자주 접근하므로 지역적인 배열 접근 경향이 있다.
4. 보조기억장치
주변장치 중 프로그램과 데이터를 저장하는 하드웨어로 2차 기억장치 또는 외부기억장치라고 한다. 자기디스크, SSD 등이 있다.
5. 시스템 버스
시스템 버스는 하드웨어를 물리적으로 연결하여 서로 데이터를 주고 받을 수 있게 하는 통로이다. 컴퓨터 내부의 다양한 신호(데이터 입출력신호, 프로세서 상태 신호, 인터럽트 요구와 허가 신호, 클록 신호 등)를 시스템 버스로 전달한다. 시스템 버스는 기능에 따라 데이터 버스, 주소 버스, 제어 버스로 구분한다.
| 종류 | 설명 |
| 데이터 버스 | 프로세서와 메인 메모리, 주변장치 사이에서 데이터를 전송한다. 데이터 버스를 구성하는 배선 수는 프로세서가 한 번에 전송할 수 있는 비트 수를 결정하는데, 이를 워드라고 한다. |
| 주소 버스 | 프로세서가 시스템의 구성 요소를 식별하는 주소 정보를 전송한다. 주소 버스를 구성하는 배선 수는 프로세서와 접속할 수 있는 메인 메모리의 최대 용량을 결정한다. |
| 제어 버스 | 프로세서가 시스템의 구성 요소를 제어하는 데 사용한다. 제어 신호로 연산장치의 연산 종류와 메인 메모리의 읽기나 쓰기 동작을 결정한다. |
6. 주변장치
주변장치는 프로세서와 메인 메모리를 제외한 나머지 하드웨어 구성요소이다.
- 입력장치 : 컴퓨터에서 처리할 데이터를 외부에서 입력하는 장치이다.
- 출력장치 : 입력장치와 반대로 컴퓨터에서 처리한 데이터를 외부로 보내는 장치이다.
- 저장장치 : 메인 메모리와 달리 거의 영구적으로 데이터를 저장하는 장치이다. 데이터를 입력하여 저장하며, 저장한 데이터를 출력하는 공간이므로 입출력장치에 포함하기도 한다.
컴퓨터 시스템의 동작
그렇다면 위의 하드웨어들을 종합하여 동작하는 컴퓨터 시스템의 동작은 어떻게 이루어질까?
- 입력장치로 정보를 입력받아 메모리에 저장한다.
- 메모리에 저장한 정보를 프로그램 제어에 따라 인출하여 연산장치에서 처리한다.
- 처리한 정보를 출력장치에 표시하거나 보조기억장치에 저장한다.
입력장치로 컴퓨터에 유입되는 정보는 명령어와 데이터로 분류한다. 명령어는 실행할 산술,논리 연산의 동작을 명시하는 문장으로, 어떤 작업을 수행하는 명령어의 잡합이 프로그램이다. 프로그램은 컴파일러 등을 이용하여 0과 1로 이진화된 기계 명령어로 변환해야 컴퓨터가 이해할 수 있다.
명령어의 구조
명령어는 프로세서가 실행할 연산인 연산부호와 명령어가 처리할 데이터, 데이터를 저장한 레지스터나 메모리 주소인 피연산자로 구성된다. 명령어는 프로세서에 따라 고정 길이나 가변길이를 구성한다. 연산 부호는 특별한 경우가 아니면 한 개이나 피연산자는 여러개 일 수 있다.
| 연산 부호 | 피연산자 1 | ... | 피연산자 n |
- 연산 부호(OPcode) : 프로세서가 실행할 동작인 연산을 지정한다. 예를 들어, 산순 연산(+,-,*,/), 논리연산(AND,OR,NOT..), 시프트, 보수 등 연산을 정의한다. 연산 부호가 n비트이면 최대 2^n개 연산이 가능하다.
