
'어텐션'에 해당되는 글 3건
- 2023.08.30 :: Transformer - 어텐션 원리 설명
- 2022.02.17 :: 딥러닝 - BERT(Bidirectional Encoder Representations from Transformers)
- 2022.02.15 :: 딥러닝 - 어텐션 메커니즘(Attention Mechanism)
https://ratsgo.github.io/nlpbook/docs/language_model/tr_self_attention/
Self Attention
pratical tips for Natural Language Processing
ratsgo.github.io
'머신러닝' 카테고리의 다른 글
| 딥러닝 - BERT(Bidirectional Encoder Representations from Transformers) (0) | 2022.02.17 |
|---|---|
| 딥러닝 - 트랜스포머(Transformer) (0) | 2022.02.15 |
| 딥러닝 - 어텐션 메커니즘(Attention Mechanism) (0) | 2022.02.15 |
| 자연어 처리 개요 (0) | 2022.01.20 |

BERT는 트랜스포머를 이용하여 구현되었으며, 위키피디아와 BooksCorpus와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델이다. BERT는 이미 기 학습된 사전 훈련 모델에 레이블이 있는 레이어 층을 하나 쌓아서 훈련해 파이미터를 재조정하여 다른 작업(task)에서도 좋은 성능을 낼 수 있다. 이러한 다른 작업을 위해 레이어를 쌓은 후 훈련하여 파라미터를 재 조정하는 과정을 파인튜닝(fine-tuning)이라고한다.
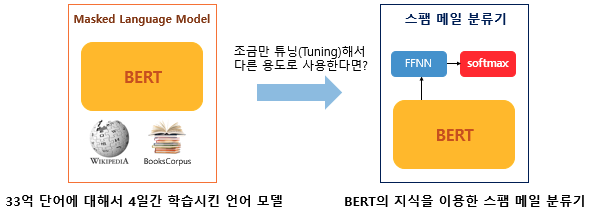
언어 모델(Language Model, LM)
언어 모델이란 단어들의 시퀀스에 대한 확률 분포다. 간단히 말하면 단어들의 모음이 있을 때 해당 단어의 모임이
어떤 확률로 등장할지를 나태나는 값이라 생각하면 된다. 예를 들면, Word2vec 모델 중 CBOW 모델은 주변
단어들을 통한 중앙 단어 예측이 학습의 목적이다. 즉, 문장 시퀀스 중 t번째 단어를 예측하기 위해 해당 단어의
앞,뒤 c개의 단어를 사용하는데, 앞뒤로 총 2c개의 단어 모음이 있을 때 t번째 위치에 올 단어에 대한 확률 분포를
찾는 언어 모델이고, 언어 모델의 성능은 이 확률을 최대화 하는 것이다.
BERT의 크기
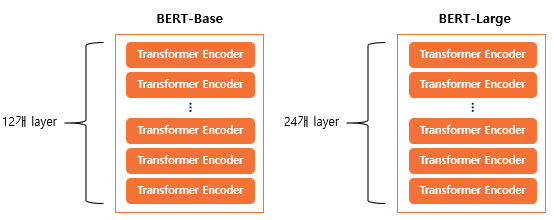
버트는 트랜스포머의 인코더-디코더의 구조를 따라가는 것은 아니고, 인코더만 여러 레이어로 쌓아 올린 구조이다. Base 버전에서는 총 12개, Large 버전에서는 총 24개의 인코더 레이어를 쌓았다. 그리고 각 버전은 모델의 차원수도 차이가 있고, 셀프어텐션 헤드수도 다르기때문에 아래와 같은 파라미터 개수를 갖는다.
BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
BERT의 문맥을 반영한 임베딩(Contextual Embedding)

BERT의 입력은 임베딩 층(Embedding Layer)를 지난 임베딩 벡터들이다. BERT base 기준 d_model을 768로 정의하였기 때문에 문장의 시퀀스들의 각각의 입력 차원은 768차원이다. 각 입력들은 총 12개의 레이어를 지나면서 연산된 후, 동일하게 각 단어에 대해서 768차원의 벡터를 출력하는데, 각 출력들은 모두 문맥을 고려한 벡터가 된다.
