

'운영'에 해당되는 글 2건
- 2020.02.24 :: Kubernetes - Kubernetes 로깅 운영(logging), Fluentd 1
- 2019.12.07 :: IT - DevOps란?

오늘 다루어볼 내용은 쿠버네티스 환경에서의 로깅운영 방법이다. 지금까지는 쿠버네티스에 어떻게 팟을 띄우는지에 대해 집중했다면 오늘 포스팅 내용은 운영단계의 내용이 될 것 같다. 사실 어떻게 보면 가장 중요한 내용중에 하나라고 볼 수 있는 것이 로깅이다. 물리머신에 웹을 띄울 때는 파일로 로그를 날짜별로 남기고, 누적 일수이상된 파일은 제거 혹은 다른 곳으로 파일을 옮기는 등의 작업을 했을 것이다. 하지만 쿠버네티스에서는 파일로 로그를 남기지 않으며 조금 다른 방법으로 로깅운영을 진행한다.
컨테이너 환경에서 로그를 운영하는 구체적인 방법을 설명하기 전에 컨테이너 환경에서 로그가 어떻게 생성되는지 알아본다. 비컨테이너 환경의 애플리케이션에서는 보통 로그를 파일로 많이 남기고 한다. 이에 비해 도커에서는 로그를 파일이 아닌 표준 출력으로 출력하고 이를 다시 Fluentd 같은 로그 컬렉터로 수집하는 경우가 많다. 이런 방법은 애플리케이션 쪽에서 로그 로테이션이 필요없으며 로그 전송을 돕는 로깅 드라이버 기능도 갖추고 있으므로 로그 수집이 편리하다.
간단하게 필자가 만든 이미지로 실습을 진행한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
> docker pull 1223yys/springboot-web:0.2.5
> docker container run -it --rm -p 8080:8080 1223yys/springboot-web:0.2.5
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.2.1.RELEASE)
2020-02-23 11:29:15.368 INFO 1 --- [ main] com.kebe.sample.SampleApplication : Starting SampleApplication on d1e5a6d24e34 with PID 1 (/app/app.jar started by root in /)
2020-02-23 11:29:15.375 INFO 1 --- [ main] com.kebe.sample.SampleApplication : No active profile set, falling back to default profiles: default
2020-02-23 11:29:17.099 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2020-02-23 11:29:17.122 INFO 1 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2020-02-23 11:29:17.124 INFO 1 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.27]
2020-02-23 11:29:17.244 INFO 1 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2020-02-23 11:29:17.245 INFO 1 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1784 ms
2020-02-23 11:29:17.619 INFO 1 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2020-02-23 11:29:17.885 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2020-02-23 11:29:17.890 INFO 1 --- [ main] com.kebe.sample.SampleApplication : Started SampleApplication in 3.221 seconds (JVM running for 3.936)
|
cs |
yoonyeoseong/kubernetes-sample
Contribute to yoonyeoseong/kubernetes-sample development by creating an account on GitHub.
github.com
우선 이미지를 내려받고 애플리케이션을 포어그라운드로 실행시킨다. 그 다음 로그가 호스트에서 어떻게 출력되는지 확인해보자.
그전에 아래의 명령으로 실행 중인 컨테이너들의 로그가 어떻게 찍히는 지 확인할 수 있다.
|
1
|
> docker run -it --rm -v /var/lib/docker/containers:/json-log alpine ash
|
cs |
명령 실행 후에 /json-log 디렉토리에 위에서 실행한 컨테이너의 아이디 디렉토리로 들어가면 현재 우리가 표준출력으로 찍고 있는 로그가 json 타입으로 찍히고 있으며 이 표준출력이 파일로 남고 있는 것을 볼 수 있다.

다시 말해, 애플리케이션에서 로그를 파일로 출력하지 않았더라도 도커에서 컨테이너의 표준 출력을 로그로 출력해주는 것이다. 따라서 로그 출력 자체를 완전히 도커에 맡길 수 있다.
도커 로깅 드라이버
도커 컨테이너의 로그가 JSON 포맷으로 출력되는 이유는 도커에 json-file이라는 기본 로깅 드라이버가 있기 때문이다. 로깅 드라이버는 도커 컨테이너가 출력하는 로그를 어떻게 다룰지를 제어하는 역할을 한다. json-file 외에도 다음과 같은 로깅 드라이버가 존재한다.
| logging driver | description |
| Syslog | syslog로 로그를 관리 |
| Journald | systemd로 로그를 관리 |
| Awslogs | AWS CloudWatch Logs로 로그를 전송 |
| Gcplogs | Google Cloud Logging으로 로그를 전송 |
| Fluentd | fluentd로 로그를 관리 |
도커 로그는 fluentd를 사용해 수집하는 것이 정석이다.