- 피연산자(operand) : 연산할 데이터 정보를 저장한다. 데이터는 레지스터나 메모리, 가상기억장치, 입출력장치 등에 위치할 수 있다. 보통 데이터 자체보다는 데이터의 위치 주소 값을 저장한다. 일반적으로는 아래와 같은 명령어 구조를 갖는다.
| 연산 부호 | 피연산자 1(목적지 피연산자) | 피연산자 2(소스 피연산자) |
y = x + b
y->목적지 피연산자
x,b->소스 피연산자
+->연산 부호
y = x + b
y->목적지 피연산자
x,b->소스 피연산자
+->연산 부호
명령어는 실행 전에 메인 메모리에 저장하며, 한 번에 하나씩 프로세서에 순차적으로 전송하여 해석,실행한다.
누산기 : 메모리에서 읽은 피연산자를 레지스터에 저장된 데이터와 연산할 때 사용하는 프로세서의 레지스터이다. 누산기는 프로그램의 명령어 수행 중에 산술,논리 연산의 결과를 일시적으로 저장한다.
누산기 : 메모리에서 읽은 피연산자를 레지스터에 저장된 데이터와 연산할 때 사용하는 프로세서의 레지스터이다. 누산기는 프로그램의 명령어 수행 중에 산술,논리 연산의 결과를 일시적으로 저장한다.
명령어에 피연산자의 위치를 명시하는 방법에는 두가지 방법이 있다. 피연산자에 데이터가 있는 레지스터나 메모리 주소를 지정하면 직접 주소라 하고, 데이터가 있는 레지스터나 메모리 주소 정보를 지정하면 간접 주소라고한다.
| 모드 비트 | 연산 부호 | 피연산자 |
위의 명령어 구조에서 모드 비트가 0이면 간접 주소, 1이면 직접 주소이다. 아래의 예를 보면,
<직접 주소>
| 1 | 101 | 001001 |
직접 주소지정 방식이며 001001(9)번 주소에 참조할 데이터가 있으므로 데이터는 한번의 메모리 참조로 가져올 수 있다.
<간접 주소>
| 0 | 101 | 001001 |
간접 주소지정 방식이며 001001(9)번 주소에 데이터의 주소 값이 저장되어 있어 001001 주소에 있는 주소 데이터를 다시 한번 참조하여 데이터를 가져온다. 즉, 데이터를 가져오기 위해 두번 참조한다.
명령어의 실행
- 명령어 인출 : 명령어 레지스터에 저장된 다음 명령어를 인출한다.
- 명령어 해석, 프로그램 카운터 변경 : 인출한 명령어를 해석하고 다음 명령어를 지정하려고 프로그램 카운터를 변경한다.
- 피연산자 인출 : 명령어가 메모리에 있는 워드를 한 개 사용하려면 사용 장소를 결정하여 피연산자를 인출하고, 필요하면 프로세서 레지스터로 보낸다.
- 명령어 실행
- 결과 저장
- 다음 명령어로 이동(1번부터 다시 시작)
프로세서의 제어장치가 명령어를 실행한다. 프로세서는 메모리에서 명령어를 한 번에 하나씩 인출하고 해석하여 연산한다. 명령어를 인출하여 연산 완료한 시점까지를 인출-해석-실행 사이클 또는 인출-실행 사이클이라고 한다. 간단히 명령어 실행 사이클이라고도 한다.
| 인출 사이클 | 실행 사이클 | ||
| 시작-> | 인출-> | 실행-> | 종료 |
인출 사이클
인출 사이클은 명렁어 실행 사이클의 첫 번째 단계이다. 인출 사이클은 메모리에서 명령어를 읽어 명령어 레지스터에 저장하고, 다음 명령어를 실행하려고 프로그램 카운터를 증가시킨다.
