
'2019/11'에 해당되는 글 5건
- 2019.11.26 :: Kubernetes - Kubernetes 아키텍쳐
- 2019.11.26 :: Kubernetes - Kubernetes 용어설명
- 2019.11.22 :: Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법
- 2019.11.20 :: Kubernetes - 쿠버네티스 서비스,인그레스(Service,Ingress) 1
- 2019.11.19 :: Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트)

이전 포스팅에서 쿠버네티스에 대한 용어와 개념을 다루어봤는데, 이번 포스팅에서는 실제 쿠버네티스가 어떤 구조로 되어 있는지 아키텍쳐에 대해 다루어본다.
2019/11/26 - [인프라/Docker&Kubernetes] - Kubernetes - Kubernetes 용어설명
Kubernetes - Kubernetes 용어설명
지금까지 쿠버네티스에 대한 포스팅을 여러개 했는데, 더 진행하기 앞서 쿠버네티스에서 사용하는 용어 및 개념들을 정리하면 좋을듯 해서 포스팅한다. 마스터&노드 쿠버네티스의 클러스터의 구조에서 전체 클러..
coding-start.tistory.com

마스터&노드
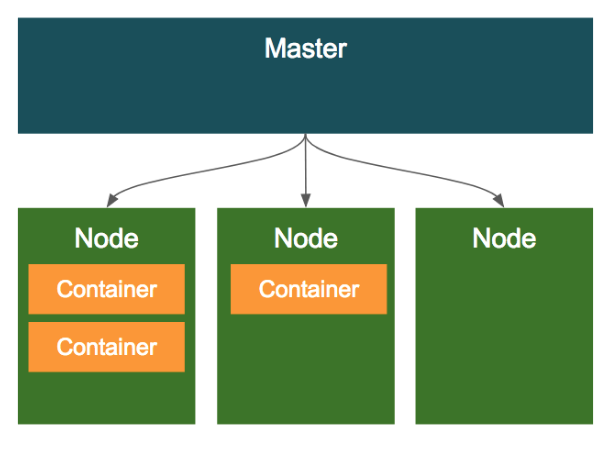
쿠버네티스 클러스터는 크게 마스터와 노드로 구성된다. 마스터는 쿠버네티스 클러스터의 전반적인 것을 관리하고 노드는 Pod이나 Service등처럼 쿠버네티스 위에서 동작하는 워크로드를 호스팅하는 역할을 한다.
1) 마스터
클러스터 전체를 관장하는 시스템이며 크게 API 서버, 스케줄러, 컨트롤러 매니저, etcd로 구성되어 있다.
-API서버 : 쿠버네티스는 모든 명령과 통신을 API를 통해서 하는데, 그 중심이 되는 서버가 API 서버이다.
-Etcd : 쿠버네티스 클러스터의 데이터 베이스 역할을 하는 Key/Value Store이다. 쿠버네티스 클러스터의 상태나 설정 정보를 저장한다.
-스케줄러 : 스케줄러는 Pod, 서비스 등 각 리소스들을 적절한 노드에 할당하는 역할을 한다.
-컨트롤러 매니저 : 컨트롤러 매니저는 컨트롤러(RC,SC,VC,NC)를 생성하고 이를 각 노드에 배포하며 관리하는 역할을 한다.
-DNS : 쿠버네티스는 리소스의 엔드포인트를 DNS로 맵핑하고 관리한다. Pod이나 서비스등은 IP를 배정받는데, 동적으로 생성되는 값이기 때문에 그 리소스에 대한 정보를 DNS로 해결한다. 이러한 패턴을 Service Discovery 패턴이라 한다. 새로운 리소스가 생성되면, 그 리소스의 IP와 DNS를 매핑하여 등록하고 DNS 이름을 기반으로 리소스에 접근할 수 있도록 한다.
2) 노드
노드는 마스터에 의해 명령을 받고 실제 워크로드를 생성하여 서비스 하는 시스템이다. 노드에는 Kubelet, Kube-Proxy, cAdvisor 그리고 컨테이너 런타임이 배포된다.
-Kubelet : 노드에 배포되는 에이전트로, 마스터의 API서버와 통신을 하면서, 노드가 수행해야 할 명령을 받아서 수행하고, 반대로 노드의 상태등을 마스터로 전달하는 역할을 한다.
-Kube-Proxy : 노드로 들어오는 네트워크 트래픽을 적절한 컨테이너로 라우팅하고, 로드밸런싱등 노드로 들어오고 나가는 네트워크 트래픽을 프록시하며 노드와 마스터간의 네트워크 통신을 관리한다.
-Container Runtime : Pod을 통해 배포된 컨테이너를 실행하는 컨테이너 런타임이다.
-cAdvisor : 각 노드에서 기동되는 모니터링 에이전트로, 노드내에서 기동되는 컨테이너들의 상태와 성능등의 정보를 수집하여, 마스터 서버의 API 서버로 전달한다.
여기까지 쿠버네티스 클러스터의 구조에 대해 간단히 살펴봤다. 사실 쿠버네티스를 사용할 때, 이 정보들을 몰라도 사용이 가능할지는 모르겠지만, 원리 혹은 구동방식, 아키텍쳐를 알고 모르고는 이슈 트랙킹하는 데 큰 차이가 있다고 생각이 들기 때문에 꼭 알고 넘어가야하는 개념들인 것 같다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때 (0) | 2020.04.09 |
|---|---|
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |
| Kubernetes - Kubernetes 용어설명 (0) | 2019.11.26 |
| Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법 (0) | 2019.11.22 |
| Kubernetes - 쿠버네티스 서비스,인그레스(Service,Ingress) (1) | 2019.11.20 |

