

'2019/08'에 해당되는 글 49건
- 2019.08.11 :: Front-End - Vue.js 컴포넌트란?(뷰 컴포넌트)
- 2019.08.10 :: Front-End - Vue.js 인스턴스(Vue 인스턴스)
- 2019.08.10 :: Front-End - Vue.js란? 특징 및 장점? 2
- 2019.08.05 :: Java - HashMap 동작 방법(jdk1.7,1.8 차이점)
- 2019.08.05 :: Springboot - DB Datasource 암호화/복호화(application.properties)
- 2019.08.04 :: OS - ssh 비밀번호 없이 접속하기
- 2019.08.03 :: 끝이 열려 있는 수업과 학습?
- 2019.08.01 :: 네트워크 - HTTP/HTTPS 차이점, HTTPS란?

오늘 포스팅할 내용은 Vue 컴포넌트이다. 여기서 말하는 컴포넌트란 무엇일까? 컴포넌트는 하나의 블록을 의미한다. 레고처럼 여러 블럭을 쌓아서 하나의 집을 모양을 만들 듯이, 컴포넌트를 활용하여 화면을 만들면 보다 빠르게 구조화하여 일괄적인 패턴으로 개발할 수 있다. 이렇게 화면의 영역을 컴포넌트로 쪼개서 재활용할 수 있는 형태로 관리하면 나중에 코드를 다시 사용하기가 훨씬 편리하다. 또한 모든 사람들이 레고의 사용설명서처럼 정해진 방식대로 컴포넌트를 등록하거나 사용하게 되므로 남이 작성한 코드를 직관적으로 이해할 수 있다.

위 그림에서 보듯이 하나의 페이지를 여러 블록으로 나누었고, 여러 블록으로 조합하여 하나의 화면으로 만들었다. 그리고 하나의 특징이라면 하나의 블록 안에 또 다른 블록들이 들어가 있는 상-하위 구조를 가진다. 이러한 컴포넌트들은 커다란 최상위 컴포넌트 위에 작성되어 있기 때문에 오른쪽 그림과 같이 Root 컴포넌트를 시작으로 트리 구조를 형성한다.
컴포넌트 등록하기
컴포넌트를 등록하는 방법은 전역과 지역 두 가지가 있다. 지역 컴포넌트는 특정 인스턴스내에서만 유효한 범위를 갖고, 전역 컴포넌트는 여러 인스턴스에서 공통으로 사용할 수 있다. 즉, 지역은 특정 범위 내에서만 사용할 수 있고, 전역은 뷰로 접근 가능한 모든 범위에서 사용할 수 있다.
전역 컴포넌트
전역 컴포넌트는 뷰 라이브러리를 로딩하고 나면 접근 가능한 Vue 변수를 이용하여 등록한다. 전역 컴포넌트를 모든 인스턴스에 등록하려면 Vue 생성자에서 .component()를 호출하여 수행한다.
|
1
2
3
|
Vue.component('컴포넌트 이름',{
//컴포넌트 내용
});
|
cs |
전역 컴포넌트 등록 형식에는 컴포넌트 이름과 컴포넌트 내용이 있다. 컴포넌트 이름은 template 속성에서 사용할 HTML 사용자 정의 태그 이름을 의미한다. 그리고 컴포넌트 태그가 실제 화면의 HTML 요소로 변환될 때 표시될 속성들을 컴포넌트 내용에 작성한다. 컴포넌트 내용에는 template, data, methods 등 인스턴스 옵션 속성을 정의할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
<html>
<head>
<title>Vue Sample</title>
</head>
<body>
<div id="app">
<button>컴포넌트 등록</button>
<my-component></my-component>
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.2/dist/vue.js"></script>
<script>
Vue.component('my-component',{
template: '<div>전역 컴포넌트가 등록되었습니다 !</div>'
});
new Vue({
el:'#app'
});
</script>
</body>
</html>
|
cs |
HTML 태그로 전역 컴포넌트의 이름을 사용하고, 해당 태그의 내용은 전역 컴포넌트의 내용으로 표시된다. 결과는 아래와 같다.

지역 컴포넌트 등록
지역 컴포넌트 등록은 전역 컴포넌트 등록과는 다르게 인스턴스에 components 속성을 추가하고 등록할 컴포넌트 이름과 내용을 정의한다.
|
1
2
3
4
5
6
|
new Vue({
...
components:{
'componentName':componentContent
}
})
|
cs |
바로 예제를 살펴보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
<html>
<head>
<title>Vue Sample</title>
</head>
<body>
<div id="app">
<button>컴포넌트 등록</button>
<my-component></my-component>
<my-local-component></my-local-component>
</div>
<hr>
<div id="app2">
<button>컴포넌트2 등록</button>
<my-component></my-component>
<my-local-component></my-local-component>
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.2/dist/vue.js"></script>
<script>
Vue.component('my-component',{
template: '<div>전역 컴포넌트가 등록되었습니다 !</div>'
});
var cmp = {
template: '<div>지역 컴포넌트가 등록되었습니다 !</div>'
}
new Vue({
el:'#app',
components:{
'my-local-component': cmp
}
});
new Vue({
el: '#app2'
})
</script>
</body>
</html>
|
cs |
여기서 전역과 지역의 유효 범위까지 살펴볼 것이다. 예제코드에서는 전역 컴포넌트와 지역 컴포넌트를 모두 작성하였다. 그리고 특정 태그 내에 컴포넌트들을 등록하였는데, 결과는 두 영역이 다르게 나타난다. app이라는 id를 가진 돔 요소는 전역,지역 컴포넌트를 모두 가지지만 app2라는 id를 가진 돔 요소는 전역 컴포넌트만 가지게 된다. 그 이유는 처음에서 설명한 유효성 범위와 관련있다.
전역 컴포넌트는 어느 인스턴스에나 사용가능한 컴포넌트이지만 지역 컴포넌트는 특정 인스턴스 내에서만 사용가능한 컴포넌트이기 때문에 app이라는 유효범위 내에서 설정된 'my-local-component' 같은 경우는 app이라는 id를 가진 돔 요소에서만 사용가능하고, 전역 컴포넌트로 등록된 'my-component'는 어느 뷰 인스턴스에나 사용가능하다.

여기까지 간단히 뷰 컴포넌트에 대하여 다루어보았다. 다음 포스팅에서는 이러한 컴포넌트들끼리의 통신에 대해 알아볼 것이다.
'Front-End > Vue.js' 카테고리의 다른 글
| Front-End - Vue.js 인스턴스(Vue 인스턴스) (0) | 2019.08.10 |
|---|---|
| Front-End - Vue.js란? 특징 및 장점? (2) | 2019.08.10 |