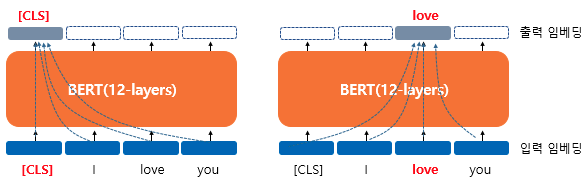
위 그림에서 [CLS] 토큰의 경우 초기 입력은 단순 임베딩 층을 지난 벡터에 지나지 않지만, 총 12개의 레이어를 지난 후 출력으로 나온 CLS의 벡터는 입력으로 들어간 모든 토큰을 참고한 문맥 정보를 가진 벡터가 된다. 이러한 연산은 CLS 토큰 이외의 모든 토큰도 마찬가지가 된다.

위 그림을 봤을 때 모든 토큰은 모든 토큰들을 참고하고 있다.
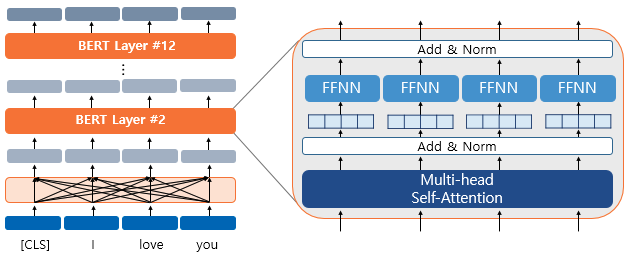
위 그림은 각 입력이 총 12개의 레이어를 지나는 모습과, 각 레이어의 세부 구성을 보여준다. 결론적으로는 각 토큰들은 12레이어를 지나면서 셀프 어텐션을 통해 문맥 정보를 담게 된다.
BERT의 서브워드 토크나이저(WordPiece)
BERT는 단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저를 사용한다. 서브워드 토크나이저는 기본적으로 자주 등장하는 단어는 그대로 단어 집합에 추가하지만, 자주 등장하지 않는 단어의 경우에는 더 작은 단위인 서브워드로 분리되어 서브워드들이 단어 집합에 추가된다는 아이디어를 갖는다. 만약 일반적인 토크나이저라면 존재하지 않는 단어일 경우 OOV 문제가 발생하지만, 서브워드 토크나이저의 경우 해당 단어가 단어집합에 존재하지 않는다고 해서, 서브워드 또한 존재하지 않는다는 의미가 아니므로 해당 단어를 더 쪼개려고 시도한다.
print(tokenizer.vocab['embeddings'])
-> em, ##bed, ##ding, ##s
이렇게 서브워드 토크나이저를 이용하여 문장 시퀀스들에 대해 WordPiece Embedding(정수 인코딩)을 진행한다.
포지션 임베딩(Position Embedding)
트랜스포머 모델에서는 포지셔널 인코딩이라는 방법으로 단어의 위치를 표현했는데, 사인함수와 코사인 함수를 이용해 각 토큰 행렬에 위치정보를 더했다. BERT는 유사하지만 사인,코사인 함수를 이용하지는 않고, 학습을 통해 얻는 포지션 임베딩을 사용한다.

위 그림에서 보이듯 워드피스 임베딩을 통해 나온 벡터에 포지션 임베딩을 더해주는 행위를 하여 임베딩에 위치정보를 반영한다. 여기서 포지션 임베딩은 위치 정보를 위한 임베딩 레이어를 하나 더 사용하고, 만약 문장의 길이가 4라면 4개의 포지션 임베딩 벡터를 학습시킨다.
첫번째 단어의 임베딩 벡터 + 0번 포지션 임베딩 벡터
두번째 단어의 임베딩 벡터 + 1번 포지션 임베딩 벡터
세번째 단어의 임베딩 벡터 + 2번 포지션 임베딩 벡터
네번째 단어의 임베딩 벡터 + 3번 포지션 임베딩 벡터
실제 BERT에서는 문장의 최대 길이를 512로 하고 있으므로 총 512개의 포지션 임베딩 벡터가 학습된다. 지금까지 총 2개의 임베딩 레이어가 나왔는데 버트에서는 추가적으로 세그먼트 임베딩이라는 1개의 임베딩 층을 더 사용한다.
