
'웹서버'에 해당되는 글 2건
- 2020.08.22 :: Web Server - Nginx 설치 및 사용방법(nginx cache, reverse proxy, 프록시, 캐시)
- 2020.02.01 :: Netty - 네티 개념과 아키텍쳐

오늘 포스팅해볼 내용은 Web server 중 하나인 Nginx의 설치 및 사용방법에 대해 다루어본다. 우선 Nginx는 무엇인가 알아보자.
예제 설정은 아래 깃헙사이트에 있다.
yoonyeoseong/kubernetes-sample
Kubernetes(쿠버네티스) sample. Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
Wiki(https://ko.wikipedia.org/wiki/Nginx)
Nginx(엔진 x라 읽는다)는 웹 서버 소프트웨어로, 가벼움과 높은 성능을 목표로 한다. 웹 서버, 리버스 프록시 및 메일 프록시 기능을 가진다.
2017년 10월 기준으로 실질적으로 작동하는 웹 사이트(active site)들에서 쓰이는 웹 서버 소프트웨어 순위는 아파치(44.89%), 엔진엑스(20.65%), 구글 웹 서버(7.86%), 마이크로소프트 IIS(7.32%)순이다.[1] 이 조사에서 생성은 되어있으나 정상적으로 작동하지 않는 웹 사이트들은 배제되었으며[2] 특히 MS의 인터넷 정보 서비스(IIS)를 설치한 웹 사이트들의 상당수가 비활성 사이트였다. 그런 사이트들도 포함하면 MS IIS가 1위이다. 2017년 6월 현재 Nginx는 한국 전체 등록 도메인 중 24.73%가 사용하고 있다.[3]
Nginx는 요청에 응답하기 위해 비동기 이벤트 기반 구조를 가진다. 이것은 아파치 HTTP 서버의 스레드/프로세스 기반 구조를 가지는 것과는 대조적이다. 이러한 구조는 서버에 많은 부하가 생길 경우의 성능을 예측하기 쉽게 해준다.
또한 nginx는 하나의 마스터 프로세스와 여러 워커 프로세스가 있고, 마스터 프로세스는 주로 설정 파일을 읽고 적용하며 워커 프로세스들을 관리하는 역할을 하게 된다. 워커 프로세스는 실제 요청에 대한 처리를 하게 된다. nginx는 event driven 모델을 메커니즘으로 사용하여 실제 워커 프로세스간 요청을 효율적으로 분산한다.
실습은 Mac os 기준으로 실습을 진행해 볼것이다. 우선 nginx를 설치해보자.
Nginx install
> brew install nginx
brew로 설치를 아래와 같은 디렉터리들이 생성된다. 우선 아래 디렉토리를 실습을 진행하면서 전부 알아볼 것이다.
Docroot is: /usr/local/var/www
The default port has been set in /usr/local/etc/nginx/nginx.conf to 8080 so that
nginx can run without sudo.
nginx will load all files in /usr/local/etc/nginx/servers/.
To have launchd start nginx now and restart at login:
brew services start nginx
Or, if you don't want/need a background service you can just run:
nginx
==> Summary
🍺 /usr/local/Cellar/nginx/1.19.2: 25 files, 2.1MB
==> Caveats
==> nginx
Docroot is: /usr/local/var/www
The default port has been set in /usr/local/etc/nginx/nginx.conf to 8080 so that
nginx can run without sudo.
nginx will load all files in /usr/local/etc/nginx/servers/.
To have launchd start nginx now and restart at login:
brew services start nginx
Or, if you don't want/need a background service you can just run:
nginx
Nginx 구동 명령어(nginx -s <signal>
- nginx : 서버시작
- nginx -s stop : 서버종료(워커들이 요청을 처리중이더라도 그냥 종료한다.)
- nginx -s quit : 워커 프로세스가 현재 요청 처리를 완료할 때까지 대기하고 모두 처리완료된 후에 서버 종료.