뷰 인스턴스의 정의와 속성
뷰 인스턴스는 뷰로 화면을 개발하기 위해 필수적으로 생성해야 하는 기본 단위이다. 즉 뷰로 화면을 개발하기 위해 빠트릴 수 없는 필수 조건이다.
뷰 인스턴스 생성
뷰 인스턴스를 사용하기 위해 아래와 같은 형식으로 뷰 인스턴스를 생성한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
<html>
<head>
<title>Vue Sample</title>
</head>
<body>
<div id="app">
{{message}}
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.2/dist/vue.js"></script>
<script>
new Vue({
el:'#app',
data:{
message: 'Hello Vue.js !'
}
});
</script>
</body>
</html>
|
cs |
위의 코드를 간단히 설명하자면 HTML화면에 'Hello Vue.js !' 라는 텍스트를 출력하기 위한 코드이다. 일단 new Vue()로 뷰 인스턴스를 생성하였다. 물론 이전에 Vue 인스턴스를 사용할 수 있게 vue.js 라이브러리를 내려받고 있는 코드가 존재한다. 그리고 인스턴스 안에 el 속성으로 해당 뷰 인스턴스의 범위를 설정해주었고, data 속성에 message 값을 정의하여 화면의 {{message}}에 'Hello Vue.js !'가 출력되도록 하였다. 잘 보면 el의 범위가 특정 div의 아이디 값과 매칭되는 것이 보인다.(css 선택자) 즉, 해당 뷰 인스턴스는 app이라는 아이디를 가진 특정 HTML 태그라는 범위를 갖고 사용되는 인스턴스인 것이다.
뷰 인스턴스 옵션 속성
뷰 인스턴스 옵션 속성은 인스턴스를 생성할 때 재정의할 data, el, template 등의 속성을 의미한다. 이 말은 무엇이냐, 이미 Vue 인스턴스에는 el,data,template 등의 속성이 선언되어 있지만 우리가 뷰 인스턴스를 생성할 때 해당 옵션들을 재정의 할 수 있다는 것이다. 위 코드에서는 data라는 미리 선언된 옵션에 message 라는 data(key/value)를 재정의 하였고 해당 값을 HTML 태그 내에서 사용하는 것을 볼 수 있다. 또한 해당 뷰 인스턴스의 범위(el)옵션을 '#app'으로 재정의하고 있다. 여기서 '#app'은 id가 app인 특정 돔 요소를 뜻한다.
| 속성 | 설명 |
| template | 화면에 표시할 HTML, CSS 등의 마크업 요소를 정의하는 속성. 뷰의 데이터 및 기타 속성들도 함께 화면에 그릴 수 있다. |
| methods | 화면 로직 제어와 관계된 메소드를 정의하는 속성. 마우스 클릭 이벤트 처리와 같이 화면의 전반적인 이벤트와 화면 동작과 관련된 로직을 추가 할 수 있다. |
| created | 뷰 인스턴스가 생성되자마자 실행할 로직을 정의할 수 있는 속성. 뷰 인스턴스의 라이프 사이클과 관련된 속성이다. created 이외에 많은 라이프 사이클 훅을 정의할 수 있는 옵션이 존재한다. |
뷰 인스턴스의 유효 범위
위에서 뷰 인스턴스의 유효범위라는 단어가 포함된 설명이 존재하였다. 그렇다면 자세히 뷰 인스턴스의 유효범위에 대하여 다루어보자. 뷰 인스턴스를 생성하면 HTML의 특정 범위 안에서만 옵션 속성들이 적용되어 나타난다. 이를 인스턴스의 유효 범위라고 한다. 다음 포스팅에서 다루어볼 "지역,전역 컴포넌트 이해"에도 중요한 내용이니 꼭 기억해야한다. 위에서 말했듯이 뷰 인스턴스의 유효범위는 el 속성과 밀접한 관계가 있다.
뷰 인스턴스의 유효 범위를 이해하려면 실제로 인스턴스의 라이플 사이클을 이해할 필요가 있다.
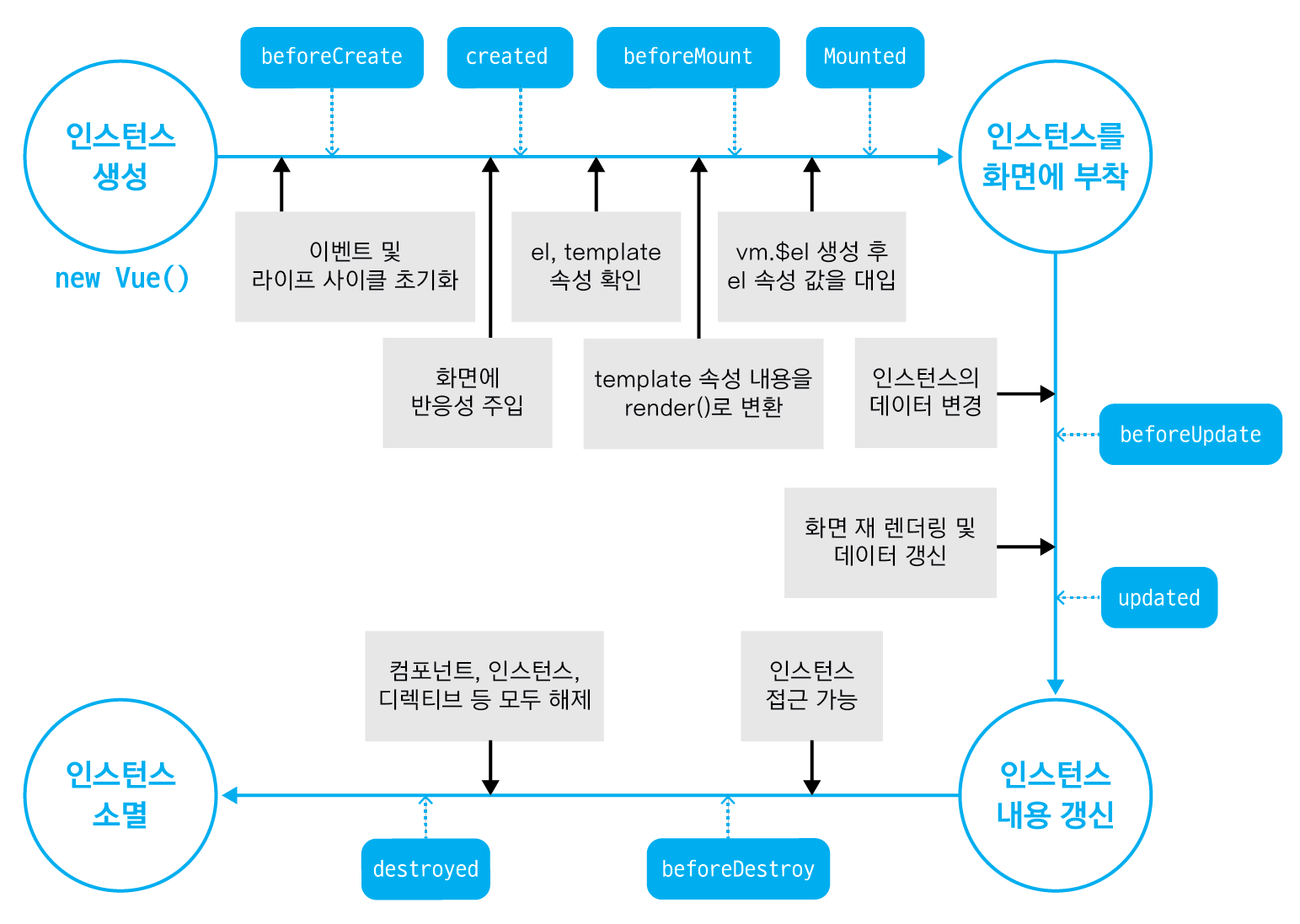
우리가 위에서 작성한 코드는 위의 라이프 사이클 흐름중 인스턴스를 화면에 부착하는 것까지의 행위를 정의한다. 먼저 자바스크립트 코드 상에서 인스턴스 옵션 속성 el과 data를 인스턴스에 정의하고 인스턴스를 생성하였다. 그리고 브라우저에서 코드를 실행시키면 el 속성에 지정된 HTML의 특정 돔요소에 인스턴스가 부착된다.(부착된다의 의미를 그냥 적용된다라고 이해해도 좋다.) el 속성에 해당하는 특정 돔 요소에 뷰 인스턴스가 부착되고 나면 인스턴스에 정의한 data 속성이 el 속성에 지정한 특정 돔 요소에 값이 적용되고 화면의 {{message}}가 'Hello Vue.js !'라는 텍스트로 치환된다.
이해하기 힘들면 '아 그렇구나 !'하고 넘어가도 좋다. 나중 포스팅에서 다시 다루어보면서 해당 의미를 다시 한번 정확히 파악해 볼것이고, 이번 포스팅에서는 뷰가 무엇이고 어떻게 간단히 사용되는지 설명하는 포스팅이다.
그렇다면 현재 <div id="app"></div> 안에 있는 {{message}}를 해당 태그 밖으로 빼보자. 어떻게 되는가? {{message}}라는 문자열이 그대로 화면에 출력되는 것이 보일 것이다. 이것이 바로 뷰 인스턴스의 유효범위이다. app이라는 아이디를 가진 특정 돔 요소에서 벗어나 버리면 뷰 인스턴스에 정의한 data를 사용할 수가 없는 것이다. 꼭 기억하자.
뷰 인스턴스 라이프 사이클
앞에서 살펴본 뷰 인스턴스 옵션 중 created라는 속성을 기억할 것이다. 해당 옵션은 인스턴스가 생성되었을 때 호출할 동작을 정의하는 속성이라고 설명하였다. 이처럼 인스턴스의 상태에 따라 호출할 수 있는 속성들을 라이프 사이클 속성이라고 한다. 그리고 각 라이프 사이클 속성에서 실행되는 커스텀 로직을 라이프 사이클 훅이라고 한다. 위의 그림에서 beforeUpdate, updated 사이클은 데이터의 변경이 없다면 지나지 않는 라이프 사이클임을 주의하자.
라이프 사이클 속성에는 총 8개가 존재한다. 위의 그림을 같이 참조하여 살펴보자.
| 속성 | 설명 |
| beforeCreate | 인스턴스가 생성되고 나서 가장 처음으로 실행되는 라이프 사이클 단계이다. 이 단계에서는 data 속성과 methods 속성이 아직 인스턴스에 정의되어 있지 않고, 돔과 같은 화면 요소에도 접근할 수 없다. |
| created |
beforeCreate 라이프 사이클 단계 다음에 실행되는 단계이다. data 속성과 methods 속성이 정의되었기 때문에 this.data 또는 this.fetchData()와 같은 로직들을 이용하여 data 속성과 methods 속성에 정의된 값에 접근하여 로직을 실행할 수 있다. 다만, 아직 인스턴스가 화면 요소에 부착되기 이전이기 때문에 template 속성에 정의된 돔 요소로 접근할 수 없다. data 속성과 methods 속성에 접근할 수 있는 가장 첫 라이프 사이클 단계이자 컴포넌트가 생성되고 나서 실행되는 단계이기 때문에 서버에 데이터를 요청하여 받아오는 로직을 수행하기 좋다. |
| beforeMount |
created 단계 이후 template 속성에 지정한 마크업 속성을 render() 함수로 변환한 후 el 속성에 지정한 특정 화면 요소에 인스턴스를 부착하기 전에 호출되는 단계이다. render()가 호출되기 이전에 로직을 추가하기 좋다.
render() - 자바스크립트로 화면의 돔을 그리는 함수 |
| mounted |
el 속성에서 지정한 화면 요소에 인스턴스가 부착되고 나면 호출되는 단계로, template 속성에 정의한 화면 요소에 접근할 수 있어 화면 요소를 제어하는 로직을 수행하기 좋은 단계이다. 다만, 돔에 인스턴스가 부착되자마자 바로 호출되기 때문에 하위 컴포넌트나 외부 라이브러리에 의해 추가된 화면 요소들이 최종 HTML 코드로 변환되는 시점과 다를 수 있다. 변환되는 시점이 다를 경우 $nextTick() API를 이용하여 HTML 코드로 최종 파싱될 때까지 기다린 후 돔 제어 로직을 추가한다. |
| beforeUpdate |
el 속성에서 지정한 화면 요소에 인스턴스가 부착되고 나면 인스턴스에 정의한 속성들이 화면에 치환된다. 치환된 값은 뷰의 반응성을 제공하기 위해 $watch 속성으로 감시한다. 또한 beforeUpdate는 관찰하고 있는 데이터가 변경되면 가상 돔으로 화면을 다시 그리기 전에 호출되는 단계이며, 변경 예정인 새 데이터에 접근할 수 있어 변경 예정 데이터의 값과 관련된 로직을 미리 넣을 수 있다.
뷰의 반응성 : 뷰의 특징 중 하나로, 코드의 변화에 따라 화면이 반사적으로 반응하여 빠르게 화면을 갱신하는 것을 의미. |
| updated | 데이터가 변경되고 나서 가상 돔으로 다시 화면을 그리고나면 실행되는 단계이다. 데이터 변경으로 인한 화면 요소 변경까지 완료된 시점이므로, 데이터 변경 후 화면 요소 제어와 관련된 로직을 추가하기 좋은 단계이다. 이 단계에서 데이터 값을 변경하면 무한 루프에 빠질 수 있기 때문에 값을 변경하려면 computed, watch 와 같은 속성을 사용해야 한다. 따라서 데이터 값을 갱신하는 로직은 가급적이면 beforeUpdate에 추가하고, updated에서는 변경 데이터의 화면 요소와 관련된 로직을 추가하는 것이 좋다. |
| beforeDestroy | 뷰 인스턴스가 파괴되기 직전에 호출되는 단계이다. 이 단계에서는 아직 인스턴스에 접근할 수 있다. 따라서 뷰 인스턴스의 데이터를 삭제하기 좋은 단계이다. |
| destroyed | 뷰 인스턴스가 파괴되고 나서 호출되는 단계이다. 뷰 인스턴스에 정의한 모든 속성이 제거되고 하위에 선언한 인스턴스들 또한 모두 제거된다. |
예제 코드를 살펴보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
<html>
<head>
<title>Vue Sample</title>
</head>
<body>
<div id="app">
{{message}}
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.2/dist/vue.js"></script>
<script>
new Vue({
el:'#app',
data:{
message: 'Hello Vue.js !'
},beforeCreate: function(){
console.log("beforeCreate");
},
created: function(){
console.log("created");
},
mounted: function(){
console.log("mounted");
},
updated: function(){
console.log("updated");
}
});
</script>
</body>
</html>
|
cs |
위코드를 수행해보자. 어떠한 로그값이 출력될까? 한번 생각해보고 결과를 예측해보자.
결과는 beforeCreate-created-mounted 만 출력될 것이고, updated는 출력되지 않을 것이다. 라이프 사이클 시작점에서 필자가 이야기 했던 부분이 있다. data가 변경되지 않으면 지나지 않는 라이프 사이클이 존재한다고 했는 데, 그 부분이 beforeUpdate, updated라는 라이프 사이클이다.
그렇다면 데이터를 변경하는 로직을 삽입해보자. 과연 updated라는 로그가 출력될까?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
<html>
<head>
<title>Vue Sample</title>
</head>
<body>
<div id="app">
{{message}}
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.2/dist/vue.js"></script>
<script>
new Vue({
el:'#app',
data:{
message: 'Hello Vue.js !'
},beforeCreate: function(){
console.log("beforeCreate");
},
created: function(){
console.log("created");
},
mounted: function(){
console.log("mounted");
this.message="Hello Vue !?";
},
updated: function(){
console.log("updated");
}
});
</script>
</body>
</html>
|
cs |
mounted라는 라이프 사이클에서 message 데이터 값을 변경하였기 때문에 updated라는 라이프 사이클을 지나게 되므로 updated라는 로그가 출력되는 것을 볼 수 있다.
여기까지 뷰 인스턴스에 대해 간략히 다루어보았다. 다음 포스팅에서는 뷰 컴포넌트에 대한 포스팅을 진행할 것이다.
'Front-End > Vue.js' 카테고리의 다른 글
| Front-End - Vue.js 컴포넌트란?(뷰 컴포넌트) (0) | 2019.08.11 |
|---|---|
| Front-End - Vue.js란? 특징 및 장점? (2) | 2019.08.10 |