지금까지 쿠버네티스에 대한 포스팅을 여러개 했는데, 더 진행하기 앞서 쿠버네티스에서 사용하는 용어 및 개념들을 정리하면 좋을듯 해서 포스팅한다.
마스터&노드
쿠버네티스의 클러스터의 구조에서 전체 클러스터를 관리하는 마스터 노드가 있고, 도커 컨테이너가 배포되는 노드가 존재한다.
Pod
Pod는 쿠버네티스에서 가장 기본적인 배포 단위로, 하나 이상의 도커 컨테이너의 묶음이다. 쿠버네티스는 컨테이너 단위로 배포하는 것이 아니라, Pod이라는 하나 이상의 도커 컨테이너로 이루어진 단위로 배포가 된다.
그렇다면 개별적인 컨테이너로 배포하지 않고, Pod이라는 단위로 배포하는 이유는 무엇일까?
- Pod 내의 컨테이너는 IP와 Port를 공유한다. 즉, 서로 localhost로 통신이 가능한 것이다.
- Pod 내에 배포된 컨테이너 간에는 디스크 볼륨 공유가 가능하다.
위와 같은 특징을 가지고 있기 때문에 보통 하나 이상의 컨테이너를 포함한 Pod 단위로 배포한다. 그렇다면 이러한 예제로는 어떤 것이 있을 까? 요즘 애플리케이션을 배포할 때는 애플리케이션 하나만 배포하는 것이 아니라, Nginx와 로그 수집기, 예거 등을 같이 배포하는 경우가 많은 데, 보통 이런 조합은 디스크를 공유해야 하거나 서로 HTTP 통신을 해야한다. 하지만 이럴때 서로 다른 컨테이너로 배포할 경우 굉장히 구성이 까다로워질 것이다. 즉, 하나의 Pod 내에 여러 컨테이너로 띄울 경우 위 문제가 어느정도 해결된다.
이렇게 애플리케이션과 애플리케이션이 사용하는 주변 프로그램을 같이 배포하는 패턴을 MSA(Micro Service Architecture)에서 사이드카패턴이라고 한다.
Volume
Pod가 뜰때, 컨테이너마다 로컬 디스크를 생성해서 기동되는데, 이 로컬 디스크의 경우 영구적이지 못하다. 즉, 컨테이너가 리스타트 되거나 새로 배포될때 로컬 디스크의 내용이 유실된다. 그런데 보통 데이터베이스와 같이 영구적으로 파일을 저장해야 하는 경우에는 컨테이너의 리스타트와 상관없이 파일을 영구적으로 저장해야 하는데, 이럴때 볼륨을 마운트해서 사용한다. 즉, Pod에 볼륨을 할당한다는 뜻이다. 이러한 볼륨은 하나의 Pod 내에서 여러 컨테이너가 공유가능하다는 특징을 가지고 있다.
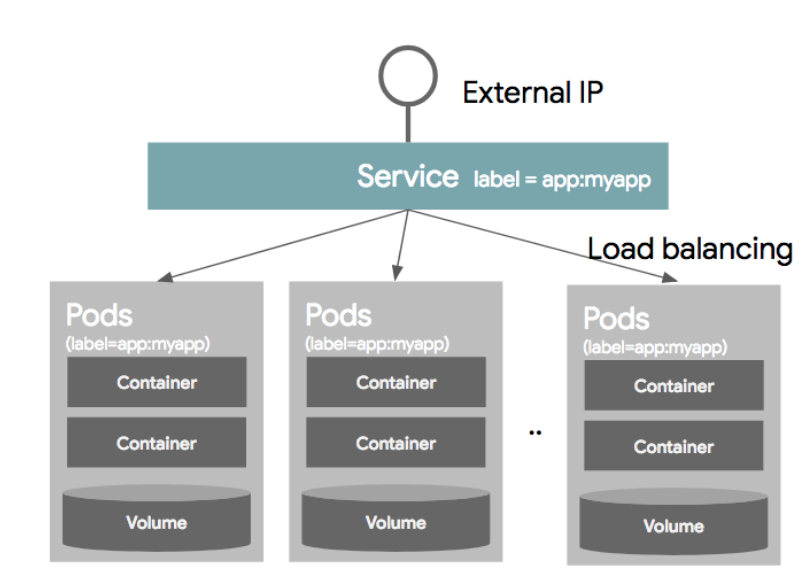
Service
보통의 경우 하나의 Pod으로만 서비스를 제공하지 않는다. 보통은 여러개의 동일한 Pod을 띄워 로드밸런싱하여 서비스를 제공한다. 이럴 경우에 Pod은 동적으로 생성되고 삭제되고, 생성되는 IP는 그때그때 다르기 때문에 이러한 Pod의 디스커버리를 IP로 묶는 것을 쉽지 않다. 그래서 사용되는 것이 Service이고 이는 내부적으로 라벨과 라벨 셀렉터를 이용하여 가용 가능한 Pod을 디스커버리한다.
서비스를 정의할때, 어떤 Pod을 하나의 서비스라는 개념으로 묶을 것인지 정의하는데, 이를 라벨 셀렉터라고 한다. 각 Pod의 Object를 정의할 때, 메타정보에 라벨정보를 넣을 수 있는데, 이 라벨을 Service Object를 정의할때 라벨셀렉터에 넣어준다. 이러면 동일한 라벨을 같은 여러개의 같은 Pod이 동일한 Service 단위로 묶이게 되는 것이다.
Namespace
네임스페이스는 한 쿠버네티스 클러스터 내의 논리적인 분리단위이다. Object들을 네임스페이스 단위로 별도 생성 및 관리가 가능하고, 사용자의 권한 역시 이 네임스페이스 단위로 부여할 수 있다. 보통 개발/운영/테스트 환경을 간혹 네임스페이스 단위로 나누기도 하는데, 왠만하면 클러스터 자체를 분리하는 것이 좋다. 네임스페이스로 나눈다고 해서 물리적인 환경을 분리하는 것이 아니고 단순 논리적인 분리밖에 되지 않아 머신의 리소스를 같이 사용하기 때문이다.
Label
라벨은 쿠버네티스의 리소스를 선택하는데 사용된다. 각 리소스는 라벨을 가질 수 있고, 라벨 검색 조건에 따라 특정 라벨을 가진 리소스만 선택이 가능하다. 라벨은 metadata 부분에 키/값으로 정의 가능하며 하나의 리소스에는 하나 이상의 라벨을 가질 수 있다.
"metadata": {
"labels": {
"key1": "value1",
"key2": "value2"
}
}
라벨 셀렉터를 사용하는 방법으로 2가지 방법을 제공한다. 하나는 Equality based selector와, Set based selector가 있다.
Equality based selector는 단순히 같고,다르다는 조건을 이용하여 라벨을 셀렉하는 방법이다.
- env = dev
- env != product
Set based selector는 집합 개념을 이용한다.
- env in (dev,qa)
- env notin (product,stage)
Controller
컨트롤러는 기본 오브젝트(Pod,Service,Volume,Namespace)들을 생성하고 관리하는 역할을 한다. 컨트롤러는 Replicaion Controller, Replication Set, DaemonSet, Job, StatefulSet, Deployment 들이 있다.
1) Replication Controller
Replication Controller는 Pod을 관리해주는 역할을 하는데, 지정된 숫자로 Pod을 기동시키고, 관리하는 역할을 한다. Replication Controller는 크게 3가지 파트로 구성되는데, Replica의 수, Pod Selector, Pod Template(Spec)으로 구성된다.
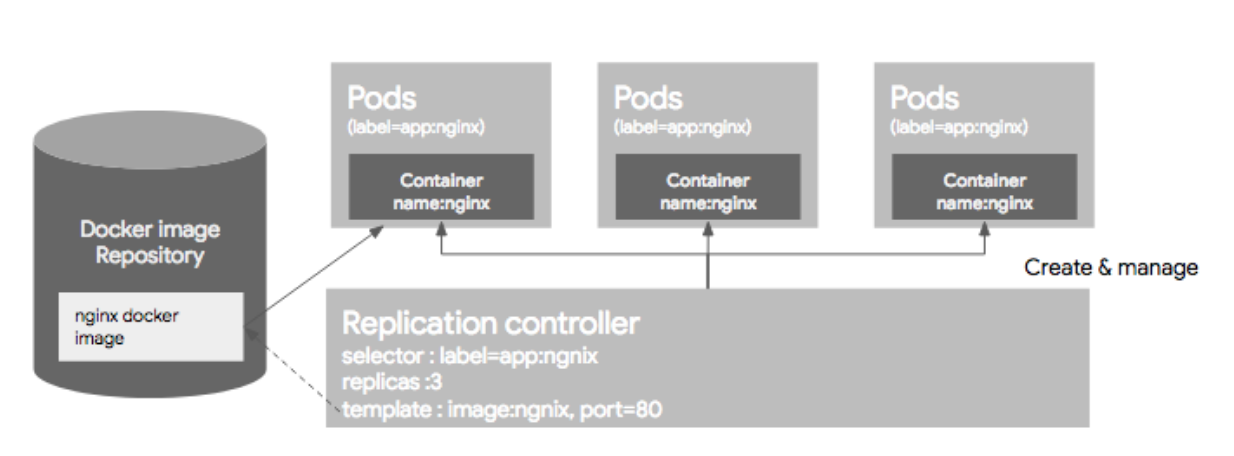
이미 기동된 Pod이 있다면 주의해야할 점이 있다. Pod이 이미 떠있는 상태에서 RC 리소스를 생성하고 그 Pod의 라벨이 RC와 라벨 셀렉터와 일치하면 Pod들은 새롭게 생성된 RC의 컨트롤을 받는다. 만약 해당 Pod들이 RC에서 정의한 replica 수보다 많으면, replica 수에 맞게 Pod들을 삭제하고, 모자르면 template(Spec)에 정의된 되로 Pod을 띄우게 된다. 하지만 여기서 주의할 점이 template(Spec)에 정의된 Pod 리소스 설정과 라벨셀렉터에 의해 픽된 Pod의 리소스 설정이 다르더라도 기존 Pod을 내렸다가 올리지 않는 다는 점이다. 이말은 즉, 싱크가 맞지 않는 형상이 다른 Pod이 뜰 가능성이 있다.
2) ReplicaSet
ReplicaSet은 RC의 새버전이라 생각하면 된다. RC는 Equality 기반 셀럭터를 사용하는데, ReplicaSet은 Set 기반 셀렉터를 이용한다.
3) Deployment
Deployment는 RC와 RS의 좀더 상위 개념이다. 셀제 운영에서는 RC,RS 보다 Deployment를 이용한다. Deployment를 설명하기 전에 배포 방식에 대한 이해가 필요하므로 설명한다.

위와 같은 RC와 Pod들이 있다고 생각하고 새로운 버전의 Pod을 띄우는 상황이라 가정하자. 보통이런 상황에서 Blue/Green 배포와 Rolling Update 배포 방식을 이용한다.
Blue/Green deployment
블루그린 배포 방식은 블루(예전) 버전으로 서비스 하고 있던 시스템은 그린(새로운)버전을 배포한 후, 트래픽을 블루에서 그린으로 한번에 돌리는 방식이다. 여러가지 방법이 있지만 가장 쉬운 방법은 새로운 RC와 Pod들을 모두 띄운 후에 Service의 트래픽을 한번에 새로운 Pod으로 돌리는 방법이다.
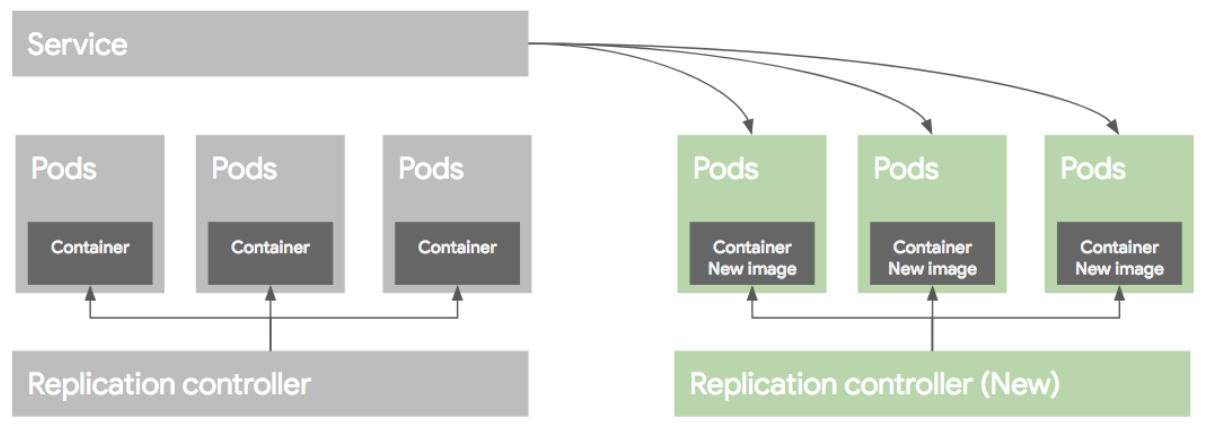
배포후 문제가 없다면 이전 RC와 Pod들을 내려준다.
Rolling update deployment
롤링 업데이트 배포 방식은 Pod을 하나씩 업그레이드 하는 방식이다. 이렇게 배포를 하려면 먼저 새로운 RC를 만든 후에, 기존 RC에서 replica 수를 하나 줄이고, 새로운 RC에는 replica 수를 하나 늘려준다. 이런식으로 하나 줄이고 하나늘리고 하는 방식으로 배포를 하게된다.
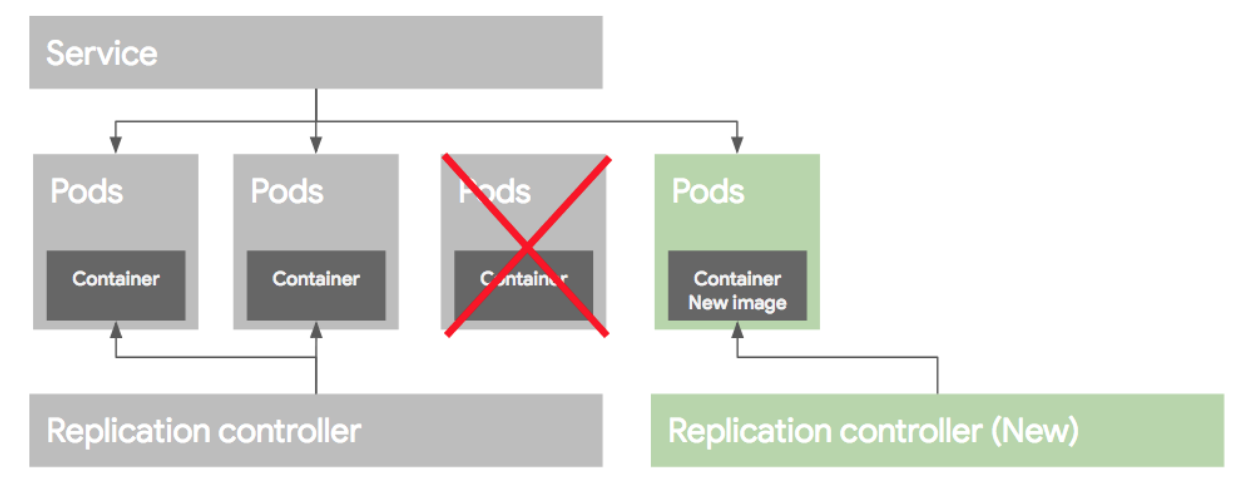