컨테이너 로그의 로테이션
애플리케이션에서 표준 출력으로 출력하기만 해도 로그를 파일에 출력할 수 있지만, 웹 애플리케이션처럼 컨테이너 업타임이 길거나 액세스 수에 비례해 로그 출력량이 늘어나는 경우에는 JSON 로그 파일 크기가 점점 커진다. 컨테이너를 오랜 시간 운영하려면 이 로그를 적절히 로테이션할 필요가 있다.
도커 컨테이너에는 로깅 동작을 제어하는 옵션인 --log-opt가 있어서 이 옵션으로 도커 컨테이너의 로그 로테이션을 설정할 수 있다. max-size는 로테이션이 발생하는 로그 파일 최대 크기이며 l/m/g 단위로 파일 크기 지정이 가능하다. max-file은 최대 파일 개수를 의미하며 파일 개수가 이 값을 초과할 경우 오래된 파일부터 삭제된다.
|
1
|
docker container run -it --rm -p 8080:8080 --log-opt max-size=1m --log-opt max-file=5 1223yys/springboot-web:0.2.5
|
cs |
이 설정을 매번 컨테이너 실행마다 할 필요는 없고, 도커 데몬에서 log-opt를 기본값으로 설정할 수 있다. Preference 화면에서 Deamon > Advanced 항목에서 다음과 같이 JSON 포맷으로 설정할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
|
{
"experimental" : false,
"debug" : true,
"log-driver": "json-file",
"log-opts": {
"max-size": "1m",
"max-file": "5"
}
}
|
cs |
쿠버네티스에서 로그 관리하기
다른 예제는 뛰어넘고, 바로 쿠버네티스 환경에서 로그관리하는 방법을 알아본다. 우선 가장 대중적인 쿠버네티스 로그 운영은 아래와 같은 플로우로 많이 진행하는 것 같다.
app ---> fluentd ---> elasticsearch ---> kibana
app에서는 표준 출력으로 로그를 출력하고 fluentd는 로그를 긁어서 엘라스틱서치에 색인한다. 그리고 키바나를 통해 색인된 로그들을 모니터링한다. 쿠버네티스의 로그 관리에서도 역시 컨테이너는 표준 출력으로만 로그를 내보내면 되며, 그에 대한 처리는 컨테이너 외부에서 이루어진다.
쿠버네티스는 다수의 도커 호스트를 노드로 운영하는데, 어떤 노드에 어떤 파드가 배치될지는 쿠버네티스 스케줄러가 결정한다. 그러므로 각 컨테이너가 독자적으로 로그를 관리하면 비용이 많이 든다. 먼저 로컬 쿠버네티스 환경에 Elasticsearch와 Kibana를 구축한 다음, 로그를 전송할 fluentd와 DaemonSet을 구축한다.
쿠버네티스에 Elasticsearch와 Kibana 구축하기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: elasticsearch-pvc
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2G
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: kube-system
spec:
selector:
app: elasticsearch
ports:
- protocol: TCP
port: 9200
targetPort: http
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
namespace: kube-system
labels:
app: elasticsearch
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:5.6-alpine
ports:
- containerPort: 9200
name: http
volumeMounts:
- mountPath: /data
name: elasticsearch-pvc
- mountPath: /usr/share/elasticsearch/config
name: elasticsearch-config
volumes:
- name: elasticsearch-pvc
persistentVolumeClaim:
claimName: elasticsearch-pvc
- name: elasticsearch-config
configMap:
name: elasticsearch-config
---
kind: ConfigMap
apiVersion: v1
metadata:
name: elasticsearch-config
namespace: kube-system
data:
elasticsearch.yml: |-
http.host: 0.0.0.0
path.scripts: /tmp/scripts
log4j2.properties: |-
status = error
appender.console.type = Console
appender.console.name = console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] %marker%m%n
rootLogger.level = info
rootLogger.appenderRef.console.ref = console
jvm.options: |-
-Xms128m
-Xmx256m
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+AlwaysPreTouch
-server
-Xss1m
-Djava.awt.headless=true
-Dfile.encoding=UTF-8
-Djna.nosys=true
-Djdk.io.permissionsUseCanonicalPath=true
-Dio.netty.noUnsafe=true
-Dio.netty.noKeySetOptimization=true
-Dio.netty.recycler.maxCapacityPerThread=0
-Dlog4j.shutdownHookEnabled=false
-Dlog4j2.disable.jmx=true
-Dlog4j.skipJansi=true
-XX:+HeapDumpOnOutOfMemoryError
|
cs |
엘라스틱서치 manifast 파일이다. 볼륨마운트, 컨피그 맵 등의 설정이 추가적으로 들어갔다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-system
spec:
selector:
app: kibana
ports:
- protocol: TCP
port: 5601
targetPort: http
nodePort: 30050
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-system
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: kibana:5.6
ports:
- containerPort: 5601
name: http
env:
- name: ELASTICSEARCH_URL
value: "http://elasticsearch:9200"
|
cs |
키바나 manifast 파일이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-system
labels:
app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
app: fluentd-logging
template:
metadata:
labels:
app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:elasticsearch
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_UID
value: "0"
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
|
cs |
마지막으로 fluentd manifast이다. DaemonSet 으로 구성되며 클러스터 노드마다 할당되는 리소스이다. DaemonSet은 클러스터 전반적인 로깅등의 작업을 수행하는 리소스에 할당하는 타입이다. 어떠한 팟마다 같이 뜨는 리소스가 아니고 클러스터 노드마다 뜨는 리소스라고 보면 된다. 로그 컬렉터같이 호스트마다 특정할 역할을 하는 에이전트를 두고자 할 때 적합하다.