오늘 포스팅할 내용은 프론트엔드 프레임워크 중에 하나인 vue.js 이다. 필자도 처음 다루어보는 프론트엔드이기 때문에 간단히 vue.js가 무엇인지 알아보자.
Vue.js란?
vue.js는 웹 페이지 화면을 개발하기 위한 프론트엔드 프레임워크이다. vue.js는 여타 다른 프론트엔드 프레임워크보다 배우기 쉽다는 장점이 있다. 리엑트와 앵귤러라는 프레임워크의 장점들을 쏙 빼와서 더욱 빠르고 가볍게 만든 프레임워크라고 한다.
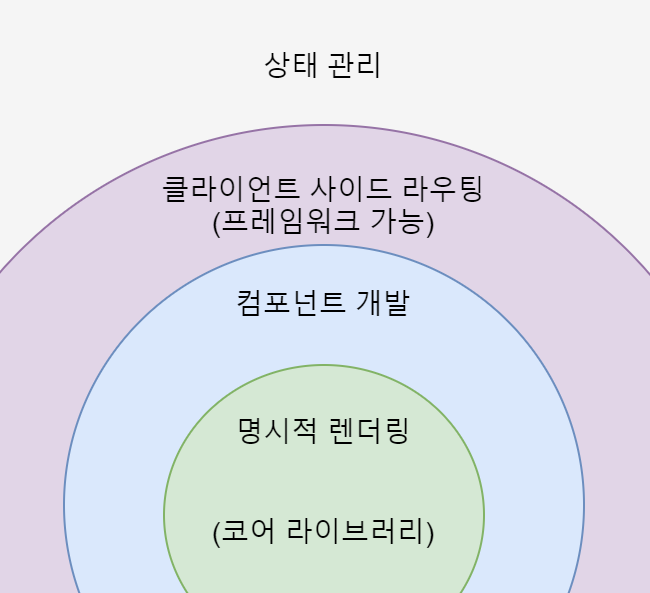
vue.js는 위 그림과 같은 구조를 가지고 있다. 코어 라이브러리는 화면단 데이터 표현에 관한 기능들을 중점적으로 지원하지만 프레임워크의 기능인 라우터, 상태관리, 테스팅 등을 쉽게 결합할 수 있는 형태로도 제공된다. 즉, 단순 라이브러리의 기능 외에 프레임워크 역할도 수행하게 되는 것이다. 그렇다면 이러한 vue.js의 장점은 무엇일까?
Vue.js 장점
뷰 같은 경우는 앵귤러의 데이터 바인딩 특성과 리액트의 가상 돔 기반 렌더링 특징을 모두 가지고 있다.
- 배우기 쉽다.
- 리액트와 앵귤러에 비해 성능이 우수하고 빠르다.
- 리액트의 장점과 앵귤러의 장점을 가지고 있다.
<Vue.js의 특징>
MVVC 패턴
뷰(Vue.js)는 UI 화면 개발 방법 중 하나인 MVVM 패턴의 뷰 모델에 해당하는 화면단 라이브러리이다.

위 그림에서 보듯, MVVM 패턴이란 화면을 모델(Model) - 뷰(View) - 뷰 모델(ViewModel)로 구조화하여 개발하는 방식을 의미한다. 이러한 방식으로 개발하는 이유는 화면의 요소들을 제어하는 코드와 데이터 제어 로직을 분리하여 코드를 더 직관적으로 이해할 수 있고, 추후 유지 보수가 편해진다.
| 용어 | 설명 |
| 뷰(View) | 사용자에게 보이는 화면 |
| 돔(DOM) | HTML 문서에 들어가는 요소(태그,클래스,속성 등)의 정보를 담고 있는 데이터 트리 |
| 돔 리스너(DOM Listener) | 돔의 변경 내역에 대해 즉각적으로 반응하여 특정 로직을 수행하는 장치 |
| 모델(Model) | 데이터를 담는 용기. 보통은 서버에서 가져온 데이터를 자바스크립트 객체 형태로 저장 |
| 데이터 바인딩(Data Binding) | 뷰(View)에 표시되는 내용과 모델의 데이터를 동기화 |
| 뷰 모델(ViewModel) | 뷰와 모델의 중간 영역. 돔 리스너와 데이터 바인딩을 제공하는 영역 |
그렇다면 MVVM 구조의 처리 흐름은 어떻게 될까?

위와 같은 구글 검색 창이 있다고 생각해보자.(실제 구글은 뷰로 개발되지는 않았음. 단순 참고용)
여기서 뷰는 사용자에게 비춰지는 구글 검색화면 전체를 의미한다. 그리고 돔은 구글로고, 검색창, 키보드, Google 검색 버튼 등의 HTML 요소들을 뜻한다. 만약 검색어를 입력하고 Google 검색 버튼을 클릭하면 어떤일이 일어날까?

위와 같은 검색 결과 화면을 보여줄 것이다. 즉, Google 검색 버튼을 클릭하였을 때, 돔 리스너에서 버튼의 클릭을 감지하고 버튼이 동작하면 검색 결과를 보여주는 로직이 실행되는 것이다. 즉, 이 처리 과정에서 데이터 바인딩이 관여하며 검색 결과에 해당하는 데이터를 모델에서 가져와 화면에 나타내 준다.
컴포넌트 기반 프레임워크
뷰가 가지는 또 하나의 큰 특징은 바로 컴포넌트 기반 프레임워크라는 것이다.
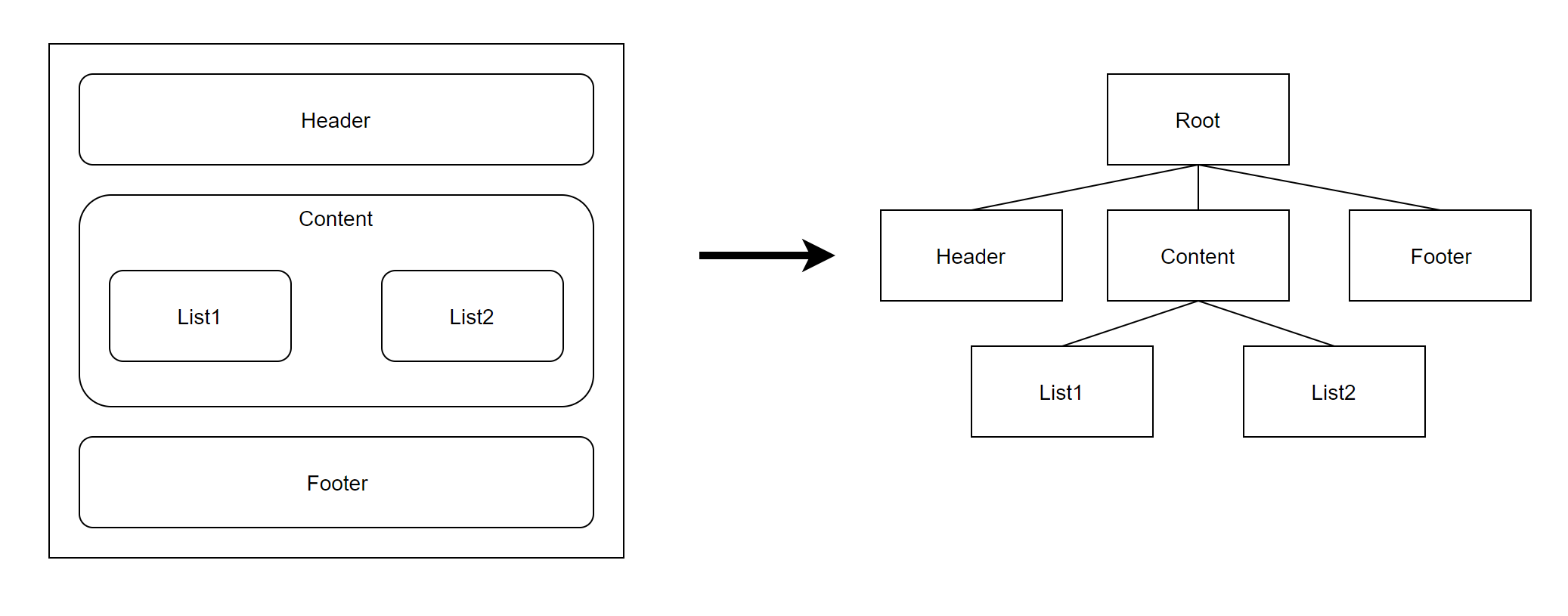
위 그림과 같이 컴포넌트란 레고 블록을 조합하는 것과 비슷하다. 즉, 화면을 왼쪽 같이 구성을 하면 오른쪽과 같은 컴포넌트 트리 구조를 가지게 되는 것이다. 이러한 컴포넌트 기반의 프레임워크를 사용함으로써 코드의 재사용성이 향상되며 직관적인 화면 구조를 갖게 되는 것이다.
리액트와 앵귤러의 장점을 가진 프레임워크
뷰는 앵귤러의 양방향 데이터 바인딩과 리액트의 단방향 데이터 흐름의 장점을 모두 결합한 프레임워크이다. 양방향 데이터 바인딩이란 화면에 표시되는 값과 프레임워크의 모델 데이터 값이 동기화되어 한쪽이 변경되면 다른 한쪽도 자동으로 값이 변경되는 것을 의미한다. 단방향 데이터 흐름은 컴포넌트의 단방향 통신을 의미한다. 즉, 컴포넌트 간에 데이터를 전달할 때 항상 상위 컴포넌트에서 하위 컴포넌트 한 방향으로만 전달하게끔 프레임워크가 구조화되어 있는 것을 말한다.
이 외에도 뷰는 빠른 화면 렌더링을 위해 리액트의 가상 돔 렌더링 방식을 적용하여 사용자 인터랙션이 많은 요즘의 웹 화면에 적합한 동작 구조를 갖추고 있다. 가상 돔을 활용하면 특정 돔 요소를 추가하거나 삭제하는 변경이 일어날 때 화면 전체를 다시 그리지 않고 프레임워크에서 정의한 방식에 따라 화면을 갱신한다. 따라서 브라우저 입장에서는 성능 부하가 줄어들어 일반 렌더링 방식보다 더 빠르게 화면을 그릴 수 있다.
다음 포스팅부터는 실제 뷰를 다루어 볼 것이다.
'Front-End > Vue.js' 카테고리의 다른 글
| Front-End - Vue.js 컴포넌트란?(뷰 컴포넌트) (0) | 2019.08.11 |
|---|---|
| Front-End - Vue.js 인스턴스(Vue 인스턴스) (0) | 2019.08.10 |
네이버의 d2 블로그에 Java Hashmap 동작에 대해 아주 상세히 설명한 자료가 있어 참조해보았다. 해시맵에 대해 아주 상세하게 작성한 글이라 알아두면 아주 좋을 것 같다.
참조 : https://d2.naver.com/helloworld/831311
Java HashMap은 어떻게 동작하는가?
이 글은 Java 7과 Java 8을 기준으로 HashMap이 어떻게 구현되어 있는지 설명합니다. HashMap 자체의 소스 코드는 Oracle JDK나 OpenJDK나 같기 때문에, 이 글이 설명하는 HashMap 구현 방식은 Oracle JDK와 OpenJDK 둘 모두에 해당한다고 할 수 있습니다. Java가 아닌 다른 언어를 주로 사용하는 개발자라 하더라도, Java의 HashMap이 현재 어떻게 구현되어 있고, 어떻게 발전되었는지 알면 라이브러리나 프레임워크 구현에 대한 혜안을 얻을 수 있을 것이라고 기대합니다.
HashMap은 Java Collections Framework에 속한 구현체 클래스입니다. Java Collections Framework는 1998년 12월에 발표한 Java 2에서 정식으로 선보였습니다. Map 인터페이스 자체는 Java 5에서 Generic이 적용된 것 외에 처음 선보인 이후 변화가 없지만, HashMap 구현체는 성능을 향상시키기 위해 지속적으로 변화해 왔습니다.
이 글에서는 어떤 방식으로 HashMap 구현체의 성능을 향상시켰는지 소개합니다. 구체적으로 다루는 내용은 Amortized Constant Time을 위하여 어떻게 해시 충돌(hash collision) 가능성을 줄이고 있는가에 대한 것입니다.
HashMap과 HashTable
이 글에서 말하는 HashMap과 HashTable은 Java의 API 이름이다. HashTable이란 JDK 1.0부터 있던 Java의 API이고, HashMap은 Java 2에서 처음 선보인 Java Collections Framework에 속한 API다. HashTable 또한 Map 인터페이스를 구현하고 있기 때문에 HashMap과 HashTable이 제공하는 기능은 같다. 다만 HashMap은 보조 해시 함수(Additional Hash Function)를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable에 비하여 해시 충돌(hash collision)이 덜 발생할 수 있어 상대으로 성능상 이점이 있다. 보조 해시 함수가 아니더라도, HashTable 구현에는 거의 변화가 없는 반면, HashMap은 지속적으로 개선되고 있다. HashTable의 현재 가치는 JRE 1.0, JRE 1.1 환경을 대상으로 구현한 Java 애플리케이션이 잘 동작할 수 있도록 하위 호환성을 제공하는 것에 있기 때문에, 이 둘 사이에 성능과 기능을 비교하는 것은 큰 의미가 없다고 할 수 있다.
HashMap과 HashTable을 정의한다면, '키에 대한 해시 값을 사용하여 값을 저장하고 조회하며, 키-값 쌍의 개수에 따라 동적으로 크기가 증가하는 associate array'라고 할 수 있다. 이 associate array를 지칭하는 다른 용어가 있는데, 대표적으로 Map, Dictionary, Symbol Table 등이다.
예제 1 HashTable과 HashMap의 선언부
associative array를 지칭하기 위하여 HashTable에서는 Dictionary라는 이름을 사용하고, HashMap에서는 그 명칭이 그대로 말하듯이 Map이라는 용어를 사용하고 있다.
map(또는 mapping)은 원래 수학 함수에서의 대응 관계를 지칭하는 용어로, 경우에 따라서는 함수 자체를 의미하기도 한다. 즉 HashMap이란 이름에서 알 수 있듯이, HashMap은 키 집합인 정의역과 값 집합인 공역의 대응에 해시 함수를 이용한다.