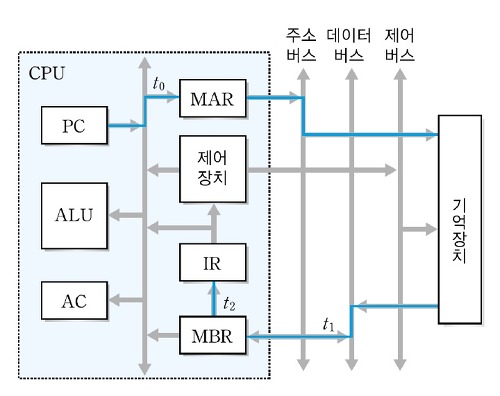
| 시간 | 레지스터 동작 | 설명 |
| 1 | PC -> MAR | PC에 저장된 주소를 프로세서 내부 버스를 이용하여 MAR에 전달한다. |
| 2 |
Memory(MAR 저장된 주소) ->MBR |
MAR에 저장된 주소에 해당하는 메모리 위치에서 명령어를 인출할 후 이 명령어를 MBR에 저장한다. 이때 제어장치는 메모리에 저장된 내용을 읽도록 제어 신호를 발생시킨다. |
| PC + 1 -> PC | 다음 명령어를 인출하려고 PC를 증가시킨다. | |
| 3 | MBR -> IR | MBR에 저장된 내용을 IR에 전달한다. |
실행 사이클
실행 사이클에서는 인출한 명령어를 해석하고 그 결과에 따라 제어 신호를 발생시켜 명령어를 실행한다.
간접 사이클
직접 주소 지정 방법을 사용하는 실행 사이클은 명령어를 즉시 수행하지만, 간접 주소 지정 방법을 사용하는 실행 사이클은 명령어를 수행하기 전에 실제 데이터가 저장된 주기억장치의 주소인 유효 주소를 한번 더 읽어 온다.
| 시간 | 레지스터 동작 | 설명 |
| 1 | IR(addr) -> MAR | IR에 저장된 명령어의 피연산자를 MAR에 전달한다. |
| 2 |
Memoroy(MAR 저장된 주소) -> MBR |
MAR에 저장된 주소에 해당하는 메모리 위치에서 데이터를 인출한 후 이 데이터를 MBR에 저장한다. 이때 제어장치는 메모리에 저장된 내용을 읽도록 제어 신호를 발생시킨다. |
| 3 | MBR -> IR | MBR에 저장된 내용을 IR에 전달한다. |
인터럽트 사이클
인터럽트는 프로세서가 프로그램을 수행하는 동안 컴퓨터 시스템의 내부나 외부에서 발생하는 예기치 못한 사건을 의미한다. 프로세서는 실행 사이클을 완료한 후 인터럽트 요구가 있는 지 검사한다. 인터럽트 요구가 없다면 다음 명령어를 인출하고, 인터럽트 요구가 있으면 현재 수행 중인 프로그램의 주소(프로그램 카운터) 값을 스택이나 메모리의 0번지와 같은 특정 장소에 저장한다. 그리고 프로그램 카운터에는 인터럽트 처리 루틴의 시작 주소를 저장해 두었다가 인터럽트 처리를 완료하면 중단된 프로그램으로 복귀하여 계속 수행한다.
| 시간 | 레지스터 동작 | 설명 |
| 1 | PC -> MBR | PC의 내용을 MBR에 저장한다. |
| 2 | IntRoutine_Address -> PC | 인터럽트 루틴 주소를 PC에 저장한다. |
| Save_Address -> MAR | PC에 저장된 인터럽트 루틴 주소를 MAR에 저장한다. | |
| 3 | MBR -> Memory(MAR) | MBR의 주소에 있는 내용을 지시된 메모리 셀로 이동한다. |
인터럽트는 현재 실행 중인 프로그램을 중단하고 다른 프로그램의 실행을 요구하는 명령어이다. 시스템의 처리 효율을 향상시키며, 프로그램이 실행 순서를 바꿔 가면서 처리하여 다중 프로그래밍에 사용한다.