여기까지 간단하게 쿠버네티스 환경에서 로깅 운영하는 방법을 간단하게 다루어봤다. 다음 예제에서는 기본적인 플로우 이외로 output을 kafka로 보내는 등의 다른 플러그인을 사용하여 로그를 수집하는 예제를 살펴볼 것이다.
'인프라 > Docker&Kubernetes' 카테고리의 다른 글
| Docker - Docker 다른 레포지토리에 push하기 (0) | 2020.04.20 |
|---|---|
| Docker - Docker image 빌드시 Dockerfile이 아닌 커스텀한 dockerfile명을 이용할때 (0) | 2020.04.09 |
| Kubernetes - Kubernetes 아키텍쳐 (0) | 2019.11.26 |
| Kubernetes - Kubernetes 용어설명 (0) | 2019.11.26 |
| Kubernetes - Helm(헬름)이란? 주요개념,설치 , 사용법 (0) | 2019.11.22 |

DevOps에 대해 조금더 자세히 알고 싶어 여기저기 서칭하던 중, 조대협님의 좋은 글이 있어 공유하려 한다. 기존에 DevOps가 무엇이냐 물어보면 막상 딱 대답할 수 없는 나였지만 이 글을 통해 DevOps가 뭔지 조금 알아볼 수 있었던 계기가 되었다.
Devops의 정의
이러한 개념들을 적극적으로 적용한 기업들이 Netflix, Flicker와 같은 인터넷 서비스 기업이다. 기존 개발 프로세스에 비해서 훨씬 빠르게 고객의 요구 사항을 반영해 내가고 있다. Flicker의 경우에는 하루에 10번 정도 [1]Deploy를 한다고 한다. 일반적인 인터넷 서비스가 한달에 한번 업데이트 빨라야 일주에 한번인데, 하루에 10번이라면, 경쟁 구조 자체가 틀려진다.
PuppetLab (Configuration management 자동화툴)의 블로그[2]에 따르면 Devops를 적용할 경우,경쟁사에 비해서 30배 정도 더 자주 Deployment를 할 수 있으며, Deployment 실패 비율도 50% 이상이나 줄일 수 있다는 것이다.
그렇다면 이렇게 장점이 많은 Devops는 무엇인가?
일반적인 Devops의 정의는 “개발과 운영이 분리되면서 오는 문제점을 해결하기 위해서, 개발과 운영을 하나의 조직으로 합쳐서 팀을 운영하는 문화이자 방법론이다”앞에서도 설명하였듯이, 개발과 운영을 합치는 것이다. 조금 더 정확하게 이야기 하면, 개발 운영 뿐만 아니라 테스트까지 하나의 팀에 합치는 것이다.

상당 부분의 테스트는 이미 TDD (Test Driven Development), CI (Continuous Integration)를 통해서 개발 과정의 일부로 들어와 있는 경우가 많다.
즉 Devops란, “엔지니어가, 프로그래밍하고, 빌드하고, 직접 시스템에 배포 및 서비스를 RUN한다. 그리고, 사용자와 끊임 없이 Interaction하면서 서비스를 개선해 나가는 일련의 과정이자 문화이다.”