BERT의 pre-trained : 마스크드 언어 모델(Masked Language Model, MLM)
BERT는 사전 훈련을 위해서 입력으로 들어가는 입력 텍스트의 15%의 단어를 랜덤으로 마스킹한다. 그리고 인공 신경망에게 이 가려진 단어들을 예측하도록 한다. 더 정확하게는 15% 단어 전부를 마스킹 하지 않고 아래와 같은 규칙을 따른다.
80%의 단어들은 [MASK]로 변경한다.
Ex) The man went to the store → The man went to the [MASK]
10%의 단어들은 랜덤으로 단어가 변경된다.
Ex) The man went to the store → The man went to the dog
10%의 단어들은 동일하게 둔다.
Ex) The man went to the store → The man went to the store
전체 단어의 85%는 학습에 사용되지 않는다. 마스크드 언어 모델의 학습에 사용되는 단어는 전체 단어의 15%이다. 학습에 사용되는 12%는 마스킹된 후 원래 단어를 예측하는 방식, 1.5%는 랜덤으로 변경된 단어의 원래 단어를 예측하는 방식, 나머지 1.5%는 단어가 변경되지 않았지만 BERT는 이 단어가 원래의 단어인지 변경된 단어인지 모르기에 원래단어가 무엇이었는지 예측해본다.
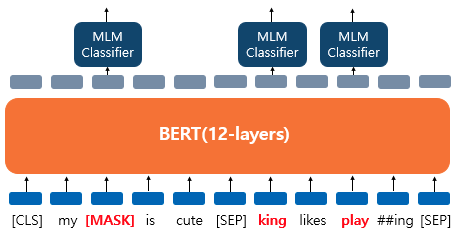
'dog' 토큰은 [MASK]로 변경되었다.
'he'는 랜덤 단어 'king'으로 변경되었다.
'play'는 변경되진 않았지만 예측에 사용된다.BERT의 pre-trained : 다음 문장 예측(Next Sentence Prediction, NSP)
BERT는 두 개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 사전 학습한다.
이어지는 문장의 경우
Sentence A : The man went to the store.
Sentence B : He bought a gallon of milk.
Label = IsNextSentence
이어지는 문장이 아닌 경우 경우
Sentence A : The man went to the store.
Sentence B : dogs are so cute.
Label = NotNextSentence
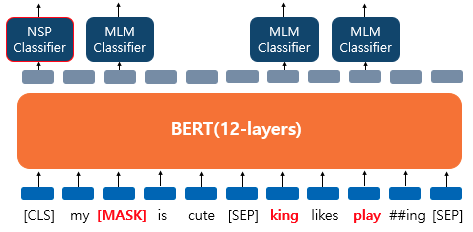
BERT의 입력으로 넣을 때에는 [SEP]라는 특별 토큰을 사용해 두 문장을 구분한다. 그리고 위 그림에서 보듯이 문장이 이어지는지 아닌지 등의 분류 문제에는 CLS 토큰의 출력을 이용한다. 또한 마스크드 언어 모델 학습과 다음 문장 예측은 서로 별도로 학습하는 것이 아니라, 각 문제의 loss를 합하여 학습이 동시에 이루어진다.
세그먼트 임베딩(Segment Embedding)
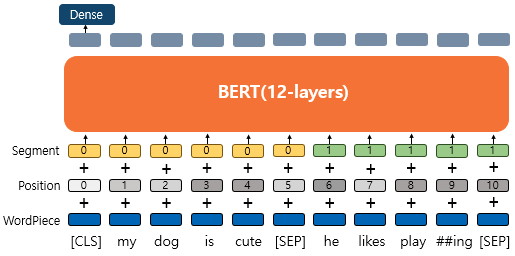
BERT는 QA등과 같은 두 개의 문장 입력이 필요한 태스크를 풀기도 하는데, 문장 구분을 위해서 세그먼트 임베딩이라는 또 다른 임베딩 층을 사용한다. 첫번째 문장에는 Sentence0 임베딩, 두번째 문장에는 Sentence1 임베딩을 더해주는 방식이며 임베딩 벡터는 두개만 사용된다.