그림 1 함수에서의 사상(map)
해시 분포와 해시 충돌
동일하지 않은 어떤 객체 X와 Y가 있을 때, 즉 X.equals(Y)가 '거짓'일 때 X.hashCode() != Y.hashCode()가 같지 않다면, 이때 사용하는 해시 함수는 완전한 해시 함수(perfect hash functions)라고 한다(
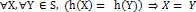
: S는 모든 객체의 집합, h는 해시 함수).
Boolean같이 서로 구별되는 객체의 종류가 적거나, Integer, Long, Double 같은 Number 객체는 객체가 나타내려는 값 자체를 해시 값으로 사용할 수 있기 때문에 완전한 해시 함수 대상으로 삼을 수 있다. 하지만 String이나 POJO(plain old java object)에 대하여 완전한 해시 함수를 제작하는 것은 사실상 불가능하다.
적은 연산만으로 빠르게 동작할 수 있는 완전한 해시 함수가 있다고 하더라도, 그것을 HashMap에서 사용할 수 있는 것은 아니다. HashMap은 기본적으로 각 객체의 hashCode() 메서드가 반환하는 값을 사용하는 데, 결과 자료형은 int다. 32비트 정수 자료형으로는 완전한 자료 해시 함수를 만들 수 없다. 논리적으로 생성 가능한 객체의 수가 232보다 많을 수 있기 때문이며, 또한 모든 HashMap 객체에서 O(1)을 보장하기 위해 랜덤 접근이 가능하게 하려면 원소가 232인 배열을 모든 HashMap이 가지고 있어야 하기 때문이다.
따라서 HashMap을 비롯한 많은 해시 함수를 이용하는 associative array 구현체에서는 메모리를 절약하기 위하여 실제 해시 함수의 표현 정수 범위

보다 작은 M개의 원소가 있는 배열만을 사용한다. 따라서 다음과 같이 객체에 대한 해시 코드의 나머지 값을 해시 버킷 인덱스 값으로 사용한다.
예제 2 해시를 사용하는 associative array 구현체에서 저장/조회할 해시 버킷을 계산하는 방법
이 코드와 같은 방식을 사용하면, 서로 다른 해시 코드를 가지는 서로 다른 객체가 1/M의 확률로 같은 해시 버킷을 사용하게 된다. 이는 해시 함수가 얼마나 해시 충돌을 회피하도록 잘 구현되었느냐에 상관없이 발생할 수 있는 또 다른 종류의 해시 충돌이다. 이렇게 해시 충돌이 발생하더라도 키-값 쌍 데이터를 잘 저장하고 조회할 수 있게 하는 방식에는 대표적으로 두 가지가 있는데, 하나는 Open Addressing이고, 다른 하나는 Separate Chaining이다. 이 둘 외에도 해시 충돌을 해결하기 위한 다양한 자료 구조가 있지만, 거의 모두 이 둘을 응용한 것이라고 할 수 있다.

그림 2 Open Addressing과 Separate Chaining 구조
Open Addressing은 데이터를 삽입하려는 해시 버킷이 이미 사용 중인 경우 다른 해시 버킷에 해당 데이터를 삽입하는 방식이다. 데이터를 저장/조회할 해시 버킷을 찾을 때에는 Linear Probing, Quadratic Probing 등의 방법을 사용한다.
Separate Chaining에서 각 배열의 인자는 인덱스가 같은 해시 버킷을 연결한 링크드 리스트의 첫 부분(head)이다.
둘 모두 Worst Case O(M)이다. 하지만 Open Addressing은 연속된 공간에 데이터를 저장하기 때문에 Separate Chaining에 비하여 캐시 효율이 높다. 따라서 데이터 개수가 충분히 적다면 Open Addressing이 Separate Chaining보다 더 성능이 좋다. 하지만 배열의 크기가 커질수록(M 값이 커질수록) 캐시 효율이라는 Open Addressing의 장점은 사라진다. 배열의 크기가 커지면, L1, L2 캐시 적중률(hit ratio)이 낮아지기 때문이다.
Java HashMap에서 사용하는 방식은 Separate Channing이다. Open Addressing은 데이터를 삭제할 때 처리가 효율적이기 어려운데, HashMap에서 remove() 메서드는 매우 빈번하게 호출될 수 있기 때문이다. 게다가 HashMap에 저장된 키-값 쌍 개수가 일정 개수 이상으로 많아지면, 일반적으로 Open Addressing은 Separate Chaining보다 느리다. Open Addressing의 경우 해시 버킷을 채운 밀도가 높아질수록 Worst Case 발생 빈도가 더 높아지기 때문이다. 반면 Separate Chaining 방식의 경우 해시 충돌이 잘 발생하지 않도록 '조정'할 수 있다면 Worst Case 또는 Worst Case에 가까운 일이 발생하는 것을 줄일 수 있다(여기에 대해서는 "보조 해시 함수"에서 설명하겠다).
예제 3 Java 7에서의 해시 버킷 관련 구현
Separate Chaining 방식을 사용하기 때문에, Java 7에서의 put() 메서드 구현은 예제 4에서 보는 것과 같다.
예제 4 put() 메서드 구현
그러나 Java 8에서는 예제 4에서 볼 수 있는 것보다 더 발전된 방식을 사용한다.
Java 8 HashMap에서의 Separate Chaining
Java 2부터 Java 7까지의 HashMap에서 Separate Chaining 구현 코드는 조금씩 다르지만, 구현 알고리즘 자체는 같았다. 만약 객체의 해시 함수 값이 균등 분포(uniform distribution) 상태라고 할 때, get() 메서드 호출에 대한 기댓값은
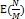
이다. 그러나 Java 8에서는 이보다 더 나은

을 보장한다. 데이터의 개수가 많아지면, Separate Chaining에서 링크드 리스트 대신 트리를 사용하기 때문이다.
데이터의 개수가 많아지면

과

의 차이는 무시할 수 없다. 게다가 실제 해시 값은 균등 분포가 아닐뿐더러, 설사 균등 분포를 따른다고 하더라도 birthday problem이 설명하듯 일부 해시 버킷 몇 개에 데이터가 집중될 수 있다. 그래서 데이터의 개수가 일정 이상일 때에는 링크드 리스트 대신 트리를 사용하는 것이 성능상 이점이 있다.
링크드 리스트를 사용할 것인가 트리를 사용할 것인가에 대한 기준은 하나의 해시 버킷에 할당된 키-값 쌍의 개수이다. 예제 5에서 보듯 Java 8 HashMap에서는 상수 형태로 기준을 정하고 있다. 즉 하나의 해시 버킷에 8개의 키-값 쌍이 모이면 링크드 리스트를 트리로 변경한다. 만약 해당 버킷에 있는 데이터를 삭제하여 개수가 6개에 이르면 다시 링크드 리스트로 변경한다. 트리는 링크드 리스트보다 메모리 사용량이 많고, 데이터의 개수가 적을 때 트리와 링크드 리스트의 Worst Case 수행 시간 차이 비교는 의미가 없기 때문이다. 8과 6으로 2 이상의 차이를 둔 것은, 만약 차이가 1이라면 어떤 한 키-값 쌍이 반복되어 삽입/삭제되는 경우 불필요하게 트리와 링크드 리스트를 변경하는 일이 반복되어 성능 저하가 발생할 수 있기 때문이다.
예제 5 Java 8 HashMap의 TREEIFY_THRESHOLD와 UNTREEIFY_THRESHOLD
Java 8 HashMap에서는 Entry 클래스 대신 Node 클래스를 사용한다. Node 클래스 자체는 사실상 Java 7의 Entry 클래스와 내용이 같지만, 링크드 리스트 대신 트리를 사용할 수 있도록 하위 클래스인 TreeNode가 있다는 것이 Java 7 HashMap과 다르다.
이때 사용하는 트리는 Red-Black Tree인데, Java Collections Framework의 TreeMap과 구현이 거의 같다. 트리 순회 시 사용하는 대소 판단 기준은 해시 함수 값이다. 해시 값을 대소 판단 기준으로 사용하면 Total Ordering에 문제가 생기는데, Java 8 HashMap에서는 이를 tieBreakOrder() 메서드로 해결한다.
예제 6 Java 8 HashMap의 Node 클래스
해시 버킷 동적 확장
해시 버킷의 개수가 적다면 메모리 사용을 아낄 수 있지만 해시 충돌로 인해 성능상 손실이 발생한다. 그래서 HashMap은 키-값 쌍 데이터 개수가 일정 개수 이상이 되면, 해시 버킷의 개수를 두 배로 늘린다. 이렇게 해시 버킷 개수를 늘리면
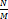
값도 작아져, 해시 충돌로 인한 성능 손실 문제를 어느 정도 해결할 수 있다.
해시 버킷 개수의 기본값은 16이고, 데이터의 개수가 임계점에 이를 때마다 해시 버킷 개수의 크기를 두 배씩 증가시킨다. 버킷의 최대 개수는 230개다. 그런데 이렇게 버킷 개수가 두 배로 증가할 때마다, 모든 키-값 데이터를 읽어 새로운 Separate Chaining을 구성해야 하는 문제가 있다. HashMap 생성자의 인자로 초기 해시 버킷 개수를 지정할 수 있으므로, 해당 HashMap 객체에 저장될 데이터의 개수가 어느 정도인지 예측 가능한 경우에는 이를 생성자의 인자로 지정하면 불필요하게 Separate Chaining을 재구성하지 않게 할 수 있다.
예제 7 Java 7 HashMap에서의 해시 버킷 확장
해시 버킷 크기를 두 배로 확장하는 임계점은 현재의 데이터 개수가 'load factor * 현재의 해시 버킷 개수'에 이를 때이다. 이 load factor는 0.75 즉 3/4이다. 이 load factor 또한 HashMap의 생성자에서 지정할 수 있다.
임계점에 이르면 항상 해시 버킷 크기를 두 배로 확장하기 때문에, N개의 데이터를 삽입했을 때의 키-값 쌍 접근 횟수는 다음과 같이 분석할 수 있다.