Puppet lab의 Devops Engineer에 대한 정의를 보면 조금 더 이 개념을 확장하고 있는 것을 볼 수 있는데, “사용자와 끊임 없이 Interaction” 하는 부분은 원론적으로 보면 개발자의 역할 보다는 기존에는 마케팅이나 고객 접점에 있는 서비스 기획자의 역할이었다.
“The DevOps engineer encapsulates depth of knowledge and years of hands-on experience,” Kelsey said. “You’re battle tested. This person blends the skills of the business analyst with the technical chops to build the solution - plus they know the business well, and can look at how any issue affects the entire company.” - See more at: http://puppetlabs.com/blog/what-is-a-devops-engineer#sthash.J5yNwCpX.dpuf “
큰 의미에서 보면 단순히 개발,운영이라는 기술적인 접근 뿐만 아니라 사용자와의 의사 소통을 통한 서비스의 개선이라는 “비즈니스”적인 역할까지 확장한 개념이 된다.
기본적인 개념은 이해 했으리라 본다. 그렇다면 Devops의 실체는 무엇일까? Scrum이나 XP와 같은 방법론? 아니면 조직 체계? Devops는 팀운용 방법론이기도 하지만 정확하게 이야기 하면 “문화”이다. 개발 문화.
하나의 엔지니어가 멀티롤을 하면서 권한이 많아지게 되고, 예전 전통적인 소프트웨어 개발처럼 요구사항을 받아서, 개발하고 운영에 넘기는 개발 라인에 서 있는 하나의 리소스보다는 같이 생각하고 같이 서비스를 개발해야 하는 “협업” 중심의 문화 체계로 바뀌게 되는 것이다. Devops는 하나의 방향을 제시 한다면, 이를 수행하기 위한 구체적인 방법은 팀에서 정의하고 만들어나가야 한다. (매뉴얼이 없다!!)
Devops의 특징
그래도 최소한 Devops를 적용하기 위해서는 어떻게 해야 할까? “팀을 합치고 문화를 바꾸세요.” 이건 너무 추상적이지 않나? 몇가지 제공되는 가이드 들이 있는데, 다음은 영국정부에서 제공하는 “Good Habit for Devops[4]”의 내용을 정리한것이다. 기본적인 내용이지만, 참 많은 의미를 담고 있는 내용들이라서 몇번을 다시 생각해봐도 의미가 있는 내용이다.
① Cross functional team – 하나의 팀에 각각 다른 역할을 할 수 있는 팀원들로 셋업해서 전체 End 2 End 서비스를 운용할 수 있도록 한다. 앞에서 개발자가 만능이되야 한다고 이야기 했지만, 그렇다고 만능 개발자로 전체 팀을 채워서 일을 하라는 것이 아니다. 개발자의 커버러지가 넓어지고 협업은 해야 하겠지만, 그렇다고 모든 개발자가 그렇게 수퍼개발자일리는 없고, 엄연하게 다른 역할이 존재 한다. 예를 들어, 테스트 엔지니어, 빌드엔지니어등.
단 여기서 Cross functional team이란, 한 팀내에서 서비스의 기획에서부터 운영 그리고 더 나아가서 영업등 해당 서비스에 관련된 모든 것 “ALL!!”을 할 수 있는 구조로 팀을 셋업 하라는 것이다.
② Widely Shared Metris – 개인적으로 가장 중요하다고 생각하는 항목중의 하나인데, 팀 전체가 기준으로 삼을 수 있는 서비스에 대한 공통적인 지표 (Metric)이 필요하다. 서비스를 개발하고 개선했을 때, 이를 평가하고 현재의 서비스의 진행 상태 (성공 여부, 시스템의 안정성, 사용자의 반응 등)를 인지할 수 있는 기준이 필요하다는 것이다.
예를 들어, 일 방문자수, 평균 체류 시간, 가입자수와 같은 비즈니스 지표에서부터, CPU 사용률, 메모리 사용률, 응답 시간등 기술 지표등이 있다.
기존 개발에서는 요건 받아서 개발하고, 운영으로 던져버렸기 때문에, 사용자들이 서비스에 만족하는지 운영에는 문제가 없는지에 대한 피드백이 전혀 없었다. 이 Metric을 팀 전체에 공유하고 꾸준하게 추적함으로써, 팀 전체가 서비스의 상태를 인지하고, 협업을 통해서 이에 대한 개선 작업을 진행할 수 있게 되는 것이다.
※ 대형 TV나 모니터등으로, 기본 서비스 및 시스템 운영 지표에 대해서는 사무실에 붙여 놓는 것도, 나쁘지 않다.