결론적으로 BERT는 총 3개의 임베딩 층이 사용된다.
WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
만약 BERT가 두 개의 문장을 입력받을 필요가 없는 태스크인 경우 세그먼트 임베딩을 전체 입력에 대해 Sentence 0 임베딩만 더해준다.
BERT를 파인 튜닝(fine-tunng) 하기
1)하나의 텍스트에 대한 텍스트 분류 유형(Single Text Claasification)
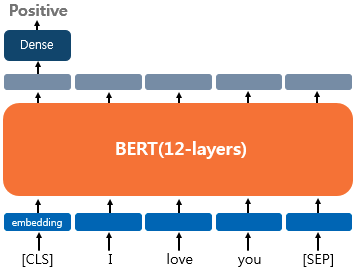
입력이 하나의 문장이고, 해당 텍스트에 대한 분류를 할때는 앞서 설명한 것과 같이 CLS 토큰의 출력을 이용한다. 즉, 파인 튜닝 단계에서 텍스트 분류 문제를 풀기 위해서 CLS 토큰 출력 위치에 Dense Layer(fully-connected layer) 층을 추가하여 분류에 대한 예측을 하게 된다.
2)하나의 텍스트에 대한 태깅 작업(Tagging)
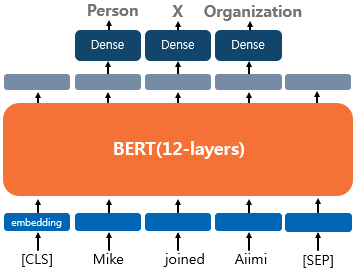
하나의 텍스트에 대해 엔티티 혹은 품사를 태깅하는 작업에 대해 파인 튜닝 할때는 스페셜 토큰을 제외한 실제 입력 토큰의 출력층에 Dense Layer를 사용하여 분류에 대한 예측을 하게 된다.
3)하나의 텍스트에 대한 태깅 작업(Tagging)
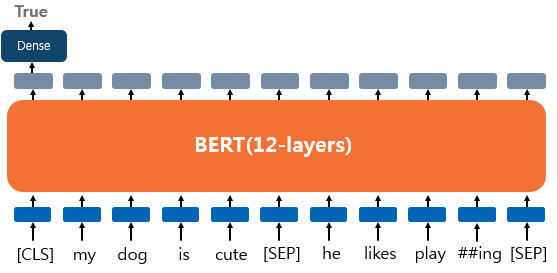
텍스트의 쌍을 입력으로 받는 대표적인 태스크로 자연어 추론(Natural language inference)이 있는데, 두 문장이 입력으로 들어오고 두문장이 논리적으로 어떤 관계에 있는지를 분류하는 것이다. 유형으로는 모순 관계(contradiction), 함의 관계(entailment), 중립 관계(neutral)이 있다. 해당 문제의 입력은 두 개의 문장이므로 SEP라는 스페셜 토큰으로 문장을 구분한다. 그리고 해당 문제는 분류 문제에 속하므로, CLS 토큰의 출력층에 Dense Layer를 쌓아서 분류를 예측한다.
위에서 설명한 문제 이외로도 하나의 문장과 하나의 문단을 넣어서 첫번째 문장(질문)에 해당하는 답을 문단에서 뽑아내는 질의 응답에 대한 문제등도 있다.