즉 기본 생성자로로 생성한 HashMap을 이용하여 많은 양의 데이터를 삽입할 때에는, 최적의 해시 버킷 개수를 지정한 것보다 약 2.5배 많이 키-값 쌍 데이터에 접근해야 한다. 이는 곧 수행 시간이 2.5배 길어진다고 할 수 있다. 따라서 성능을 높이려면, HashMap 객체를 생성할 때 적정한 해시 버킷 개수를 지정해야 한다.
그런데 이렇게 해시 버킷 크기를 두 배로 확장하는 것에는 결정적인 문제가 있다. 해시 버킷의 개수 M이 2a 형태가 되기 때문에, index = X.hashCode() % M을 계산할 때 X.hashCode()의 하위 a개의 비트만 사용하게 된다는 것이다. 즉 해시 함수가 32비트 영역을 고르게 사용하도록 만들었다 하더라도 해시 값을 2의 승수로 나누면 해시 충돌이 쉽게 발생할 수 있다.
이 때문에 보조 해시 함수가 필요하다.
보조 해시 함수
index = X.hashCode() % M을 계산할 때 사용하는 M 값은 소수일 때 index 값 분포가 가장 균등할 수 있다. 그러나 M 값이 소수가 아니기 때문에 별도의 보조 해시 함수를 이용하여 index 값 분포가 가급적 균등할 수 있도록 해야 한다.
보조 해시 함수(supplement hash function)의 목적은 '키'의 해시 값을 변형하여, 해시 충돌 가능성을 줄이는 것이다. 이 보조 해시 함수는 JDK 1.4에 처음 등장했다. Java 5 ~ Java 7은 같은 방식의 보조 해시 함수를 사용하고, Java 8부터는 다시 새로운 방식의 보조 해시 함수를 사용하고 있다.
예제 8 Java 7 HashMap에서의 보조 해시 함수
그런데 Java 8에서는 Java 7보다 훨씬 더 단순한 형태의 보조 해시 함수를 사용한다.
예제 9 Java 8 HashMap에서의 보조 해시 함수
예제 9에서 볼 수 있는 것처럼, Java 8 HashMap 보조 해시 함수는 상위 16비트 값을 XOR 연산하는 매우 단순한 형태의 보조 해시 함수를 사용한다. 이유로는 두 가지가 있는데, 첫 번째는 Java 8에서는 해시 충돌이 많이 발생하면 링크드 리스트 대신 트리를 사용하므로 해시 충돌 시 발생할 수 있는 성능 문제가 완화되었기 때문이다. 두 번째로는 최근의 해시 함수는 균등 분포가 잘 되게 만들어지는 경향이 많아, Java 7까지 사용했던 보조 해시 함수의 효과가 크지 않기 때문이다. 두 번째 이유가 좀 더 결정적인 원인이 되어 Java 8에서는 보조 해시 함수의 구현을 바꾸었다.
개념상 해시 버킷 인덱스를 계산할 때에는 index = X.hashCode() % M처럼 나머지 연산을 사용하는 것이 맞지만, M값이 2a일 때는 해시 함수의 하위 a비트 만을 취한 것과 값이 같다. 따라서 나머지 연산 대신 '1 << a – 1' 와 비트 논리곱(AND, &) 연산을 사용하면 수행이 훨씬 더 빠르다.
String 객체에 대한 해시 함수
String 객체에 대한 해시 함수 수행 시간은 문자열 길이에 비례한다.
때문에 JDK 1.1에서는 String 객체에 대해서 빠르게 해시 함수를 수행하기 위해, 일정 간격의 문자에 대한 해시를 누적한 값을 문자열에 대한 해시 함수로 사용했다.
예제 10 JDK 1.1에서의 String 클래스 해시 함수
예제 10에서 볼 수 있듯이 모든 문자에 대한 해시 함수를 계산하는 게 아니라, 문자열의 길이가 16을 넘으면 최소 하나의 문자를 건너가며 해시 함수를 계산했다.
그러나 이런 방식은 심각한 문제를 야기했다. 웹상의 URL은 길이가 수십 글자에 이르면서 앞 부분은 동일하게 구성되는 경우가 많다. 이 경우 서로 다른 URL의 해시 값이 같아지는 빈도가 매우 높아질 수 있다는 문제가 있다. 따라서 이런 방식은 곧 폐기되었고, 예제 11에서 보는 방식을 현재의 Java 8까지도 계속 사용하고 있다.
예제 11 Java String 클래스 해시 함수
예제 11은 Horner's method를 구현한 것이다. Horner's method는 다항식을 계산하기 쉽도록 단항식으로 이루어진 식으로 표현하는 것이다. 즉 예제 11에서 계산하고자 하는 해시 값 h는 다음과 같다.
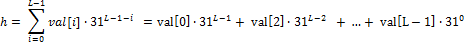

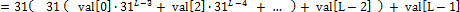
이렇게 단항식을 재귀적으로 사용하여 다항식 연산을 표현할 수 있다.
String 객체 해시 함수에서 31을 사용하는 이유는, 31이 소수이며 또한 어떤 수에 31을 곱하는 것은 빠르게 계산할 수 있기 때문이다. 31N=32N-N인데, 32는 25이니 어떤 수에 대한 32를 곱한 값은 shift 연산으로 쉽게 구현할 수 있다. 따라서 N에 31을 곱한 값은, (N << 5) – N과 같다. 31을 곱하는 연산은 이렇게 최적화된 머신 코드로 생성할 수 있기 때문에, String 클래스에서 해시 값을 계산할 때에는 31을 승수로 사용한다.
Java 7에서 String 객체에 대한 별도의 해시 함수
JDK 7u6부터 JDK 7u25까지는 HashMap에 저장된 키-값 쌍이 일정 개수 이상이면 String 객체에 한하여 별도의 해시 함수를 사용할 수 있게 하는 기능이 있다. 이 기능은 JDK 7u40부터는 삭제되었고, 당연히 Java 8에도 해당 기능은 없다. 여기서 말하는 '일정 개수 이상'이나 '별도의 해시 함수 사용 여부 지정'은 JVM을 가동할 때 옵션으로 지정할 수 있다.
예제 12 Java 7의 String에 대한 hash32() 메서드
JDK 7u6부터 JDK 7u25까지는 jdk.map.althashing.threshold 옵션을 지정하면, HashMap에 저장된 키-값 쌍이 일정 개수 이상일 때 String 객체에 String 클래스의 hashCode() 메서드 대신 sun.misc.Hashing.stringHash32() 메서드를 사용할 수 있게 했다. sun.misc.Hashing.stringHash32() 메서드는 String 클래스의 hash32() 메서드를 호출하게 한 것이고, hash32() 메서드는 MurMur 해시를 구현한 것이다. 이 MurMur 해시를 이용하여 String 객체에 대한 해시 충돌을 매우 낮출 수 있었다고 한다.
그러나 부작용도 있다. MurMur 해시는 hash seed를 필요로 하는데, 이를 위한 것이 sun.misc.Hashing.randomHashSeed() 메서드다. 이 메서드에서는 Random.nextInt() 메서드를 사용한다. Random.nextInt() 메서드는 compare and swap 연산(이하 CAS 연산)을 사용하는 AtomicLong을 사용하는데, CAS 연산은 코어가 많을수록 성능이 떨어진다. 즉 JDK 7u6부터 등장한 String 객체에 대한 별도의 해시 함수는 멀티 코어 환경에서는 성능이 하락했고, 이런 문제로 인해 JDK 7u40부터는 해당 기능을 사용하지 않는다. 당연히 Java 8도 사용하지 않는다.
'프로그래밍언어 > Java&Servlet' 카테고리의 다른 글
| Java - 중첩이 많은 Stream 처리 Tip ! (0) | 2020.04.21 |
|---|---|
| Java - CopyOnWriteArraySet 클래스 (0) | 2019.12.19 |
| Java - Garbage Collection(GC,가비지 컬렉션) 란? (1) | 2019.07.29 |
| Java - JVM이란? JVM 메모리 구조 (1) | 2019.07.29 |
| Eclipse - Archive for required library 해결방법 (0) | 2019.06.18 |

이번 포스팅에서 다루어볼 내용은 spring boot project에서 DB Access관련 설정을 application.properties에 설정 해 놓는데, 기존처럼 평문으로 username/password를 넣는 것이 아니라 특정 알고리즘으로 암호화된 문자열을 넣고 애플리케이션 스타트업 시점에 복호화하여 DB Access를 하는 것입니다. 바로 예제로 들어가겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
package com.example.demo;
import java.security.Key;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Base64;
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
import org.junit.Test;
public class EncryptTest {
@Test
public void encrypt() throws Exception {
String str = "ENCRYPT!@1234";
String encStr = encAES(str);
System.out.println(encStr);
System.out.println(decAES(encStr));
}
public Key getAESKey() throws Exception {
String iv;
Key keySpec;
String key = "encryption!@1234";
iv = key.substring(0, 16);
byte[] keyBytes = new byte[16];
byte[] b = key.getBytes("UTF-8");
int len = b.length;
if (len > keyBytes.length) {
len = keyBytes.length;
}
System.arraycopy(b, 0, keyBytes, 0, len);
keySpec = new SecretKeySpec(keyBytes, "AES");
return keySpec;
}
// 암호화
public String encAES(String str) throws Exception {
Key keySpec = getAESKey();
String iv = "0987654321654321";
Cipher c = Cipher.getInstance("AES/CBC/PKCS5Padding");
c.init(Cipher.ENCRYPT_MODE, keySpec, new IvParameterSpec(iv.getBytes("UTF-8")));
byte[] encrypted = c.doFinal(str.getBytes("UTF-8"));
String enStr = new String(Base64.getEncoder().encode(encrypted));
return enStr;
}
// 복호화
public String decAES(String enStr) throws Exception {
Key keySpec = getAESKey();
String iv = "0987654321654321";
Cipher c = Cipher.getInstance("AES/CBC/PKCS5Padding");
c.init(Cipher.DECRYPT_MODE, keySpec, new IvParameterSpec(iv.getBytes("UTF-8")));
byte[] byteStr = Base64.getDecoder().decode(enStr.getBytes("UTF-8"));
String decStr = new String(c.doFinal(byteStr), "UTF-8");
return decStr;
}
}
|
cs |
위의 소스는 암복호화 단위테스트 코드입니다. AES-128 방식으로 암복호화하였으며 CBC 방식으로 진행하였습니다. 암호화 알고리즘에 대해서는 추후 포스팅하도록 하겠습니다.
|
1
2
3
|
#AES128_Encrypt
spring.datasource.username=T7Me97L7JW9YXubNVtNfpQ==
spring.datasource.password=/Wm/Ubs7CniQuA+5Mzq7Qg==
|
cs |
위는 암호화된 형태소 Datasource 정보를 넣은 것입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
package com.example.demo.config;
import java.security.Key;
import java.util.Base64;
import java.util.Properties;
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.env.EnvironmentPostProcessor;
import org.springframework.core.env.ConfigurableEnvironment;
import org.springframework.core.env.PropertiesPropertySource;
public class EncryptEnvPostProcessor implements EnvironmentPostProcessor {
@Override
public void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {
Properties props = new Properties();
try {
props.put("spring.datasource.password", decAES(environment.getProperty("spring.datasource.password")));
props.put("spring.datasource.username", decAES(environment.getProperty("spring.datasource.username")));
} catch (Exception e) {
System.out.println("DB id/password decrypt fail !");
}
environment.getPropertySources().addFirst(new PropertiesPropertySource("myProps", props));
}
public Key getAESKey() throws Exception {
String iv;
Key keySpec;
String key = "encryption!@1234";
iv = key.substring(0, 16);
byte[] keyBytes = new byte[16];
byte[] b = key.getBytes("UTF-8");
int len = b.length;
if (len > keyBytes.length) {
len = keyBytes.length;
}
System.arraycopy(b, 0, keyBytes, 0, len);
keySpec = new SecretKeySpec(keyBytes, "AES");
return keySpec;
}
// 암호화
public String encAES(String str) throws Exception {
Key keySpec = getAESKey();
String iv = "0987654321654321";
Cipher c = Cipher.getInstance("AES/CBC/PKCS5Padding");
c.init(Cipher.ENCRYPT_MODE, keySpec, new IvParameterSpec(iv.getBytes("UTF-8")));
byte[] encrypted = c.doFinal(str.getBytes("UTF-8"));
String enStr = new String(Base64.getEncoder().encode(encrypted));
return enStr;
}
// 복호화
public String decAES(String enStr) throws Exception {
Key keySpec = getAESKey();
String iv = "0987654321654321";
Cipher c = Cipher.getInstance("AES/CBC/PKCS5Padding");
c.init(Cipher.DECRYPT_MODE, keySpec, new IvParameterSpec(iv.getBytes("UTF-8")));
byte[] byteStr = Base64.getDecoder().decode(enStr.getBytes("UTF-8"));
String decStr = new String(c.doFinal(byteStr), "UTF-8");
return decStr;
}
}
|
cs |
위 소스는 springboot application 기동 시점에 암호화된 username/password를 복호화하여 Datasource 객체를 생성하기 위한 후처리 프로세서입니다. EnvironmentPostProcessor라는 인터페이스를 구현한 클래스를 하나 생성하여 오버라이딩된 메소드에 복호화하는 로직을 구현해주시면 됩니다.
여기서 중요한 것은 그냥 후처리 프로세서를 등록하면 끝나는 것이 아니라 설정 파일을 넣어 주어야 합니다.