③ Automating repetitive tasks – 반복적인 작업을 툴을 이용해서 자동화 한다. 일반적으로 우리가 CI (Continuous Integration)이나 CD (Continuous Delivery)등을 이용해서 다루는 빌드, 배포, 테스트 자동화 들이 이에 속한다. 반복적인 작업의 자동화를 통해서 똑똑한 개발 자원들이 반복작업에 투여되는 시간을 줄여서 작업의 효율을 높이고 여기에 더해서 배포나 테스트에 관련된 시간을 줄여서 빠른 서비스 업데이트를 가능하게 하며, 마지막으로 이런 자동화 시스템 구축을 통해서 전체 시스템에 대한 이해도를 높일 수 있다.
④ Post mortems – 직역하자면 해부? 사후 검증 정도의 의미가 되는데, 장애나 이슈가 있을때, 처리 후에, 그 내용을 전체 팀과 공유해야 한다. 서비스를 운영하는 팀의 문제점은 이슈등에 대한 심각도가 얼마나 높은지를 인지하지 못하는 경우가 많다. 시스템이 정지되었을 때, 비즈니스 적으로 손실이 어떤지,얼마나 심각한 문제를 인지하고 궁극적으로는 원인을 파악함으로써 다음 부터는 같은 이슈가 다시 발생하지 않도록 할 수 있다.
⑤ Regular release – 마지막으로 정기 릴리즈이다. 시스템 릴리즈는 많은 협업이 필요한 작업이다. 개발도 끝내야 하고, 테스트, 배포 과정을 거쳐야 하고, 릴리즈가 끝나면 다음 릴리즈를 위한 기능 정의 등의 과정을 거쳐야 한다. 그래서 정기적으로 릴리즈 주기를 설정하면, 전체 협업을 하는 입장에서 언제 어떤 협업을 해야 할지도 명확해지고, 개발이 리듬(?)을 타게 된다.
첨언을 하자면, 짧은 주기의 정기 릴리즈를 통해서, 빠르게 서비스의 기능을 개선하고, 고객의 VoC를 반영해나갈 수 있다.
Devops 기반의 개발팀
Devops 기반의 서비스 팀은 End 2 End 서비스를 커버할 수 있어야 한다.
그리고 Devops는 개발과 운영을 포함한 팀 운영 방법론이라고 소개했었다. 그렇다고 기존 팀 모델에 개발과 운영만 합쳐 놓는다고 모든 문제가 해결 되는 것이 아니다. 다양한 Devops 기반의 팀 모델링이 있게지만, 몇 가지 레퍼런스를 소개하고자 한다.
영국 정부가 운영 하는 https://www.gov.uk/service-manual/the-team 에 역할이 잘 정리되어 있음. Scrum 방법론 기반이 아니라 익숙하지는 않지만, 유사한 팀 모델링. 100% 따라하기 보다는 레퍼런스. 개발뿐만 아니라 전체 비즈니스, 기획적인 면에서 많이 고려가 되어 있으며, 상세한 내용과, R&R, 그리고, Job Description까지 나와 있다.
사실 디테일 자체는 다를 수 있지만 기본적으로 Devops 기반의 팀의 조직 구조는 대부분 유사하다.
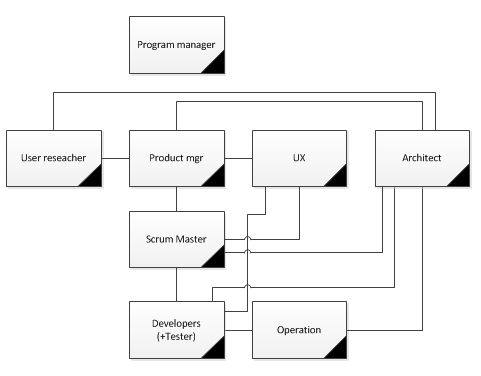
전체 서비스를 관장하는 역할을 갖는 사람이 있다. Service Manager, Program Manager 보통 정의 하는데, 개발,운영뿐만 아니라 전체 서비스 기획, Stake holder등과의 Communication등 전체 프로젝트에 대한 전반적인 내용을 커버 한다.
Product manager가 중요한 역할인데, 서비스를 기획하고 요구 사항을 정의하며, 우선 순위를 메긴다. 기존의 개발 방식에서도 기획이 있었는데, 기존 기획은 요구 사항을 정의하고 개발에 넘기면 끝이었지만, 이러한 팀의 모델링 구조에서는 개발팀과 계속 협업하면서 모자른 요구 사항을 재정의 및 다듬어 나가고, 우선 순위를 끊임 없이 조정해 나간다.