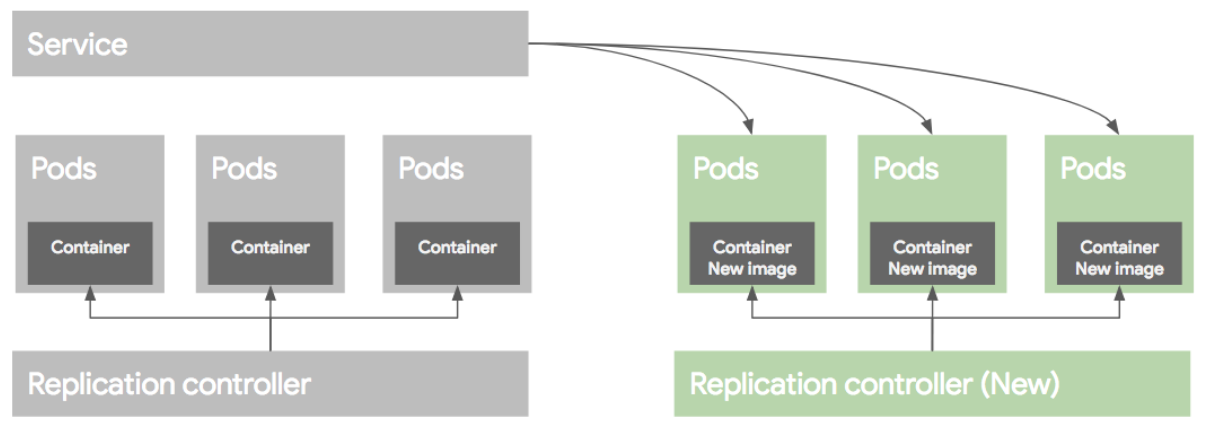
만약 배포가 잘못되었다면 기존 RC의 replica를 원래대로 올리고, 새버전의 replica 수를 0으로 만들어 롤백한다. 이런 롤링 업데이트 배포 방식을 RC 단위로도 가능하지만 여러가지 작업이 필요하다. 그래서 이러한 여러 과정을 추상화한 개념을 Deployment라고 보면 된다.
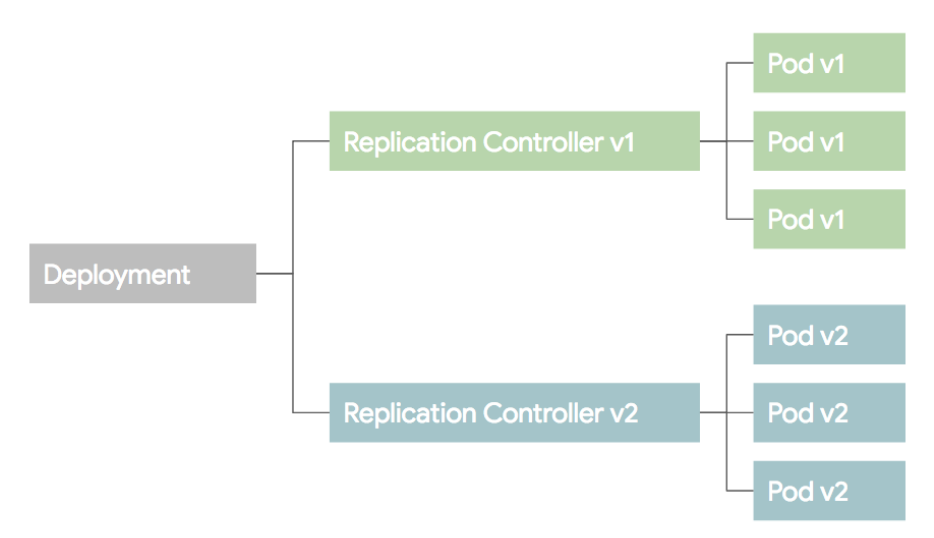
4) DaemonSet
DaemonSet은 Pod가 각각의 노드에서 하나씩만 돌게하는 형태로 Pod을 관리하는 컨트롤러이다. RC, RS 혹은 Deployment로 관리되는 Pod들은 클러스터 노드의 리소스 상황에 따라 비균등적으로 배포되는데, DS에 의해 관리되는 Pod는 모든 노드에 균등하게 하나씩만 배포된다. 보통 서버 모니터링 혹은 로그 수집용도로 많이 사용된다.
DS의 다른 특징중 하나는 특정 Node들에만 Pod들을 하나씩 배포되도록 설정이 가능 하다. 이렇게 특정 노드를 셀렉하기 위해 node selector를 제공하여 특정 노드를 선택가능하도록 지원한다.
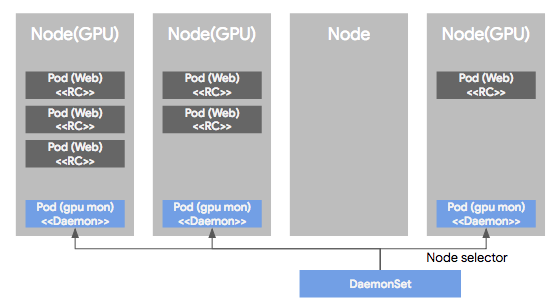
여기까지 간단히 쿠버네티스에서 사용되는 용어들을 다루어봤다. 사실 다루지 못한 용어들이 많이 있지만 추후에 더 다루어볼 예정이다. 다음 포스팅에서는 쿠버네티스 아키텍쳐에 대해 다루어볼 것이다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - Kubernetes 로깅 운영(logging), Fluentd (1) | 2020.02.24 |
|---|---|
| Kubernetes - Kubernetes 아키텍쳐 (0) | 2019.11.26 |
| Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법 (0) | 2019.11.22 |
| Kubernetes - 쿠버네티스 서비스,인그레스(Service,Ingress) (1) | 2019.11.20 |
| Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트) (0) | 2019.11.19 |