어텐션 마스크(Attention Mask)
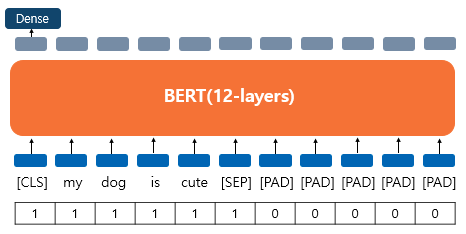
BERT는 입력으로 어텐션 마스크라는 시퀀스 입력이 추가로 필요하다. 쉽게 말해 어텐션 마스크는 연산이 필요없는 패딩 토큰에 대해 어텐션을 하지 않도록 마스킹해주는 역할이다. 이 값은 0과 1값으로 가지는데, 실제로 입력 시퀀스중 [PAD] 토큰의 위치에 해당하는 어텐션 마스크는 0으로, 실제 연산에 필요한 토큰 위치는 1로 채워지게 된다.
'머신러닝' 카테고리의 다른 글
| Transformer - 어텐션 원리 설명 (0) | 2023.08.30 |
|---|---|
| 딥러닝 - 트랜스포머(Transformer) (0) | 2022.02.15 |
| 딥러닝 - 어텐션 메커니즘(Attention Mechanism) (0) | 2022.02.15 |
| 자연어 처리 개요 (0) | 2022.01.20 |
어텐션 메커니즘
시퀀스-투-시퀀스(seq2seq) 모델 같은 경우는 인코더에서 입력 시퀀스를 컨텍스트 벡터(context vector)라는 하나의 고정된 크기의 벡터 표현으로 문장 시퀀스를 압축하고, 디코더는 해당 컨텍스트 벡터를 이용해 출력 시퀀스를 만들어낸다.
하지만, 이러한 RNN에 기반한 seq2seq 모델에는 아래와 같은 문제점이 있다.
- 하나의 고정된 크기의 벡터에 문장 시퀀스 정보 모두를 압축하려 하기에 정보 소실이 발생한다.
- RNN의 고질적인 문제인 기울기 소실(vanishing gradient)문제가 존재한다.
즉, 위와 같은 문제로 기계번역 같은 분야에서 입력된 문장의 길이가 길어지게 되면 번역 성능이 크게 줄어든다. 하지만 어텐션이라는 아이디어로 긴 입력 시퀀스에 대한 품질이 떨어지는 것을 보정 해줄 수 있다.
어텐션의 아이디어
어텐션은 디코더에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 다시 한번 참고하는 것이다. 하지만 여기서 중요한 것은 입력 문장 전체를 동일 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분에 조금 더 집중(attention)해서 보게 된다.
어텐션 함수
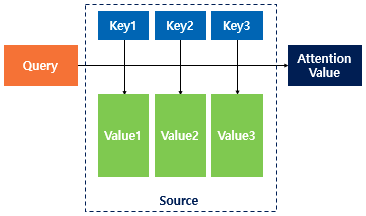
Attention(Q, K, V) = Attention Value
어텐션 함수는 주어진 쿼리(Q)에 대해서 모든 키(K)와의 유사도를 각각 구한 후 각 키와 매핑된 값(V)에 반영해준다. 그리고 유사도가 반영된 값을 모두 더해 리턴하는데, 여기서 리턴된 값을 어텐션 값(Attention Value)라고 한다.