UX는 Product manager와 아주 밀접한 관계에서, 서비스에 대한 UX 디자인을 프로토타입에서, 개발 단계까지 정의하고, 사용자의 피드백에 따라서, 끊임 없이 UX를 개선해 나간다.
그리고,실제 개발팀을 이끄는 Project Leader나 Scrum Manager가 있다. 일정관리, 개발 리소스 관리등을 담당한다. 또 전체 시스템에 구조와 틀을 잡는 아키텍트 역할이 있고, (아키텍트의 종류 - http://bcho.tistory.com/668 대규모 팀에서는 아키텍트도 역할을 나눌 필요가 있다.)
필요에 따라서 테스트 엔지니어를 별도로 두기도 하는데, 일반적인 기능 테스트 등은 개발자가 함께 테스트 케이스를 작성해서 자동화 해서 수행하는 경우가 많고, 경우에 따라서는 성능 테스트까지 함께 하는 경우가 있다. 성능 엔지니어링이 복잡한 경우에는 별도의 성능 테스트 엔지니어를 두는 경우도 있다.
빼먹기 쉬운 역할 중에 하나가 Contents Writer/Technical Writer인데, 서비스에 들어가는 컨텐츠에 대한 컨텐츠를 작성하고 리뷰등을 수행한다. 다국어 번역이나, 컨텐츠의 내용이 해당 서비스 국가에 문제가 없는지 까지 검증하는 역할을 한다. 일반적인 웹사이트에서는 웹 컨텐츠, 테크니컬 사이트의 경우에는 샘플 코드나, 가이드등의 작업을 한다.
마지막으로, 서비스 전략/user researcher라는 역할을 들 수 있는데, 이 역할은 Product manager보다 선행해서, 서비스나 제품이 나가야할 방향을 정의한다. 시장 상황을 분석하고, 수익 구조 및 비즈니스 모델을 정의하고, 주요 제품 로드맵을 정의한다. Product manager와 역할이 겹치는 부분이 있지만, Product manager가 detail 한 서비스에 대한 기획은 서비스 자체 관점에서 한다면, user researcher는 조금 더 넓은 범위에서 제품의 방향과 비즈니스 및 수익 관점에서 서비스를 바라본다.
Devops 기반의 팀의 개발 싸이클
그렇다면 Devops 기반의 개발팀의 서비스 개발 싸이클은 어떻게 될까?
영국 정부가 운영하는 사이트 https://www.gov.uk/service-manual/the-team 의 가이드를 참고해 보면 다음과 같은 시나리오로 개발을 진행하도록 되어 있다.
① 사용자의 needs 분석. VoC 수집
② 사용자 스토리 작성 (요구 사항 작성)
③ 사용자 스토리에 대한 scope 정의 및 우선순위 지정
④ Stakeholder에 대한 리포팅 및 관리 (내부 영업, 보고 등)
⑤ 다른 프로젝트와 연관성(dependency) 관리
⑥ 필요의 경우 솔루션 (오픈소스 또는 상용) 평가 및 도입
⑦ 개발!! (디자인, 빌드,테스트, 데모.-iterative way)
⑧ 테스팅. 실 사용자 대상 테스팅 포함
⑨ 서버에 배포
⑩ Security 관리, Compliance 관리 (개인 정보 보호, 국가별 법적 사항 확인등)
⑪ 서비스 운영, 모니터링.
⑫ 대 고객 지원 (Customer Support) – 추가 하였음
이런 프로세스를 한마디로 정리 해보면 결국 Devops 기반의 개발팀의 특징은, 한 팀내에서 모든 개발,테스트,배포 운영이 이루어진다는 것이고, 가장 중요한 것은, 운영을 통해서 사용자의 피드백을 접수하고, 이것이 새로운 요구 사항으로 연결되는데, 이 싸이클이 매우 빠르며 연속적이고 서로 연결 되어 있다 라는 것이다.

참고 : 개발팀의 성숙도별 개발 모델 http://bcho.tistory.com/721
조금 더 정리해서 말하자면 기존 개발팀은 기획팀이 요구사항을 개발팀에 던지고, 개발팀은 개발 내용을 운영에 던지는, waterfall 모델 처럼, 각 팀이 개발 단계별로 자기 역할을 한 후에, 다음 단계로 던지고 잊어 버리는 (fire & forget) 형태라면, Devops 형태의 개발팀은, 던지는 것이 아니라 과정 내내 같이 수행한다. 요구 사항을 개발팀에 넘겨도, 개발팀과 계속 협의를 하면서 요구 사항을 구체화 하고, 개선하며, 개발중에 운영인원과 같이 협의 하면서 최적의 구조를 논의 하면서 개발이 진행된다.