보통 쿠버네티스를 사용하면 단일 클러스터 환경에서 운영하지 않는다. 보통 Phase 별로 클러스터를 구성하기도 하고, 각 Phase의 클러스터는 하나 이상의 노드를 갖는 클러스터 형태인 경우가 많다. 또한 쿠버네티스를 사용하면 하나의 애플리케이션 혹은 미들웨어를 디플로이먼트나 서비스, 컨피그맵 혹은 인그레스 등 여러 종류의 리소스를 조합하는 형태로 배포한다.
그런데 각 Phase마다 배포시 달라지는 정보들이 많다. 예를 들면 개발환경의 데이터베이스 주소와 프로덕환경의 데이터베이스 주소가 다른것처럼 말이다. 그렇다면 모든 환경마다 매니페스트를 작성해야하나? 만약 Phase가 많다면 관리가 쉽지 않을 것이다. 이렇게 배포 환경에 따라 달라지는 설정값만 정의해 둔 다음 이에 따라 배포하는 메커니즘이 필요하게 되었는데, 이런 문제를 해결한 것이 헬름(Helm)이다.
Helm is a tool for managing Kubernetes charts. Charts are packages of pre-configured Kubernetes resources.
헬름은 쿠버네티스 차트를 관리하기 위한 도구이다. 차트는 사전 구성된 쿠버네티스 리소스의 패키지다.
헬름은 패키지 관리 도구고, 차트가 리소스를 하나로 묶은 패키지에 해당한다. 헬름으로 차트를 관리하는 목적은 자칫 번잡해지기 쉬운 매니페스트 파일을 관리하기 쉽게 하기 위한 것이다.
실무에서는 로컬 및 운영 클러스터를 막론하고 여러 환경에 배포해야 하는 애플리케이션은 모두 차트로 패키징해 kubectl 대신 헬름으로 배포 및 업데이트를 수행한다. 그 대신 이미 배포된 리소스에 대해 kubectl로 수정한다.
헬름설치
> curl https://raw.githubusercontent.com/helm/helm/master/scripts/get > get_helm.sh
> chmod 700 get_helm.sh
> ./get_helm.sh
필요한 것을 다운로드 받는다.
> helm init
Creating /Users/yun-yeoseong/.helm
Creating /Users/yun-yeoseong/.helm/repository
Creating /Users/yun-yeoseong/.helm/repository/cache
Creating /Users/yun-yeoseong/.helm/repository/local
Creating /Users/yun-yeoseong/.helm/plugins
Creating /Users/yun-yeoseong/.helm/starters
Creating /Users/yun-yeoseong/.helm/cache/archive
Creating /Users/yun-yeoseong/.helm/repository/repositories.yaml
Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com
Adding local repo with URL: http://127.0.0.1:8879/charts
$HELM_HOME has been configured at /Users/yun-yeoseong/.helm.
Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.
To prevent this, run `helm init` with the --tiller-tls-verify flag.
For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation
> kubectl get service,deployment,pod -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/tiller-deploy ClusterIP 10.96.113.96 <none> 44134/TCP 39s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.extensions/tiller-deploy 1/1 1 1 39s
NAME READY STATUS RESTARTS AGE
pod/tiller-deploy-dc4f6cccd-zgvhp 1/1 Running 0 39s
여기까지 잘 따라왔다면 설치는 완료된 것이다. 실제로 helm init 명령을 실행하면 틸러라는 서버 애플리케이션이 kube-system 네임스페이스에 배포되고, 틸러는 helm 명령에 따라 설치 등의 작업을 담당하게 된다.
현재 사용하고 있는 헬름 버전이 낮다면 아래 명령으로 업그레이드하면 된다.
> helm version
> helm init --upgrade //최신버전으로 업그레이드
//특정 버전 헬름 사용
> export TLLER_TAG=2.9.0
> kubectl --namespace=kube-system set image deployments/tiller-deploy tiller=gcr.io/kubernetes-helm/tiller:$TILLER_TAG
헬름의 주요 개념
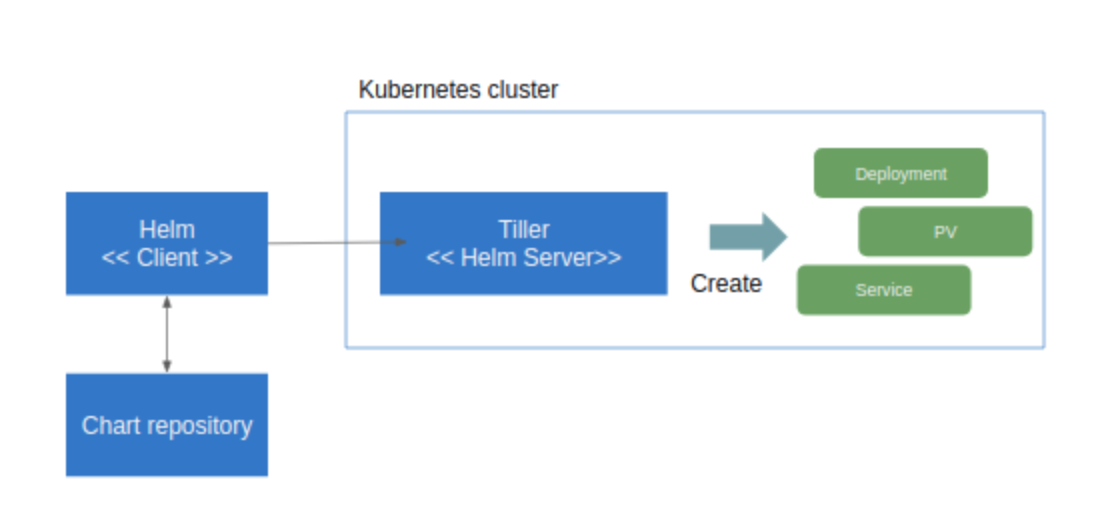
헬름은 클라이언트(cli)와 서버(쿠버네티스 클러스터에 설치되는 틸러)로 구성된다. 클라이언트는 서버를 대상으로 명령을 지시하는 역할을 한다. 서버는 클라이언트에서 전달받은 명령에 따라 쿠버네티스 클러스터에 패키지 설치, 업데이트, 삭제 등의 작업을 수행한다.
쿠버네티스는 서비스나 디플로이먼트, 인그레스 같은 리소스를 생성하고 매니페스트 파일을 적용하는 방식으로 애플리케이션을 배포한다. 이 매니페스트 파일을 생성하는 템플릿을 여러 개 패키징한 것이 차트다. 차트는 헬름 리포지토리에 tgz 파일로 저장되며, 틸러가 매니페스트를 생성하는 데 사용한다.
리포지토리
| 종류 | 내용 |
| local | 헬름 클라이언트가 설치된 로컬 리포지토리로, 로컬에서 생성한 패키지가 존재한다. |
| stable | 안정 버전에 이른 차트가 존재하는 리포지토리다. 안정된 보안 수준과 기본 설정값을 포함하는 등 일정한 요건을 만족하는 차트만 제공될 수 있다. |
| incubator | stable 요건을 만족하지 못하는 차트가 제공되는 리포지토리다. stable로 넘어갈 예정인 차트가 제공된다. |
stable 리포지토리는 기본값으로 사용되는 리포지토리로, 깃헙 helm/charts 리포지토리에 저장된 차트를 사용할 수 있다. incubator 리포지토리는 기본값으로 사용되지는 않으나, 다음과 같이 리포지토리를 추가할 수 있다.
> helm repo add incubator https://kubernetes-charts-incubator.storage.googleapis.com/
리포지토리에서 다음과 같이 차트를 검색할 수 있다. helm search 명령에 지정한 키워드로 검색도 가능하다.
> helm search
차트의 구성
차트는 다음과 같은 디렉터리 구성을 갖는다.
chart_name
->templates
->xxxxx.yaml 각종 쿠버네티스 리소스의 매니페스트 템플릿
->_helper.tpl 매니페스트 랜더링에 사용되는 템플릿 헬퍼
->NOTE.txt 차트 사용법 등의 참조 문서 템플릿
->charts/ 이 차트가 의존하는 차트의 디렉터리
->Chart.yaml 차트 정보가 정의된 파일
->values.yaml 차트 기본값 value 파일
차트 설치하기
차트를 이용해 애플리케이션을 설치하려면 helm install 명령을 사용한다. 설치했던 애플리케이션을 업데이트하거나 삭제하려면 릴리스 네임이 필요하므로 --name 옵션으로 릴리스 네임을 붙여준다. 이 릴리스 네임은 해당 클러스터 안에서 유일한 값이어야 한다.
> helm install [--name 릴리스_네임] 차트_리포지토리/차트명
helm install 명령을 실행하면 차트에 포함된 기본값 value 파일에 정의된 설정값으로 애플리케이션이 설치된다. 그러나 기본값 value 파일을 있는 그대로 사용하는 경우는 드물며, 일부 기본값을 수정한 커스터 value 파일을 주로 사용한다. helm install 예제로 프로젝트 관리 도구인 레드마인의 차트를 이용한다.
예제에서는 사용하지 않을 명령 이것은 기본값을 사용하는 일반적인 설치법이다.
> helm install --name redmine-exam stable/redmine
NAME: redmine-exam
LAST DEPLOYED: Sun Nov 24 17:54:39 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/ConfigMap
NAME AGE
redmine-exam-mariadb 0s
redmine-exam-mariadb-tests 0s
==> v1/Deployment
NAME AGE
redmine-exam 0s
==> v1/PersistentVolumeClaim
NAME AGE
redmine-exam 0s
==> v1/Pod(related)
NAME AGE
redmine-exam-748d45d8f8-8js7k 0s
redmine-exam-mariadb-0 0s
==> v1/Secret
NAME AGE
redmine-exam 0s
redmine-exam-mariadb 0s
==> v1/Service
NAME AGE
redmine-exam 0s
redmine-exam-mariadb 0s
==> v1/StatefulSet
NAME AGE
redmine-exam-mariadb 0s
NOTES:
1. Get the Redmine URL:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
Watch the status with: 'kubectl get svc --namespace default -w redmine-exam'
export SERVICE_IP=$(kubectl get svc --namespace default redmine-exam --template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}")
echo "Redmine URL: http://$SERVICE_IP/"
2. Login with the following credentials
echo Username: user
echo Password: $(kubectl get secret --namespace default redmine-exam -o jsonpath="{.data.redmine-password}" | base64 --decode)
레드마인 로그인 사용자명과 패스워드를 새로 설정하는 예제를 수행할 것이다. 문서에 규정된 설정값을 따라 커스텀 value 파일을 작성한다. 그리고 다음과 같이 인증정보 설정을 담은 redmine.yaml 파일을 작성한다. 또 인그레스 대신 NodePort 서비스를 사용해 서비스를 노출할 것이므로 serviceType 필드의 값을 NodePort로 수정한다.
#redmine.yaml
redmineUsername: yeoseong_gae
redminePassword: yeoseong_gae
redmineLanguage: ja
serviceType: NodePort
위 파일을 작성해준다.
helm install -f redmine.yaml --name redmine-sample stable/redmine --version 4.0.0
NAME: redmine-sample
LAST DEPLOYED: Sun Nov 24 18:01:42 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/ConfigMap
NAME AGE
redmine-sample-mariadb 1s
redmine-sample-mariadb-tests 1s
==> v1/PersistentVolumeClaim
NAME AGE
redmine-sample-redmine 1s
==> v1/Pod(related)
NAME AGE
redmine-sample-mariadb-0 1s
redmine-sample-redmine-769df7c8b5-wdgx9 1s
==> v1/Secret
NAME AGE
redmine-sample-mariadb 1s
redmine-sample-redmine 1s
==> v1/Service
NAME AGE
redmine-sample-mariadb 1s
redmine-sample-redmine 1s
==> v1beta1/Deployment
NAME AGE
redmine-sample-redmine 1s
==> v1beta1/StatefulSet
NAME AGE
redmine-sample-mariadb 1s
NOTES:
1. Get the Redmine URL:
export NODE_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[0].nodePort}" services redmine-sample-redmine)
export NODE_IP=$(kubectl get nodes --namespace default -o jsonpath="{.items[0].status.addresses[0].address}")
echo http://$NODE_IP:$NODE_PORT/
2. Login with the following credentials
echo Username: yeoseong_gae
echo Password: $(kubectl get secret --namespace default redmine-sample-redmine -o jsonpath="{.data.redmine-password}" | base64 --decode)
위와 같이 작성한 redmine.yaml 파일을 인자로 포함시켜 레드만을 차트를 설치하였다. 설치가 끝나면 다음과 같이 릴리스 네임의 목록을 확인할 수 있다.
> helm ls
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
redmine-sample 1 Sun Nov 24 18:01:42 2019 DEPLOYED redmine-4.0.0 3.4.6 default
레드마인 리소스가 생성됐는지 확인한다.
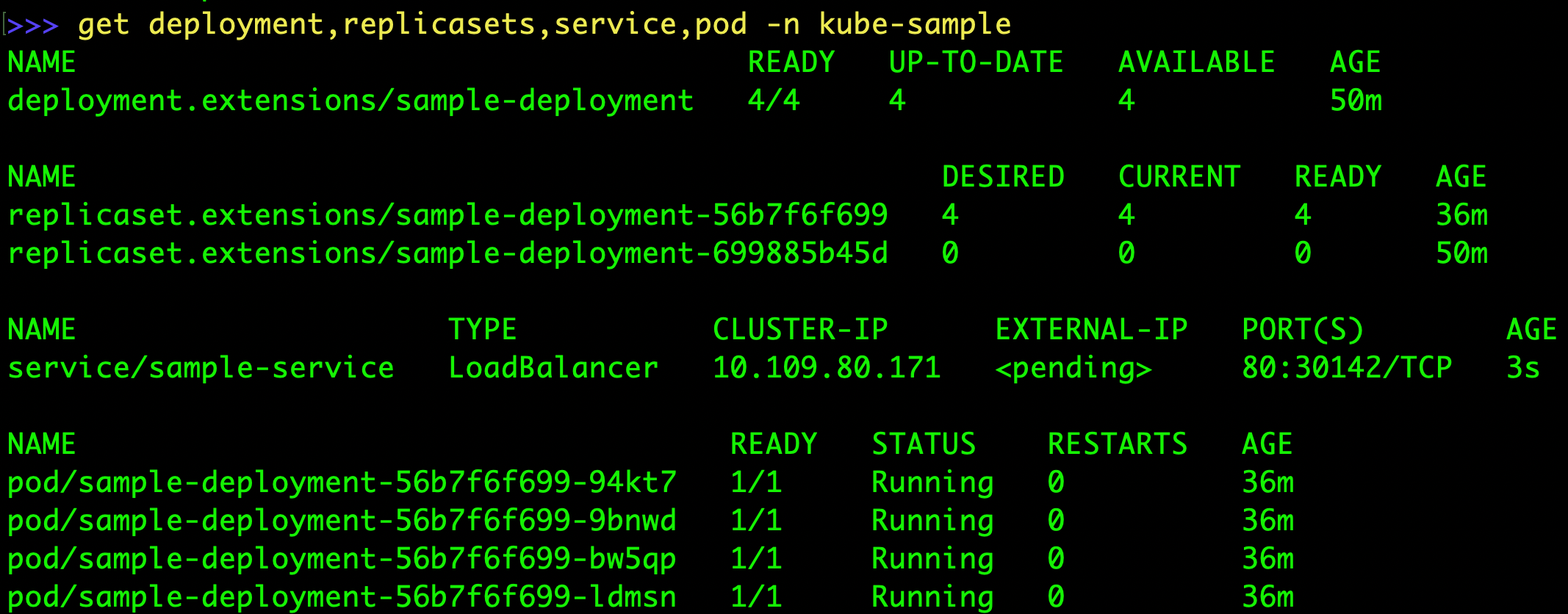
> kubectl get service,deployment --selector release=redmine-sample
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/redmine-sample-mariadb ClusterIP 10.99.90.57 <none> 3306/TCP 3m1s
service/redmine-sample-redmine NodePort 10.96.215.91 <none> 80:30441/TCP 3m1s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.extensions/redmine-sample-redmine 0/1 1 0 3m1s
노출하려는 서비스 redmine-sample-redmine이 차트의 기본값 value 파일의 내용대로 LoadBalancer가 아닌 NodePort로 생성되었다. NodePortsms 30441 포트를 개방하고 있으므로 웹브라우저에서 바로 접근가능하다. 그리고 우리가 파일에 작성한 로그인정보로 로그인이 가능하다.
헬름으로 설치된 릴리스를 업데이트하려면 다음과 같이 helm upgrade 명령을 사용한다.
> helm upgrade -f redmine.yaml redmine stable/redmine --version 4.0.0
차트로 설치한 애플리케이션을 제거하고 싶다면 아래 명령을 이용한다,
> helm delete 릴리스_네임
애플리케이션을 제거해도 헬름에는 롤백 기능이 있기 때문에 원하는 리비전으로 돌아갈 수 있다.
> helm ls --all
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
redmine-exam 1 Sun Nov 24 17:54:39 2019 DELETED redmine-13.5.0 4.0.5 default
> helm rollback redmine-exam 1
만약 리비전 기록을 남기지 않고 애플리케이션을 완전히 제거하려면 다음과 같이 한다.
> helm del --purge redmine(릴리즈_네임)
사용자 차트 생성하기
사용자 차트를 만들고 이 차트를 사용해 애플리케이션을 설치해본다. 쿠버네티스에서 동작하는 대부분의 애플리케이션은 서비스나 인그레스, 디플로이먼트 같은 쿠버네티스 리소스로 구성된다. 차트는 이 구성을 추상화하고 패키징해 배포하기 위한 것으로, 매니페스트 파일을 복사해 하나 이상의 환경에 배포하는 방식보다 유지 보수성이 좋다.
로컬 리포지토리 활성화하기
밑의 명령으로 헬름에서 사용할 수 있는 리포지토리를 확인할 수 있다. 기본 원격 리포지토리와 로컬 리포지토리 정보가 출력될 것이며, 로컬 리포지토리는 헬름이 실행되는 호스트 머신에 위치한다.
> helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
local http://127.0.0.1:8879/charts
하지만 이 로컬 리포지토리는 바로 사용할 수 없다. 이 URL에 http 프로토콜로 접근할 수 있어야 우리가 만든 차트를 사용할 수 있으므로 이 웹서버를 실행한다. 로컬 리포지토리에 항상 접근할 수 있도록 서버를 백그라운드로 실행한다.
> helm serve &
해당 URL을 접근해보면 "Helm Chart Repository"라는 문구가 보일 것이다.
차트 템플릿 작성하기
차트를 생성하려면 먼저 차트의 디렉터리 구조를 만들어야 한다. 헬름에 이 템플릿을 만들어주는 기능이 있다.
> helm create springboot-web
Creating springboot-web
명령 수행후에 명령을 수행한 디렉토리에 밑의 디렉토리 및 파일들이 생성된다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - Kubernetes 아키텍쳐 (0) | 2019.11.26 |
|---|---|
| Kubernetes - Kubernetes 용어설명 (0) | 2019.11.26 |
| Kubernetes - 쿠버네티스 서비스,인그레스(Service,Ingress) (1) | 2019.11.20 |
| Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트) (0) | 2019.11.19 |
| Docker - Docker로 MongoDB 설치하기. (0) | 2019.09.13 |