- nginx -s reload : nginx config를 새로 로드한다. 마스터 프로세스가 설정을 다시 로드하라는 요청을 받으면 설정 유효성 검사후 새로운 워커 프로세스를 시작하고, 이전 워커 프로세스에게 종료 메시지를 보내게 되고 이전 워커 프로세스는 요청을 완료하게 되면 종료된다.
위 명령어로 nginx를 시작 해보자 !
> nginx
> lsof -i:8080
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 88891 yun-yeoseong 6u IPv4 0x7370b7ed168f296f 0t0 TCP *:http-alt (LISTEN)
nginx 88892 yun-yeoseong 6u IPv4 0x7370b7ed168f296f 0t0 TCP *:http-alt (LISTEN)
#실행중인 모든 nginx 프로세스 목록을 가져온다.
> ps -ax | grep nginx
88891 ?? 0:00.00 nginx: master process nginx
88892 ?? 0:00.01 nginx: worker process
89201 ttys000 0:00.03 vi nginx.conf
89695 ttys001 0:00.00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn nginx
디폴트 포트인 8080으로 nginx 프로세스가 잘 떠있다. 이제 웹브라우저에서 localhost:8080으로 접속해보자.
> curl localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
브라우저에 welcome to nginx가 보인다면 설치 및 실행이 잘된 것이다 ! 어 그렇다면, 여기서 조금 의아한 것이 있을 것이다. 과연 저 html은 어디서 응답을 준것일까?
Docroot
답은 도큐먼트 루트에 있다. 설치를 하면 아래와 같은 로그가 출력되어있을 것인데, 해당 디렉토리 내에 html 파일이 존재한다.
Docroot is: /usr/local/var/www
기본적으로 웹서버는 다른 서버로 프록시 하지 않는 이상 uri로 명시한 path로 도큐먼트 루트 디렉토리를 찾아서 응답을 주게 된다. 사실 localhost:8080은 localhost:8080/index.html과 같다고 보면된다. 그렇다면 index.html의 위치를 바꾸면 어떻게 될까?
> cd /usr/local/var/www
> mkdir backup
> mv index.html ./backup
이제 아래 요청을 보내보자.
> curl localhost:8080/index.html
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.19.2</center>
</body>
</html>
우리는 index.html을 다른 디렉토리로 옮겼기 때문에 404 not found가 뜨게 된다. 그렇다면 옮긴 디렉토리 path를 명시해서 요청을 보내보자.
> curl http://localhost:8080/backup/index.html
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
응답이 잘 도착하였다. 보통 도큐멘트 루트는 어떻게 사용이 될까? 보통은 정적인 리소스 파일(css, html)을 위치시키게 된다. 그렇다면 정적인 리로스 파일을 위치시키는 이유는 무엇일까? 만약 WAS에 해당 정적인 리소스 파일을 위치시키게 되면, 사실상 서버 동작과 관련이 적은 정적 리소스를 가져오기 위한 요청도 모두 WAS로 들어가기 때문에 앱에 부하가 많이 가게 될수 있다. 그렇기 때문에 보통 정적인 리소스는 nginx(웹서버)에서 처리하고 WAS는 백엔드 데이터만 제공하게 하여 WAS의 부담을 줄여줄 수 있다.
이제는 본격적으로 Nginx의 설정을 커스터마이징해보자.
Configuration file's structure
nginx의 설정 파일은 simple directives(단순 지시문)과 block directives(블록 지시문)으로 나뉜다. 단순 지시문을 공백으로 구분 된 이름과 매개변수로 구성되며 세미콜론(;)으로 끝난다. 블록 지시문은 단순 지시문과 구조가 동일하지만 세미콜론 대신 중괄호({})로 명령 블록을 지정한다. 또한 블록지시문을 블록지시문의 중첩구조로도 이루어 질 수 있다. 이러한 지시문으로 nginx에 플러그인 된 여러 모듈을 제어하게 된다.