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
닷-프로덕트 어텐션(Dot-Product Attention)
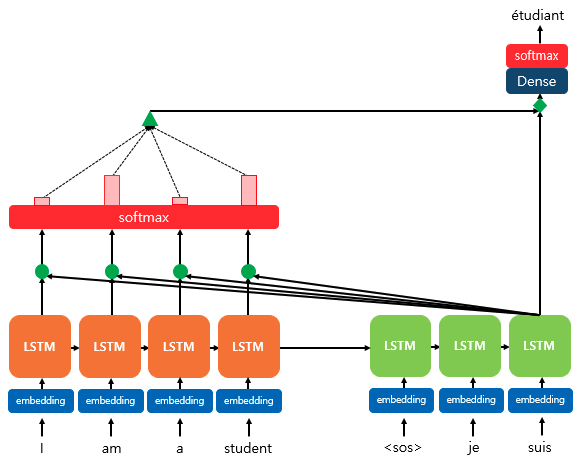
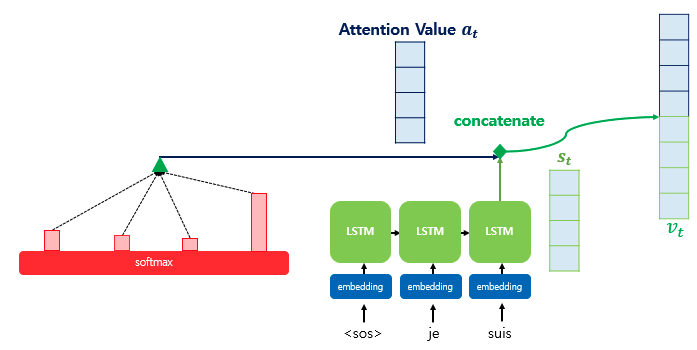
디코더의 세번째 시점의 LSTM 셀에서 출력 단어를 예측하는 예제
디코더의 세번째 LSTM 셀은 출력 단어를 예측하기 위해서 인코더의 모든 입력 단어들의 정보를 다시 한번 참고한다. 인코더 쪽의 소프트맥스 함수를 통해 나온 결과값은 I, am, a, student 단어 각각이 출력 단어(suis가 입력으로 들어간 세번째 시점의 LSTM 출력 )를 예측할 때 얼마나 도움이 되는지의 정도를 수치화한 값이다. 그리고 각 입력 단어가 디코더의 예측에 도움이 되는 정도를 수치화하여 하나의 정보로 담아서 디코더로 전송한다. 결과적으로 해당 어텐션 값을 이용해 디코더는 출력 단어를 더 정확하게 예측할 확률이 높아진다.
어텐션 스코어

인코더의 각 시점의 은닉 상태(hidden state)를 각각 h1,h2,..hn이라고 하고, 디코더의 현재 시점 t에서의 디코더의 은닉 상태를 st라고 한다. 다시 돌아가서, 디코더의 현재 시점 t에서 필요한 입력값은 바로 이전 시점인 t-1의 은닉 상태와 이전 시점 t-1에서 나온 출력단어이다. 그런데 어텐션 메커니즘에서는 출력 단어 예측에 어텐션 값이라는 새로운 값이 필요하다. 여기서 t시점의 출력을 예측하기 위한 어텐션 값을 at라고 하자.
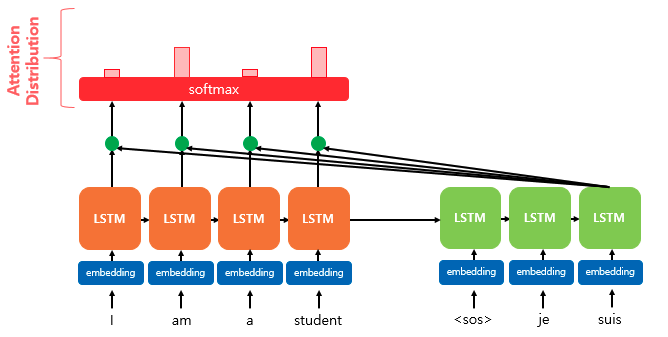
우선 어텐션 스코어(Attention score)를 구해보자. 어텐션 스코어란 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 은닉상태 st와 얼마나 유사한지를 판단하는 스코어값이다.
닷-프로덕트 어텐션에서는 이 스코어 값을 구하기 위해 st를 전치(transpose)하고 각 은닉 상태와 내적(dot product)을 수행한다. 아래 그림은 st과 인코더 i번째의 은닉 상태의 어텐션 스코어의 계산 방법이다. 여기서 어텐션 스코어 값은 모두 스칼라 값을 가진다.


소프트맥스 함수를 통해 어텐션 분포 구하기
위 et에 소프트 맥스 함수를 적용하여, 모든 값을 합하면 1이 되는 확률 분포를 얻어낸다. 이를 어텐션 분포라고 하며, 각각의 값은 어텐션 가충치(Attention Weight)라고 한다. 예를 들어 소프트맥스 함수를 적용하여 얻은 출력값인 I, am, a, student의 어텐션 가중치를 각각 0.1, 0.4, 0.1, 0.4라고 하고, 이들의 합은 1이다.