src/main/resources/META-INF/spring.factories 파일을 생성하여 아래와 같은 정보를 기입해줍니다.
|
1
2
|
# post processor 적용
org.springframework.boot.env.EnvironmentPostProcessor=com.example.demo.config.EncryptEnvPostProcessor
|
cs |
EncryptEnvPostProcessor라는 클래스의 패키지네임을 포함한 Full Path를 해당 설정파일에 기입해주시면 됩니다.
여기까지 application.properties에 암호화된 정보를 넣어 복호화하는 예제를 진행해봤습니다. 사실 Datasource 외에도 다른 설정파일에도 적용가능한 예제입니다. 활용하시길 바랍니다!
'Web > Spring' 카테고리의 다른 글
| Springboot - Bean Scope(싱글톤, 프로토타입) ? (0) | 2019.08.17 |
|---|---|
| Spring - Field vs Constructor vs Setter Injection 그리고 순환참조(Circular Reference) (3) | 2019.08.17 |
| Springboot - Logback 설정 방법 !(logback-spring.xml) (1) | 2019.06.15 |
| Spring - RestTemplate Connection Pooling (0) | 2019.06.13 |
| Spring - JSON to Object(Object to JSON) Converting Gson ! (0) | 2019.05.30 |
실습은 Mac OS 환경에서 진행하였습니다.
ssh로 원격서버에 접속할 때 매번 비밀번호 치는 것은 귀찮은 작업입니다. 그리고 Git과 같이 버전관리 시스템도 ssh로 원격접속하는 경우가 많은데 이때도 매번 비밀번호를 쳐줘야하는 귀찮은 작업이 있기에 이번에 알아볼 내용은 비밀번호없이 ssh 접속하는 방법입니다.

모두 3번의 엔터를 치고 키를 생성하였습니다. 첫번째 엔터는 키 파일을 만들겠냐, 두번째,세번째는 키파일의 암호를 만들어주는 것인데 필자는 따로 암호를 만들지 않을 것임으로 모두 엔터를 쳐 넘어갔습니다.

이제 /home/.ssh에 두개의 파일이 생성되었을 텐데, id_rsa는 우리가 사용할 비밀키입니다. 절대로 유출되어서는 안되는 파일입니다. 그리고 id_rsa.pub은 원격 접속할 서버에서 사용할 우리의 공개키입니다. 권한은 절대 변경하시지 말고 사용하시길 바랍니다. 이 파일들을 어떻게 사용하냐면 우리가 생성한 공개키를 원격서버에 저장합니다. 그리고 우리는 원격서버에 접속할때 비밀번호를 치지않고 우리의 비밀키를 이용하여 원격서버에 접속을 하게 됩니다. 즉, 사용자가 직접 비밀번호를 치는 것이 아니라 OS가 내부적으로 원격서버의 공개키, 그리고 우리의 비밀키와 대조하여 인증을 대신하게 됩니다.
id_rsa.pub 안에 있는 공개키 내용을 원격 서버의 /home/.ssh/authorized_keys 라는 파일에 저장할 것입니다. 만약 원격 서버에 authorized_keys라는 파일이 없으면 생성해주시면 되는데, 중요한 것은 파일의 내용을 임의로 바꾸시지 마시고 위의 파일명과 동일하게 만들어주셔야 합니다. 그리고 id_rsa.pub안에 있는 내용을 빠짐없이 전부 authorized_keys에 저장하여야합니다.
그런데 매번 id_rsa.pub에 있는 내용을 복사해서 원격서버에 들어가 authorized_keys에 공개키를 저장하는 것은 귀찮은 작업입니다. 이럴때 사용할 수 있는 명령어를 소개하겠습니다.
>ssh-copy-id id@ip
위에 보시는 것처럼 ssh-copy-id라는 명령어의 인자로 접속할 원격 서버의 계정명@원격서버ip를 입력해주시면 우리의 공개키를 원격서버의 /home/.ssh/authorized_keys에 추가해줍니다.
이제 모든 작업이 완료되었습니다.
>ssh id@ip
위의 명령어로 원격서버에 접속하면 첫번째 접속만 빼고는 이제 비밀번호 없이 접속이 가능해집니다!
'인프라 > 네트워크(기초)' 카테고리의 다른 글
| 네트워크(DNS) - A record와 CNAME의 차이점!(DNS Record Type) (0) | 2020.04.22 |
|---|---|
| Network - Proxy(프록시)와 Gateway(게이트웨이)란? 이 둘의 차이점은? (0) | 2020.04.12 |
| 네트워크 - GSLB(Global Server Load Balancing)란? (2) | 2020.04.07 |
| 네트워크 - HTTP/HTTPS 차이점, HTTPS란? (0) | 2019.08.01 |
| 네트워크 - Wireshark(와이어샤크) 설치 및 패킷 분석 예제 (0) | 2019.08.01 |
생활 코딩이라는 웹사이트의 이고잉님이 하신 말씀이 너무 와닿아서 글로 남겨본다. 지금까지 필자는 새로운 기술이 궁금하면 찾아서 보고 그것만으로는 안될 것 같아 여러권의 책을 사서 구입하고 책을 완독한 후에 뭔가 공부를 했다라는 성취감을 느끼고 그것으로 만족함을 얻었던 것 같다. 그런데 과연 책 몇 권을 읽고 완독해서 그것을 다 공부했다고 할 수 있을까? 마스터 했다고 할 수 있을까? 책은 쪽수가 있고, 그 쪽수까지 다 보고 나면 그 책의 내용은 끝이 난다. 즉, 끝이 닫혀 있는 공부인 것이다.
하지만 나는 여기서 조금 더 생각을 보태본다.
새로운 것을 알고 싶다 -> 책을 사서 공부한다 -> 실 사례에 적용해본다 -> 또 다른 새로운 것을 배우는 시작점이 된다.
새로운 것을 배운다라는 마음을 먹기 시작하고 실천에 옮기면 또 다른 무엇인가를 새로 배우는 것을 두려워 하지 않는다. 이것은 직접 느낀 점이다. 하지만 절대 강박을 갖지말자 강박을 갖기 시작하면 쉴틈없이 내몸을 혹사시킨다. 꼭 쉬는 시간을 가져가자.

오늘 포스팅할 내용은 간단하게 HTTP와 HTTPS와의 차이점을 보고 더 나아가 HTTPS에 대해 다루어보려 한다.
HTTP VS HTTPS
웹 개발을 하는 개발자라면 HTTP 프로토콜이라는 것을 모르지 않을 것이다. HTTP란 Hypertext Transfer Protocol의 약자이다. OSI 7계층 중 응용계층에 위치하고 있는 프로토콜이다. 이 프로토콜은 간단히 네트워크 구간에서 HTML문서를 전송하기 위한 통신규약이다. 물론 HTML 문서만을 주고 받는 것은 아니지만 간단히 쉽게 HTML을 주고 받기 위한 프로토콜이라고 생각하자. 그렇다면 HTTPS란 무엇일까? HTTPS는 Hypertext Transfer Protocol Over Secure Socket Layer의 약자로 Secure라는 단어가 포함되어 있는 것을 보면 알 수 있듯이 보안이 강화되면 HTTP 프로토콜이다. 지난 포스팅 중에 Wireshark를 이용해 간단히 HTTP의 패킷을 분석해보았을 때, POST로 보낸 데이터가 평문 텍스트로 그대로 노출되어 있는 것을 볼 수 있었다. 즉, 암호화되지 않은 데이터를 전송하기 때문에 서버와 클라이언트가 주고 받는 메시지를 그대로 노출하기 때문에 보안에 아주 취약하다. 이러한 점을 보완하여 보안을 더욱 강화한 프로토콜이 HTTPS인 것이다.
2019/08/01 - [네트워크(기초)] - 네트워크 - Wireshark(와이어샤크) 설치 및 패킷 분석 예제
네트워크 - Wireshark(와이어샤크) 설치 및 패킷 분석 예제
오늘 다루어볼 포스팅 내용은 Wireshark를 이용한 네트워크 패킷 분석 예제입니다. HTTP/HTTPS 포스팅을 위한 선행 작업이라고 볼 수 있을 것 같습니다. 모든 환경은 Mac OS 환경에서 진행되었음을 알려드립니다...
coding-start.tistory.com
그렇다면 HTTPS는 어떻게 동작할까? 간단히 HTTPS는 SSL이라는 보안 프로토콜 위에서 동작하는 HTTP라고 생각 할 수 있다.
그렇다면 SSL,TLS란 무엇일까? 아래 그림과 같이 살펴보자.