Nginx Configuration
nginx.conf 파일에는 nginx의 설정 내용이 들어간다. 해당 파일의 전체적인 구조(모듈)는 아래와 같이 이루어져있다.
user nginx;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
#응답의 기본 default mime type을 지정
default_type application/octet-stream;
charset utf-8;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
#지정된 에러 코드에 대해 응답나갈 document root의 html 파일을 지정
#docroot의 html말고 다른 URL로 리다이렉션 가능하다.
error_page 500 502 503 504 /50x.html;
#error_page 500 502 503 504 http://example.com/error.html
sendfile on;
tcp_nopush on;
keepalive_timeout 65;
#keepalive로 유지되는 커넥션으로 최대 처리할 요청수를 지정
#keepalive_requests 100;
#nginx의 버전을 숨길 것인가에 대한 옵션이다. 보안상 활성화하는 것을 권장한다.
server_tokens on;
#응답 컨텐츠를 압축하는 옵션, 해당 옵션말고 gzip관련 다양한 옵션 존재(압축 사이즈 등등)
gzip on;
#context : http, server, location
#클라이언트 요청 본문을 읽기 위한 버퍼 크기를 설정 64bit platform default 16k
client_body_buffer_size 16k;
#클라이언트 요청 본문을 읽기 위한 타임아웃 시간 설정
client_body_timeout 60s;
#클라이언트 요청 헤더를 읽기위한 버퍼 크기 설정
client_header_buffer_size 1k;
client_header_timeout 60s;
#클라이언트가 보낸 요청 본문의 최대 사이즈
client_max_body_size 1m;
server {
listen 80;
location / {
root html;
index index.html index.htm;
}
}
}
- Core 모듈 설정 : 위 예제의 worker_processes와 같은 지시자 설정 파일 최상단에 위치하면서 nginx의 기본적인 동작 방식을 정의한다.
- http 모듈 블록 : 밑에서 설명할 server, location의 루트 블록이라고 할 수 있고, 여기서 설정된 값을 하위 블록들은 상속한다. http 블록은 여러개를 사용할 수 있지만 관리상의 이슈로 한번만 정의하는 것을 권장한다. http, server, location 블록은 계층구조를 가지고 있고 많은 지시어가 각각의 블록에서 동시에 사용될 수 있는데, http의 내용은 server의 기본값이 되고, server의 지시어는 location의 기본값이 된다. 그리고 하위의 블록에서 선언된 지시어는 상위의 선언을 무시하고 적용된다.
- server 블록 : server 블록은 하나의 웹사이트를 선언하는데 사용된다. 가상 호스팅(vhost)의 개념이다.
- location 블록 : location 블록은 server 블록 안에 정의하며 특정 URL을 처리하는 방법을 정의한다. 예를 들어 uri path마다 다르게 요청을 처리하고 싶을 때 해당 블록 내에 정의한다.
- events 블록 : nginx는 event driven을 메커니즘으로 동작하는데, 이 event driven 동작 방식에 대한 설정을 다룬다.
nginx.conf
"user"
user의 값이 root로 되어 있다면 일반 계정으로 변경하는 것이 좋다. nginx는 마스터 프로세스와 워커 프로세스로 동작하고, 워커 프로세스가 실질적인 웹서버의 역할을 수행하는데 user 지시어는 워커프로세스의 권한을 지정한다. 만약 user의 값이 root로 되어 있다면 워커 프로세스를 root의 권한으로 동작하게 되고, 워커 프로세스를 악의적으로 사용자가 제어하게 된다면 해당 머신을 루트 사용자의 권한으로 원격제어하게 되는 셈이기 때문에 보안상 위험하다.
user 설정의 값으로는 대표성있는 이름(nginx)로 사용하고, 이 계정은 일반 유저의 권한으로 쉘에 접속할 수 없어야 안전하다.
> useradd --shell /sbin/nologin www-data
"worker_process"
worker_process는 워커 프로세스를 몇개 생성할 것인지를 지정하는 지시어이다. 이 값이 1이라면 모든 요청을 하나의 프로세스로 실행하겠다는 뜻인데, 여러개의 CPU 코어가 있는 시스템이라면 CPU 코어수만큼 지정하길 권장한다.