또 인터럽트는 컴퓨터에 설치된 입출력장치나 프로그램 등에서 프로세서로 보내는 하드웨어 신호이다. 인터럽트를 받은 프로그램은 실행을 중단하고 다른 프로그램을 실행한다. 단일 프로세서의 컴퓨터는 명령어를 한 번에 한 개만 수행할 수 있지만, 인터럽트를 이용하면 중간에 다른 프로그램이나 명령어를 수행할 수 있다. 특히 인터럽트는 예상치 못한 사용자 입력, 갑작스런 정전, 컴퓨터 시스템에서 긴급 요청, 잘못된 명령어 수행, 입출력 작업 완료와 같은 상황을 시스템이 적절히 처리하는데 필요하다.
제어 버스 중에는 인터럽트 요청 회선(IRQ)이 있다. 인터럽트 요청 회선을 사용하면 키보드에서 입력이 발생하였을 때만 프로세서에 통보하여 처리하므로 프로세서가 일일이 입출력장치의 상태를 폴링하고 있을 필요가 없다.
인터럽트는 크게 인터럽트 요청과 인터럽트 서비스 루틴으로 구분할 수 있다. 인터럽트 요청 신호에 따라 수행하는 루틴이 인터럽트 처리 프로그램, 즉 인터럽트 서비스 루틴이다.
인터럽트가 도달하기 전에 프로그램 A를 실행하고 있고 인터럽트가 발생했다고 가정하면 프로세서에 인터럽트 신호가 도달하여 현재 프로그램 A의 명령어를 종료한다. 레지스터의 모든 내용을 스택 영역에 보낸다. 그리고 프로그램 카운터는 인터럽트 처리 프로그램(프로그램 B)의 시작 위치를 저장하고 제어를 넘긴 프로그램 B를 실행한다. 프로그램 B가 수행이 완료되면 스택 영역에 있던 내용을 레지스터에 다시 저장하며, 프로그램 A가 다시 시작하는 위치를 저장하고 중단했던 프로그램 A를 재실행한다.
인터럽트는 서브루틴 호출과 매우 비슷하지만, 몇 가지 면에서 다르다. 보통 서브루틴은 자신을 호출한 프로그램이 요구한 기능을 수행하지만, 인터럽트 처리 프로그램은 인터럽트가 발생했을 때 실행 중인 프로그램과 관련이 없을 수 있다. 그러므로 프로세서는 인터럽트 프로그램을 처리하기 전에 프로그램 카운터를 비롯해 중단된 프로그램으로 복귀하여 실행할 때 영향을 미치는 정보를 모두 저장해야한다.
여기까지 컴퓨터의 핵심이 되는 하드웨어들을 아주 간단히 다루어보았다. 사실 필자가 요즘 느끼고 있는 것이 기초가 중요하다라는 것이다. 이전에는 이론이 아닌 스킬베이스의 공부만 주로 하다보니 시간이 지날수록 기초의 탄탄함의 중요성이 느껴지고 코딩에도 해당 이론이 아주 중요할 때가 있다. 오늘은 간단하게 하드웨어들을 뭔지 정도만 다루어 보았고 다음 포스팅은 아마 진짜 운영체제에 대한 포스팅이 될 듯하다.
'인프라 > 운영체제' 카테고리의 다른 글
| 운영체제 - 디스크 사용량 및 정보 확인 (0) | 2020.08.22 |
|---|---|
| 운영체제 - 상호배제와 동기화(뮤텍스,TAS,세마포어,모니터) (0) | 2019.07.28 |
| 운영체제 - 병행 프로세스란? (0) | 2019.07.28 |
| 운영체제 - 쓰레드란?(Thread,사용자 수준 쓰레드, 커널 수준 쓰레드, 혼합형 쓰레드) (1) | 2019.07.27 |
| 운영체제 - 프로세스(Process)란? 프로세스상태,Context Switching (0) | 2019.07.27 |