Devops 팀의 개발자의 필요 역량
그럼 Devops 엔지니어가 되고 싶다면? Puppet의 포스팅을 [5]보면 Devops engineer가 가져야 할 역량에 대해서 잘 설명이 되어 있다.
기본적인 소양으로는
코딩능력은 필수 이며
Devops 엔지니어는 기본적으로 개발자를 기본으로 하고 있기 때문에, 개발을 위한 기본적인 코딩 능력. 만약에 운영이나 시스템쪽에 치우친 엔지니어라면 자동화를 만들 수 있는 스크립트 작성 능력등은 필수이다.
다른 사람과 잘 협업하고 커뮤니케이션할 수 있는 능력
Devops는 앞서 설명한바와 같이 큰 틀에서 협업 문화이다. 시작 자체가 개발과 운영간의 소통 문제를 해결하고자 한것이기 때문에, 다른 팀원의 의견을 존중하고 문제를 함께 해결해나갈 수 있는 오픈 마인드 기반의 커뮤니케이션 능력이 매우 중요하다.
그리고 프로세스를 이해하고 때로는 그 프로세스를 재 정의할 수 있는 능력
마지막으로, Devops는 언뜻 보기에는 정형화된 프로세스가 없어 보일 수 있지만, 테스트 자동화, 배포, 그리고 요구 사항에 대한 수집 및 정의등은 모두 프로세스이며, 해당 팀의 모델이나 서비스의 성격에 따라서 만들어나가야 한다. 그래서, 프로세스를 이해하고 준수하며, 같이 만들어나갈 수 있는 능력을 가져야 한다.
필자의 경험상 위의 3가지는 정말로 중요한 요소인데, 많이 놓치는 부분같다. 특히 프로세스 부분에 대해서는 다들 제각각의 프로세스나 자기 사상으로 프로젝트를 진행해서 생기는 문제가 많아 보인다. 사실 프로세스를 지켜 나가는 건 어떻게 보면 귀찮은 일일 수 도 있지만, 같이 일하는 환경이라면 최소한의 기준은 필요하다고 본다.
이런 기본적인 소양 이외에, 몇가지 역량을 예로 들었다.
오픈소스 제품과 툴에 대한 이해
코딩 능력
인프라 시스템에 대한 이해와 시스템 운영 경험
자동화된 툴 (컴파일,테스트,배포)에 대한 이해
비지니스에 대한 이해
오픈 마인드, 커뮤니케이션 및 협업 능력
그리고, Devops 팀의 엔지니어는 부족한 부분을 메꾸기 위해서 공부는 필수이다. 그 보다 더 중요한 것은 경험이다.. 운영은 직접 겪어 보기전에는 알 수 없다. 그리고 오픈 마인드 기반으로 커뮤니케이션을 해가면서 문제를 풀고 협업하는 능력은 책이 아니라 직접 겪어야 얻을 수 있는 능력이다.
요즘 같이 비지니스 변화가 심하고 멀티롤 개발자가 필요한 시점에 Devops 를 수행할 수 있는 능력의 개발자의 가치는 점점 높아지고 있다. Mashable에 따르면 가장 빠르게 성장하고 있는 IT Job 중의 하나가 Devops Engineer이다. http://mashable.com/2013/11/13/fastest-growing-jobs/
Devops팀을 셋업 할때 주의할점
Devops 팀에 대한 확실한 정의나 가이드는 없다. 그럼에도 불구 하고, 여러 블로그나 몇몇 서적등에서 Devops의 개념에 대해 설명할때, Devops 팀 셋업시 주의할점을 몇가지 드는 것이 있다.
첫번째가 Devops 팀을 만들지 말것.