"events.worker_connections"
이 값은 몇개의 접속을 동시에 처리할 것인가를 지정하는 값이다. 이 값과 worker_process의 값을 조합해 동시에 최대로 처리할 수 있는 커넥션의 양을 산출할 수 있다.(worker_process*worker_connections)
"http.incloud"
가상 호스트 설정이나, 반복되는 설정들을 파일로 저장해놓고, incloude를 통해 불러올 수 있다.
"http.log_format"
access 로그에 남길 로그 포맷을 지정한다. 보통 어떠한 장애가 났을 때, 가장 먼저보는 것이 로그 파일이기 때문에 디버깅하기 위해 유용한 값들을 로그에 남겨두는 것이 중요하다. 특히나, 여러 프록시 서버를 지나오는 서버 구성인 경우에는 x-forwarded-ip 등을 지정하면 지나온 프록시들의 아이피들을 할 수 있다.
"http.access_log"
access로그를 어느 디렉토리에 남길지 설정한다.
"http.keepalive_timeout"
소켓을 끊지 않고 얼마나 유지할지에 대한 설정이다. 자세한 내용은 keepalive 개념을 확인하자.
"http.server_tokens"
nginx의 버전을 숨길 것인가에 대한 옵션이다. 보안상 활성화하는 것을 권장한다.
기타 설정들은 위 예제 파일에 주석으로 달아놓았다.
다음은 실제 프록시 설정이 들어가는 server 블록 설정을 다루어 보자.
server {
listen 80;
server_name levi.local.com;
access_log logs/access.log;
error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_pass http://app;
}
}
upstream app {
server localhost:8080;
}
위 설정은 http 블록 하위로 들어가게 된다. 크게 어려운 설정은 없고, "levi.local.com:80/"으로 요청이 들어오면 upstream(요청받는 서버)으로 요청을 리버스 프록시 한다라는 뜻이다. 실제로 앱하나를 띄워보고 프록시 되는지 확인해보자.
> curl levi.local.com/api
new api ! - 7
위처럼 응답이 잘오는 것을 볼 수 있다. 그런데 사실 server 블록이 하나일때는 server_name에 적혀있는 도메인으로 오지않아도 응답을 준다. server_name이 진짜 도메인네임을 구분하기 위한 server_name으로 사용되기 위해서는 listen 포트가 같은 server 블록이 두개 이상 존재할때 이다. 아래 예제를 보자.
server {
listen 80;
server_name levi.local.com;
#access_log logs/access.log;
#error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_pass http://app;
}
}
upstream app {
server localhost:8080;
}
server {
listen 80;
server_name local.yoon.com;
#access_log logs/access.log;
#error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_pass http://app2;
}
}
upstream app2 {
server localhost:7070;
}
위와 같이 설정하고, 각 도메인을 분리해서 요청을 보내보자. server_name으로 분리되어 요청이 프록시 될것이다.
Nginx cache
마지막으로 location 블록에 대한 설정중 nginx cache에 설정에 대해 주로 다루어보자.
- /path/to/cache ==> 캐시 내용이 local disk 에 저장될 위치
- levels=1:2 ==> directory depth 와 사용할 name 길이.
- ex ) /data/nginx/cache/c/29/b7f54b2df7773722d382f4809d65029c
- keys_zone ==> 캐시 키로 사용될 이름과 크기. 1MB 는 약 8천개의 이름 저장. 10MB면 8만개.
- max_size ==> 캐시 파일 크기의 maximum. size 가 over 되면 가장 오래전에 사용한 데이터 부터 삭제한다.
- inactive ==> access 되지 않았을 경우 얼마 뒤에 삭제 할 것인가.
- use_temp_path ==> 설정된 path 외에 임시 저장 폴더를 따로 사용할 것인가? 따로 설정하지 않는 것이 좋다.
- proxy_cache <namev> ==> 캐시로 사용할 메모리 zone 이름.
- proxy_cache_methods ==> request method를 정의한다. default : GET, HEAD
- proxy_cache_key ==> 캐시 할 때 사용할 이름.