이전 포스팅에서 쿠버네티스란 무엇이고, 간단하게 팟,레플리카셋,디플로이먼트를 다루어보았다. 이번 시간은 이렇게 띄운 팟을 외부로 서비스할 수 있게 해주는 서비스,인그레스에 대해 다룰 것이다.
2019/11/19 - [인프라/Docker for mac] - Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트)
Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트)
이번 포스팅은 kubernetes에 대해 다루어본다. 사실 쿠버네티스를 다루기 위해서는 docker(도커)에 대한 지식이 필요하지만 여기에서는 다루지 않는다. 그렇다면 쿠버네티스란 무엇인가? 쿠버네티스란? 쿠버네티..
coding-start.tistory.com
서비스(Service)
서비스는 쿠버네티스 클러스터 안에서 파드의 집합에 대한 경로나 서비스 디스커버리를 제공하는 리소스다. 서비스의 대상이 되는 파드는 서비스에서 정의하는 레이플 셀렉터로 정해진다.
apiVersion: v1
kind: Service
metadata:
name: sample-service
spec:
selector:
app: springboot-web
ports:
- port: 80
protocol: TCP
targetPort: 8080
위는 Service 매니페스트 파일이다. 셀렉터로 우리가 띄운 팟을 참조하고 있다. 그리고 해당 서비스는 80포트로 노출시키고 프로토콜은 TCP이며, 해당 서비스로 들어온 요청을 8080 포트로 포워딩하고 있다.
하지만 이 서비스는 아직 외부 서비스에 노출되고 있지 않다. External-ip를 보면 아직 할당되지 않았다. 이 말은 클러스터 내부에서만 이 서비스에 접근 가능하다는 것이다. 그렇다면 이 서비스를 어떻게 노출시킬까? 방법은 2가지가 있다. 바로 다음에 다루어보도록 한다.
<서비스의 네임 레졸루션>
쿠버네티스 클러스터의 DNS는 서비스를 서비스명.네임스페이스명.svc.local로 연결해준다.
예를 들어 위 서비스는
http://sample-service.kube-sample.svc.local로 접근가능하며, svc.local이 생략가능하기에
http://sample-service.kube-sample로 접근이 가능하다.
또한 같은 네임스페이스끼리의 접근이라면 네임스페이스 또한 생략가능하다.
http://sample-service
ClusterIP 서비스
서비스에도 여러 가지 종류가 있어서 그 종류를 yaml 파일에서 지정할 수 있다. 종류의 기본값은 ClusterIP 서비스다.
ClusterIP를 사용하면 쿠버네티스 클러스터의 내부 IP 주소에 서비스를 공개할 수 있다. 이를 이용해 어떤 파드에서 다른 파드 그룹으로 접근할 때 서비스를 거쳐 가도록 할 수 있으며, 서비스명으로 네임 레졸루션이 가능해진다. 다만, 외부로부터는 접근할 수 없다.
NodePort 서비스
NodePort 서비스는 클러스터 외부에서 접근할 수 있는 서비스다. NodePort 서비스는 ClusterIP를 만든다는 점은 ClusterIP 서비스와 같다. 각 노드에서 서비스 포트로 접속하기 위한 글로벌 포트를 개방한다는 점이 차이점이다.
apiVersion: v1
kind: Service
metadata:
name: sample-service
spec:
type: NodePort
selector:
app: springboot-web
ports:
- port: 80
protocol: TCP
targetPort: 8080
외부에서 접근해보자. 접근하기전에 해당 서비스와 연결된 외부에서 접근할 포트를 확인하기 위해 아래 명령을 쳐보자.

외부에서 localhost:30142로 접근해보면, 아래와 같은 결과값이 반환된다. 여기서 중요한 것은 ClusterIP는 외부에서 접근하는 IP가 아니라는 점이다. 클러스터 내부에서 사용되는 IP이기에 외부에서는 접근되지 않는다.
인그레스(Ingress)
쿠버네티스 클러스터 외부로 서비스를 공개하려면 서비스를 NodePort로 노출시킨다. 그러나 이 방법은 L4 레벨까지만 다룰 수 있기 때문에 HTTP/HTTPS처럼 경로를 기반으로 서비스를 전환하는 L7 레벨의 제어는 불가능하다.
이를 해결하기 위한 리소스가 인그레스다. 서비스를 이용한 쿠버네티스 클러스터 외부에 대한 노출과 가상 호스트 및 경로 기반의 정교한 HTTP 라우팅을 할 수 있다.
로컬 쿠버네티스 환경에서는 인그레스를 사용해 서비스를 노출하기 위해서는 몇 가지 설정이 더 필요하다. 클러스터 외부에서 온 HTTP 요청을 서비스로 라우팅하기 위한 nginx_ingress_controller를 다음과 같이 배포한다.
> kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.16.2/deploy/mandatory.yaml
> kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.16.2/deploy/provider/cloud-generic.yaml
이제는 필요한 Ingress Resource를 작성하면 된다. 여기서 작성되는 Ingress는 어떠한 워커에 팟을 띄우는 행위가 아니다. 지금 작성하는 것은 Nginx-ingress에 Rule을 추가하는 행위인 것이다.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-ingress-sample
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: levi.local.com
http:
paths:
- path: /app
backend:
serviceName: sample-service
servicePort: 80

> curl http://localhost/app/api -H "Host:levi.local.com"
위의 설정으로 nginx에 룰을 추가하고, 해당 룰로 들어온 요청은 sample-service라는 라우팅 룰을 가지는 팟으로 요청이 전달되는 것이다. 그리고 팟이 여러개라면 로드밸런싱을 nginx가 해준다. 여기까지 간단하게 서비스와 인그레스에 대해 다루어보았다. 사실 간단하게 테스트로 띄우는 정도의 예제였지만 추후에 좀더 실무에 가까운 예제를 다루어볼 것이다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - Kubernetes 용어설명 (0) | 2019.11.26 |
|---|---|
| Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법 (0) | 2019.11.22 |
| Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트) (0) | 2019.11.19 |
| Docker - Docker로 MongoDB 설치하기. (0) | 2019.09.13 |
| Mac OS - 터미널에서 디렉토리 Tree 구조로 보기 (0) | 2019.02.12 |

이번 포스팅은 kubernetes에 대해 다루어본다. 사실 쿠버네티스를 다루기 위해서는 docker(도커)에 대한 지식이 필요하지만 여기에서는 다루지 않는다. 그렇다면 쿠버네티스란 무엇인가?
쿠버네티스란?
쿠버네티스는 컨테이너 운영을 자동화하기 위한 컨테이너 오케스트레이션 도구이다. 많은 수의 컨테이너를 협조적으로 연동시키기 위한 통합 시스템이며 이 컨테이너를 다루기 위한 API 및 명령행 도구등이 함께 제공된다.
컨테이너를 이용한 애플리케이션 배포 외에도 다양한 운영 관리 업무를 자동화할 수 있다. 도커 호스트 관리, 서버 리소스의 여유를 고려한 컨테이너 배치, 스케일링, 여러 개의 컨테이너 그룹에 대한 로드 밸런싱, 헬스 체크 등의 기능을 갖추고 있다.
쿠버네티스 이외에도 도커 컴포즈, 스웜, 스택등을 이용하여 컨테이너 오케스트레이션을 다룰 수 있지만, 쿠버네티스는 더 충실한 기능을 갖춘 컨테이너 오케스트레이션 시스템이자 사실상 가장 표준으로 자리잡은 도구라고 볼 수 있다. 이번 포스팅에서는 완벽한 클러스터 구성을 다루어보지는 못하지만 간단히 로컬에서 예제를 다루어보고 이후에 진짜 여러 머신에서 클러스터 구성하는 방법을 다루어볼 것이다.
로컬 PC에서 쿠버네티스 실행
사실 실제 프러덕 환경에서는 사용하기 힘든 방법이지만, 간단히 쿠버네티스가 무엇인지 맛보기 위해 로컬 환경에서 쿠버네티스를 사용해본다.