Devops 팀은 개발과 운영을 합쳐서 같이 운영하는 것이지 이를 위해서 개발과 운영을 모두 할 수 있는 팀을 새로 만들어서 개발팀과 운영팀 내에 배치하게 되면, 오히려 추가적인 burden을 더 넣는 것이다. Devops는 개발과 운영을 하나의 팀으로 합쳐서, 커뮤니케이션에서 오는 부하를 줄이기 위함임을 잊지 말자
Devops 엔지니어를 채용하지 말아라
여기에 대해서는 의견이 분분한 면이 있는데, 내 경우에는 이 의견에 어느정도 공감한다. Devops 엔지니어를 채용해서 팀을 Devops화 시킨다... 이건 한마디로 돈으로 Devops를 사겠다. 즉 돈으로 "문화"를 사겠다는 의미인데, Devops 엔지니어는 Devops 팀에서 일하는 하나의 사람일 뿐이다 Devops를 하려면 전체 조직 문화를 변경 시켜야 한다. 이는 한 두사람의 엔지니어를 채용한다고 되는 일이 아니라. 경영자가 이에 대한 확실한 의지를 가지고 있을때, Devops에 대해서 외부로 부터 가이드나 도움은 받을 수 있겠지만, 어떻게 문화를 바꿀 수 있는지에 대해서 접근하고, 조직 내부에서 부터의 문화 변경을 시도하는 것이 좋다. 경영자가 Devops에 대한 이해가 없고, 단기간내에 성과를 내려고 한다면, 글쎄.. 개인적인 생각으로는 성공하기 쉽지 않으리라 본다. 이미 애자일 방법론을 적용할때, 경영자의 이해와 강력한 스폰서 쉽 그리고 문화의 변경을 기다려 주는 인내가 없는 경우 도입에 실패하는 경우를 숱하게 봤다. 이런 문화적인 변화는 수동적으로 시킨다고 되는것이 아니다. 조직 전체에 공감대가 형성이 되고, 능동적인 자세 아래서, 변화가 가능한 것이다.
재미있는 사례가 있는데, 쿠팡(소셜커머스 업체)가 많은 개발자가 있음에도 불구하고, 1년여간에 걸쳐서 애자일 방법론을 성공적으로 도입한 사례이다. http://blog.naver.com/coupang1104/140200775250
Devops는 아니지만, 문화를 변경한다는 관점에서, 주목해볼만한 사례이다.
Devops 팀에서는 개발자가 개발 및 운영을 다한다? 아니면 별도의 운영자가 있다?
사실 Devops에 대한 개념을 잡는 것중에서 가장 헷갈렸던 부분이 부분인데, 개발팀과 운영팀을 합쳐서 하나의 팀을 만들었다고 하자. 그러면. 개발자가 개발 및 운영을 다하는 것인가? 아니면 그 안에서도 개발과 운영롤을 나눠야 하는 것인가?
사실 내 대답은 "그때 그때 달라요"이다. 팀내에 개발하는 사람이 운영을 다할 수 있으면, 개발자가 운영까지 하는 모델로 가는 것이고, 기존 팀이 개발과 운영으로 갈려 있었다면, 팀내에서도 개발롤과 운영롤로 나누되, 둘간의 협업을 잘 만들어내는 것이 관건이다.
사실 결과적으로는 개발역할과 운영 역할이 팀 내에서도 나눠 질 수 밖에 없다고 본다. 개발자의 역량 한계상, 모든 것을 다할 수는 없고, 각자 선호하는 분야가 있기 때문이다.
Devops의 경우 소규모 스타트업 기업에 유리. 조직이 큰 경우 인내심을 가지고 차근차근 적용해 나가야
소규모 스타트업의 경우 개발과 운영팀을 분리할 규모도 안되서 각각의 엔지니어가 여러 역할을 동시 수행해야 하고, 빠른 개발 주기를 가지고, 개발 문화를 초반 부터 만들어나가야 하는 단계이기 때문에, 매우 적절하다고 볼 수 있다. 그러나 이미 크기가 커버린 일반적인 개발팀의 경우에는 전체 문화를 바꾸는 것 자체가 모험이다. 단기적인 전략보다는 장기적인 전략으로 Devops라는 문화 변경 프로젝트를 바라봐야 할것이며, 또한 그 변화의 기간동안 인내심 있게 이를 지원해줄 조직의 경영층이 필요하다.
한마디로 Devops란 개발과 운영을 합쳐서 하나의 조직내에서 서비스를 독립적으로 개발 및 운영할 수 있는 협업 체계이자 개발 문화라고 정의할 수 있다.
개발과 운영의 조화 - Devops #2/2
1편 글 링크 - http://bcho.tistory.com/815 Devops의 정의 이러한 개념들을 적극적으로 적용한 기업들이 Netflix, Flicker와 같은 인터넷 서비스 기업이다. 기존 개발 프로세스에 비해서 훨씬 빠르게 고객의 요구..
bcho.tistory.com
'IT이론' 카테고리의 다른 글
| CQRS(Command and Query Responsibility Segregation) 명령-질의 책임분리란? (0) | 2019.09.09 |
|---|---|
| 리팩토링 - 디메테르의 법칙(The Law of Demeter),최소 지식 원칙 (0) | 2019.09.08 |
| 성능 분석 및 튜닝이란?(performance tuning) (1) | 2019.07.16 |
| The Twelve-Factor App (0) | 2019.04.03 |
| 재귀호출(재귀함수) (0) | 2018.03.09 |