- proxy_cache_bypass ==> 예를 들어 "http://www.example.com/?nocache=true" 이러한 요청이 왔을 때 캐싱되지 않은 response 를 보낸다. 이 설정이 없다면 nocache 아규먼트는 동작하지 않는다. http_pragma==> 헤더 Pragma:no-cache
- proxy_cache_lock ==> 활성화 시키면 한 번에 단 하나의 요청만 proxy server로 전달되어 proxy_cache_key 에 따라 캐싱된 데이터로 사용합니다. 다른 request 들은 캐싱된 데이터를 사용하거나 proxy_cache_lock_timeout의 설정에 따라 proxy server로 전달 될 수 있습니다.
- proxy_cache_valid ==> 기본적으로 캐싱할 response code 와 시간을 정의한다.
예제 설정으로는 아래와 같다.
proxy_cache_path /usr/local/etc/nginx/cache levels=1:2 keys_zone=myapp:10m max_size=10g inactive=60s use_temp_path=off;
server {
listen 80;
server_name levi.local.com;
access_log logs/access.log;
error_log logs/error.log;
error_page 500 502 503 504 /50x.html;
charset utf-8;
location / {
proxy_cache myapp;
proxy_cache_methods GET;
proxy_cache_key "$uri$is_args$args";
proxy_cache_bypass $cookie_nocache $arg_nocache $http_pragma;
proxy_ignore_headers Expires Cache-Control Set-Cookie;
#proxy_cache_lock on;
#200ok인 응답을 1분동안 캐싱
proxy_cache_valid 200 1m;
proxy_pass http://app;
}
}
upstream app {
server localhost:8080;
}
실제로 캐싱이 잘되는지 요청을 보내보고 실제 캐싱이 저장되는 디렉토리로 들어가보자.
> cd /usr/local/etc/nginx/cache
> ls
8
> cd 8
> ls
68
> cd 68
> ls
5d198634e5fa00f3cf3a478fcdf57688
> vi 5d198634e5fa00f3cf3a478fcdf57688
^E^@^@^@^@^@^@^@û½@_^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ÿÿÿÿÿÿÿÿ¿½@_^@^@^@^@#Y|^V^@^@d^Aè^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
KEY: /api?arg=args
HTTP/1.1 200 ^M
Content-Type: text/html;charset=UTF-8^M
Content-Length: 13^M
Date: Sat, 22 Aug 2020 06:39:59 GMT^M
Connection: close^M
^M
new api ! - 5
응답이 잘 캐싱된것을 볼수 있다. 그리고 대략 1분후에는 해당 캐싱 파일 지워져있다.
여기까지 간단하게 Nginx 설치 및 사용방법에 대해 다루어보았다. 맘 같아선 캐싱에 대해 더 자세히 다루고 싶었다. 대규모 웹사이트 같은 경우는 정말 장비를 늘리는 것으로는 트래픽을 받는데 한계가 있기 때문에 사실상 캐싱 싸움이 될것이기 때문이다. 이번 포스팅에서는 Nginx에 대해 맛보기 정도만 하였지만, 다음 시간에는 조금더 딥한 내용까지 다루어 볼 계획이다.
참조
nginx cache
1. cache dir 설정 proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=cache:2m 2. cache 사용 설정 server { listen 80; server_name cached.test.co.kr; access_log /var/log/nginx/cache-access.log c..
semode.tistory.com
'인프라 > Web Server & WAS' 카테고리의 다른 글
| Web - Http Header의 뜻 (0) | 2019.04.03 |
|---|---|
| 웹 취약성 검사 대비하기 ! (2) | 2018.10.26 |
| tomcat WAS에 spring(spring boot) 여러개의 war파일 배포(여러개 context) (0) | 2018.09.12 |

오늘 다루어볼 포스팅 내용은 Netty의 개념과 아키텍쳐에 대한 대략적인 설명이다. Netty에 대해 알아보기 전에 AS-IS 자바의 네트워킹 동작 방식에 대해 먼저 다루어본다.