모든 환경은 Mac OS 환경에서 진행한다. 우선 각 PC에 설치된 도커 Preference에 들어가 위와 같이 Enable Kubernetes를 체크해준후 필요한 패키지들을 Install 한다.
kubectl 설치
kubectl은 쿠버네티스를 다루기 위한 명령행 도구이다. 로컬 환경이나 매니지드 환경(GKE등) 모두에서 사용할 수 있다.
brew install kubernetes-cli
kubectl이 잘 설치되었는지 확인해보자.
> kubectl version
Client Version: version.Info{Major:"1", Minor:"16", GitVersion:"v1.16.2", GitCommit:"c97fe5036ef3df2967d086711e6c0c405941e14b", GitTreeState:"clean", BuildDate:"2019-10-15T19:18:23Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.8", GitCommit:"211047e9a1922595eaa3a1127ed365e9299a6c23", GitTreeState:"clean", BuildDate:"2019-10-15T12:02:12Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"linux/amd64"}
kubernetes dashboard 설치
대시보드는 쿠버네티스에 배포된 컨테이너 등에 대한 정보를 한눈에 보여주는 관리도구이다.

> kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta4/aio/deploy/recommended.yaml
> kubectl proxy
여기까지 모두 따라왔다면 아래 url로 접속가능하다.
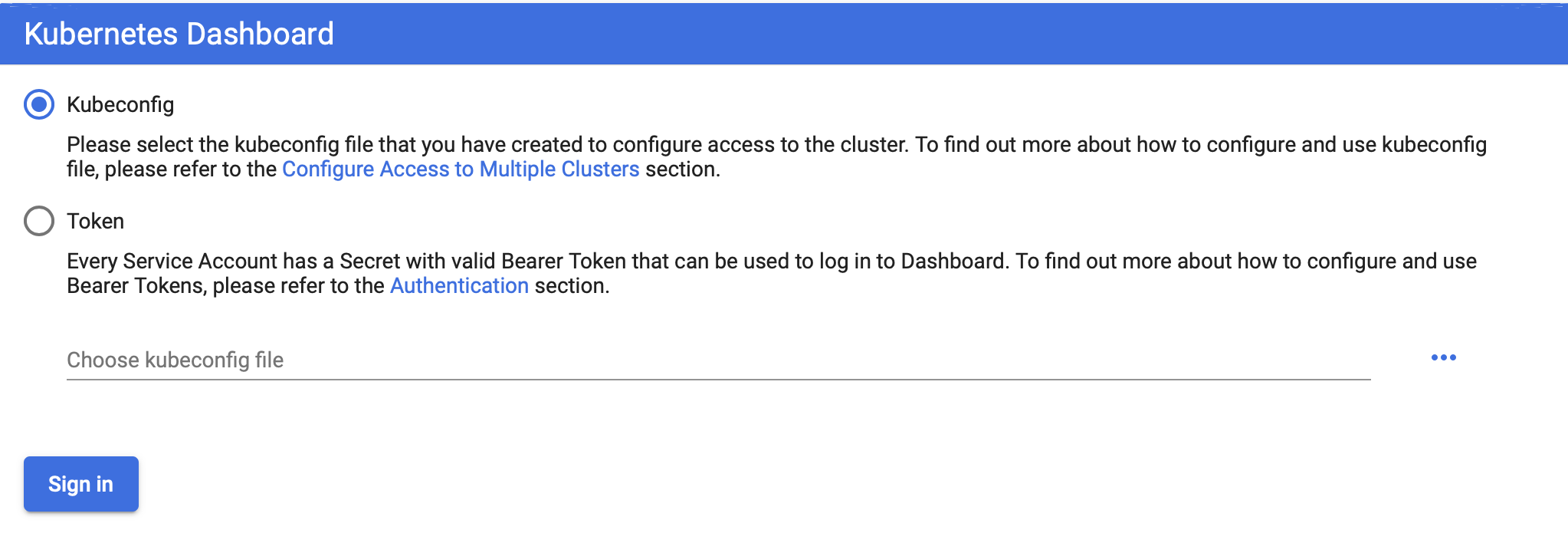
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/#/login
접속 후에는 아마 아래와 같은 팝업이 보일 것이다. 2가지 방법의 접속이 있지만 우리는 토큰을 이용한 방법에 대해 다룬다.
> kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
...
Data
====
ca.crt: 1025 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC10b2tlbi00aDU0eiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjczYWNkOGEzLTBhYjctMTFlYS1hMjRkLTAyNTAwMDAwMDAwMSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDprdWJlcm5ldGVzLWRhc2hib2FyZCJ9.JtykwdSsrqSPb45KieBxoLTgZ-EK2PPTsdsDHr-xJFmFqbMwduui9uQIJH0gFW53iLw_ySb6FpSKRoDNuKbNO-gs89DnGStfogu1ldOS4X4xxZAPIq3za-83OpBRNLGqG8nvPsHSYHPWhJ-vIHxImchlFv0xZDAQJklpIMWX2oQJMsBOkp688RnZ5xCm16YgqIFPCd712hfMufmHFzcdtd7U-Ma3fK6Jkl_FG7E_ee3o3E8kp3_HPdCcQkfMQwPtnvIGf21gmXLisGUsI12J-xdYt8ElmlU7wav0BjB7T-PK4LMUP_KmYytWTnpJL-okrU83wbOoblOyZitpNNHijQ
위와 같은 명령을 통해 쿠버네티스 대시보드 접속을 위한 토큰 값을 얻을 수 있다. 토큰 값을 복사해 접속해보자 .
쿠버네티스의 주요 개념
쿠버네티스로 실행하는 애플리케이션은 애플리케이션을 구성하는 다양한 리소스가 함께 연동해 동작한다. 여기서 말하는 쿠버네티스의 리소스란 애플리케이션을 구성하는 부품과 같은 것으로 앞으로 설명할 노드, 네임스페이스, 파드 등을 가리킨다.
쿠버네티스 클러스터와 노드
쿠버네티스 클러스터는 쿠버네티스의 여러 리소스를 관리하기 위한 집합체를 말한다. 여타 엘라스틱서치, 레디스 등 많은 미들웨어에서 사용하는 클러스터라는 용어와 크게 다르지 않다.
쿠버네티스 리소스 중에서 가장 큰 개념은 노드(node)이다. 노드는 클러스터의 관리 대상으로 등록된 도커 호스트로, 도커 컨테이너가 배치되는 대상이다. 그리고 쿠버네티스 클러스터 전체를 관리하는 서버인 마스터가 적어도 하나 이상 있어야한다. 여기서 하나 이상이라는 말은 클러스터가 작동하기 위한 최소 조건이지만 실제 프러덕 환경에서는 절대 하나로 클러스터를 구성하지 않는다. 최소 3개 이상의 마스터 노드를 갖는 것이 좋다.
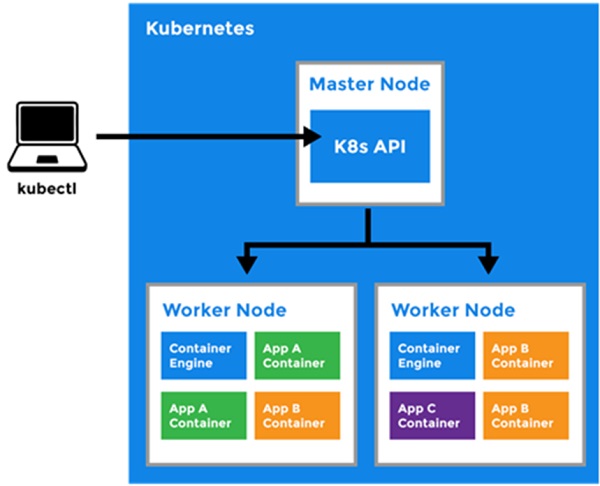
쿠버네티스는 노드의 리소스 사용 현황 및 배치 전략을 근거로 컨테이너를 적절히 배치한다. 다시 말해 클러스터에 배치된 노드의 수, 노드의 사양 등에 따라 배치할 수 있는 컨테이너 수가 결정된다는 뜻이다.
마스터를 구성하는 관리 컴포넌트
쿠버네티스의 마스터 노드에 배포되는 관리 컴포넌트에는 다음과 같은 것이 있다.
| 컴포넌트 | 역할 |
| kube-apiserver | 쿠버네티스 API를 노출하는 컴포넌트이다. kubectl로부터 리소스를 조작하라는 지시를 받는다. |
| etcd | 고가용성을 갖춘 분산 키-값 스토어이다. 쿠버네티스 클러스터의 백킹 스토어로 사용된다. |
| kube-scheduler | 노드를 모니터링하고 컨테이너를 배치할 적절한 노드를 선택한다. |
| kube-controller-manager | 리소스를 제어하는 컨트롤러를 실행한다. |
네임스페이스
쿠버네티스는 클러스터 안에 가상 클러스터를 또 다시 만들 수 있다. 이 클러스터 안의 가상 클러스터를 네임스페이스라고 한다. 클러스터를 처음 구축하면 default, docker, kube-public, kube-system의 네임스페이스 4개가 이미 만들어져 있다. kubectl get namespace 명령으로 현재 클러스터 안에 존재하는 네임스페이스의 목록을 확인할 수 있다.
> kubectl get namespace
NAME STATUS AGE
default Active 42m
docker Active 41m
kube-node-lease Active 42m
kube-public Active 42m