디코더의 시점 t에서의 어텐션 가중치의 모음값인 어텐션 분포를 αt이라고 할 때, αt을 식으로 정의하면 다음과 같다.
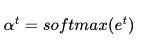
각 인코더의 어텐션 가중치와 은닉 상태를 가중합하여 어텐션 값(Attention Value)을 구한다.
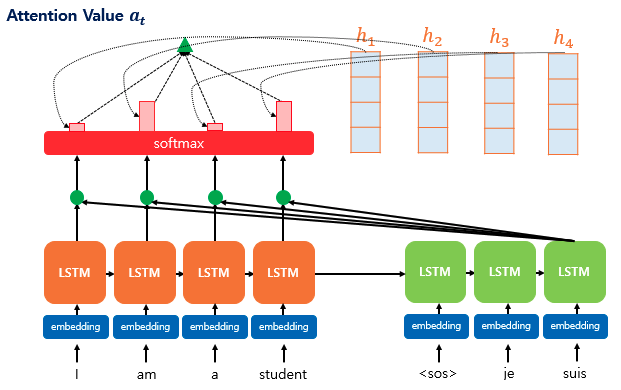
어텐션 값을 얻기 위해 각 인코더의 은닉 상태와 어텐션 가중치 값들을 곱하고, 최종적으로 모두 더한다. 요약하자면 가중합(weighted Sum)을 진행한다. 수식으로 표현하면 아래와 같다.
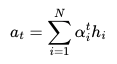
이러한 어텐션 값은 종종 인코더의 문맥을 포함하고 있다고 하여, 컨텍스트 벡터(Context Vector)라고도 불린다.
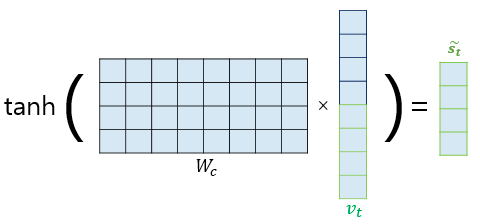
어텐션 값과 디코더의 t 시점의 은닉 상태를 연결한다.(Concatenate)
어텐션 함수의 최종값인 어텐션 값 at을 구했고 그리고 at를 st와 결합(concatenate)하여 하나의 벡터 Vt로 만드는 작업을 수행한다. 그리고 이 Vt를 y^ 예측 연산의 입력으로 사용하므로서 인코더로부터 얻은 정보를 활용하여 y^를 좀 더 잘 예측할 수 있게 된다. 이것이 어텐션 메커니즘의 핵심이다. 하지만 여기서 나온 Vt를 바로 출력의 입력으로는 사용하지 못하고, 아래 그림과 같이 출력층으로 보내기 전에 신경망 연산을 통해 기존 은닉층과 같은 벡터 차원으로 만들어준 후에 나온 St^값을 입력으로 넣는다.
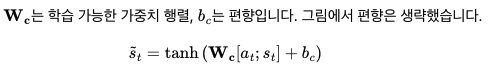
위와 같이 St^를 출력층의 입력으로 사용해 예측 벡터를 얻는다.

위에서 설명한 dot-product 어텐션 말고도 다양한 어텐션 종류가 있다. 하지만 그 차이는 중간에 수식 차이이다.

위에서 St는 Query, Hi는 keys, Wa와 Wb는 학습 가능한 가중치 행렬이다. 즉, 쿼리는 디코더의 현재 시점의 은닉 상태, 키는 모든 인코더의 은닉 상태를 뜻하며 이러한 값들을 이용해 최종적인 어텐션 값을 구하게 된다.
'머신러닝' 카테고리의 다른 글
| Transformer - 어텐션 원리 설명 (0) | 2023.08.30 |
|---|---|
| 딥러닝 - BERT(Bidirectional Encoder Representations from Transformers) (0) | 2022.02.17 |
| 딥러닝 - 트랜스포머(Transformer) (0) | 2022.02.15 |
| 자연어 처리 개요 (0) | 2022.01.20 |