자바의 네트워킹
순수 자바로 네트워크 통신을 하기위해서 생긴 최초의 라이브러리는 java.net 패키지이다. 해당 소켓 라이브러리가 제공하는 방식은 블로킹 함수만 지원했다. 해당 라이브러리를 이용한 서버코드를 간단히 보면 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public void blockCall() throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
Socket clientSocket = serverSocket.accept();
BufferedReader in = new BufferedReader(
new InputStreamReader(clientSocket.getInputStream())
);
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);
String request, response;
while ((request = in.readLine()) != null) {
if ("OK".equals(request)) {
break;
}
response = processRequest(request);
System.out.println(response);
}
}
public String processRequest(String request) {
return request + "Done";
}
|
cs |
해당 코드는 한 번에 한 연결만 처리한다. 다수의 동시 클라이언트를 관리하려면 새로운 클라이언트 Socket마다 새로운 Thread를 할당해야한다. 이런식의 블로킹 처리는 어떠한 결과를 초래하게 될 것인가? 여러 스레드가 입력이나 출력 데이터가 들어오기를 기다리며 무한정 대기 상태로 유지될 수 있고, 이것은 고로 리소스의 낭비로 이어진다. 그리고 하나의 연결당 하나의 스레드가 생성되므로, 많은 수의 클라이언트를 관리하기 위해서는 많은 수의 스레드를 생성해야 하고, 이것은 리소스 낭비는 물론 잦은 컨텍스트 스위칭에 의한 오버헤드가 발생하게 된다.
이러한 문제때문에 그 다음 나온 자바의 네트워킹 통신은 자바 NIO방식이다.
자바 NIO
해당 방식은 네트워크 리소스 사용률을 세부적으로 제어할 수 있는 논블로킹 호출이 포함되어 있다. 논블로킹은 내부적으로 시스템의 이벤트 통지 API를 이용해 논블로킹 소켓의 집합을 등록하면 읽거나 기록할 데이터가 준비됐는지 여부를 알 수 있다. 즉, 계속해서 기다릴 필요가 없어지는 것이다.
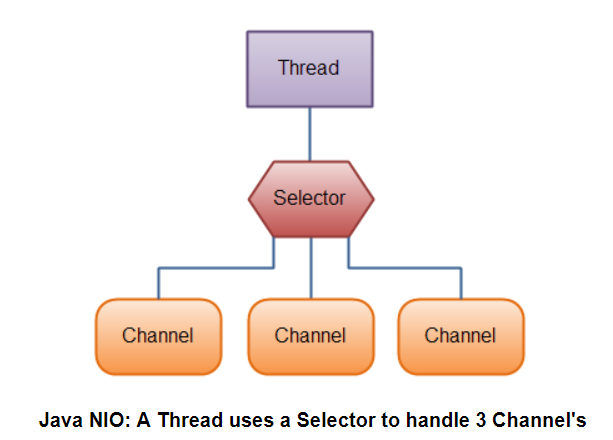
OIO와는 달리 NIO는 채널과 소켓이 1:1 매칭되지 않는다. java.nio.channels.Selector가 논블로킹 Socket의 집합에서 입출력이 가능한 항목을 지정하기 위해 이벤트 통지 API를 이용하기 때문에, 언제든지 읽기나 쓰기 작업의 완료상태를 확인가능하다. 그렇기 때문에 채널당 하나의 쓰레드가 분배되지 않고(블록킹하면 기다리지 않아도) 필요할때마다 쓰레드에게 통지를 하므로써 필요할때만 일을 할 수 있고, 필요하지 않을때는 다른 일을 할 수 있게 한다. 이런식의 처리흐름을 도입함으로써
- 적은 수의 스레드로 더 많은 연결을 처리할 수 있어 메모리 관리와 컨텍스트 스위치에 대한 오버헤드가 준다.
- 입출력을 처리하지 않을 때는 스레드를 다른 작업에 활용할 수 있다.