kube-system Active 42m
kubernetes-dashboard Active 25m
네임스페이스가 위에 설명에서는 클러스터 안의 가상 클러스터라고 설명했다. 사실 이해가 힘들수 있다. 쉽게 전체 클러스터에서 리소스의 구분 용도라고 생각해도 좋을 듯하다. 즉, 전체 클러스터에서 특정 이름으로 클러스터의 영역을 구분하는 것이다.
파드(pod)
파드는 컨테이너가 모인 집합체의 단위로, 적어도 하나 이상의 컨테이너로 이루어진다. 여기서 말하는 컨테이너는 도커 컨테이너를 이야기한다. 쿠버네티스를 도커와 함께 사용한다면 파드는 컨테이너 하나 혹은 컨테이너의 집합체가 된다.
쿠버네티스에서는 결합이 강한 컨테이너를 파드로 묶어 일괄 배포한다.(ex spring web app + nginx)
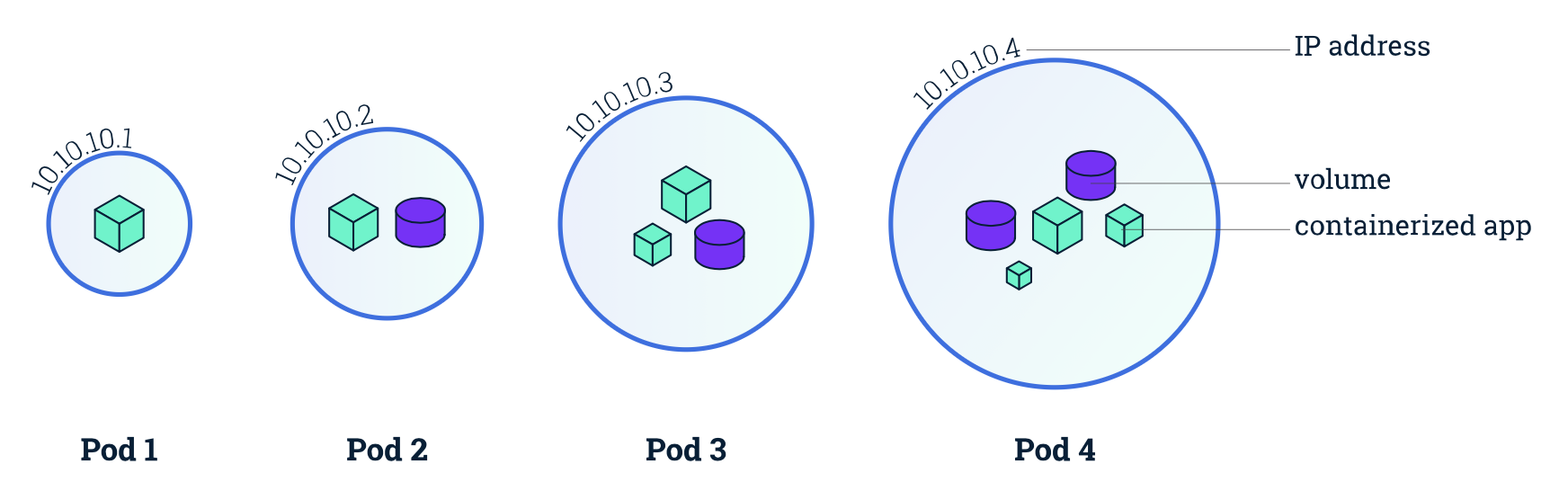
또한 이러한 팟은 노드에 배치된다.
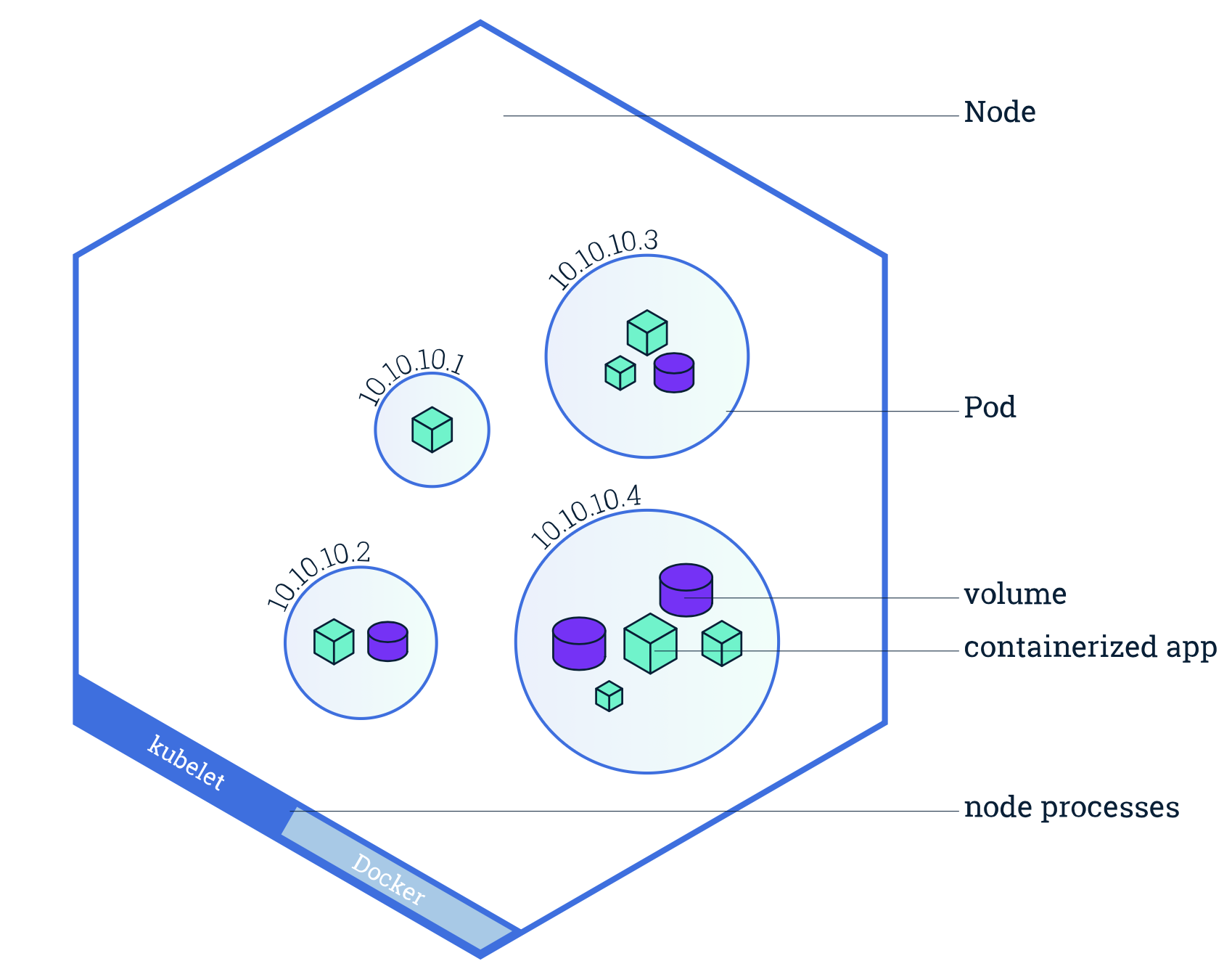
한 팟 안의 컨테이너는 모두 같은 노드에 배치된다. 다시 말해, 팟 하나가 여러 노드에 걸쳐 배치될 수는 없다.
그렇다면 가장 먼저 고민되는 부분은 '팟의 적절한 크기는 어느 정도인가'가 될 것이다. 보통 리버스 프록시 역할을 할 Nginx와 그 뒤에 위치할 애플리케이션 컨테이너를 함께 팟으로 묶는 구성이 일반적이다. 또한 예거와 같은 로그와 관련된 서버는 애플리케이션 컨테이너의 사이드카로 많이 팟을 구성한다.
또 함께 배포해야 정합성을 유지할 수 있는 컨테이너 등에도 해당 컨테이너를 같은 팟으로 묶어두는 전략이 유용하다.
파드(pod) 생성 및 배포하기
파드 생성은 kubectl만 사용해도 가능하지만, 버전 관리 관점에서도 yaml 파일로 정의하는 것이 좋다. 쿠버네티스의 여러 가지 리소스를 정의하는 파일을 매니페스트 파일이라고 한다.
우선 매니페스트 파일을 이용하여 컨테이너 설정을 하기 이전에 간단히 도커 이미지와 컨테이너에 대해 다루어보자.
| 개념 | 역할 |
| 도커 이미지 | 도커 컨테이너를 구성하는 파일 시스템과 실행할 애플리케이션 설정을 하나로 합친 것으로 컨테이너를 생성하는 템플릿 역할을 한다. |
| 도커 컨테이너 | 도커 이미지를 기반으로 생성되며, 파일 시스템과 애플리케이션이 구체화돼 실행되는 상태. |
모든 소스 및 Dockerfile은 깃헙에 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@RestController
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@RequestMapping("/")
public String index(){
return "Hello Kubernetes!";
}
}
|
cs |
간단히 "localhost:8080/"을 호출하였을 때 "Hello Kubernetes!"를 출력하는 예제이다. 해당 애플리케이션을 도커이미지로 만들기 위한 Dockerfile이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
FROM openjdk:8-jdk
# 어떤 이미지로부터 새로운 이미지를 생성할 지 지정. 플랫폼 : 버전 형태로 작성
MAINTAINER levi <1223yys@naver.com>
# Dockerfile을 생성-관리하는 사람
VOLUME /tmp
# 호스트의 directory를 docker 컨테이너에 연결. 즉 소스코드나 외부 설정파일을 커밋하지 않고 docker container에서 사용가능하도록 함
RUN mkdir -p /app/
# 도커 이미지 생성시 실행
ADD ./build/libs/sample-0.0.1-SNAPSHOT.jar /app/app.jar
# 파일이나 디렉토리를 docker image로 복사
EXPOSE 8080
# 외부에 노출할 포트 지정
CMD ["java", "-jar", "/app/app.jar"]
# docker image가 실행될 때 기본으로 실행될 command
|
cs |
해당 파일을 프로젝트 root에 위치시켜준다.(Dockerfile) 이후 해당 도커파일을 기반으로 이미지를 빌드해준다.
> docker build -t 1223yys/springboot-web:0.1.6 . #도커이미지 빌드
> docker image ls #이미지가 잘 생성되었는지 확인
> docker run -d -p 8080:8080 1223yys/springboot-web:0.1.6 #도커 컨테이너 실행
> docker ps #컨테이너가 잘 실행되고 있는지 확인
빌드 완료후 간단히 테스트를 위하여 로컬 도커에서 컨테이너를 실행해보자. 해당 이미지는 Docker Hub에 배포한 상태이다. 추후에 Kubernetes 리소스 파일 작성시 사용하기 위한 배포인 것이다.
> docker push 1223yys/springboot-web:0.1.6
파드(pod) 매니페스트 작성
apiVersion: v1
kind: Pod
metadata:
name: springboot-web
spec:
containers:
- name: springboot-web
image: 1223yys/springboot-web:0.1.6
ports:
- containerPort: 8080
kind는 이 파일에서 정의하는 쿠버네티스 리소스의 유형을 지정하는 속성이다. 이 파일은 파드를 정의하는 파일이므로 속성값이 Pod이다. kind 속성에 따라 spec 아래의 스키마가 변화한다. metadata는 이름 그대로 리소스에 부여되는 메타 데이터이다. spec은 리소스를 정의하기 위한 속성으로, 파드의 경우 파드를 구성하는 컨테이너를 containers 아래에 정의한다.
containers 속성 아래의 값들을 보자. name은 컨테이너 이름, image는 도커 허브에 저장된 이미지 태그값을 지정한다. 포트는 외부에 노출시킬 포트번호이다.
이제 위의 설정을 바탕으로 팟을 띄워보자. 팟을 띄우기 전에 샘플용 네임스페이스 하나를 생성한다. 그리고 팟을 띄워보도록 한다.
> kubectl create namespace kube-sample
> kubectl apply -f pod-sample.yaml -n kube-sample
> kubectl get pod -n kube-sample
아래 이미지와 같이 나왔다면 팟이 정상적으로 뜬 것이다.