SSL(Secure Sockey Layer)란 보안 소켓 계층을 이르는 것으로, 인터넷 상에서 데이터를 안전하게 전송하기 위한 인터넷 암호화 통신 프로토콜을 말한다. SSL은 전자상거래 등의 보안을 위해 넷스케이프에서 처음 개발되었고, 시간이 지나 IETF에 의해 SSL3.0을 이용해TLS(Transport Layer Security)로 표준화 하였다. 즉, 간단히 이야기하면 SSL == TLS이다.(물론 표준화되면서 기능상 차이가 있을 지는 모르지만 결국 SSL를 표준화한 것이 TLS이다.)
위의 그림을 보자. SSL/TLS는 어떠한 계층에 올라가있을까? 사실 어느 계층에 속해있다고 이야기하기는 힘들다. SSL/TLS는 응용계층과 전송계층 사이에서 동작하는 독립적인 프로토콜이라고 생각하면 좋다. 자세한 동작 방식을 설명하기 전에 간단한 SSL 플로우를 이야기하자면 응용계층의 HTTP 프로토콜에서 사용자의 데이터를 받고 전송계층으로 캡슐화되기 이전에 SSL 프로토콜에 의해서 사용자의 데이터가 암호화된다. 그리고 서버는 전송계층에서 세그먼트를 받아 SSL 계층에서 데이터를 복호화하여 응용계층까지 보낸다. 즉, 우리는 SSL 프로토콜만 적용하면 마치 애플리케이션은 SSL을 TCP로 인식하고 TCP는 SSL을 애플리케이션으로 인식하는 것처럼 통신하기 때문에 우리가 별도로 통신에 대해 손댈것은 없다.
SSL은 TCP 위에서 Record Protocol을 통해 실질적인 보안서비스를 제공하고 Handshake Procotol, Change Cipher Spec Protocol, Alert Protocol을 통해 SSL 동작에 관한 관리를 하게 된다.
1.Record Protocol
Record protocol은 데이터의 압축을 수행하여 안전한 TCP패킷으로 변환하고, 데이터 암호화 및 무결성을 위한 메시지 인증을 수행하는 프로토콜로 Handshake Protocol, Change Cipher Spec Protocol, Alert Protocol 그리고 Application Protocol을 감싸는 역할을 한다.
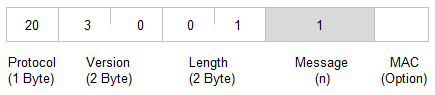
-Protocol 필드에는 Change Cipher Spec을 나타내는 20이 들어간다.
-data를 보내기 좋게 자르거나 붙이고 선택적으로 압축하여 MAC(Message Authentication Code)을 적용하고 암호화하여 이를 TCP로 전달
2.Change Cipher Spec Protocol
암호화 알고리즘과 보안 정책을 송수신 측간에 조율하기 위해 사용하는 프로토콜로 프로토콜의 내용에는 단 하나의 바이트, 언제나 1이라는 값이 들어간다.
3.Alert Protocol

2바이트로 구성되며, 첫번째 바이트에는 warning 또는 fatal이 들어가고 두번째 바이트에는 handshake, change cipher spec, record protocol 수행 중 발생하는 오류메시지가 들어가게 된다.
-Warning : 주의해야 하는 문제, 연결 미종료
-Fatal : 매우 중요한 문제, 연결 종료
4.Handshake Protocol
암호 알고리즘 결정, 키 분배, 서버 및 클라이언트 인증을 수행하기 위해 사용되는 프로토콜이다. 아래 그림은 간단한 해당 프로토콜의 동작방식이다.

SSL 전체 통신 과정
자 지금까지 이론을 다루어 보았는데, 실제 동작에 대해서 알아보자. 우선 SSL 설명 전에 암호화 방식에 대해 간단히 다루어보자.
암호를 만드는 행위인 암호화를 할 때 사용하는 일종의 비밀번호를 키(key)라고 한다. 이 키에 따라서 암호화된 결과가 달라지기 때문에 키를 모르면 암호를 푸는 행위인 복호화를 할 수 없다.
-대칭키 : 하나의 키로 데이터를 암호화하고 복호화한다. 하나의 키로 암복호화를 하기 때문에 해당 키가 노출된다면 보안상 아주 치명적인 문제가 발생한다. 장점이라고 하면 암복호화에 드는 비용이 적다.
대칭키 방식은 단점이 있다. 암호를 주고 받는 사람들 사이에 대칭키를 전달하는 것이 어렵다는 점이다. 대칭키가 유출되면 키를 획득한 공격자는 암호의 내용을 복호화 할 수 있기 때문에 암호가 무용지물이 되기 때문이다. 이런 배경에서 나온 암호화 방식이 비대칭키(공개키)방식이다.
-비대칭키 : 2개의 키(공개키,비공개키)로 암호화&복호화한다. 즉, 공개키로 데이터를 암호화하면 반드시 비밀키로만 복호화 가능하고 비밀키로 데이터를 암호화하면 공개키로만 복호화할 수 있다. 이 방식에 착안해서 두개의 키 중 하나를 비공개키(private key, 개인키, 비밀키라고도 부른다)로하고, 나머지를 공개키(public key)로 지정한다. 비공개키는 자신만이 가지고 있고, 공개키를 타인에게 제공한다. 그렇다면 암호화,복호화의 주체가 되는 키에 따른 특징을 무엇일까?
1)암호화-공개키,복호화-비공개키 : 진짜 데이터를 암호화하여 보호하기 위한 목적이다.
2)암호화-비공개키,복호화-공개키 : 인증을 위한 목적이다. 즉, 서버에서 비공개키로 데이터를 암호화해서 보냈고 클라이언트에서 공개키로 복호화가 된다면 최소한 해당 서버는 클라이언트 입장에서 신뢰할 수 있다는 인증과정을 거치게 된것이다.
위의 두개의 개념들은 SSL에서 사용되는 개념이다. 꼭 알아두어야 한다. SSL에서는 두가지 방식을 혼합하여 사용한다.

위의 그림을 살펴보자. 우리가 평소에 아는 것은 Client&Server이다. 하지만 위에 Host responps with valid SSL certificate 라는 생소한 것이 있다. 이것은 무엇일까?
CA
인증서의 역할은 클라이언트가 접속한 서버가 클라이언트가 의도한 서버가 맞는지를 보장하는 역할을 한다. 이 역할을 하는 민간기업들이 있는데 이런 기업들을 CA(Certificate authority) 혹은 Root Certificate 라고 부른다. CA는 아무 기업이나 할 수 있는 것이 아니고 신뢰성이 엄격하게 공인된 기업들만이 참여할 수 있다. 그 중에 대표적인 기업들은 아래와 같다. 수치는 현시점의 시장점유율이다. (위키피디아 참조)
- Symantec (VeriSign, Thawte, Geotrust) with 42.9% market share
- Comodo with 26%
- GoDaddy with 14%
- GlobalSign with 7.7%
SSL을 통해서 암호화된 통신을 제공하려는 서비스는 CA를 통해서 인증서를 구입해야 한다. CA는 서비스의 신뢰성을 다양한 방법으로 평가하게 된다.
즉, 개발자 입장에서 우리가 서버를 개발하는 개발자이다. 모든 개발이 끝나고 오픈을 하기위해 HTTPS를 적용하려고 한다. 그렇다면 우리는 신뢰할 수 있는 CA 기업에 인증서를 구입하여야 한다.(물론 무료인 인증서도 있지만 브라우저가 신뢰할 수 있는 CA이며 무료인 것은 많지 않다. 1년간 무료 인증서를 제공하는 starcom이라는 기업뿐이다.) 인증서를 구입하면 CA는 우리에게 무엇을 줄까? 바로 인증서를 준다. 정확히 말하면 CA기업의 비밀키를 이용하여 암호화한 인증서를 주는 것이다. 그렇다면 인증서에는 어떠한 정보가 들어가 있을까?
SSL 인증서에 들어가 있는 정보
- 서비스의 정보(인증서를 발급한 CA, 서비스의 도메인 등)
- 서버 측 공개키(공개키의 내용, 공개키의 암호화 방법)
위에서는 이야기 하지 않았지만 CA기업은 우리에게 암호화된 인증서 + 서버에서 사용할 비밀키까지 쥐어준다. 그렇기 때문에 해당 비밀키와 함께 사용될 공개키를 SSL 인증서 안에 담아주는 것이다. 집중한 사람은 여기서 의문이 생길 것이다. 그러면 서버에서 사용할 비밀키를 받았고 클라이언트가 사용할 공개키는 인증서 안에 담겨 있는데, 그렇다면 CA의 비밀키로 암호화된 인증서를 복호화할 공개키는 어디있지? 답은 브라우저에 있다. 우리가 사용하는 크롬,IE,사파리,파이어폭스 등에는 이미 신뢰할 수 있는 CA 기관의 리스트와 해당 기관의 공개키를 이미 가지고 있다. 나머지 내용은 밑에서 설명한다.
SSL의 인증서의 역할
그렇다면 SSL 인증서가 우리에게 해주는 역할은 무엇일까?
- 클라이언트가 접속한 서버가 신뢰 할 수 있는 서버임을 보장한다.
- SSL 통신에 사용할 공개키를 클라이언트에게 제공한다.
위의 그림을 보면서 자세한 동작을 확인하자.
1)클라이언트는 브라우저에 들어가 접속한 URL을 치고 엔터를 친다.
-HTTP 통신을 위해서는 3-way-handshake(TCP연결수립)라는 동작을 한다. 하지만 HTTPS는 HTTP와는 조금 다른 3-way-handshake 작업을 한다. 위 4번의 handshake protocol글을 참조하자.
즉, HTTPS의 3-way-handshake 과정에서 클라이언트는 서버에게 SSL 인증서를 전달받는다. 그리고 전달받은 SSL인증서를 브라우저가 내부적으로 가지고 있는 CA리스트와 CA공개키를 이용해 신뢰할 수 있는 기관의 인증서인지를 검사한다. 그리고 데이터 암호화를 위한 대칭키를 생성한다.