라는 장점이 생긴다. 하지만 그에 따른 단점이 존재한다면, 순수 자바 라이브러리를 직접 사용해 애플리케이션을 제작하기에는 아주 어렵다. 특히 부하가 높은 상황에서 입출력을 안정적이고 효율적으로 처리하고 호출하는 것과 같이 까다롭고 문제 발생이 높은 일은 어려운 일이기 때문이다.
이러한 어렵고 까다로운 일을 대신해주기 위해 네티와 같은 네트워크 프레임워크가 존재하는 것이다.
Netty(네티)
네티는 위와 같이 어려운 자바의 고급 API를 내부에 숨겨 놓고, 사용자에게 비즈니스 로직에만 집중할 수 있도록 추상화한 API를 제공한다. 또한 적은양의 리소스를 소모하면서 더 많은 요청을 처리할 수 있게 설계되었으므로 확장하기에도 부담이 없다. 아래는 네티의 특징을 요약한 표이다.
| category | feature |
| 설계 | 단일 API로 블로킹과 논블로킹 방식의 여러 전송 유형을 지원하며, 단순하지만 강력한 스레딩 모델을 제공한다. |
| 이용 편의성 | JDK 1/6+을 제외한 추가 의존성이 필요 없다. |
| 성능 | 코어 자바 API보다 높은 처리량과 짧은 지연시간을 갖는다. 풀링과 재사용을 통한 리소스 소비를 감소시켰고, 메모리 복사를 최소화하였다. |
| 견고성 | 저속, 고속 또는 과부하 연결로 인한 OOM이 잘 발생하지 않는다.(요청을 처리하는 스레드 수가 굉장히 적기 때문) 고속 네트워크 상의 NIO 애플리케이션에서 일반적인 읽기/쓰기 비율 불균형이 발생하지 않는다. |
| 보안 | 완벽한 SSL/TLS 및 StarTLS 지원. 애플릿이나 OSGi 같은 제한된 환경에서도 이용 가능. |
비동기식 이벤트 기반 네트워킹
- 네티의 논블로킹 네트워크 연결은 작업 완료를 기다릴 필요가 없다. 완전 비동기 입출력은 이 특징을 바탕으로 한 단계 더 나아간다. 비동기 메서드는 즉시 반환하며 작업이 완료되면 직접 또는 나중에 이를 통지한다.
- 셀렉터는 적은 수의 스레드로 여러 연결에서 이벤트를 모니터링할 수 있게 해준다
위의 특징들을 종합해보면 블로킹 입출력 방식을 이용할 때보다 더 많은 이벤트를 훨씬 빠르고 경제적으로 처리할 수 있다.
네티의 핵심 컴포넌트들
- Channel
- Callback
- Future
- 이벤트와 핸들러
Channel은 하나 이상의 입출력 작업을 수행할 수 있는 하드웨어 장치, 파일, 네트워크 소켓, 프로그램 컴포넌트와 같은 엔티티에 대한 열린 연결을 뜻한다. 쉽게 말해 인바운드 데이터와 아웃바운드 데이터를 위한 운송수단이라고 생각하면 좋을 것 같다.
Callback은 간단히 말해 다른 메서드로 자신에 대한 참조를 제공할 수 있는 메서드다. 관심 대상에게 작업 완료를 알리는 가장 일반적인 방법 중 하나이다. 네티는 이러한 콜백을 내부적으로 이벤트 처리에 사용한다.
Future는 작업이 완료되면 애플리케이션에게 알리는 한 방법이다. 즉, 작업이 완료되는 미래의 어떤 시점에 그 결과에 접근할 수 있게 해준다. 하지만 자바의 Future는 결과를 얻기 위해서는 반드시 블로킹해야만 한다. 그래서 네티는 비동기 작업이 실행됐을 때 이용할 수 있는 자체 구현 ChannelFuture를 제공한다. 더 자세한 내용은 뒤에서 다루어본다.
마지막으로 네티는 이벤트가 들어오면 해당 이벤트를 핸들러 클래스의 사용자 구현 메서드로 전달하여 이벤트를 변환하며 이러한 핸들러의 체인으로 이벤트들을 처리한다. 이벤트와 핸들러 또한 뒤에서 더 자세히 다룬다.