팟을 다루는 기타 명령이다.
pod-sample -> yaml 파일명
springboot-web -> pod 이름
kube-sample -> 네임스페이스 이름
> kubectl get pod #떠있는 팟 목록을 가져온다
> kubectl logs -f springboot-web -c springboot-web -n kube-sample #표준 출력 로그를 본다.
> kubectl delete pod springboot-web #pod 삭제
> kubectl delete -f pod-sample.yaml
여기서 파드에 대한 설명을 보충하자면, 파드에는 각각 고유의 가상 IP주소가 할당된다. 파드에 할당된 가상 IP 주소는 해당 파드에 속하는 모든 컨테이너가 공유한다. 즉, 같은 파드 안의 모든 컨테이너의 가상 IP 주소가 같기 때문에 컨테이너간의 localhost 통신이 가능해진다. 하지만 다른 팟 간에는 localhost 통신이 당연히 불가능하다.(할당된 가상 IP 주소가 다르기 때문)
레플리카세트(ReplicaSet)
파드를 정의한 매니페스트 파일로는 파드를 하나밖에 생성할 수 없다. 그러나 어느 정도 규모가 되는 애플리케이션을 구축하려면 같은 파드를 여러 개 실행해 가용성을 확보해야 하는 경우가 생긴다. 이런 경우 사용하는 것이 레플리카세트이다. 레플리카세트는 똑같은 정의를 갖는 파드 여러개를 생성하고 관리하기 위한 리소스이다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: sample-replicaset
labels:
app: springboot-web
spec:
replicas: 3
selector:
matchLabels:
app: springboot-web
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: web-app
image: 1223yys/springboot-web:0.1.6
ports:
- containerPort: 8080
간단하게 매니페스트 파일을 설명하자면, apiVersion은 리소스 유형마다 조금씩 다르다. 왜냐 각 리소스마다 호출하는 api path가 다르기 대문에 잘 확인하자. 그리고 kind는 ReplicaSet이고, metadata에는 이름등을 정의한다. 두번째는 ReplicaSet의 spec 부분이다. 이전 Pod의 매니페스트와는 조금 다르게 replicas와 selector가 생겼다. 우선 replicas는 몇개의 복제본을 만들것인가를 정의하고, selector는 어떠한 Pod을 대상으로 ReplicaSet을 만들것인가를 지정한다. matchLabels의 값으로 template 밑의 라벨 값이 선택되었다. template 밑의 설정들은 Pod의 설정과 동일하다. 이 말은 즉, selector 속성으로 복제할 Pod의 설정을 참조하는 것이다. 이제 정말 레플리카셋이 잘 떴는지 확인하자.
> kubectl describe replicasets -n kube-sample
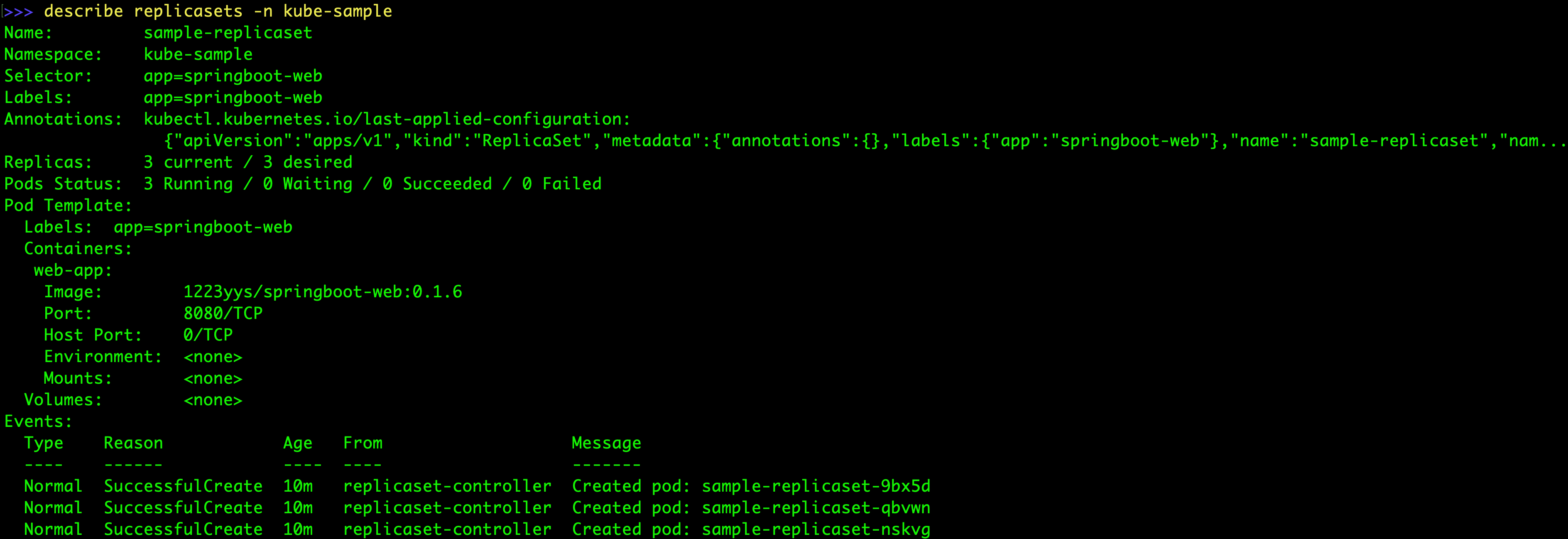
해당 명령은 레플리카셋의 리소스에 대한 자세한 설명이 담겨있다.
> kubectl get replicasets,pod -n kube-sample

해당 명령으로 하나의 레플리카셋이 떠있으며 이 레플리카셋에 설정된 리소스로 Pod이 총 3개 떠있는 것을 확인할 수 있다.
디플로이먼트(deployment)
레플리카셋보다 상위에 해당하는 리소스로 디플로이먼트가 있다. 보통 디플로이먼트가 애플리케이션 배포의 기본 단위가 되는 리소스이다. 레플리카셋은 똑같은 팟의 레플리카를 관리 및 제어하는 리소스인데 반해, 디플로이먼트는 레플리카셋을 관리하고 다루기 위한 리소스이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-deployment
labels:
app: springboot-web
spec:
replicas: 3
selector:
matchLabels:
app: springboot-web
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: web-app
image: 1223yys/springboot-web:0.1.6
ports:
- containerPort: 8080
사실 디플로이먼트의 설정은 레플리카셋과 크게 다르지 않다. 차이가 있다면 디플로이먼트가 레플리카셋의 리비전 관리를 할 수 있다는 정도이다.

총 리소스 타입이 3개가 뜬 것을 볼 수 있다.

디플로이먼트는 위와 같이 리비전이 관리된다. 하지만 change-cause가 보이지 않는다. 이것을 apply할때 옵션을 하나 빠트려서 그런다.

이렇게 디플로이먼트는 리비전관리가 되기 때문에 레플리카셋 대신 배포의 기본단위가 된다.
레플리카세트의 생애주기
쿠버네티스는 디플로이먼트를 단위로 애플리케이션을 배포한다. 실제 운영에서는 레플리카세트를 직접 다루기 보단 디플로이먼트 매니페스트 파일을 통해 다루는 경우가 대부분이다.
디플로이먼트가 관리하는 레플리카세트는 지정된 개수만큼 파드를 화곱하거나 파드를 새로운 버전으로 교체하거나 이전 버전으로 롤백하는 등 중요한 역할을 한다.
애플리케이션 배포를 바르게 운영하려면 이러한 레플리카세트가 어떻게 동작하는지 파악할 수 있어야 한다. 디플로이먼트를 수정하면 레플리카세트가 새로 생성되고 기존 레플리카세트와 교체된다.
파드 개수만 수정하면 레플리카세트가 새로 생성되지 않음
매니페스트 파일에서 replicas 값을 3->4로 수정해 반영하자. 그리고 팟의 정보를 보면(kubectl get pod -n kube-sample) 기존 팟을 그대로 있고, 새로운 컨테이너가 새로 생성되는 것을 알 수 있다.
레플리카세트가 새로 생성됬다면 리비전 번호가 2일 텐데, 그 내용은 출력되지 않는다. replicas 값만 변경해서는 레플리카세트의 교체가 일어나지 않는다.

컨테이너 정의 수정
만약 새로운 API가 추가되어 컨테이너의 수정이 있다고 해보자. 그렇다면 레플리카셋은 어떻게 될까? 새로운 엔드포인트를 추가하여 도커이미지를 새로운 태그로 빌드하고 디플로이먼트의 Pod의 이미지 태그를 변경해보자.

기존 팟들이 내려가고 새로운 팟들이 생성되고 있으며, 새로운 리비전이 하나 생겨났다.
롤백 실행하기
디플로이먼트는 리비전 번호가 기록되므로 특정 리비전의 내용을 확인할 수 있다.
> kubectl rollout history deployment sample-deployment --revision=1

> kubectl rollout undo deployment sample-deployment -n kube-sample
위 undo 명령을 실행하면 바로 이전의 리비전 상태의 디플로이먼트로 되돌아 갈 수 있다. 만약 애플리케이션 배포후 문제가 있다면 바로 롤백할 수 있기때문에 좋은 기능이 될 것이다.
여기까지 쿠버네티스가 무엇인지 Pod,RepliaSets,Deployment에 대해 간단히 다루어보았다. 하지만 여기까지 진행해서는 실제 애플리케이션을 사용해 볼수 없다. 우리가 띄운 Pod을 외부에 노출시키기 위해서는 서비스, 인그레스라는 애들이 필요하다. 서비스 및 인그레스 리소스는 다음 포스팅에서 다루어볼 것이다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법 (0) | 2019.11.22 |
|---|---|
| Kubernetes - 쿠버네티스 서비스,인그레스(Service,Ingress) (1) | 2019.11.20 |
| Docker - Docker로 MongoDB 설치하기. (0) | 2019.09.13 |
| Mac OS - 터미널에서 디렉토리 Tree 구조로 보기 (0) | 2019.02.12 |
| Docker - docker oracle11g 설치 (0) | 2018.08.10 |