다음은 Wireshark를 이용하여 HTTPS 통신의 패킷을 분석한 결과이다.
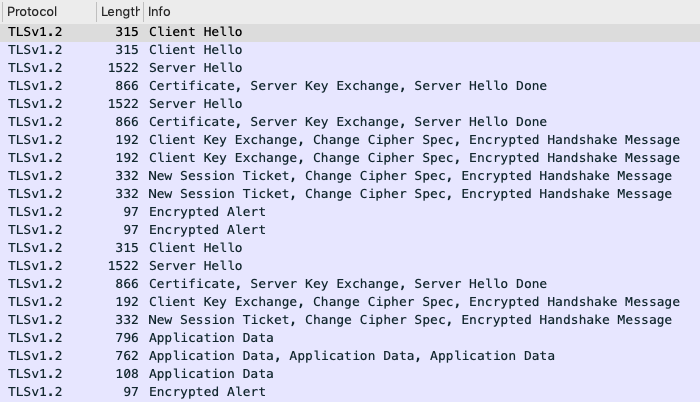
다수의 과정을 통해 클라이언트가 서버에 접속한다. 다시 뒤로 돌아가서 HTTPS로 통신을 하면 네트워크 통신과정에서 주고 받는 데이터가 암호화 된다. 그렇다면 클라이언트의 데이터는 어떻게 암호화할까? SSL은 대칭키와 비대칭키를 혼합해서 사용한다고 했다. 즉, 클라이언트의 데이터는 대칭키로 암호화한다! 그렇다면 이 대칭키는 어떻게 만들까? 인증서에는 클라이언트가 사용할 공개키 밖에 없다고 했는데? 이것은 위의 그림의 과정 중에 만들어진다. Client Hello,Server Hello 등의 과정에서 클라이언트와 서버는 각각 생성한 랜덤 데이터를 주고 받는다. 또한 사용 가능한 암호화 방식들을 주고 받는다. 대칭키는 바로 서로 주고 받는 랜덤 데이터를 이용하여 만들게 되는 것이다. 그리고 매번 통신을 할때 3-way-handshake 과정을 거치는데 이때 매번 새로운 대칭키가 만들어진다.
어? 대칭키는 키 유출시에 보안에 굉장히 취약하다고 했는데.. 여기서 바로 인증서에 있는 클라이언트 공개키를 이용하는 것이다. 인증서에 있는 공개키를 이용하여 랜덤데이터(클,서)로 만든 대칭키를 암호화하는 것이다. 그리고 서버에서는 자신의 비공개키로 암호화된 대칭키를 복호화하고 복호화된 대칭키로 클라이언트 데이터를 다시 복호화한다. 복잡하다.. 다시 정리해보자
1.클라이언트가 접속한 서버가 신뢰 할 수 있는 서버임을 보장한다.
1)클라이언트는 서버로 접속하여 CA의 SSL 인증서를 응답으로 받는다.
2)브라우저는 SSL인증서가 신뢰할 수 있는 CA기관의 인증서인지 확인한다.(여기서 브라우저가 내부적으로 가지고 있는 CA리스트와 각 CA의 공개키를 이용해 SSL인증서를 복호화한다.)
처음에 비밀키로 암호화하고 공개키로 복호화하면 인증과 같은 용도로 사용된다고 이야기했다.
2.SSL 통신에 사용할 공개키를 클라이언트에게 제공한다.
1)클라이언트와 서버의 3-way-handshake 과정에서 클라이언트와 서버가 생성한 랜덤데이터를 이용해 대칭키를 만든다.
2)클라이언트는 해당 대칭키로 서버에 보낼 데이터를 암호화한 후에 SSL인증서에 담겨있는 공개키를 이용하여 대칭키를 암호화한다.
3)암호화한 데이터와 암호화한 대칭키를 서버로 전송한다.
4)서버는 자신의 비밀키로 암호화된 대칭키를 복호화하고 해당 대칭키로 클라이언트가 보낸 암호화된 데이터를 복호화한다.
공개키로 암호화하고 비밀키로 복호화하는 것은 진짜 보낼 데이터를 암호화하여 노출되지 않게 할 용도로 사용한다 이야기했다.
필자의 설명이 부족할 것 같아 이고잉님이 정리하신 글을 다시 반복해서 올린다.
결론부터 말하면 SSL은 암호화된 데이터를 전송하기 위해서 공개키와 대칭키를 혼합해서 사용한다. 즉 클라이언트와 서버가 주고 받는 실제 정보는 대칭키 방식으로 암호화하고, 대칭키 방식으로 암호화된 실제 정보를 복호화할 때사용할 대칭키는 공개키 방식으로 암호화해서 클라이언트와 서버가 주고 받는다. 이 설명만으로는 이해하기 어려울 것이다. 아래의 관계만 일단 머리속에 기억해두고 좀 더 구체적인 설명으로 넘어가자.
- 실제 데이터 : 대칭키
- 대칭키의 키 : 공개키
컴퓨터와 컴퓨터가 네트워크를 이용해서 통신을 할 때는 내부적으로 3가지 단계가 있다. 아래와 같다.
악수 -> 전송 -> 세션종료
이것은 은밀하게 일어나기 때문에 사용자에게 노출되지 않는다. 이 과정에서 SSL가 어떻게 데이터를 암호화해서 전달하는지 살펴보자.
1. 악수 (handshake)
사람과 사람이 소통을 할 때를 생각해보자. 우선 인사를 한다. 인사를 통해서 상대의 기분과 상황을 상호탐색을 하는 것이다. 이 과정이 잘되야 소통이 원활해진다. 클라이언트와 서버 사이도 마찬가지다. 실제 데이터를 주고 받기 전에 클라이언트와 서버는 일종의 인사인 Handshake(진짜로 사용하는 기술용어다)를 한다. 이 과정을 통해서 서로 상대방이 존재하는지, 또 상대방과 데이터를 주고 받기 위해서는 어떤 방법을 사용해야하는지를 파악한다.
SSL 방식을 이용해서 통신을 하는 브라우저와 서버 역시 핸드쉐이크를 하는데, 이 때 SSL 인증서를 주고 받는다. 이 과정은 앞에서 설명한 바 있다. 인증서에 포함된 서버 측 공개키의 역할은 무엇일까를 이제 알아보자.
공개키는 이상적인 통신 방법이다. 암호화와 복호화를 할 때 사용하는 키가 서로 다르기 때문에 메시지를 전송하는 쪽이 공개키로 데이터를 암호화하고, 수신 받는 쪽이 비공개키로 데이터를 복호화하면 되기 때문이다. 그런데 SSL에서는 이 방식을 사용하지 않는다. 왜냐하면 공개키 방식의 암호화는 매우 많은 컴퓨터 자원을 사용하기 때문이다. 반면에 암호화와 복호화에 사용되는 키가 동일한 대칭키 방식은 적은 컴퓨터 자원으로 암호화를 수행할 수 있기 때문에 효율적이지만 수신측과 송신측이 동일한 키를 공유해야 하기 때문에 보안의 문제가 발생한다. 그래서 SSL은 공개키와 대칭키의 장점을 혼합한 방법을 사용한다. 그 핸드쉐이크 단계에서 클라이언트와 서버가 통신하는 과정을 순서대로 살펴보자.
- 클라이언트가 서버에 접속한다. 이 단계를 Client Hello라고 한다. 이 단계에서 주고 받는 정보는 아래와 같다.
- 클라이언트 측에서 생성한 랜덤 데이터 : 아래 3번 과정 참조
- 클라이언트가 지원하는 암호화 방식들 : 클라이언트와 서버가 지원하는 암호화 방식이 서로 다를 수 있기 때문에 상호간에 어떤 암호화 방식을 사용할 것인지에 대한 협상을 해야 한다. 이 협상을 위해서 클라이언트 측에서는 자신이 사용할 수 있는 암호화 방식을 전송한다.
- 세션 아이디 : 이미 SSL 핸드쉐이킹을 했다면 비용과 시간을 절약하기 위해서 기존의 세션을 재활용하게 되는데 이 때 사용할 연결에 대한 식별자를 서버 측으로 전송한다.
- 서버는 Client Hello에 대한 응답으로 Server Hello를 하게 된다. 이 단계에서 주고 받는 정보는 아래와 같다.
- 서버 측에서 생성한 랜덤 데이터 : 아래 3번 과정 참조
- 서버가 선택한 클라이언트의 암호화 방식 : 클라이언트가 전달한 암호화 방식 중에서 서버 쪽에서도 사용할 수 있는 암호화 방식을 선택해서 클라이언트로 전달한다. 이로써 암호화 방식에 대한 협상이 종료되고 서버와 클라이언트는 이 암호화 방식을 이용해서 정보를 교환하게 된다.
- 인증서
- 클라이언트는 서버의 인증서가 CA에 의해서 발급된 것인지를 확인하기 위해서 클라이언트에 내장된 CA 리스트를 확인한다. CA 리스트에 인증서가 없다면 사용자에게 경고 메시지를 출력한다. 인증서가 CA에 의해서 발급된 것인지를 확인하기 위해서 클라이언트에 내장된 CA의 공개키를 이용해서 인증서를 복호화한다. 복호화에 성공했다면 인증서는 CA의 개인키로 암호화된 문서임이 암시적으로 보증된 것이다. 인증서를 전송한 서버를 믿을 수 있게 된 것이다.
클라이언트는 상기 2번을 통해서 받은 서버의 랜덤 데이터와 클라이언트가 생성한 랜덤 데이터를 조합해서 pre master secret라는 키를 생성한다. 이 키는 뒤에서 살펴볼 세션 단계에서 데이터를 주고 받을 때 암호화하기 위해서 사용될 것이다. 이 때 사용할 암호화 기법은 대칭키이기 때문에 pre master secret 값은 제 3자에게 절대로 노출되어서는 안된다.
그럼 문제는 이 pre master secret 값을 어떻게 서버에게 전달할 것인가이다. 이 때 사용하는 방법이 바로 공개키 방식이다. 서버의 공개키로 pre master secret 값을 암호화해서 서버로 전송하면 서버는 자신의 비공개키로 안전하게 복호화 할 수 있다. 그럼 서버의 공개키는 어떻게 구할 수 있을까? 서버로부터 받은 인증서 안에 들어있다. 이 서버의 공개키를 이용해서 pre master secret 값을 암호화한 후에 서버로 전송하면 안전하게 전송할 수 있다.
- 서버는 클라이언트가 전송한 pre master secret 값을 자신의 비공개키로 복호화한다. 이로서 서버와 클라이언트가 모두 pre master secret 값을 공유하게 되었다. 그리고 서버와 클라이언트는 모두 일련의 과정을 거쳐서 pre master secret 값을 master secret 값으로 만든다. master secret는 session key를 생성하는데 이 session key 값을 이용해서 서버와 클라이언트는 데이터를 대칭키 방식으로 암호화 한 후에 주고 받는다. 이렇게해서 세션키를 클라이언트와 서버가 모두 공유하게 되었다는 점을 기억하자.
- 클라이언트와 서버는 핸드쉐이크 단계의 종료를 서로에게 알린다.
2. 세션
세션은 실제로 서버와 클라이언트가 데이터를 주고 받는 단계이다. 이 단계에서 핵심은 정보를 상대방에게 전송하기 전에 session key 값을 이용해서 대칭키 방식으로 암호화 한다는 점이다. 암호화된 정보는 상대방에게 전송될 것이고, 상대방도 세션키 값을 알고 있기 때문에 암호를 복호화 할 수 있다.
그냥 공개키를 사용하면 될 것을 대칭키와 공개키를 조합해서 사용하는 이유는 무엇을까? 그것은 공개키 방식이 많은 컴퓨터 파워를 사용하기 때문이다. 만약 공개키를 그대로 사용하면 많은 접속이 몰리는 서버는 매우 큰 비용을 지불해야 할 것이다. 반대로 대칭키는 암호를 푸는 열쇠인 대칭키를 상대에게 전송해야 하는데, 암호화가 되지 않은 인터넷을 통해서 키를 전송하는 것은 위험하기 때문이다. 그래서 속도는 느리지만 데이터를 안전하게 주고 받을 수 있는 공개키 방식으로 대칭키를 암호화하고, 실제 데이터를 주고 받을 때는 대칭키를 이용해서 데이터를 주고 받는 것이다.
3. 세션종료
데이터의 전송이 끝나면 SSL 통신이 끝났음을 서로에게 알려준다. 이 때 통신에서 사용한 대칭키인 세션키를 폐기한다.
HTTPS와 SSL 인증서 - 생활코딩
HTTPS VS HTTP HTTP는 Hypertext Transfer Protocol의 약자다. 즉 Hypertext 인 HTML을 전송하기 위한 통신규약을 의미한다. HTTPS에서 마지막의 S는 Over Secure Socket Layer의 약자로 Secure라는 말을 통해서 알 수 있듯이 보안이 강화된 HTTP라는 것을 짐작할 수 있다. HTTP는 암호화되지 않은 방법으로 데이터를 전송하기 때문에 서버와 클라이언트가 주고 받는 메시지를 감청하는 것이
www.opentutorials.org
여기까지 간단히 HTTP와 HTTPS의 차이점, HTTPS의 동작방법을 다루어보았다.
'인프라 > 네트워크(기초)' 카테고리의 다른 글
| 네트워크(DNS) - A record와 CNAME의 차이점!(DNS Record Type) (0) | 2020.04.22 |
|---|---|
| Network - Proxy(프록시)와 Gateway(게이트웨이)란? 이 둘의 차이점은? (0) | 2020.04.12 |
| 네트워크 - GSLB(Global Server Load Balancing)란? (2) | 2020.04.07 |
| OS - ssh 비밀번호 없이 접속하기 (0) | 2019.08.04 |
| 네트워크 - Wireshark(와이어샤크) 설치 및 패킷 분석 예제 (0) | 2019.08.01 |